жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
ж‘ҳиҰҒ
еҰӮжһңиҰҒжғізңҹжӯЈзҡ„жҺҢжҸЎsparkSQLзј–зЁӢпјҢйҰ–е…ҲиҰҒеҜ№sparkSQLзҡ„ж•ҙдҪ“жЎҶжһ¶д»ҘеҸҠsparkSQLеҲ°еә•иғҪеё®еҠ©жҲ‘们解еҶід»Җд№Ҳй—®йўҳжңүдёҖдёӘж•ҙдҪ“зҡ„и®ӨиҜҶпјҢ然еҗҺе°ұжҳҜеҜ№еҗ„дёӘеұӮзә§е…ізі»жңүдёҖдёӘжё…жҷ°зҡ„и®ӨиҜҶеҗҺпјҢжүҚиғҪзңҹжӯЈзҡ„жҺҢжҸЎе®ғпјҢеҜ№дәҺsparkSQLж•ҙдҪ“жЎҶжһ¶иҝҷдёҖеқ—пјҢеңЁеүҚдёҖдёӘеҚҡе®ўе·Із»ҸиҝӣиЎҢиҝҮдәҶдёҖдәӣд»Ӣз»ҚпјҢеҰӮжһңеҜ№иҝҷеқ—иҝҳжңүз–‘й—®еҸҜд»ҘзңӢжҲ‘еүҚдёҖдёӘеҚҡе®ўпјҡhttp://9269309.blog.51cto.com/9259309/1845525гҖӮжң¬зҜҮеҚҡе®ўдё»иҰҒжҳҜеҜ№sparkSQLе®һжҲҳиҝӣиЎҢи®Іи§Је’ҢжҖ»з»“пјҢиҖҢдёҚжҳҜеҜ№sparkSQLжәҗз Ғзҡ„и®Іи§ЈпјҢеҰӮжһңжғізңӢжәҗз Ғзҡ„иҜ·з»•йҒ“гҖӮ
еҶҚеӨҡиҜҙдёҖзӮ№пјҢеҜ№дәҺеҲқеӯҰиҖ…пјҢжң¬дәәеқҡжҢҒзҡ„и§ӮзӮ№жҳҜдёҚиҰҒдёҖдёҠжқҘе°ұзңӢжәҗз ҒпјҢиҝҷж ·зҡ„ж•ҲжһңдёҚжҳҜеҫҲеӨ§пјҢиҝҳжөӘиҙ№ж—¶й—ҙпјҢеҜ№иҝҷдёӘдёңиҘҝиҝҳжІЎжңүеӨ§иҮҙжҺҢжҸЎпјҢиҝҳдёҚзҹҘйҒ“е®ғжҳҜе№Ід»Җд№Ҳзҡ„пјҢдёҠжқҘе°ұзңӢжәҗз ҒпјҢй—Ёж§ӣеӨӘй«ҳпјҢиҖҢдё”зңӢжәҗз ҒеҜ№дёӘдәәзҡ„жҸҗеҚҮд№ҹдёҚжҳҜеҫҲй«ҳгҖӮжҲ‘们еҒҡиҪҜ件ејҖеҸ‘зҡ„пјҢжҲ‘们ејҖеҸ‘зҡ„йЎәеәҸд№ҹжҳҜпјҢйҰ–е…ҲжҳҜйңҖжұӮпјҢеҜ№йңҖжұӮжңүдәҶиҜҰз»Ҷзҡ„и®ӨиҜҶпјҢйңҖиҰҒи§ЈеҶід»Җд№Ҳй—®йўҳпјҢ然еҗҺжүҚжҳҜиҪҜ件зҡ„и®ҫи®ЎпјҢд»Јз Ғзҡ„зј–еҶҷгҖӮеҗҢж ·пјҢеӯҰд№ жЎҶжһ¶д№ҹжҳҜпјҢжҲ‘们еҸӘжңүеҜ№иҝҷдёӘжЎҶжһ¶зҡ„йңҖжұӮпјҢе®ғйңҖиҰҒи§ЈеҶід»Җд№Ҳй—®йўҳпјҢе®ғйңҖиҰҒе№Ід»Җд№Ҳе·ҘдҪңпјҢйғҪйқһеёёдәҶи§ЈдәҶпјҢ然еҗҺеҶҚзңӢжәҗз ҒпјҢиҝҷж ·ж•ҲжһңжүҚиғҪеҫ—еҲ°еҫҲеӨ§зҡ„жҸҗеҚҮгҖӮеҜ№дәҺйҳ…иҜ»жәҗд»Јз ҒиҝҷдёҖеқ—пјҢжҳҜжң¬дәәзҡ„дёҖзӮ№зңӢжі•пјҢиҜҙзҡ„еҜ№дёҺй”ҷпјҢж¬ўиҝҺеҗҗж§Ҫ ......пјҒ
......пјҒ
1гҖҒsparkSQLеұӮзә§
еҪ“жҲ‘们жғіз”ЁsparkSQLжқҘи§ЈеҶіжҲ‘们зҡ„йңҖжұӮж—¶пјҢе…¶е®һиҜҙз®ҖеҚ•д№ҹз®ҖеҚ•пјҢе°ұз»ҸеҺҶдәҶдёүжӯҘпјҡиҜ»е…Ҙж•°жҚ® -> еҜ№ж•°жҚ®иҝӣиЎҢеӨ„зҗҶ -> еҶҷе…ҘжңҖеҗҺз»“жһңпјҢйӮЈд№ҲиҝҷдёүдёӘжӯҘйӘӨз”Ёзҡ„дё»иҰҒзұ»е…¶е®һе°ұдёүдёӘпјҡиҜ»е…Ҙж•°жҚ®е’ҢеҶҷе…ҘжңҖеҗҺз»“жһңз”ЁеҲ°дёӨдёӘзұ»HiveContextе’ҢSQLContextпјҢеҜ№ж•°жҚ®иҝӣиЎҢеӨ„зҗҶз”ЁеҲ°зҡ„жҳҜDataFrameзұ»пјҢжӯӨзұ»жҳҜдҪ жҠҠж•°жҚ®д»ҺеӨ–йғЁиҜ»е…ҘеҲ°еҶ…еӯҳеҗҺпјҢж•°жҚ®еңЁеҶ…еӯҳдёӯиҝӣиЎҢеӯҳеӮЁзҡ„еҹәжң¬ж•°жҚ®з»“жһ„пјҢеңЁеҜ№ж•°жҚ®иҝӣиЎҢеӨ„зҗҶж—¶иҝҳдјҡз”ЁеҲ°дёҖдәӣдёӯй—ҙзұ»пјҢз”ЁеҲ°ж—¶еңЁиҝӣиЎҢи®Іи§ЈгҖӮеҰӮдёӢеӣҫжүҖзӨәпјҡ
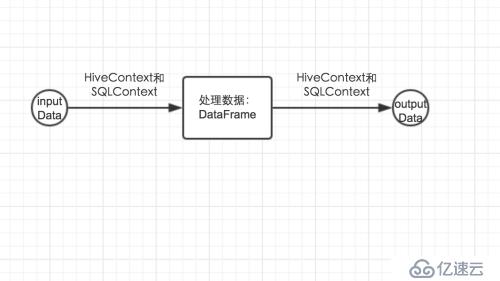
2гҖҒHiveContextе’ҢSQLContext
жҠҠHiveContextе’ҢSQLContextж”ҫеңЁдёҖиө·и®Іи§ЈжҳҜеӣ дёә他们жҳҜе·®дёҚеӨҡзҡ„пјҢеӣ дёәHiveContext继жүҝиҮӘSQLContextпјҢдёәд»Җд№ҲдјҡжңүдёӨдёӘиҝҷж ·зҡ„зұ»пјҢе…¶е®һдёҺhiveе’Ңsqlжңүе…ізі»зҡ„пјҢиҷҪ然hiveжӢҘжңүHQLиҜӯиЁҖпјҢдҪҶжҳҜе®ғжҳҜдёҖдёӘзұ»sqlиҜӯиЁҖпјҢе’ҢsqlиҜӯиЁҖиҝҳжҳҜжңүе·®еҲ«зҡ„пјҢжңүдәӣsqlиҜӯжі•пјҢHQLжҳҜдёҚж”ҜжҢҒзҡ„гҖӮжүҖд»Ҙ他们иҝҳжҳҜжңүе·®еҲ«зҡ„гҖӮйҖүжӢ©дёҚеҗҢзҡ„зұ»пјҢжңҖеҗҺжү§иЎҢзҡ„жҹҘиҜўеј•ж“Һзҡ„й©ұеҠЁжҳҜдёҚдёҖж ·зҡ„гҖӮдҪҶжҳҜеҜ№дәҺеә•еұӮжҳҜжҖҺд№ҲеҢәеҲ«зҡ„иҝҷйҮҢдёҚеҒҡиҜҰз»Ҷзҡ„д»Ӣз»ҚпјҢдҪ е°ұзҹҘйҒ“дёҖзӮ№пјҢдҪҝз”ЁдёҚеҗҢзҡ„иҜ»ж•°жҚ®зҡ„зұ»пјҢеә•еұӮдјҡиҝӣиЎҢж