您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
怎么在python蜘蛛使用用pushplus对亚马逊到货动态推送进行监控?针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
一、pushplus相关介绍
pushplus提供了免费的微信消息推送api,具体内容可以参考他的官网:pushplus(推送加)微信推送消息直达 (hxtrip.com)
我们需要用到的东西有,登陆后的个人Token(用于精准推送消息),如图:
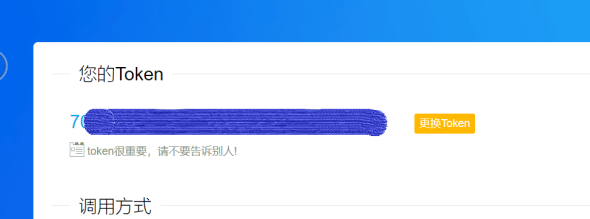
调用该接口可使用如下代码,token为上面提到的你个人的token,titile对应推送标题,content对应推送内容,此代码借鉴了官方demo
def post_push(token, title, content):
url = 'http://pushplus.hxtrip.com/send'
data = {
"token": token,
"title": title,
"content": content
}
body = json.dumps(data).encode(encoding='utf-8')
headers = {'Content-Type': 'application/json'}
requests.post(url, data=body, headers=headers)不出意外的话,你在编写代码时,amazon应该处于无货状态(有货直接就买了啊喂)!!!我们在此时打开amazon页面,可以看到如下界面:
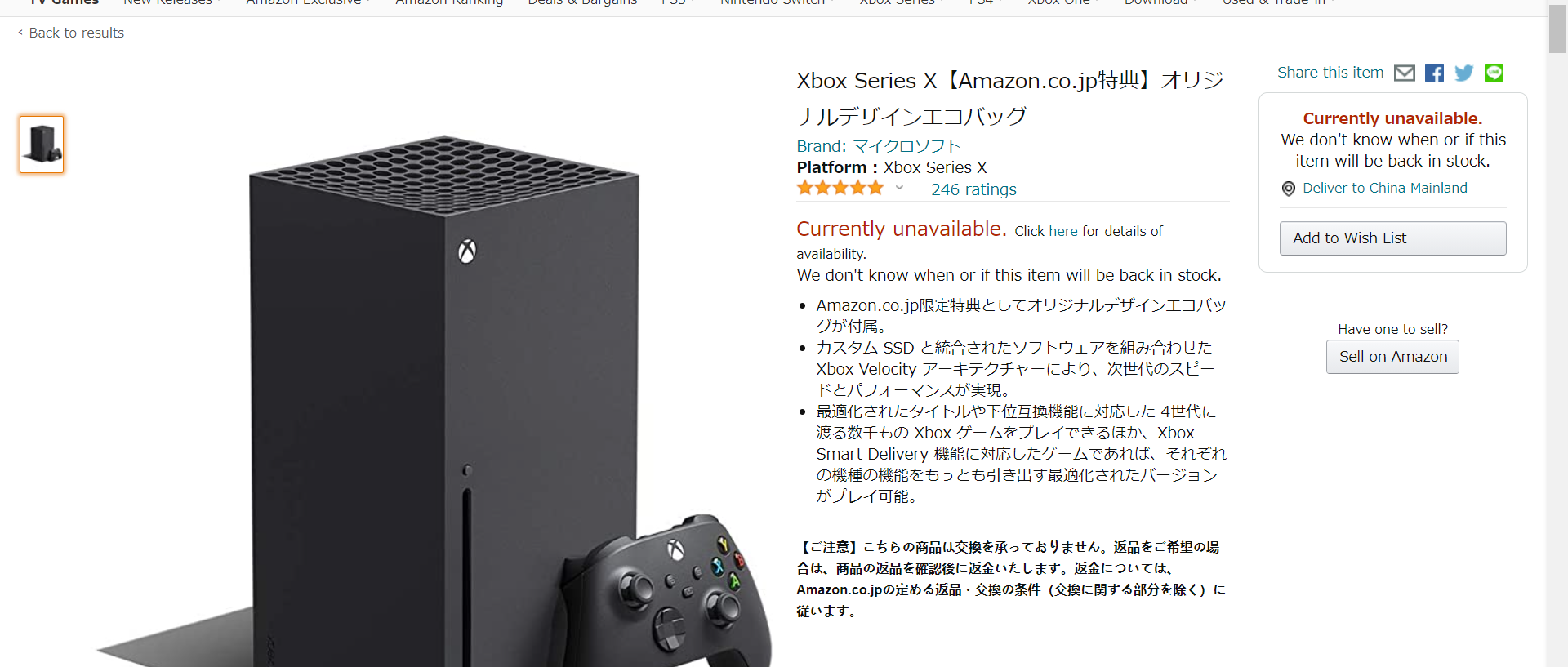
在新版Edge浏览器或者chrome下,按F12查看网页源码,选定中间Currently unavailable标识的区域(五颗星下面那个,最好覆盖范围大一点),能看到代码如下:
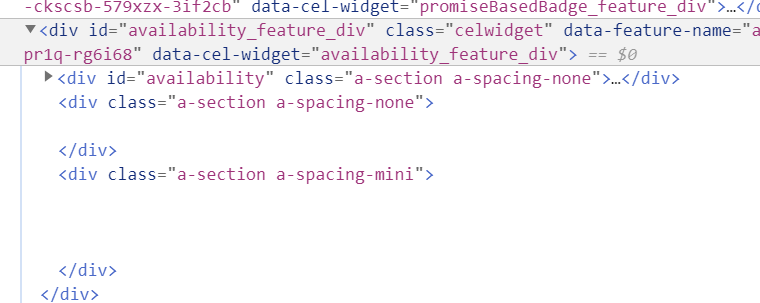
有一个比较简单的办法,判断amazon是否有补货。我们可以抓取这一部分的html源码,存进一个文件里(txt即可)。每过一定时间,重新抓取源码,如果这些源码变化了,那么基本上是网站更新了(补货了)。不过有个小瑕疵,这种补货也可能是亚马逊第三方(黄牛)补货- -
不过总归是有了一个判断上新的方法嘛;其实黄牛补货很少的,德亚上好像看不到黄牛(我个人没见过德亚上的第三方卖xsx的),日亚上基本没有啥黄牛卖xbox
好了,接下来,我们看看如何实现相关功能
我们使用Requests+BeautfifulSoup来抓取<div id = 'availability_feature_div> </div>这个标签内部的所有html源码
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 9; SM-A102U) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.93 Mobile Safari/537.36",
'Content-Type': 'application/json'
}
html = requests.get(url=self.url, headers=headers)
soup = BeautifulSoup(html.text, 'lxml')
html.close()
target = str(soup.find('div', id='availability_feature_div'))注意如果不加headers的话,amazon会检测到爬虫,不会给你返回完整html代码。第7行把requests给close掉是因为,我在监测时开了两个线程同时检测日亚和德亚,如果不加这一句的话,会被amazon认为是我在攻击网站,会拒绝我的网络访问
最终的target是被转为str格式的相应html源码,接下来只需要将其保存到文件,每隔一定时间再次爬虫比对就行了
import json
import requests
from bs4 import BeautifulSoup
import filecmp
import time
import threading
class listenThread(threading.Thread):
def __init__(self, url, originFile, newFile, content):
threading.Thread.__init__(self)
self.url = url
self.originFile = originFile
self.newFile = newFile
self.content = content
