жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚеҰӮдҪ•дҪҝз”ЁNode.jsй«ҳж•Ҳең°д»ҺWebзҲ¬еҸ–ж•°жҚ®пјҢж–Үдёӯд»Ӣз»Қзҡ„йқһеёёиҜҰз»ҶпјҢе…·жңүдёҖе®ҡзҡ„еҸӮиҖғд»·еҖјпјҢж„ҹе…ҙи¶Јзҡ„е°Ҹдјҷдјҙ们дёҖе®ҡиҰҒзңӢе®ҢпјҒ
з”ұдәҺJavascriptжңүдәҶе·ЁеӨ§зҡ„ж”№иҝӣпјҢ并且引е…ҘдәҶз§°дёәNodeJSзҡ„иҝҗиЎҢж—¶пјҢеӣ жӯӨе®ғе·ІжҲҗдёәжңҖжөҒиЎҢе’ҢдҪҝз”ЁжңҖе№ҝжіӣзҡ„иҜӯиЁҖд№ӢдёҖгҖӮ ж— и®әжҳҜWebеә”з”ЁзЁӢеәҸиҝҳжҳҜ移еҠЁеә”з”ЁзЁӢеәҸпјҢJavascriptзҺ°еңЁйғҪе…·жңүжӯЈзЎ®зҡ„е·Ҙе…·гҖӮ жң¬ж–Үи®Іи§ЈжҖҺж ·з”Ё Node.js й«ҳж•Ҳең°д»Һ Web зҲ¬еҸ–ж•°жҚ®гҖӮ
жң¬ж–Үдё»иҰҒй’ҲеҜ№е…·жңүдёҖе®ҡ JavaScript з»ҸйӘҢзҡ„зЁӢеәҸе‘ҳгҖӮеҰӮжһңдҪ еҜ№ Web жҠ“еҸ–жңүж·ұеҲ»зҡ„дәҶи§ЈпјҢдҪҶеҜ№ JavaScript 并дёҚзҶҹжӮүпјҢйӮЈд№Ҳжң¬ж–Үд»Қ然иғҪеӨҹеҜ№дҪ жңүжүҖеё®еҠ©гҖӮ
вң… дјҡ JavaScript
вң… дјҡз”Ё DevTools жҸҗеҸ–е…ғзҙ йҖүжӢ©еҷЁ
вң… дјҡдёҖдәӣ ES6 пјҲеҸҜйҖүпјү
йҖҡиҝҮжң¬ж–ҮдҪ е°ҶеӯҰеҲ°пјҡ
еӯҰеҲ°жӣҙеӨҡе…ідәҺ Node.js зҡ„дёңиҘҝ
з”ЁеӨҡдёӘ HTTP е®ўжҲ·з«ҜжқҘеё®еҠ© Web жҠ“еҸ–зҡ„иҝҮзЁӢ
еҲ©з”ЁеӨҡдёӘз»ҸиҝҮе®һи·өиҖғйӘҢиҝҮзҡ„еә“жқҘзҲ¬еҸ– Web
Javascript жҳҜдёҖз§Қз®ҖеҚ•зҡ„зҺ°д»Јзј–зЁӢиҜӯиЁҖпјҢжңҖеҲқжҳҜдёәдәҶеҗ‘жөҸи§ҲеҷЁдёӯзҡ„зҪ‘йЎөж·»еҠ еҠЁжҖҒж•ҲжһңгҖӮеҪ“еҠ иҪҪзҪ‘з«ҷеҗҺпјҢJavascript д»Јз Ғз”ұжөҸи§ҲеҷЁзҡ„ Javascript еј•ж“ҺиҝҗиЎҢгҖӮдёәдәҶдҪҝ Javascript дёҺдҪ зҡ„жөҸи§ҲеҷЁиҝӣиЎҢдәӨдә’пјҢжөҸи§ҲеҷЁиҝҳжҸҗдҫӣдәҶиҝҗиЎҢж—¶зҺҜеўғпјҲdocumentгҖҒwindowзӯүпјүгҖӮ
иҝҷж„Ҹе‘ізқҖ Javascript дёҚиғҪзӣҙжҺҘдёҺи®Ўз®—жңәиө„жәҗдәӨдә’жҲ–еҜ№е…¶иҝӣиЎҢж“ҚдҪңгҖӮдҫӢеҰӮеңЁ Web жңҚеҠЎеҷЁдёӯпјҢжңҚеҠЎеҷЁеҝ…йЎ»иғҪеӨҹдёҺж–Ү件系з»ҹиҝӣиЎҢдәӨдә’пјҢиҝҷж ·жүҚиғҪиҜ»еҶҷж–Ү件гҖӮ
Node.js дҪҝ Javascript дёҚд»…иғҪеӨҹиҝҗиЎҢеңЁе®ўжҲ·з«ҜпјҢиҖҢдё”иҝҳеҸҜд»ҘиҝҗиЎҢеңЁжңҚеҠЎеҷЁз«ҜгҖӮдёәдәҶеҒҡеҲ°иҝҷдёҖзӮ№пјҢе…¶еҲӣе§Ӣдәә Ryan Dahl йҖүжӢ©дәҶGoogle Chrome жөҸи§ҲеҷЁзҡ„ v8 Javascript EngineпјҢ并е°Ҷе…¶еөҢе…ҘеҲ°з”Ё C++ ејҖеҸ‘зҡ„ Node зЁӢеәҸдёӯгҖӮжүҖд»Ҙ Node.js жҳҜдёҖдёӘиҝҗиЎҢж—¶зҺҜеўғпјҢе®ғе…Ғи®ё Javascript д»Јз Ғд№ҹиғҪеңЁжңҚеҠЎеҷЁдёҠиҝҗиЎҢгҖӮ
дёҺе…¶д»–иҜӯиЁҖпјҲдҫӢеҰӮ C жҲ– C++пјүйҖҡиҝҮеӨҡдёӘзәҝзЁӢжқҘеӨ„зҗҶ并еҸ‘жҖ§зӣёеҸҚпјҢNode.js еҲ©з”ЁеҚ•дёӘдё»зәҝзЁӢ并并еңЁдәӢ件еҫӘзҺҜзҡ„её®еҠ©дёӢд»Ҙйқһйҳ»еЎһж–№ејҸжү§иЎҢд»»еҠЎгҖӮ
иҰҒеҲӣе»әдёҖдёӘз®ҖеҚ•зҡ„ Web жңҚеҠЎеҷЁйқһеёёз®ҖеҚ•пјҢеҰӮдёӢжүҖзӨәпјҡ
const http = require('http');
const PORT = 3000;
const server = http.createServer((req, res) => {
res.statusCode = 200;
res.setHeader('Content-Type', 'text/plain');