Үи®°пјҢиҮӘеҠЁиҜҶеҲ«жҳҜдҪҝз”Ёе“ӘдёӘзұ»иҝӣиЎҢж•°жҚ®ж“ҚдҪңпјҢ然еҗҺйҮҮз”ЁдёҚеҗҢзҡ„жү§иЎҢи®ЎеҲ’жү§иЎҢж“ҚдҪңпјҢиҝҷзӮ№еңЁдёҠдёҖзҜҮsparkSQLж•ҙдҪ“жЎҶжһ¶дёӯиҝӣиЎҢдәҶд»Ӣз»ҚпјҢиҝҷйҮҢдёҚеҒҡд»Ӣз»ҚгҖӮеҪ“д»Һhiveеә“дёӯиҜ»ж•°жҚ®зҡ„ж—¶еҖҷпјҢеҝ…йЎ»дҪҝз”ЁHiveContextжқҘиҝӣиЎҢиҜ»еҸ–ж•°жҚ®пјҢдёҚ然еңЁиҝӣиЎҢжҹҘиҜўзҡ„ж—¶еҖҷдјҡеҮәдёҖдәӣеҘҮжҖӘзҡ„й”ҷгҖӮе…¶д»–зҡ„ж•°жҚ®жәҗдёӨиҖ…йғҪеҸҜд»ҘйҖүжӢ©пјҢдҪҶжҳҜжңҖеҘҪдҪҝз”ЁSQLContextжқҘе®ҢжҲҗгҖӮеӣ дёәе…¶ж”ҜжҢҒзҡ„sqlиҜӯжі•жӣҙеӨҡгҖӮз”ұдәҺHiveContextжҳҜ继жүҝиҮӘSQLContextпјҢиҝҷйҮҢеҸӘеҜ№SQLContextиҝӣиЎҢиҜҰз»Ҷзҡ„д»Ӣз»ҚпјҢдҪҶжҳҜд»ҘдёӢиҝҷдәӣж–№жі•жҳҜе®Ңе…ЁеҸҜд»Ҙз”ЁеңЁHiveContextдёӯзҡ„гҖӮе…¶е®һHiveContextзұ»е°ұжү©еұ•дәҶSQLContextзҡ„дёӨдёӘжҲ‘们еҸҜд»ҘдҪҝз”Ёзҡ„ж–№жі•(еңЁзңӢжәҗз Ғж—¶д»Ҙprotectedе’ҢprivateејҖеӨҙзҡ„ж–№жі•йғҪжҳҜжҲ‘们дёҚиғҪдҪҝз”Ёзҡ„пјҢиҝҷдёӘжҳҜscalaзҡ„жҺ§еҲ¶йҖ»иҫ‘пјҢзӣёеҸҚпјҢдёҚжҳҜд»ҘиҝҷдёӨдёӘе…ій”®еӯ—ж Үи®°зҡ„ж–№жі•жҳҜжҲ‘们еҸҜд»ҘзӣҙжҺҘдҪҝз”Ёзҡ„ж–№жі•)пјҡanalyze(tableName:String)е’ҢrefreshTable(tableName:String)гҖӮ
| ж–№жі• | з”ЁйҖ” |
| analyzeж–№жі• | иҝҷдёӘжҲ‘们дёҖиҲ¬дҪҝз”ЁдёҚеҲ°пјҢе®ғжҳҜжқҘеҜ№жҲ‘们еҶҷзҡ„sqlжҹҘиҜўиҜӯеҸҘиҝӣиЎҢеҲҶжһҗз”Ёзҡ„пјҢдёҖиҲ¬з”ЁдёҚеҲ°гҖӮ |
| refreshTableж–№жі• | еҪ“жҲ‘们еңЁsparkSQLдёӯеӨ„зҗҶзҡ„жҹҗдёӘиЎЁзҡ„еӯҳеӮЁдҪҚзҪ®еҸ‘з”ҹдәҶеҸҳжҚўпјҢдҪҶжҳҜжҲ‘们еңЁеҶ…еӯҳзҡ„metaDataдёӯзј“еӯҳ(cache)дәҶиҝҷеј иЎЁпјҢеҲҷйңҖиҰҒи°ғз”ЁиҝҷдёӘж–№жі•жқҘдҪҝиҝҷдёӘзј“еӯҳж— ж•ҲпјҢйңҖиҰҒйҮҚж–°еҠ иҪҪгҖӮ |
2.1 иҜ»ж•°жҚ®
жҲ‘们еңЁи§ЈеҶіжҲ‘们зҡ„йңҖжұӮж—¶пјҢйҰ–е…ҲжҳҜиҜ»е…Ҙж•°жҚ®пјҢйңҖиҰҒжҠҠж•°жҚ®иҜ»е…ҘеҲ°еҶ…еӯҳдёӯеҺ»пјҢиҜ»ж•°жҚ®SQLContextжҸҗдҫӣдәҶдёӨдёӘж–№жі•пјҢжҲ‘们жҸҗдҫӣдёӨдёӘж•°жҚ®иЎЁпјҢдёәдәҶдҫҝдәҺжј”зӨәпјҢжҲ‘йҮҮз”Ёзҡ„жҳҜз”ЁJSONж јејҸиҝӣиЎҢеӯҳеӮЁзҡ„пјҢеҶҷжҲҗиҝҷж ·зҡ„ж јејҸпјҢдҪҶжҳҜеҸҜд»Ҙдҝқеӯҳдёә.txtж јејҸзҡ„ж–Ү件гҖӮ

1гҖҒ第дёҖз§Қж•°жҚ®иҜ»е…Ҙпјҡиҝҷз§ҚжҳҜеҜ№ж•°жҚ®жәҗж–Ү件иҝӣиЎҢж“ҚдҪңгҖӮ
import org.apache.spark.sql.SQLContext
val sql = new SQLContext(sc) //еЈ°жҳҺдёҖдёӘSQLContextзҡ„еҜ№иұЎпјҢд»ҘдҫҝеҜ№ж•°жҚ®иҝӣиЎҢж“ҚдҪң
val peopleInfo = sql.read.json("ж–Ү件и·Ҝеҫ„")
//е…¶дёӯpeopleInfoиҝ”еӣһзҡ„з»“жһңжҳҜпјҡorg.apache.spark.sql.DataFrame =
// [age: bigint, id: bigint, name: string],иҝҷж ·е°ұжҠҠж•°жҚ®иҜ»е…ҘеҲ°еҶ…еӯҳдёӯдәҶеҶҷдәҶиҝҷеҮ иЎҢд»Јз ҒеҗҺйқўжҖ»е…ұеҸ‘з”ҹдәҶд»Җд№ҲпјҢйҰ–е…ҲsparkSQLе…ҲжүҫеҲ°ж–Ү件пјҢд»Ҙи§Јжһҗjsonзҡ„еҪўејҸиҝӣиЎҢи§ЈжһҗпјҢеҗҢж—¶йҖҡиҝҮjsonзҡ„keyеҪўжҲҗschemaпјҢscheamзҡ„еӯ—ж®өзҡ„йЎәеәҸдёҚжҳҜжҢүз…§жҲ‘们иҜ»е…Ҙж•°жҚ®ж—¶жңҹй»ҳи®Өзҡ„йЎәеәҸпјҢеҰӮдёҠпјҢе…¶еӯ—ж®өзҡ„йЎәеәҸжҳҜйҖҡиҝҮеӯ—з¬ҰдёІзҡ„йЎәеәҸиҝӣиЎҢйҮҚж–°з»„з»Үзҡ„гҖӮй»ҳи®Өжғ…еҶөдёӢпјҢдјҡжҠҠж•ҙж•°и§ЈжһҗжҲҗbigintзұ»еһӢзҡ„пјҢжҠҠеӯ—з¬ҰдёІи§ЈжһҗжҲҗstringзұ»еһӢзҡ„пјҢйҖҡиҝҮиҝҷдёӘж–№жі•иҜ»е…Ҙж•°жҚ®ж—¶пјҢиҝ”еӣһеҖјеҫ—з»“жһңжҳҜдёҖдёӘDataFrameж•°жҚ®зұ»еһӢгҖӮ