def listen(self):
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 9; SM-A102U) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.93 Mobile Safari/537.36",
'Content-Type': 'application/json'
}
html = requests.get(url=self.url, headers=headers)
soup = BeautifulSoup(html.text, 'lxml')
html.close()
target = str(soup.find('div', id='availability_feature_div'))
filetxt = open(self.originFile, 'w', encoding='utf-8')
filetxt.write(target)
filetxt.close()
while True:
target = str(soup.find('div', id='availability_feature_div'))
filetxt = open(self.newFile, 'w', encoding='utf-8')
filetxt.write(target)
filetxt.close()
if filecmp.cmp(self.originFile, self.newFile) == False:
post_push('这里输你自己的token', 'xbox update', self.content)
fileAvail = open(self.originFile, 'w')
fileAvail.write(target)
fileAvail.close()
time.sleep(30)
def run(self):
self.listen()
def post_push(token, title, content):
url = 'http://pushplus.hxtrip.com/send'
data = {
"token": token,
"title": title,
"content": content
}
body = json.dumps(data).encode(encoding='utf-8')
headers = {'Content-Type': 'application/json'}
requests.post(url, data=body, headers=headers)
if __name__ == '__main__':
detect_url = 'https://www.amazon.co.jp/-/en/dp/B08GGKZ34Z/ref=sr_1_2?dchild=1&keywords=xbox&qid=1611674118&sr=8-2'
#url_special = 'https://www.amazon.co.jp/-/en/dp/B08GG17K5G/ref=sr_1_6?dchild=1&keywords=xbox%E3%82%B7%E3%83%AA%E3%83%BC%E3%82%BAx&qid=1611722050&sr=8-6'
url_germany = 'https://www.amazon.de/Microsoft-RRT-00009-Xbox-Series-1TB/dp/B08H93ZRLL/ref=sr_1_2?__mk_de_DE=%C3%85M%C3%85%C5%BD%C3%95%C3%91&dchild=1&keywords=xbox&qid=1611742161&sr=8-2'
xbox = listenThread(url=detect_url,originFile='avail.txt',newFile='avail_now.txt',content='日亚')
#xbox_sp = listenThread(url=detect_url,originFile='avail_sp.txt',newFile='avail_now_sp.txt')
xbox_germany = listenThread(url=url_germany,originFile='avail_sp.txt',newFile='avail_now_sp.txt',content='德亚')
xbox.start()
#xbox_sp.start()
xbox_germany.start()关于怎么在python蜘蛛使用用pushplus对亚马逊到货动态推送进行监控问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。