res.end('Hello World');
});
server.listen(port, () => {
console.log(`Server running at PORT:${port}/`);
});еҰӮжһңдҪ е·Іе®үиЈ…дәҶ Node.jsпјҢеҸҜд»ҘиҜ•зқҖиҝҗиЎҢдёҠйқўзҡ„д»Јз ҒгҖӮ Node.js йқһеёёйҖӮеҗҲ I/O еҜҶйӣҶеһӢзЁӢеәҸгҖӮ
HTTP е®ўжҲ·з«ҜжҳҜиғҪеӨҹе°ҶиҜ·жұӮеҸ‘йҖҒеҲ°жңҚеҠЎеҷЁпјҢ然еҗҺжҺҘ收жңҚеҠЎеҷЁе“Қеә”зҡ„е·Ҙе…·гҖӮдёӢйқўжҸҗеҲ°зҡ„жүҖжңүе·Ҙе…·еә•зҡ„еұӮйғҪжҳҜз”Ё HTTP е®ўжҲ·з«ҜжқҘи®ҝй—®дҪ иҰҒжҠ“еҸ–зҡ„зҪ‘з«ҷгҖӮ
Request жҳҜ Javascript з”ҹжҖҒдёӯдҪҝз”ЁжңҖе№ҝжіӣзҡ„ HTTP е®ўжҲ·з«Ҝд№ӢдёҖпјҢдҪҶжҳҜ Request еә“зҡ„дҪңиҖ…е·ІжӯЈејҸеЈ°жҳҺејғз”ЁдәҶгҖӮдёҚиҝҮиҝҷ并дёҚж„Ҹе‘ізқҖе®ғдёҚеҸҜз”ЁдәҶпјҢзӣёеҪ“еӨҡзҡ„еә“д»ҚеңЁдҪҝз”Ёе®ғпјҢ并且йқһеёёеҘҪз”ЁгҖӮз”Ё Request еҸ‘еҮә HTTP иҜ·жұӮжҳҜйқһеёёз®ҖеҚ•зҡ„пјҡ
const request = require('request')
request('https://www.reddit.com/r/programming.json', function (
error,
response,
body
) {
console.error('error:', error)
console.log('body:', body)
})дҪ еҸҜд»ҘеңЁ Github дёҠжүҫеҲ° Request еә“пјҢе®үиЈ…е®ғйқһеёёз®ҖеҚ•гҖӮдҪ иҝҳеҸҜд»ҘеңЁ https://github.com/request/re... жүҫеҲ°ејғз”ЁйҖҡзҹҘеҸҠе…¶еҗ«д№үгҖӮ
Axios жҳҜеҹәдәҺ promise зҡ„ HTTP е®ўжҲ·з«ҜпјҢеҸҜеңЁжөҸи§ҲеҷЁе’Ң Node.js дёӯиҝҗиЎҢгҖӮеҰӮжһңдҪ з”Ё TypescriptпјҢйӮЈд№Ҳ axios дјҡдёәдҪ иҰҶзӣ–еҶ…зҪ®зұ»еһӢгҖӮйҖҡиҝҮ Axios еҸ‘иө· HTTP иҜ·жұӮйқһеёёз®ҖеҚ•пјҢй»ҳи®Өжғ…еҶөдёӢе®ғеёҰжңү Promise ж”ҜжҢҒпјҢиҖҢдёҚжҳҜеңЁ Request дёӯеҺ»дҪҝз”Ёеӣһи°ғпјҡ
const axios = require('axios')
axios
.get('https://www.reddit.com/r/programming.json')
.then((response) => {
console.log(response)
})
.catch((error) => {
console.error(error)
});еҰӮжһңдҪ е–ңж¬ў Promises API зҡ„ async/await иҜӯжі•зі–пјҢйӮЈд№ҲдҪ д№ҹеҸҜд»Ҙз”ЁпјҢдҪҶжҳҜз”ұдәҺйЎ¶зә§ await д»ҚеӨ„дәҺ stage 3 пјҢжүҖд»ҘжҲ‘们еҸӘеҘҪе…Ҳз”ЁејӮжӯҘеҮҪж•°жқҘд»Јжӣҝпјҡ
async function getForum() {
try {
const response = await axios.get(
'https://www.reddit.com/r/programming.json'
)
console.log(response)
} catch (error) {
console.error(error)
}
}дҪ жүҖиҰҒеҒҡзҡ„е°ұжҳҜи°ғз”Ё getForumпјҒеҸҜд»ҘеңЁ https://github.com/axios/axios дёҠжүҫеҲ°Axiosеә“гҖӮ
дёҺ Axios дёҖж ·пјҢSuperagent жҳҜеҸҰдёҖдёӘејәеӨ§зҡ„ HTTP е®ўжҲ·з«ҜпјҢе®ғж”ҜжҢҒ Promise е’Ң async/await иҜӯжі•зі–гҖӮе®ғе…·жңүеғҸ Axios иҝҷж ·зӣёеҪ“з®ҖеҚ•зҡ„ APIпјҢдҪҶжҳҜ Superagent з”ұдәҺеӯҳеңЁжӣҙеӨҡзҡ„дҫқиө–关系并且дёҚйӮЈд№ҲжөҒиЎҢгҖӮ