DataFrameжҳҜд»Җд№Ҳпјҹе…¶е®һе®ғжҳҜsparkSQLеӨ„зҗҶеӨ§ж•°жҚ®зҡ„еҹәжң¬е№¶дё”жҳҜж ёеҝғзҡ„ж•°жҚ®з»“жһ„пјҢжҳҜжқҘеӯҳеӮЁsparkSQLжҠҠж•°жҚ®иҜ»е…ҘеҲ°еҶ…еӯҳдёӯпјҢж•°жҚ®еңЁеҶ…еӯҳдёӯиҝӣиЎҢеӯҳеӮЁзҡ„еҹәжң¬ж•°жҚ®з»“жһ„гҖӮе®ғйҮҮз”Ёзҡ„еӯҳеӮЁжҳҜзұ»дјјдәҺж•°жҚ®еә“зҡ„иЎЁзҡ„еҪўејҸиҝӣиЎҢеӯҳеӮЁзҡ„гҖӮжҲ‘们жғідёҖжғіпјҢдёҖдёӘж•°жҚ®иЎЁжңүеҮ йғЁеҲҶз»„жҲҗпјҡ1гҖҒж•°жҚ®пјҢиҝҷдёӘж•°жҚ®жҳҜдёҖиЎҢдёҖиЎҢиҝӣиЎҢеӯҳеӮЁзҡ„пјҢдёҖжқЎи®°еҪ•е°ұжҳҜдёҖиЎҢпјҢ2гҖҒж•°жҚ®иЎЁзҡ„ж•°жҚ®еӯ—е…ёпјҢеҢ…жӢ¬иЎЁзҡ„еҗҚз§°пјҢиЎЁзҡ„еӯ—ж®өе’Ңеӯ—ж®өзҡ„зұ»еһӢзӯүе…ғж•°жҚ®дҝЎжҒҜгҖӮйӮЈд№ҲDataFrameд№ҹжҳҜжҢүз…§иЎҢиҝӣиЎҢеӯҳеӮЁзҡ„пјҢиҝҷдёӘзұ»жҳҜRowпјҢдёҖиЎҢдёҖиЎҢзҡ„иҝӣиЎҢж•°жҚ®еӯҳеӮЁгҖӮдёҖиҲ¬жғ…еҶөдёӢеӨ„зҗҶзІ’еәҰжҳҜиЎҢзІ’еәҰзҡ„пјҢдёҚйңҖиҰҒеҜ№е…¶иЎҢеҶ…ж•°жҚ®иҝӣиЎҢж“ҚдҪңпјҢеҰӮжһңжғіеҚ•зӢ¬ж“ҚдҪңиЎҢеҶ…ж•°жҚ®д№ҹжҳҜеҸҜд»Ҙзҡ„пјҢеҸӘжҳҜеңЁеӨ„зҗҶзҡ„ж—¶еҖҷиҰҒе°ҸеҝғпјҢеӣ дёәеӨ„зҗҶиЎҢеҶ…зҡ„ж•°жҚ®е®№жҳ“еҮәй”ҷпјҢжҜ”еҰӮйҖүй”ҷж•°жҚ®пјҢж•°з»„и¶Ҡз•ҢзӯүгҖӮж•°жҚ®зҡ„еӯҳеӮЁзҡ„еҪўејҸжңүдәҶпјҢж•°жҚ®иЎЁзҡ„еӯ—ж®өе’Ңеӯ—ж®өзҡ„зұ»еһӢйғҪеӯҳж”ҫеңЁе“ӘйҮҢе‘ўпјҢе°ұжҳҜschemaдёӯгҖӮжҲ‘们еҸҜд»Ҙи°ғз”ЁschemaжқҘзңӢе…¶еӯҳеӮЁзҡ„жҳҜд»Җд№ҲгҖӮ
peopleInfo.schema //иҝ”еӣһзҡ„з»“жһңжҳҜ:org.apache.spark.sql.types.StructType = //StructType(StructField(age,LongType,true), StructField(id,LongType,true), // StructField(name,StringType,true))
еҸҜд»ҘзңӢеҮәpeopleInfoеӯҳеӮЁзҡ„жҳҜж•°жҚ®пјҢschemaдёӯеӯҳеӮЁзҡ„жҳҜиҝҷдәӣеӯ—ж®өзҡ„дҝЎжҒҜгҖӮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜиЎЁзҡ„еӯ—ж®өзҡ„зұ»еһӢдёҺscalaж•°жҚ®зұ»еһӢзҡ„еҜ№еә”е…ізі»пјҡbigint->Long,int -> Int,Float -> Float,double -> Double,string -> StringзӯүгҖӮдёҖдёӘDataFrameжҳҜжңүдёӨйғЁеҲҶз»„жҲҗзҡ„пјҡд»ҘиЎҢиҝӣиЎҢеӯҳеӮЁзҡ„ж•°жҚ®е’ҢscheamпјҢschemaжҳҜStructTypeзұ»еһӢзҡ„гҖӮеҪ“жҲ‘们жңүж•°жҚ®иҖҢжІЎжңүschemaж—¶пјҢжҲ‘们еҸҜд»ҘйҖҡиҝҮиҝҷдёӘеҪўејҸиҝӣиЎҢжһ„йҖ д»ҺиҖҢеҪўжҲҗдёҖдёӘDataFrameгҖӮ
readеҮҪж•°иҝҳжҸҗдҫӣдәҶе…¶д»–иҜ»е…Ҙж•°жҚ®зҡ„жҺҘеҸЈпјҡ
| еҮҪж•° | з”ЁйҖ” |
json(path:String) | иҜ»еҸ–jsonж–Ү件用жӯӨж–№жі• |
| table(tableName:String) | иҜ»еҸ–ж•°жҚ®еә“дёӯзҡ„иЎЁ |
| jdbc(url: String,table: String,predicates:Array[String],connectionProperties:Properties) | йҖҡиҝҮjdbcиҜ»еҸ–ж•°жҚ®еә“дёӯзҡ„иЎЁ |
| orc(path:String) | иҜ»еҸ–д»Ҙorcж јејҸиҝӣиЎҢеӯҳеӮЁзҡ„ж–Ү件 |
| parquet(path:String) | иҜ»еҸ–д»Ҙparquetж јејҸиҝӣиЎҢеӯҳеӮЁзҡ„ж–Ү件 |
| schema(schema:StructType) | иҝҷдёӘжҳҜдёҖдёӘдјҳеҢ–пјҢеҪ“жҲ‘们иҜ»е…Ҙж•°жҚ®зҡ„ж—¶еҖҷжҢҮе®ҡдәҶе…¶schemaпјҢеә•еұӮе°ұдёҚдјҡеҶҚж¬Ўи§Јжһҗschemaд»ҺиҖҢиҝӣиЎҢдәҶдјҳеҢ–пјҢдёҖиҲ¬дёҚйңҖиҰҒиҝҷж ·зҡ„дјҳеҢ–пјҢдёҚиҝӣиЎҢжӯӨдјҳеҢ–пјҢж—¶й—ҙж•ҲзҺҮиҝҳжҳҜеҸҜд»ҘжҺҘеҸ— |
2гҖҒ第дәҢз§ҚиҜ»е…Ҙж•°жҚ®пјҡиҝҷдёӘиҜ»е…Ҙж•°жҚ®зҡ„ж–№жі•пјҢдё»иҰҒжҳҜеӨ„зҗҶд»ҺдёҖдёӘж•°жҚ®иЎЁдёӯйҖүжӢ©йғЁеҲҶеӯ—ж®өпјҢиҖҢдёҚжҳҜйҖүжӢ©иЎЁдёӯзҡ„жүҖжңүеӯ—ж®өгҖӮйӮЈд№Ҳиҝҷз§ҚйңҖжұӮпјҢйҮҮз”ЁиҝҷдёӘж•°жҚ®иҜ»е…Ҙж–№ејҸжҜ”иҫғжңүдјҳеҠҝгҖӮиҝҷз§Қж–№ејҸжҳҜзӣҙжҺҘеҶҷsqlзҡ„жҹҘиҜўиҜӯеҸҘгҖӮжҠҠдёҠиҝ°jsonж јејҸзҡ„ж•°жҚ®дҝқеӯҳдёәж•°жҚ®еә“дёӯиЎЁзҡ„ж јејҸгҖӮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜиҝҷз§ҚеҸӘиғҪеӨ„зҗҶж•°жҚ®еә“иЎЁж•°жҚ®гҖӮ
val peopleInfo = sql.sql("""
|select
| id,
| name,
| age
|from peopleInfo
""".stripMargin)//е…¶дёӯstripMarginж–№жі•жҳҜжқҘи§ЈжһҗжҲ‘们еҶҷзҡ„sqlиҜӯеҸҘзҡ„гҖӮ
//иҝ”еӣһзҡ„з»“жһңжҳҜе’ҢreadиҜ»еҸ–иҝ”еӣһзҡ„з»“жһңжҳҜдёҖж ·зҡ„пјҡ
//org.apache.spark.sql.DataFrame =
// [age: bigint, id: bigint, name: string]йңҖиҰҒжіЁж„Ҹзҡ„жҳҜе…¶иҝ”еӣһзҡ„schmeaдёӯеӯ—ж®өзҡ„йЎәеәҸе’ҢжҲ‘们жҹҘиҜўзҡ„йЎәеәҸиҝҳжҳҜдёҚдёҖиҮҙзҡ„гҖӮ
2.2 еҶҷе…Ҙж•°жҚ®
еҶҷе…Ҙж•°жҚ®е°ұжҜ”иҫғзҡ„з®ҖеҚ•пјҢеӣ дёәе…¶жӢҘжңүдёҖе®ҡзҡ„жЁЎејҸпјҢжҢүз…§иҝҷдёӘжЁЎејҸиҝӣиЎҢж•°жҚ®зҡ„еҶҷе…ҘгҖӮдёҖиҲ¬жғ…еҶөдёӢпјҢжҲ‘们йңҖиҰҒеҶҷе…Ҙзҡ„ж•°жҚ®жҳҜдёҖдёӘDataFrameзұ»еһӢзҡ„пјҢеҰӮжһңе…¶дёҚжҳҜDataFrameзұ»еһӢзҡ„жҲ‘们йңҖиҰҒжҠҠе…¶иҪ¬жҚўдёә
DataFrameзұ»еһӢпјҢжңүдәӣдәәеҸҜиғҪдјҡжңүз–‘й—®пјҢж•°жҚ®иҜ»е…ҘеҲ°еҶ…еӯҳдёӯпјҢе…¶зұ»еһӢжҳҜDataFrameзұ»еһӢпјҢжҲ‘们еңЁеӨ„зҗҶж•°жҚ®ж—¶з”ЁеҲ°зҡ„жҳҜDataFrameзұ»дёӯзҡ„ж–№жі•пјҢдҪҶжҳҜDataFrameдёӯзҡ„ж–№жі•дёҚдёҖе®ҡиҝ”еӣһеҖјд»Қ然жҳҜDataFrameзұ»еһӢзҡ„пјҢеҗҢж—¶жңүж—¶жҲ‘们йңҖиҰҒжһ„е»әиҮӘе·ұзҡ„зұ»еһӢпјҢжүҖд»ҘжҲ‘们йңҖиҰҒдёәжҲ‘们зҡ„ж•°жҚ®жһ„е»әжҲҗDataFrameзҡ„зұ»еһӢгҖӮжҠҠжІЎжңүschemaзҡ„ж•°жҚ®пјҢжһ„е»әschemaзұ»еһӢпјҢжҲ‘жүҖзҹҘйҒ“зҡ„е°ұжңүдёӨз§Қж–№жі•гҖӮ
1гҖҒйҖҡиҝҮзұ»жһ„е»әschemaпјҢиҝҳд»ҘдёҠйқўзҡ„peopleInfoдёәдҫӢеӯҗгҖӮ
val sql = new SQLContext(sc) //еҲӣе»әдёҖдёӘSQLContextеҜ№иұЎ
import sql.implicits._ //иҝҷдёӘsqlжҳҜдёҠйқўжҲ‘们е®ҡд№үзҡ„sqlпјҢиҖҢдёҚжҳҜжҹҗдёҖдёӘjarеҢ…пјҢзҪ‘дёҠжңүеҫҲеӨҡ
//жҳҜimport sqlContext.implicits._,йӮЈжҳҜ他们е®ҡд№үзҡ„жҳҜ
//sqlContext = SQLContext(sc),иҝҷдёӘжҳҜscalaзҡ„дёҖдёӘзү№жҖ§
val people = sc.textFile("people.txt")//жҲ‘们йҮҮз”Ёsparkзҡ„зұ»еһӢиҜ»е…Ҙж•°жҚ®пјҢеӣ дёәеҰӮжһңз”Ё
//SQLContextиҝӣиЎҢиҜ»е…ҘпјҢ他们иҮӘеҠЁжңүдәҶschema
case clase People(id:Int,name:String,age:Int)//е®ҡд№үдёҖдёӘзұ»
val peopleInfo = people.map(lines => lines.split(","))
.map(p => People(p(0).toInt,p(1),p(2).toInt)).toDF
//иҝҷж ·зҡ„дёҖдёӘtoDFе°ұеҲӣе»әдәҶдёҖдёӘDataFrameпјҢеҰӮжһңдёҚеҜје…Ҙ
//sql.implicits._,иҝҷдёӘtoDFж–№жі•жҳҜдёҚеҸҜд»Ҙз”Ёзҡ„гҖӮдёҠйқўзҡ„дҫӢеӯҗжҳҜеҲ©з”ЁдәҶscalaзҡ„еҸҚе°„жҠҖжңҜпјҢз”ҹжҲҗдәҶдёҖдёӘDataFrameзұ»еһӢгҖӮеҸҜд»ҘзңӢеҮәжҲ‘们жҳҜжҠҠRDDз»ҷиҪ¬жҚўдёәDataFrameзҡ„гҖӮ
2гҖҒзӣҙжҺҘжһ„йҖ schemaпјҢд»ҘpeopelInfoдёәдҫӢеӯҗгҖӮзӣҙжҺҘжһ„йҖ пјҢжҲ‘们йңҖиҰҒжҠҠжҲ‘们зҡ„ж•°жҚ®зұ»еһӢиҝӣиЎҢиҪ¬еҢ–жҲҗRowзұ»еһӢпјҢдёҚ然дјҡжҠҘй”ҷгҖӮ
val sql = new SQLContext(sc) //еҲӣе»әдёҖдёӘSQLContextеҜ№иұЎ
val people = sc.textFile("people.txt").map(lines => lines.split(","))
val peopleRow = sc.map(p => Row(p(0),p(1),(2)))//жҠҠRDDиҪ¬еҢ–жҲҗRDD(Row)зұ»еһӢ
val schema = StructType(StructFile("id",IntegerType,true)::
StructFile("name",StringType,true)::
StructFile("age",IntegerType,true)::Nil)
val peopleInfo = sql.createDataFrame(peopleRow,schema)//peopleRowзҡ„жҜҸдёҖиЎҢзҡ„ж•°жҚ®
//зұ»еһӢдёҖе®ҡиҰҒдёҺschemaзҡ„дёҖиҮҙ
//еҗҰеҲҷдјҡжҠҘй”ҷпјҢиҜҙзұ»еһӢж— жі•еҢ№й…Қ
//еҗҢж—¶peopleRowжҜҸдёҖиЎҢзҡ„й•ҝеәҰ
//д№ҹиҰҒе’ҢschemaдёҖиҮҙпјҢеҗҰеҲҷ
//д№ҹдјҡжҠҘй”ҷжһ„йҖ schemaз”ЁеҲ°дәҶдёӨдёӘзұ»StructTypeе’ҢStructFileпјҢе…¶дёӯStructFileзұ»зҡ„дёүдёӘеҸӮж•°еҲҶеҲ«жҳҜ(еӯ—ж®өеҗҚз§°пјҢзұ»еһӢпјҢж•°жҚ®жҳҜеҗҰеҸҜд»Ҙз”ЁnullеЎ«е……)