з”Ё promiseгҖҒasync/await жҲ–еӣһи°ғеҗ‘ Superagent еҸ‘еҮәHTTPиҜ·жұӮзңӢиө·жқҘеғҸиҝҷж ·пјҡ
const superagent = require("superagent")
const forumURL = "https://www.reddit.com/r/programming.json"
// callbacks
superagent
.get(forumURL)
.end((error, response) => {
console.log(response)
})
// promises
superagent
.get(forumURL)
.then((response) => {
console.log(response)
})
.catch((error) => {
console.error(error)
})
// promises with async/await
async function getForum() {
try {
const response = await superagent.get(forumURL)
console.log(response)
} catch (error) {
console.error(error)
}
}еҸҜд»ҘеңЁ https://github.com/visionmedi... жүҫеҲ° SuperagentгҖӮ
еңЁжІЎжңүд»»дҪ•дҫқиө–жҖ§зҡ„жғ…еҶөдёӢпјҢжңҖз®ҖеҚ•зҡ„иҝӣиЎҢзҪ‘з»ңжҠ“еҸ–зҡ„ж–№жі•жҳҜпјҢдҪҝз”Ё HTTP е®ўжҲ·з«ҜжҹҘиҜўзҪ‘йЎөж—¶пјҢеңЁж”¶еҲ°зҡ„ HTML еӯ—з¬ҰдёІдёҠдҪҝз”ЁдёҖе ҶжӯЈеҲҷиЎЁиҫҫејҸгҖӮжӯЈеҲҷиЎЁиҫҫејҸдёҚйӮЈд№ҲзҒөжҙ»пјҢиҖҢдё”еҫҲеӨҡдё“дёҡдәәеЈ«е’ҢдёҡдҪҷзҲұеҘҪиҖ…йғҪйҡҫд»Ҙзј–еҶҷжӯЈзЎ®зҡ„жӯЈеҲҷиЎЁиҫҫејҸгҖӮ
и®©жҲ‘们иҜ•дёҖиҜ•пјҢеҒҮи®ҫе…¶дёӯжңүдёҖдёӘеёҰжңүз”ЁжҲ·еҗҚзҡ„ж ҮзӯҫпјҢжҲ‘们йңҖиҰҒиҜҘз”ЁжҲ·еҗҚпјҢиҝҷзұ»дјјдәҺдҪ дҫқиө–жӯЈеҲҷиЎЁиҫҫејҸж—¶еҝ…йЎ»жү§иЎҢзҡ„ж“ҚдҪң
const htmlString = '<label>Username: John Doe</label>'
const result = htmlString.match(/<label>(.+)<\/label>/)
console.log(result[1], result[1].split(": ")[1])
// Username: John Doe, John DoeеңЁ Javascript дёӯпјҢmatch() йҖҡеёёиҝ”еӣһдёҖдёӘж•°з»„пјҢиҜҘж•°з»„еҢ…еҗ«дёҺжӯЈеҲҷиЎЁиҫҫејҸеҢ№й…Қзҡ„жүҖжңүеҶ…е®№гҖӮ第дәҢдёӘе…ғзҙ пјҲеңЁзҙўеј•1дёӯпјүе°ҶжүҫеҲ°жҲ‘们жғіиҰҒзҡ„ <label> ж Үи®°зҡ„ textContent жҲ– innerHTMLгҖӮдҪҶжҳҜз»“жһңдёӯеҢ…еҗ«дёҖдәӣдёҚйңҖиҰҒзҡ„ж–Үжң¬пјҲ вҖңUsername: вҖңпјүпјҢеҝ…йЎ»е°Ҷе…¶еҲ йҷӨгҖӮ
еҰӮдҪ жүҖи§ҒпјҢеҜ№дәҺдёҖдёӘйқһеёёз®ҖеҚ•зҡ„з”ЁдҫӢпјҢжӯҘйӘӨе’ҢиҰҒеҒҡзҡ„е·ҘдҪңйғҪеҫҲеӨҡгҖӮиҝҷе°ұжҳҜдёәд»Җд№Ҳеә”иҜҘдҫқиө– HTML и§ЈжһҗеҷЁзҡ„еҺҹеӣ пјҢжҲ‘们е°ҶеңЁеҗҺйқўи®Ёи®әгҖӮ
Cheerio жҳҜдёҖдёӘй«ҳж•ҲиҪ»дҫҝзҡ„еә“пјҢе®ғдҪҝдҪ еҸҜд»ҘеңЁжңҚеҠЎеҷЁз«ҜдҪҝз”Ё JQuery зҡ„дё°еҜҢиҖҢејәеӨ§зҡ„ APIгҖӮеҰӮжһңдҪ д»ҘеүҚз”ЁиҝҮ JQueryпјҢйӮЈд№Ҳе°ҶдјҡеҜ№ Cheerio ж„ҹеҲ°еҫҲзҶҹжӮүпјҢе®ғж¶ҲйҷӨдәҶ DOM жүҖжңүдёҚдёҖиҮҙе’ҢдёҺжөҸи§ҲеҷЁзӣёе…ізҡ„еҠҹиғҪпјҢ并公ејҖдәҶдёҖз§Қжңүж•Ҳзҡ„ API жқҘи§Јжһҗе’Ңж“ҚдҪң DOMгҖӮ
const cheerio = require('cheerio')
const $ = cheerio.load('<h3 class="title">Hello world</h3>')
$('h3.title').text('Hello there!')
$('h3').addClass('welcome')
$.html()
// <h3 class="title welcome">Hello there!</h3>еҰӮдҪ жүҖи§ҒпјҢCheerio дёҺ JQuery з”Ёиө·жқҘйқһеёёзӣёдјјгҖӮ
дҪҶжҳҜпјҢе°Ҫз®Ўе®ғзҡ„е·ҘдҪңж–№ејҸдёҚеҗҢдәҺзҪ‘з»ңжөҸи§ҲеҷЁпјҢд№ҹе°ұиҝҷж„Ҹе‘ізқҖе®ғдёҚиғҪпјҡ
жёІжҹ“д»»дҪ•и§Јжһҗзҡ„жҲ–ж“Қзәө DOM е…ғзҙ
еә”з”Ё CSS жҲ–еҠ иҪҪеӨ–йғЁиө„жәҗ
жү§иЎҢ JavaScript
еӣ жӯӨпјҢеҰӮжһңдҪ е°қиҜ•зҲ¬еҸ–зҡ„зҪ‘з«ҷжҲ– Web еә”з”ЁжҳҜдёҘйҮҚдҫқиө– Javascript зҡ„пјҲдҫӢеҰӮвҖңеҚ•йЎөеә”з”ЁвҖқпјүпјҢйӮЈд№Ҳ Cheerio 并дёҚжҳҜжңҖдҪійҖүжӢ©пјҢдҪ еҸҜиғҪдёҚеҫ—дёҚдҫқиө–зЁҚеҗҺи®Ёи®әзҡ„е…¶д»–йҖүйЎ№гҖӮ
дёәдәҶеұ•зӨә Cheerio зҡ„ејәеӨ§еҠҹиғҪпјҢжҲ‘们е°Ҷе°қиҜ•еңЁ Reddit дёӯжҠ“еҸ– r/programming и®әеқӣпјҢе°қиҜ•иҺ·еҸ–её–еӯҗеҗҚз§°еҲ—иЎЁгҖӮ
йҰ–е…ҲпјҢйҖҡиҝҮиҝҗиЎҢд»ҘдёӢе‘Ҫд»ӨжқҘе®үиЈ… Cheerio е’Ң axiosпјҡnpm install cheerio axiosгҖӮ
然еҗҺеҲӣе»әдёҖдёӘеҗҚдёә crawler.js зҡ„ж–°ж–Ү件пјҢ并еӨҚеҲ¶зІҳиҙҙд»ҘдёӢд»Јз Ғпјҡ
const axios = require('axios');
const cheerio = require('cheerio');
const getPostTitles = async () => {
try {
const { data } = await axios.get(
'https://old.reddit.com/r/programming/'
);
const $ = cheerio.load(data);
const postTitles = [];
$('div > p.title > a').each((_idx, el) => {
const postTitle = $(el).text()
postTitles.push(postTitle)
});
return postTitles;
} catch (error) {
throw error;
}
};
getPostTitles()
.then((postTitles) => console.log(postTitles));getPostTitles() жҳҜдёҖдёӘејӮжӯҘеҮҪж•°пјҢе°ҶеҜ№ж—§зҡ„ reddit зҡ„ r/programming и®әеқӣиҝӣиЎҢзҲ¬еҸ–гҖӮйҰ–е…ҲпјҢз”ЁеёҰжңү axios HTTP е®ўжҲ·з«Ҝеә“зҡ„з®ҖеҚ• HTTP GET иҜ·жұӮиҺ·еҸ–зҪ‘з«ҷзҡ„ HTMLпјҢ然еҗҺз”Ё cheerio.load() еҮҪж•°е°Ҷ html ж•°жҚ®иҫ“е…ҘеҲ° Cheerio дёӯгҖӮ
然еҗҺеңЁжөҸи§ҲеҷЁзҡ„ Dev Tools её®еҠ©дёӢпјҢеҸҜд»ҘиҺ·еҫ—еҸҜд»Ҙе®ҡдҪҚжүҖжңүеҲ—иЎЁйЎ№зҡ„йҖүжӢ©еҷЁгҖӮеҰӮжһңдҪ дҪҝз”ЁиҝҮ JQueryпјҢеҲҷеҝ…йЎ»йқһеёёзҶҹжӮү $('div> p.title> a')гҖӮиҝҷе°Ҷеҫ—еҲ°жүҖжңүеё–еӯҗпјҢеӣ дёәдҪ еҸӘеёҢжңӣеҚ•зӢ¬иҺ·еҸ–жҜҸдёӘеё–еӯҗзҡ„ж ҮйўҳпјҢжүҖд»Ҙеҝ…йЎ»йҒҚеҺҶжҜҸдёӘеё–еӯҗпјҢиҝҷдәӣж“ҚдҪңжҳҜеңЁ each() еҮҪж•°зҡ„её®еҠ©дёӢе®ҢжҲҗзҡ„гҖӮ
иҰҒд»ҺжҜҸдёӘж ҮйўҳдёӯжҸҗеҸ–ж–Үжң¬пјҢеҝ…йЎ»еңЁ Cheerio зҡ„её®еҠ©дёӢиҺ·еҸ– DOMе…ғзҙ пјҲ el жҢҮд»ЈеҪ“еүҚе…ғзҙ пјүгҖӮ然еҗҺеңЁжҜҸдёӘе…ғзҙ дёҠи°ғз”Ё text() иғҪеӨҹдёәдҪ жҸҗдҫӣж–Үжң¬гҖӮ
зҺ°еңЁпјҢжү“ејҖз»Ҳз«Ҝ并иҝҗиЎҢ node crawler.jsпјҢ然еҗҺдҪ е°ҶзңӢеҲ°еӨ§зәҰеӯҳжңүж Үйўҳзҡ„ж•°з»„пјҢе®ғдјҡеҫҲй•ҝгҖӮе°Ҫз®ЎиҝҷжҳҜдёҖдёӘйқһеёёз®ҖеҚ•зҡ„з”ЁдҫӢпјҢдҪҶе®ғеұ•зӨәдәҶ Cheerio жҸҗдҫӣзҡ„ API зҡ„з®ҖеҚ•жҖ§иҙЁгҖӮ
еҰӮжһңдҪ зҡ„з”ЁдҫӢйңҖиҰҒжү§иЎҢ Javascript 并еҠ иҪҪеӨ–йғЁжәҗпјҢйӮЈд№Ҳд»ҘдёӢеҮ дёӘйҖүйЎ№е°ҶеҫҲжңүеё®еҠ©гҖӮ
JSDOM жҳҜеңЁ Node.js дёӯдҪҝз”Ёзҡ„ж–ҮжЎЈеҜ№иұЎжЁЎеһӢзҡ„зәҜ Javascript е®һзҺ°пјҢеҰӮеүҚжүҖиҝ°пјҢDOM еҜ№ Node дёҚеҸҜз”ЁпјҢдҪҶжҳҜ JSDOM жҳҜжңҖжҺҘиҝ‘зҡ„гҖӮе®ғжҲ–еӨҡжҲ–е°‘ең°жЁЎд»ҝдәҶжөҸи§ҲеҷЁгҖӮ
з”ұдәҺеҲӣе»әдәҶ DOMпјҢжүҖд»ҘеҸҜд»ҘйҖҡиҝҮзј–зЁӢдёҺиҰҒзҲ¬еҸ–зҡ„ Web еә”з”ЁжҲ–зҪ‘з«ҷиҝӣиЎҢдәӨдә’пјҢд№ҹеҸҜд»ҘжЁЎжӢҹеҚ•еҮ»жҢүй’®гҖӮеҰӮжһңдҪ зҶҹжӮү DOM ж“ҚдҪңпјҢйӮЈд№ҲдҪҝз”Ё JSDOM е°Ҷдјҡйқһеёёз®ҖеҚ•гҖӮ
const { JSDOM } = require('jsdom')
const { document } = new JSDOM(
'<h3 class="title">Hello world</h3>'
).window
const heading = document.querySelector('.title')
heading.textContent = 'Hello there!'