йҮҮз”ЁзӣҙжҺҘжһ„йҖ жңүеҫҲеӨ§зҡ„еҲ¶зәҰжҖ§пјҢеӯ—ж®өе°‘дәҶиҝҳеҸҜд»ҘпјҢеҰӮжһңжңүеҮ еҚҒдёӘз”ҡиҮідёҖзҷҫеӨҡдёӘеӯ—ж®өпјҢиҝҷз§Қж–№жі•е°ұжҜ”иҫғиҖ—ж—¶пјҢдёҚд»…иҰҒдҝқиҜҒRowдёӯж•°жҚ®зҡ„зұ»еһӢиҰҒе’ҢжҲ‘们е®ҡд№үзҡ„schemaзұ»еһӢдёҖиҮҙпјҢй•ҝеәҰд№ҹиҰҒдёҖж ·пјҢдёҚ然йғҪдјҡжҠҘй”ҷпјҢжүҖд»ҘиҰҒжғізӣҙжҺҘжһ„йҖ schemaпјҢдёҖе®ҡиҰҒз»Ҷеҝғз»ҶеҝғеҶҚз»ҶеҝғпјҢжң¬дәәе°ұиў«иҮӘе·ұзҡ„дёҚз»ҶеҝғиҷҗжғЁдәҶпјҢеӨ„зҗҶзҡ„еӯ—ж®өе°Ҷиҝ‘дёҖзҷҫпјҢз”ұдәҺе®ҡд№үзҡ„schemaе’ҢжҲ‘зҡ„ж•°жҚ®зұ»еһӢдёҚдёҖиҮҙпјҢжҲ‘е°ұйңҖиҰҒжҜҸдёҖдёӘеӯ—ж®өжҜҸдёҖдёӘеӯ—ж®өзҡ„еҺ»зЎ®и®ӨпјҢеӯ—ж®өдёҖеӨҡеңЁеҜ№зҡ„ж—¶еҖҷе°ұе®№жҳ“з–ІеҠіпјҢе°ұиҝҷж ·зҡ„дёҖдёӘй”ҷиҜҜпјҢз”ұдәҺжң¬дәәжҜ”иҫғз¬ЁпјҢе°ұиҠұиҙ№дәҶдёҖдёӘдёӢеҚҲзҡ„ж—¶й—ҙпјҢжүҖд»Ҙеӯ—ж®өеӨҡдәҶпјҢеңЁзӣҙжҺҘжһ„йҖ schemaзҡ„ж—¶еҖҷпјҢдёҖе®ҡиҰҒз»ҶеҝғгҖҒз»ҶеҝғгҖҒз»ҶеҝғпјҢйҮҚиҰҒзҡ„дәӢжғ…иҜҙдёүйҒҚпјҢдёҚ然дјҡжӯ»зҡ„еҫҲжғЁгҖӮ
еҘҪдәҶпјҢзҺ°еңЁжҲ‘们已з»ҸжҠҠжҲ‘们зҡ„ж•°жҚ®иҪ¬еҢ–жҲҗDataFrameзұ»еһӢзҡ„пјҢдёӢйқўе°ұиҰҒеҫҖж•°жҚ®еә“дёӯеҶҷжҲ‘们зҡ„ж•°жҚ®дәҶ
еҶҷж•°жҚ®ж“ҚдҪңпјҡ
val sql = new SQLContext(sc)
val people = sc.textFile("people.txt").map(lines => lines.split(","))
val peopleRow = sc.map(p => Row(p(0),p(1),(2)))
val schema = StructType(StructFile("id",IntegerType,true)::
StructFile("name",StringType,true)::
StructFile("age",IntegerType,true)::Nil)
val peopleInfo = sql.createDataFrame(peopleRow,schema)
peopleInfo.registerTempTable("tempTable")//еҸӘжңүжңүдәҶиҝҷдёӘжіЁеҶҢзҡ„иЎЁtempTableпјҢжҲ‘们
//жүҚиғҪйҖҡиҝҮsql.sql(вҖңвҖқвҖң вҖқвҖңвҖқ)иҝӣиЎҢжҹҘиҜў
//иҝҷдёӘжҳҜеңЁеҶ…еӯҳдёӯжіЁеҶҢдёҖдёӘдёҙж—¶иЎЁз”ЁжҲ·жҹҘиҜў
sql.sql.sql("""
|insert overwrite table tagetTable
|select
| id,
| name,
| age
|from tempTable
""".stripMargin)//иҝҷж ·е°ұжҠҠж•°жҚ®еҶҷе…ҘеҲ°дәҶж•°жҚ®еә“зӣ®ж ҮиЎЁtagetTableдёӯжңүдёҠйқўеҸҜд»ҘзңӢеҲ°пјҢsparkSQLзҡ„sql()е…¶е®һе°ұжҳҜз”ЁжқҘжү§иЎҢжҲ‘们еҶҷзҡ„sqlиҜӯеҸҘзҡ„гҖӮ
еҘҪдәҶпјҢдёҠйқўд»Ӣз»ҚдәҶиҜ»е’ҢеҶҷзҡ„ж“ҚдҪңпјҢзҺ°еңЁйңҖиҰҒеҜ№жңҖйҮҚиҰҒзҡ„ең°ж–№жқҘиҝӣиЎҢж“ҚдҪңдәҶе•ҠгҖӮ
2.3 йҖҡиҝҮDataFrameдёӯзҡ„ж–№жі•еҜ№ж•°жҚ®иҝӣиЎҢж“ҚдҪң
еңЁд»Ӣз»ҚDataFrameд№ӢеүҚпјҢжҲ‘们иҝҳжҳҜиҰҒе…ҲжҳҺзЎ®дёҖдёӢпјҢsparkSQLжҳҜз”ЁжқҘе№Ід»Җд№Ҳзҡ„пјҢе®ғдё»иҰҒдёәжҲ‘们жҸҗдҫӣдәҶжҖҺж ·зҡ„дҫҝжҚ·пјҢжҲ‘们дёәд»Җд№ҲиҰҒз”Ёе®ғгҖӮе®ғжҳҜдёәдәҶи®©жҲ‘们иғҪз”ЁеҶҷд»Јз Ғзҡ„еҪўејҸжқҘеӨ„зҗҶsqlпјҢиҝҷж ·иҜҙеҸҜиғҪжңүзӮ№дёҚеҮҶзЎ®пјҢеҰӮжһңе°ұиҝҷд№Ҳз®ҖеҚ•пјҢеҸӘжҳҜеҜ№sqlиҝӣиЎҢз®ҖеҚ•зҡ„жӣҝжҚўпјҢиҰҒжҳҜжҲ‘пјҢжҲ‘д№ҹдёҚеӯҰд№ е®ғпјҢеӣ дёәжҲ‘е·Із»ҸдјҡsqlдәҶпјҢдјҡйҖҡиҝҮsqlиҝӣиЎҢеӨ„зҗҶж•°жҚ®д»“еә“зҡ„etlпјҢжҲ‘иҝҳеӯҰд№ sparkSQLе№ІеҳӣпјҢиҖҢдё”еӯҰд№ зҡ„жҲҗжң¬еҸҲйӮЈд№Ҳй«ҳгҖӮsparkSQLиӮҜе®ҡжңүеҘҪеӨ„дәҶпјҢдёҚ然д№ҹдёҚдјҡжңүиҝҷзҜҮеҚҡе®ўе•ҰгҖӮжҲ‘们йғҪзҹҘйҒ“йҖҡиҝҮеҶҷsqlжқҘиҝӣиЎҢж•°жҚ®йҖ»иҫ‘зҡ„еӨ„зҗҶж—¶жңүйҷҗзҡ„пјҢеҶҷзЁӢеәҸжқҘиҝӣиЎҢж•°жҚ®йҖ»иҫ‘зҡ„еӨ„зҗҶжҳҜйқһеёёзҒөжҙ»зҡ„пјҢжүҖд»ҘsparkSQLжҳҜз”ЁжқҘеӨ„зҗҶйӮЈдәӣдёҚиғҪеӨҹз”ЁsqlжқҘиҝӣиЎҢеӨ„зҗҶзҡ„ж•°жҚ®йҖ»иҫ‘жҲ–иҖ…з”ЁsqlеӨ„зҗҶиө·жқҘжҜ”иҫғеӨҚжқӮзҡ„ж•°жҚ®йҖ»иҫ‘гҖӮдёҖиҲ¬зҡ„еҺҹеҲҷжҳҜиғҪз”ЁsqlжқҘеӨ„зҗҶзҡ„пјҢе°ҪйҮҸз”ЁsqlжқҘеӨ„зҗҶпјҢжҜ•з«ҹејҖеҸ‘иө·жқҘз®ҖеҚ•пјҢsqlеӨ„зҗҶдёҚдәҶзҡ„пјҢеҶҚйҖүжӢ©з”ЁsparkSQLйҖҡиҝҮеҶҷд»Јз Ғзҡ„ж–№ејҸжқҘеӨ„зҗҶгҖӮеҘҪдәҶеәҹиҜқдёҚеӨҡиҜҙдәҶпјҢејҖе§ӢDataFrameд№Ӣж—…гҖӮ