heading.classList.add('welcome')
heading.innerHTML
// <h3 class="title welcome">Hello there!</h3>д»Јз Ғдёӯз”Ё JSDOM еҲӣе»әдёҖдёӘ DOMпјҢ然еҗҺдҪ еҸҜд»Ҙз”Ёе’Ңж“ҚзәөжөҸи§ҲеҷЁ DOM зӣёеҗҢзҡ„ж–№жі•е’ҢеұһжҖ§жқҘж“ҚзәөиҜҘ DOMгҖӮ
дёәдәҶжј”зӨәеҰӮдҪ•з”Ё JSDOM дёҺзҪ‘з«ҷиҝӣиЎҢдәӨдә’пјҢжҲ‘们е°ҶиҺ·еҫ— Reddit r/programming и®әеқӣзҡ„第дёҖзҜҮеё–еӯҗ并еҜ№е…¶иҝӣиЎҢжҠ•зҘЁпјҢ然еҗҺйӘҢиҜҒиҜҘеё–еӯҗжҳҜеҗҰе·Іиў«жҠ•зҘЁгҖӮ
йҰ–е…ҲиҝҗиЎҢд»ҘдёӢе‘Ҫд»ӨжқҘе®үиЈ… jsdom е’Ң axiosпјҡnpm install jsdom axios
然еҗҺеҲӣе»әеҗҚдёә crawler.jsзҡ„ж–Ү件пјҢ并еӨҚеҲ¶зІҳиҙҙд»ҘдёӢд»Јз Ғпјҡ
const { JSDOM } = require("jsdom")
const axios = require('axios')
const upvoteFirstPost = async () => {
try {
const { data } = await axios.get("https://old.reddit.com/r/programming/");
const dom = new JSDOM(data, {
runScripts: "dangerously",
resources: "usable"
});
const { document } = dom.window;
const firstPost = document.querySelector("div > div.midcol > div.arrow");
firstPost.click();
const isUpvoted = firstPost.classList.contains("upmod");
const msg = isUpvoted
? "Post has been upvoted successfully!"
: "The post has not been upvoted!";
return msg;
} catch (error) {
throw error;
}
};
upvoteFirstPost().then(msg => console.log(msg));upvoteFirstPost() жҳҜдёҖдёӘејӮжӯҘеҮҪж•°пјҢе®ғе°ҶеңЁ r/programming дёӯиҺ·еҸ–第дёҖдёӘеё–еӯҗпјҢ然еҗҺеҜ№е…¶иҝӣиЎҢжҠ•зҘЁгҖӮaxios еҸ‘йҖҒ HTTP GET иҜ·жұӮиҺ·еҸ–жҢҮе®ҡ URL зҡ„HTMLгҖӮ然еҗҺйҖҡиҝҮе…ҲеүҚиҺ·еҸ–зҡ„ HTML жқҘеҲӣе»әж–°зҡ„ DOMгҖӮ JSDOM жһ„йҖ еҮҪж•°жҠҠHTML дҪңдёә第дёҖдёӘеҸӮж•°пјҢжҠҠ option дҪңдёә第дәҢдёӘеҸӮж•°пјҢе·Іж·»еҠ зҡ„ 2 дёӘ option йЎ№жү§иЎҢд»ҘдёӢеҠҹиғҪпјҡ
runScriptsпјҡи®ҫзҪ®дёә dangerously ж—¶е…Ғи®ёжү§иЎҢдәӢ件 handler е’Ңд»»дҪ• Javascript д»Јз ҒгҖӮеҰӮжһңдҪ дёҚжё…жҘҡе°ҶиҰҒиҝҗиЎҢзҡ„и„ҡжң¬зҡ„е®үе…ЁжҖ§пјҢеҲҷжңҖеҘҪе°Ҷ runScripts и®ҫзҪ®дёәвҖңoutside-onlyвҖқпјҢиҝҷдјҡжҠҠжүҖжңүжҸҗдҫӣзҡ„ Javascript 规иҢғйҷ„еҠ еҲ° вҖңwindowвҖқ еҜ№иұЎпјҢд»ҺиҖҢйҳ»жӯўеңЁ inside дёҠжү§иЎҢзҡ„д»»дҪ•и„ҡжң¬гҖӮ
resourcesпјҡи®ҫзҪ®дёәвҖңusableвҖқж—¶пјҢе…Ғи®ёеҠ иҪҪз”Ё <script> ж Үи®°еЈ°жҳҺзҡ„д»»дҪ•еӨ–йғЁи„ҡжң¬пјҲдҫӢеҰӮпјҡд»Һ CDN жҸҗеҸ–зҡ„ JQuery еә“пјү
еҲӣе»ә DOM еҗҺпјҢз”ЁзӣёеҗҢзҡ„ DOM ж–№жі•еҫ—еҲ°з¬¬дёҖзҜҮж–Үз« зҡ„ upvote жҢүй’®пјҢ然еҗҺеҚ•еҮ»гҖӮиҰҒйӘҢиҜҒжҳҜеҗҰзЎ®е®һеҚ•еҮ»дәҶе®ғпјҢеҸҜд»ҘжЈҖжҹҘ classList дёӯжҳҜеҗҰжңүдёҖдёӘеҗҚдёә upmod зҡ„зұ»гҖӮеҰӮжһңеӯҳеңЁдәҺ classList дёӯпјҢеҲҷиҝ”еӣһдёҖжқЎж¶ҲжҒҜгҖӮ
жү“ејҖз»Ҳз«Ҝ并иҝҗиЎҢ node crawler.jsпјҢ然еҗҺдјҡзңӢеҲ°дёҖдёӘж•ҙжҙҒзҡ„еӯ—з¬ҰдёІпјҢиҜҘеӯ—з¬ҰдёІе°ҶиЎЁжҳҺеё–еӯҗжҳҜеҗҰиў«иөһиҝҮгҖӮе°Ҫз®ЎиҝҷдёӘдҫӢеӯҗеҫҲз®ҖеҚ•пјҢдҪҶдҪ еҸҜд»ҘеңЁиҝҷдёӘеҹәзЎҖдёҠжһ„е»әеҠҹиғҪејәеӨ§зҡ„дёңиҘҝпјҢдҫӢеҰӮпјҢдёҖдёӘеӣҙз»•зү№е®ҡз”ЁжҲ·зҡ„её–еӯҗиҝӣиЎҢжҠ•зҘЁзҡ„жңәеҷЁдәәгҖӮ
еҰӮжһңдҪ дёҚе–ңж¬ўзјәд№ҸиЎЁиҫҫиғҪеҠӣзҡ„ JSDOM пјҢ并且е®һи·өдёӯиҰҒдҫқиө–дәҺи®ёеӨҡжӯӨзұ»ж“ҚдҪңпјҢжҲ–иҖ…йңҖиҰҒйҮҚж–°еҲӣе»әи®ёеӨҡдёҚеҗҢзҡ„ DOMпјҢйӮЈд№ҲдёӢйқўе°ҶжҳҜжӣҙеҘҪзҡ„йҖүжӢ©гҖӮ
йЎҫеҗҚжҖқд№үпјҢPuppeteer е…Ғи®ёдҪ д»Ҙзј–зЁӢж–№ејҸж“ҚзәөжөҸи§ҲеҷЁпјҢе°ұеғҸж“ҚзәөжңЁеҒ¶дёҖж ·гҖӮе®ғйҖҡиҝҮдёәејҖеҸ‘дәәе‘ҳжҸҗдҫӣй«ҳзә§ API жқҘй»ҳи®ӨжҺ§еҲ¶ж— еӨҙзүҲжң¬зҡ„ ChromeгҖӮ
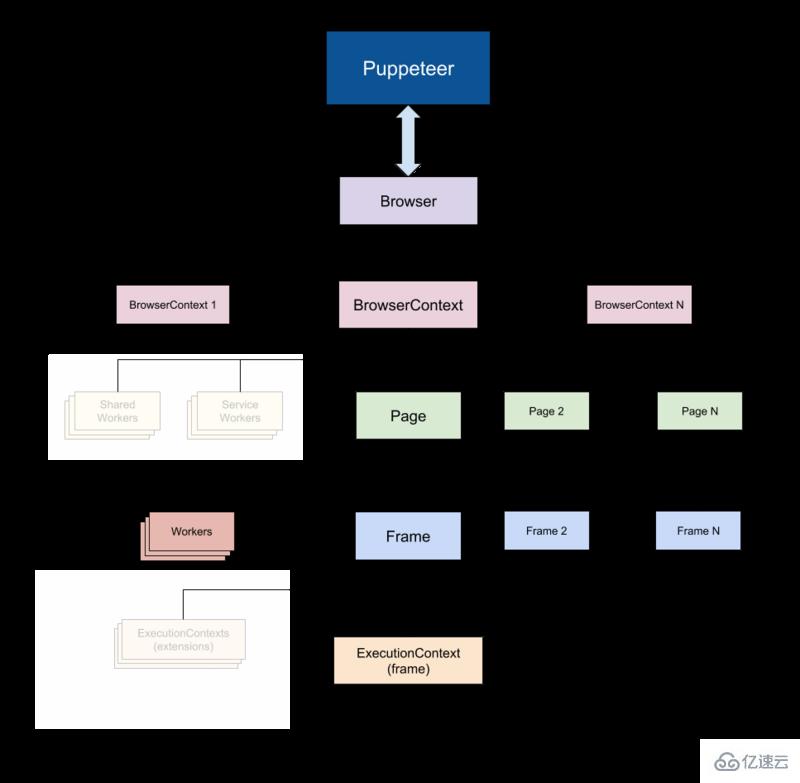
Puppeteer жҜ”дёҠиҝ°е·Ҙе…·жӣҙжңүз”ЁпјҢеӣ дёәе®ғеҸҜд»ҘдҪҝдҪ еғҸзңҹжӯЈзҡ„дәәеңЁдёҺжөҸи§ҲеҷЁиҝӣиЎҢдәӨдә’дёҖж ·еҜ№зҪ‘з»ңиҝӣиЎҢзҲ¬еҸ–гҖӮиҝҷе°ұе…·еӨҮдәҶдёҖдәӣд»ҘеүҚжІЎжңүзҡ„еҸҜиғҪжҖ§пјҡ
дҪ еҸҜд»ҘиҺ·еҸ–еұҸ幕жҲӘеӣҫжҲ–з”ҹжҲҗйЎөйқў PDFгҖӮ
еҸҜд»ҘжҠ“еҸ–еҚ•йЎөеә”用并з”ҹжҲҗйў„жёІжҹ“зҡ„еҶ…е®№гҖӮ
иҮӘеҠЁжү§иЎҢи®ёеӨҡдёҚеҗҢзҡ„з”ЁжҲ·дәӨдә’пјҢдҫӢеҰӮй”®зӣҳиҫ“е…ҘгҖҒиЎЁеҚ•жҸҗдәӨгҖҒеҜјиҲӘзӯүгҖӮ
е®ғиҝҳеҸҜд»ҘеңЁ Web зҲ¬еҸ–д№ӢеӨ–зҡ„е…¶д»–д»»еҠЎдёӯеҸ‘жҢҘйҮҚиҰҒдҪңз”ЁпјҢдҫӢеҰӮ UI жөӢиҜ•гҖҒиҫ…еҠ©жҖ§иғҪдјҳеҢ–зӯүгҖӮ
йҖҡеёёдҪ дјҡжғіиҰҒжҲӘеҸ–зҪ‘з«ҷзҡ„еұҸ幕жҲӘеӣҫпјҢд№ҹи®ёжҳҜдёәдәҶдәҶи§Јз«һдәүеҜ№жүӢзҡ„дә§е“Ғзӣ®еҪ•пјҢеҸҜд»Ҙз”Ё puppeteer жқҘеҒҡеҲ°гҖӮйҰ–е…ҲиҝҗиЎҢд»ҘдёӢе‘Ҫд»Өе®үиЈ… puppeteerпјҢпјҡnpm install puppeteer
иҝҷе°ҶдёӢиҪҪ Chromium зҡ„ bundle зүҲжң¬пјҢж №жҚ®ж“ҚдҪңзі»з»ҹзҡ„дёҚеҗҢпјҢиҜҘзүҲжң¬еӨ§зәҰ 180 MB иҮі 300 MBгҖӮеҰӮжһңдҪ иҰҒзҰҒз”ЁжӯӨеҠҹиғҪгҖӮ