sparkSQLйқһеёёејәеӨ§пјҢе®ғжҸҗдҫӣдәҶжҲ‘们sqlдёӯзҡ„жӯЈеҲ ж”№жҹҘжүҖжңүзҡ„еҠҹиғҪпјҢжҜҸдёҖдёӘеҠҹиғҪйғҪеҜ№еә”дәҶдёҖдёӘе®һзҺ°жӯӨеҠҹиғҪзҡ„ж–№жі•гҖӮ
еҜ№schemaзҡ„ж“ҚдҪң
val sql = new SQLContext(sc)
val people = sql.read.json("people.txt")//peopleжҳҜдёҖдёӘDataFrameзұ»еһӢзҡ„еҜ№иұЎ
//ж•°жҚ®иҜ»иҝӣжқҘдәҶпјҢйӮЈжҲ‘们жҹҘзңӢдёҖдёӢе…¶schemaеҗ§
people.schema
//иҝ”еӣһзҡ„зұ»еһӢ
//org.apache.spark.sql.types.StructType =
//StructType(StructField(age,LongType,true),
// StructField(id,LongType,true),
// StructField(name,StringType,true))
//д»Ҙж•°з»„зҡ„еҪўејҸеҲҶдјҡschema
people.dtypes
//иҝ”еӣһзҡ„з»“жһңпјҡ
//Array[(String, String)] =
// Array((age,LongType), (id,LongType), (name,StringType))
//иҝ”еӣһschemaдёӯзҡ„еӯ—ж®ө
people.columns
//иҝ”еӣһзҡ„з»“жһңпјҡ
//Array[String] = Array(age, id, name)
//д»Ҙtreeзҡ„еҪўејҸжү“еҚ°иҫ“еҮәschema
people.printSchema
//иҝ”еӣһзҡ„з»“жһң:
//root
// |-- age: long (nullable = true)
// |-- id: long (nullable = true)
// |-- name: string (nullable = true)еҜ№иЎЁзҡ„ж“ҚдҪң,еҜ№иЎЁзҡ„ж“ҚдҪңиҜӯеҸҘдёҖиҲ¬жғ…еҶөдёӢжҳҜдёҚеёёз”Ёзҡ„пјҢеӣ дёәиҷҪ然sparkSQLжҠҠsqlжҹҘзҡ„жҜҸдёҖдёӘеҠҹиғҪйғҪе°ҒиЈ…еҲ°дәҶдёҖдёӘж–№жі•дёӯпјҢдҪҶжҳҜеӨ„зҗҶиө·жқҘиҝҳжҳҜдёҚжҖҺд№ҲзҒөжҙ»дёҖиҲ¬жғ…еҶөдёӢжҲ‘们йҮҮз”Ёзҡ„жҳҜз”Ёsql()ж–№жі•зӣҙжҺҘжқҘеҶҷsqlпјҢиҝҷж ·жҜ”иҫғе®һз”ЁпјҢиҝҳжӣҙзҒөжҙ»пјҢиҖҢдё”д»Јз Ғзҡ„еҸҜиҜ»жҖ§д№ҹжҳҜеҫҲй«ҳзҡ„гҖӮйӮЈдёӢйқўе°ұжҠҠиғҪз”ЁеҲ°зҡ„ж–№жі•еҒҡдёҖдёӘз®ҖиҰҒзҡ„иҜҙжҳҺгҖӮ
| ж–№жі•(sqlдҪҝжҲ‘们е®ҡд№үзҡ„sql = new SQLContext(sc)) dfжҳҜдёҖдёӘDataFrameеҜ№иұЎ | е®һдҫӢиҜҙжҳҺ |
| sql.read.table(tableName) | иҜ»еҸ–дёҖеј иЎЁзҡ„ж•°жҚ® |
| df.where(), df.filter() | иҝҮж»ӨжқЎд»¶пјҢзӣёеҪ“дәҺsqlзҡ„whereйғЁеҲҶ; з”Ёжі•пјҡйҖүжӢ©еҮәе№ҙйҫ„еӯ—ж®өдёӯе№ҙйҫ„еӨ§дәҺ20зҡ„еӯ—ж®өгҖӮ иҝ”еӣһеҖјзұ»еһӢпјҡDataFrame df.where("age >= 20"),df.filter("age >= 20") |
| df.limit() | йҷҗеҲ¶иҫ“еҮәзҡ„иЎҢж•°пјҢеҜ№еә”дәҺsqlзҡ„limit з”Ёжі•пјҡйҷҗеҲ¶иҫ“еҮәдёҖзҷҫиЎҢ иҝ”еӣһеҖјзұ»еһӢпјҡDataFrame df.limit(100) |
| df.join() | й“ҫжҺҘж“ҚдҪңпјҢзӣёеҪ“дәҺsqlзҡ„join еҜ№дәҺjoinж“ҚдҪңпјҢдёӢйқўдјҡеҚ•зӢ¬иҝӣиЎҢд»Ӣз»Қ |
| df.groupBy() | иҒҡеҗҲж“ҚдҪңпјҢзӣёеҪ“дәҺsqlзҡ„groupBy з”Ёжі•пјҡеҜ№дәҺжҹҗеҮ иЎҢиҝӣиЎҢиҒҡеҗҲ иҝ”еӣһеҖјзұ»еһӢпјҡDataFrame df.groupBy("id") |
| df.agg() | жұӮиҒҡеҗҲз”Ёзҡ„зӣёе…іеҮҪж•°пјҢдёӢйқўдјҡиҜҰз»Ҷд»Ӣз»Қ |
| df.intersect(other:DataFrame) | жұӮдёӨдёӘDataFrameзҡ„дәӨйӣҶ |
| df.except(other:DataFrame) | жұӮеңЁdfдёӯиҖҢдёҚеңЁotherдёӯзҡ„иЎҢ |
| df.withColumn(colName:String,col:Column) | еўһеҠ дёҖеҲ— |
| df.withColumnRenamed(exName,newName) | еҜ№жҹҗдёҖеҲ—зҡ„еҗҚеӯ—иҝӣиЎҢйҮҚж–°е‘ҪеҗҚ |