и®©жҲ‘们е°қиҜ•еңЁ Reddit дёӯиҺ·еҸ– r/programming и®әеқӣзҡ„еұҸ幕жҲӘеӣҫе’Ң PDFпјҢеҲӣе»әдёҖдёӘеҗҚдёә crawler.jsзҡ„ж–°ж–Ү件пјҢ然еҗҺеӨҚеҲ¶зІҳиҙҙд»ҘдёӢд»Јз Ғпјҡ
const puppeteer = require('puppeteer')
async function getVisual() {
try {
const URL = 'https://www.reddit.com/r/programming/'
const browser = await puppeteer.launch()
const page = await browser.newPage()
await page.goto(URL)
await page.screenshot({ path: 'screenshot.png' })
await page.pdf({ path: 'page.pdf' })
await browser.close()
} catch (error) {
console.error(error)
}
}
getVisual()getVisual() жҳҜдёҖдёӘејӮжӯҘеҮҪж•°пјҢе®ғе°ҶиҺ· URL еҸҳйҮҸдёӯ url еҜ№еә”зҡ„еұҸ幕жҲӘеӣҫе’Ң pdfгҖӮйҰ–е…ҲпјҢйҖҡиҝҮ puppeteer.launch() еҲӣе»әжөҸи§ҲеҷЁе®һдҫӢпјҢ然еҗҺеҲӣе»әдёҖдёӘж–°йЎөйқўгҖӮеҸҜд»Ҙе°ҶиҜҘйЎөйқўи§Ҷдёә常规жөҸи§ҲеҷЁдёӯзҡ„йҖүйЎ№еҚЎгҖӮ然еҗҺйҖҡиҝҮд»Ҙ URL дёәеҸӮж•°и°ғз”Ё page.goto() пјҢе°Ҷе…ҲеүҚеҲӣе»әзҡ„йЎөйқўе®ҡеҗ‘еҲ°жҢҮе®ҡзҡ„ URLгҖӮжңҖз»ҲпјҢжөҸи§ҲеҷЁе®һдҫӢдёҺйЎөйқўдёҖиө·иў«й”ҖжҜҒгҖӮ
е®ҢжҲҗж“ҚдҪң并е®ҢжҲҗйЎөйқўеҠ иҪҪеҗҺпјҢе°ҶеҲҶеҲ«дҪҝз”Ё page.screenshot() е’Ң page.pdf() иҺ·еҸ–еұҸ幕жҲӘеӣҫе’Ң pdfгҖӮдҪ д№ҹеҸҜд»ҘдҫҰеҗ¬ javascript load дәӢ件пјҢ然еҗҺжү§иЎҢиҝҷдәӣж“ҚдҪңпјҢеңЁз”ҹдә§зҺҜеўғзә§еҲ«дёӢејәзғҲе»әи®®иҝҷж ·еҒҡгҖӮ
еңЁз»Ҳз«ҜдёҠиҝҗиЎҢ node crawler.js пјҢеҮ з§’й’ҹеҗҺпјҢдҪ дјҡжіЁж„ҸеҲ°е·Із»ҸеҲӣе»әдәҶдёӨдёӘж–Ү件пјҢеҲҶеҲ«еҗҚдёә screenshot.jpg е’Ң page.pdfгҖӮ
Nightmare жҳҜзұ»дјј Puppeteer зҡ„й«ҳзә§жөҸи§ҲеҷЁиҮӘеҠЁеҢ–еә“пјҢиҜҘеә“дҪҝз”Ё ElectronпјҢдҪҶжҚ®иҜҙйҖҹеәҰжҳҜе…¶еүҚиә« PhantomJS зҡ„дёӨеҖҚгҖӮ
еҰӮжһңдҪ еңЁжҹҗз§ҚзЁӢеәҰдёҠдёҚе–ңж¬ў Puppeteer жҲ–еҜ№ Chromium жҚҶз»‘еҢ…зҡ„еӨ§е°Ҹж„ҹеҲ°жІ®дё§пјҢйӮЈд№Ҳ nightmare жҳҜдёҖдёӘзҗҶжғізҡ„йҖүжӢ©гҖӮйҰ–е…ҲпјҢиҝҗиЎҢд»ҘдёӢе‘Ҫд»Өе®үиЈ… nightmare еә“пјҡnpm install nightmare
然еҗҺпјҢдёҖж—ҰдёӢиҪҪдәҶ nightmareпјҢжҲ‘们е°Ҷз”Ёе®ғйҖҡиҝҮ Google жҗңзҙўеј•ж“ҺжүҫеҲ° ScrapingBee зҡ„зҪ‘з«ҷгҖӮеҲӣе»әдёҖдёӘеҗҚдёәcrawler.jsзҡ„ж–Ү件пјҢ然еҗҺе°Ҷд»ҘдёӢд»Јз ҒеӨҚеҲ¶зІҳиҙҙеҲ°е…¶дёӯпјҡ
const Nightmare = require('nightmare')
const nightmare = Nightmare()
nightmare
.goto('https://www.google.com/')
.type("input[title='Search']", 'ScrapingBee')
.click("input[value='Google Search']")
.wait('#rso > div:nth-child(1) > div > div > div.r > a')
.evaluate(
() =>
document.querySelector(
'#rso > div:nth-child(1) > div > div > div.r > a'
).href
)
.end()
.then((link) => {
console.log('Scraping Bee Web Link': link)
})
.catch((error) => {
console.error('Search failed:', error)
})йҰ–е…ҲеҲӣе»әдёҖдёӘ Nighmare е®һдҫӢпјҢ然еҗҺйҖҡиҝҮи°ғз”Ё goto() е°ҶиҜҘе®һдҫӢе®ҡеҗ‘еҲ° Google жҗңзҙўеј•ж“ҺпјҢеҠ иҪҪеҗҺпјҢдҪҝз”Ёе…¶йҖүжӢ©еҷЁиҺ·еҸ–жҗңзҙўжЎҶпјҢ然еҗҺдҪҝз”ЁжҗңзҙўжЎҶзҡ„еҖјпјҲиҫ“е…Ҙж Үзӯҫпјүжӣҙж”№дёәвҖңScrapingBeeвҖқгҖӮе®ҢжҲҗеҗҺпјҢйҖҡиҝҮеҚ•еҮ» вҖңGoogleжҗңзҙўвҖқ жҢүй’®жҸҗдәӨжҗңзҙўиЎЁеҚ•гҖӮ然еҗҺе‘ҠиҜү Nightmare зӯүеҲ°з¬¬дёҖдёӘй“ҫжҺҘеҠ иҪҪе®ҢжҜ•пјҢдёҖж—Ұе®ҢжҲҗпјҢе®ғе°ҶдҪҝз”Ё DOM ж–№жі•жқҘиҺ·еҸ–еҢ…еҗ«иҜҘй“ҫжҺҘзҡ„е®ҡдҪҚж Үи®°зҡ„ href еұһжҖ§зҡ„еҖјгҖӮ
жңҖеҗҺпјҢе®ҢжҲҗжүҖжңүж“ҚдҪңеҗҺпјҢй“ҫжҺҘе°Ҷжү“еҚ°еҲ°жҺ§еҲ¶еҸ°гҖӮ
вң… Node.js жҳҜ Javascript еңЁжңҚеҠЎеҷЁз«Ҝзҡ„иҝҗиЎҢж—¶зҺҜеўғгҖӮз”ұдәҺдәӢ件еҫӘзҺҜжңәеҲ¶пјҢе®ғе…·жңүвҖңйқһйҳ»еЎһвҖқжҖ§иҙЁгҖӮ
вң… HTTPе®ўжҲ·з«ҜпјҲдҫӢеҰӮ AxiosгҖҒSuperagent е’Ң Requestпјүз”ЁдәҺе°Ҷ HTTP иҜ·жұӮеҸ‘йҖҒеҲ°жңҚеҠЎеҷЁе№¶жҺҘ收е“Қеә”гҖӮ
вң… Cheerio жҠҠ JQuery зҡ„дјҳзӮ№жҠҪеҮәжқҘпјҢеңЁжңҚеҠЎеҷЁз«Ҝ иҝӣиЎҢ Web зҲ¬еҸ–жҳҜе”ҜдёҖзҡ„зӣ®зҡ„пјҢдҪҶдёҚжү§иЎҢ Javascript д»Јз ҒгҖӮ
вң… JSDOM ж №жҚ®ж ҮеҮҶ Javascript规иҢғ д»Һ HTML еӯ—з¬ҰдёІдёӯеҲӣе»әдёҖдёӘ DOMпјҢ并е…Ғи®ёдҪ еҜ№е…¶жү§иЎҢDOMж“ҚдҪңгҖӮ
вң… Puppeteer and Nightmare жҳҜй«ҳзә§пјҲhigh-level пјүжөҸи§ҲеҷЁиҮӘеҠЁеҢ–еә“пјҢеҸҜи®©дҪ д»Ҙзј–зЁӢж–№ејҸеҺ»ж“ҚдҪң Web еә”з”ЁпјҢе°ұеғҸзңҹе®һзҡ„дәәжӯЈеңЁдёҺд№ӢдәӨдә’дёҖж ·гҖӮ
д»ҘдёҠжҳҜвҖңеҰӮдҪ•дҪҝз”ЁNode.jsй«ҳж•Ҳең°д»ҺWebзҲ¬еҸ–ж•°жҚ®вҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢжӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