df.map(), df.flatMap, df.mapPartitions(), df.foreach() df.foreachPartition() df.collect() df.collectAsList() df.repartition() df.distinct() df.count() | иҝҷдәӣж–№жі•йғҪжҳҜsparkзҡ„RDDзҡ„еҹәжң¬ж“ҚдҪңпјҢе…¶дёӯеңЁDataFrameзұ»дёӯд№ҹе°ҒиЈ…дәҶиҝҷдәӣж–№жі•пјҢйңҖиҰҒжіЁж„Ҹзҡ„жҳҜиҝҷдәӣж–№жі•зҡ„иҝ”еӣһеҖјжҳҜRDDзұ»еһӢзҡ„пјҢдёҚжҳҜDataFrameзұ»еһӢзҡ„пјҢеңЁиҝҷдәӣж–№жі•зҡ„дҪҝз”ЁдёҠпјҢдёҖе®ҡиҰҒи®°жё…жҘҡиҝ”еӣһеҖјзұ»еһӢпјҢдёҚ然е°ұе®№жҳ“еҮәзҺ°й”ҷиҜҜ |
| df.select() | йҖүеҸ–жҹҗеҮ еҲ—е…ғзҙ пјҢиҝҷдёӘж–№жі•зӣёеҪ“дәҺsqlзҡ„selectзҡ„еҠҹиғҪ з”Ёжі•пјҡиҝ”еӣһйҖүжӢ©зҡ„жҹҗеҮ еҲ—ж•°жҚ® иҝ”еӣһеҖјзұ»еһӢпјҡDataFrame df.select("id","name") |
д»ҘдёҠжҳҜдёӨдёӘйғҪжҳҜдёҖеҶҷеҹәжң¬зҡ„ж–№жі•пјҢдёӢйқўе°ұиҜҰз»Ҷд»Ӣз»ҚдёҖдёӢjoinе’Ңagg,na,udfж“ҚдҪң
2.4 sparkSQLзҡ„joinж“ҚдҪң
sparkзҡ„joinж“ҚдҪңе°ұжІЎжңүзӣҙжҺҘеҶҷsqlзҡ„joinж“ҚдҪңжқҘзҡ„зҒөжҙ»пјҢеңЁиҝӣиЎҢй“ҫжҺҘзҡ„ж—¶еҖҷпјҢдёҚиғҪеҜ№дёӨдёӘиЎЁдёӯзҡ„еӯ—ж®өиҝӣиЎҢйҮҚж–°е‘ҪеҗҚпјҢиҝҷж ·е°ұдјҡеҮәзҺ°еҗҢдёҖеј иЎЁдёӯеҮәзҺ°дёӨдёӘзӣёеҗҢзҡ„еӯ—ж®өгҖӮдёӢйқўе°ұдёҖзӮ№дёҖзӮ№зҡ„иҝӣиЎҢеұ•ејҖз”ЁеҲ°зҡ„дёӨдёӘиЎЁпјҢдёҖдёӘжҳҜз”ЁжҲ·дҝЎжҒҜиЎЁпјҢдёҖдёӘжҳҜз”ЁжҲ·зҡ„收е…Ҙи–Әиө„иЎЁпјҡ
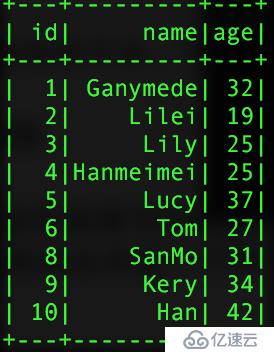
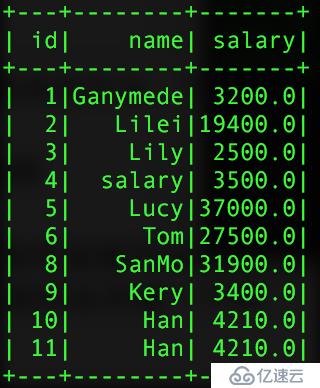
1гҖҒеҶ…иҝһжҺҘпјҢзӯүеҖјй“ҫжҺҘпјҢдјҡжҠҠй“ҫжҺҘзҡ„еҲ—еҗҲ并жҲҗдёҖдёӘеҲ—
val sql = new SQLContext(sc)
val pInfo = sql.read.json("people.txt")
val pSalar = sql.read.json("salary.txt")
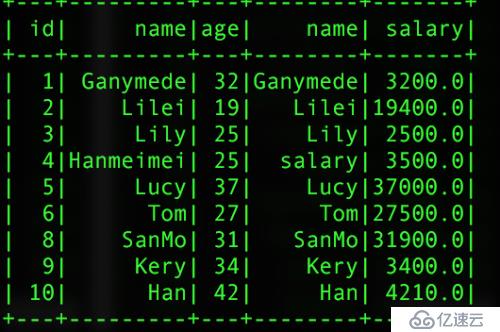
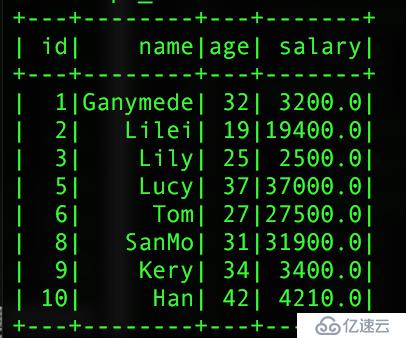
val info_salary = pInfo.join(pSalar,"id")//еҚ•дёӘеӯ—ж®өиҝӣиЎҢеҶ…иҝһжҺҘ
val info_salary1 = pInfo.join(pSalar,Seq("id","name"))//еӨҡеӯ—ж®өй“ҫжҺҘиҝ”еӣһзҡ„з»“жһңеҰӮдёӢеӣҫпјҡ
еҚ•дёӘidиҝӣиЎҢй“ҫжҺҘ (дёҖеј иЎЁеҮәзҺ°дёӨдёӘnameеӯ—ж®ө) дёӨдёӘеӯ—ж®өиҝӣиЎҢй“ҫжҺҘ
2гҖҒjoinиҝҳж”ҜжҢҒе·ҰиҒ”жҺҘе’ҢеҸій“ҫжҺҘпјҢдҪҶжҳҜе…¶е·ҰиҒ”жҺҘе’ҢеҸій“ҫжҺҘе’ҢжҲ‘们sqlзҡ„й“ҫжҺҘзҡ„ж„ҸжҖқжҳҜдёҖж ·зҡ„пјҢеҗҢж ·д№ҹжҳҜеңЁй“ҫжҺҘзҡ„ж—¶еҖҷдёҚиғҪеҜ№еӯ—ж®өиҝӣиЎҢйҮҚж–°е‘ҪеҗҚпјҢеҰӮжһңдёӨдёӘиЎЁдёӯжңүзӣёеҗҢзҡ„еӯ—ж®өпјҢеҲҷе°ұдјҡеҮәзҺ°еңЁеҗҢдёҖдёӘjoinзҡ„иЎЁдёӯпјҢеҗҢдәӢе·ҰеҸій“ҫжҺҘпјҢдёҚдјҡеҗҲ并用дәҺй“ҫжҺҘзҡ„еӯ—ж®өгҖӮй“ҫжҺҘз”Ёзҡ„е…ій”®иҜҚпјҡouter,inner,left_outer,right_outer
//еҚ•еӯ—ж®өй“ҫжҺҘ
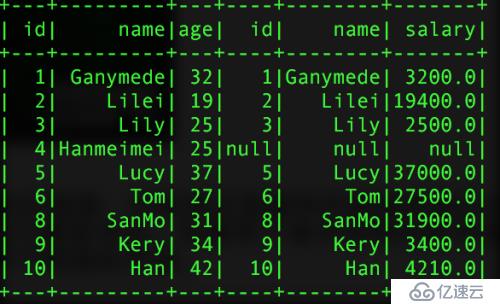
val left = pInfo.join(pSalar,pInfo("id") === pSalar("id"),"left_outer")
//еӨҡеӯ—ж®өй“ҫжҺҘ
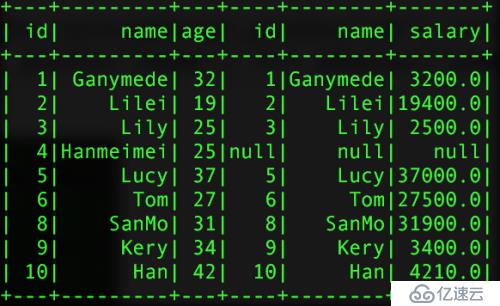
val left2 = pInfo.join(pSalar,pInfo("id") === pSalar("id") and
pInfo("name") === pSalar("name"),"left_outer")иҝ”еӣһзҡ„з»“жһңпјҡ
еҚ•еӯ—ж®өй“ҫжҺҘ еӨҡеӯ—ж®өй“ҫжҺҘ
з”ұдёҠеҸҜд»ҘеҸ‘зҺ°пјҢsparkSQLзҡ„joinж“ҚдҪңиҝҳжҳҜжІЎжңүsqlзҡ„joinзҒөжҙ»пјҢе®№жҳ“еҮәзҺ°йҮҚеӨҚзҡ„еӯ—ж®өеңЁеҗҢдёҖеј иЎЁдёӯпјҢдёҖиҲ¬жҲ‘们иҝӣиЎҢй“ҫжҺҘж“ҚдҪңж—¶пјҢжҲ‘们йғҪжҳҜе…ҲеҲ©з”ЁregisterTempTable()еҮҪж•°жҠҠжӯӨDataFrameжіЁеҶҢжҲҗдёҖдёӘеҶ…йғЁиЎЁпјҢ然еҗҺйҖҡиҝҮsql.sql("")еҶҷsqlзҡ„ж–№жі•иҝӣиЎҢй“ҫжҺҘпјҢиҝҷж ·еҸҜд»ҘжӣҙеҘҪзҡ„и§ЈеҶідәҶйҮҚеӨҚеӯ—ж®өзҡ„й—®йўҳгҖӮ
2.5 sparkSQLзҡ„aggж“ҚдҪң
е…¶дёӯsparkSQLзҡ„aggжҳҜsparkSQLиҒҡеҗҲж“ҚдҪңзҡ„дёҖз§ҚиЎЁиҫҫејҸпјҢеҪ“жҲ‘们и°ғз”Ёaggж—¶пјҢе…¶дёҖиҲ¬жғ…еҶөдёӢйғҪжҳҜе’ҢgroupBy()зҡ„дёҖиө·дҪҝз”Ёзҡ„,йҖүжӢ©ж“ҚдҪңзҡ„ж•°жҚ®иЎЁдёәпјҡ
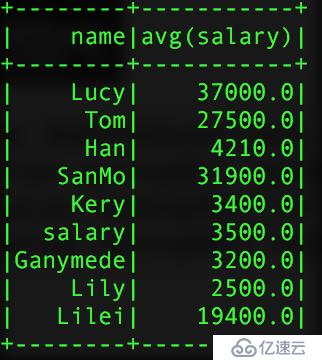
val pSalar = new SQLContext(sc).read.json("salary.txt")
val group = pSalar.groupBy("name").agg("salary" -> "avg")
val group2 = pSalar.groupBy("id","name").agg("salary" -> "avg")
val group3 = pSalar.groupBy("name").agg(Map("id" -> "avg","salary"->"max"))еҫ—еҲ°зҡ„з»“иҝҮеҰӮдёӢпјҡ
groupзҡ„з»“жһң group2 group3
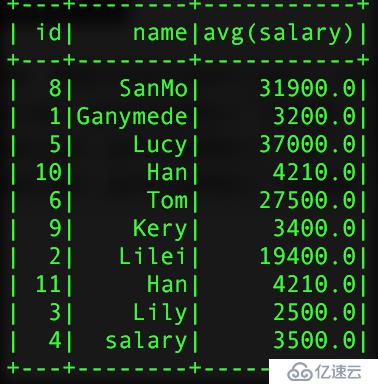
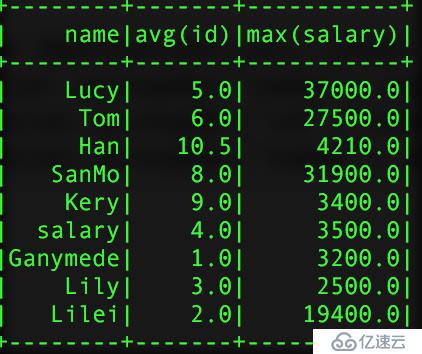
дҪҝз”Ёaggж—¶йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢеҗҢдёҖдёӘеӯ—ж®өдёҚиғҪиҝӣиЎҢдёӨж¬Ўж“ҚдҪңжҜ”еҰӮпјҡagg(Map("salary" -> "avg","salary" -> "max"),д»–еҸӘдјҡи®Ўз®—maxзҡ„ж“ҚдҪңпјҢеҺҹеӣ еҫҲз®ҖеҚ•пјҢaggжҺҘе…Ҙзҡ„еҸӮж•°жҳҜMapзұ»еһӢзҡ„key-valueеҜ№пјҢеҪ“keyзӣёеҗҢж—¶пјҢдјҡиҰҶзӣ–жҺүд№ӢеүҚзҡ„valueгҖӮеҗҢж—¶иҝҳеҸҜд»ҘзӣҙжҺҘдҪҝз”ЁaggпјҢиҝҷж ·жҳҜеҜ№жүҖжңүзҡ„иЎҢиҖҢиЁҖзҡ„гҖӮиҒҡеҗҲжүҖз”Ёзҡ„и®Ўз®—еҸӮж•°жңүпјҡavgпјҢmaxпјҢminпјҢsumпјҢcountпјҢиҖҢдёҚжҳҜеҸӘжңүдҫӢеӯҗдёӯз”ЁеҲ°зҡ„avg
2.6 sparkSQLзҡ„naж“ҚдҪң
sparkSQLзҡ„naж–№жі•пјҢиҝ”еӣһзҡ„жҳҜдёҖдёӘDataFrameFuctionsеҜ№иұЎпјҢжӯӨзұ»дё»иҰҒжҳҜеҜ№DataFrameдёӯеҖјдёәnullзҡ„иЎҢзҡ„ж“ҚдҪңпјҢеҸӘжҸҗдҫӣдёүдёӘж–№жі•пјҢdrop()еҲ йҷӨиЎҢпјҢfill()еЎ«е……иЎҢпјҢreplace()д»ЈжӣҝиЎҢзҡ„ж“ҚдҪңгҖӮеҫҲз®ҖеҚ•дёҚеҒҡиҝҮеӨҡзҡ„д»Ӣз»ҚгҖӮ
3гҖҒжҖ»з»“
жҲ‘们дҪҝз”ЁsparkSQLзҡ„зӣ®зҡ„е°ұжҳҜдёәдәҶи§ЈеҶіз”ЁеҶҷsqlдёҚиғҪи§ЈеҶізҡ„жҲ–иҖ…и§ЈеҶіиө·жқҘжҜ”иҫғеӣ°йҡҫзҡ„й—®йўҳпјҢеңЁе№іж—¶зҡ„ејҖеҸ‘иҝҮзЁӢдёӯпјҢжҲ‘们дёҚиғҪдёәдәҶй«ҳйҖјж јд»Җд№Ҳж ·зҡ„sqlй—®йўҳйғҪжҳҜз”ЁsparkSQLпјҢиҝҷж ·дёҚжҳҜжңҖй«ҳж•Ҳзҡ„гҖӮдҪҝз”ЁsparkSQLпјҢдё»иҰҒжҳҜеҲ©з”ЁдәҶеҶҷд»Јз ҒеӨ„зҗҶж•°жҚ®йҖ»иҫ‘зҡ„зҒөжҙ»жҖ§пјҢдҪҶжҳҜжҲ‘们д№ҹдёҚиғҪе®Ңе…Ёзҡ„еҸӘдҪҝз”ЁsparkSQLжҸҗдҫӣзҡ„sqlж–№жі•пјҢиҝҷж ·еҗҢж ·жҳҜиө°еҗ‘дәҶеҸҰеӨ–дёҖдёӘжһҒз«ҜпјҢжңүдёҠйқўзҡ„и®Ёи®әеҸҜзҹҘпјҢеңЁдҪҝз”Ёjoinж“ҚдҪңж—¶пјҢеҰӮжһңдҪҝз”ЁsparkSQLзҡ„joinж“ҚдҪңпјҢжңүеҫҲеӨҡзҡ„ејҠз«ҜгҖӮдёәдәҶиғҪз»“еҗҲsqlиҜӯеҸҘзҡ„дјҳи¶ҠжҖ§пјҢжҲ‘们еҸҜд»Ҙе…ҲжҠҠиҰҒиҝӣиЎҢй“ҫжҺҘзҡ„DataFrameеҜ№иұЎпјҢжіЁеҶҢжҲҗеҶ…йғЁзҡ„дёҖдёӘдёӯй—ҙиЎЁпјҢ然еҗҺеңЁйҖҡиҝҮеҶҷsqlиҜӯеҸҘпјҢз”ЁSQLContextжҸҗдҫӣзҡ„sql()ж–№жі•жқҘжү§иЎҢжҲ‘们еҶҷзҡ„sqlпјҢиҝҷж ·еӨ„зҗҶиө·жқҘжӣҙеҠ зҡ„еҗҲзҗҶиҖҢдё”й«ҳж•ҲгҖӮеңЁе·ҘдҪңзҡ„ејҖеҸ‘иҝҮзЁӢдёӯпјҢжҲ‘们иҰҒз»“еҗҲеҶҷд»Јз Ғе’ҢеҶҷsqlзҡ„еҗ„иҮӘзҡ„жүҖй•ҝжқҘеӨ„зҗҶжҲ‘们зҡ„й—®йўҳпјҢиҝҷж ·дјҡжӣҙеҠ зҡ„й«ҳж•ҲгҖӮ
еҶҷиҝҷзҜҮеҚҡе®ўпјҢиҠұиҙ№дәҶжҲ‘дёӨе‘Ёзҡ„ж—¶й—ҙпјҢз”ұдәҺе·ҘдҪңжҜ”иҫғеҝҷпјҢеҸӘжңүеңЁдёҡдҪҷж—¶й—ҙиҝӣиЎҢжҖқиҖғе’ҢжҖ»з»“гҖӮд№ҹз®—еҜ№иҮӘе·ұеӯҰд№ зҡ„дёҖдёӘдәӨд»ЈгҖӮе…ідәҺsparkSQLзҡ„дёӨдёӘзұ»HiveContextе’ҢSQLContextжҸҗдҫӣзҡ„udfж–№жі•пјҢеҰӮжһңз”ЁеҘҪдәҶudfж–№жі•пјҢеҸҜд»ҘдҪҝжҲ‘们代з Ғзҡ„ејҖеҸ‘жӣҙеҠ зҡ„з®ҖжҙҒе’Ңй«ҳж•ҲпјҢеҸҜиҜ»жҖ§д№ҹжҳҜеҫҲејәзҡ„гҖӮз”ұдәҺеңЁд»Јз ҒдёӯжіЁеҶҢudfж–№жі•пјҢиҝҳжңүеҫҲеӨҡеҫҲз»Ҷзҡ„зҹҘиҜҶзӮ№йңҖиҰҒжіЁж„ҸпјҢжҲ‘еҮҶеӨҮеңЁеҸҰеӨ–еҶҷдёҖзҜҮеҚҡе®ўиҝӣиЎҢиҜҰз»Ҷзҡ„д»Ӣз»ҚгҖӮ
зҙҜжӯ»жҲ‘дәҶпјҢе·Із»ҸдёӨеӨ©е®…еңЁе®¶йҮҢдәҶпјҢиҜҘеҮәеҺ»жәңиҫҫжәңиҫҫдәҶпјҒпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