жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢSparkSQLжҖҺд№Ҳз”ЁпјҢзӣёдҝЎеӨ§йғЁеҲҶдәәйғҪиҝҳдёҚжҖҺд№ҲдәҶи§ЈпјҢеӣ жӯӨеҲҶдә«иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҸӮиҖғдёҖдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеӨ§жңү收иҺ·пјҢдёӢйқўи®©жҲ‘们дёҖиө·еҺ»дәҶи§ЈдёҖдёӢеҗ§пјҒ
1.0д»ҘеүҚпјҡ Shark
1.1.xејҖе§ӢпјҡSparkSQL(еҸӘжҳҜжөӢиҜ•жҖ§зҡ„) SQL
1.3.x: SparkSQL(жӯЈејҸзүҲжң¬)+Dataframe
1.5.x: SparkSQL й’Ёдёқи®ЎеҲ’
1.6.xпјҡ SparkSQL+DataFrame+DataSet(жөӢиҜ•зүҲжң¬)
2.x:
SparkSQL+DataFrame+DataSet(жӯЈејҸзүҲжң¬)
SparkSQL:иҝҳжңүе…¶д»–зҡ„дјҳеҢ–
StructuredStreaming(DataSet)
Spark on Hiveе’ҢHive on Spark
Spark on HiveпјҡHiveеҸӘдҪңдёәеӮЁеӯҳи§’иүІпјҢSparkиҙҹиҙЈsqlи§ЈжһҗдјҳеҢ–пјҢжү§иЎҢгҖӮ
Hive on SparkпјҡHiveеҚідҪңдёәеӯҳеӮЁеҸҲиҙҹиҙЈsqlзҡ„и§ЈжһҗдјҳеҢ–пјҢSparkиҙҹиҙЈжү§иЎҢгҖӮ
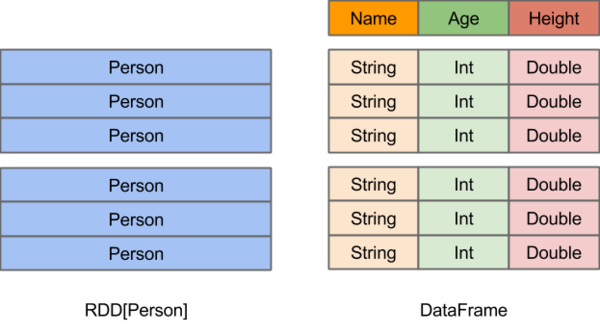
spark SQLжҳҜsparkзҡ„дёҖдёӘжЁЎеқ—пјҢдё»иҰҒз”ЁдәҺиҝӣиЎҢз»“жһ„еҢ–ж•°жҚ®зҡ„еӨ„зҗҶгҖӮе®ғжҸҗдҫӣзҡ„жңҖж ёеҝғзҡ„зј–зЁӢжҠҪиұЎе°ұжҳҜDataFrameгҖӮ
жҸҗдҫӣдёҖдёӘзј–зЁӢжҠҪиұЎпјҲDataFrameпјү 并且дҪңдёәеҲҶеёғејҸ SQLжҹҘиҜўеј•ж“Һ
DataFrameпјҡе®ғеҸҜд»Ҙж №жҚ®еҫҲеӨҡжәҗиҝӣиЎҢжһ„е»әпјҢеҢ…жӢ¬пјҡз»“жһ„еҢ–зҡ„ж•°жҚ®ж–Ү件пјҢhiveдёӯзҡ„иЎЁпјҢеӨ–йғЁзҡ„е…ізі»еһӢж•°жҚ®еә“пјҢд»ҘеҸҠRDD
е°ҶSpark SQLиҪ¬еҢ–дёәRDDпјҢ然еҗҺжҸҗдәӨеҲ°йӣҶзҫӨжү§иЎҢ
пјҲ1пјүе®№жҳ“ж•ҙеҗҲ
пјҲ2пјүз»ҹдёҖзҡ„ж•°жҚ®и®ҝй—®ж–№ејҸ
пјҲ3пјүе…је®№ Hive
пјҲ4пјүж ҮеҮҶзҡ„ж•°жҚ®иҝһжҺҘ
SparkSessionжҳҜSpark 2.0еј•еҰӮзҡ„ж–°жҰӮеҝөгҖӮSparkSessionдёәз”ЁжҲ·жҸҗдҫӣдәҶз»ҹдёҖзҡ„еҲҮе…ҘзӮ№пјҢжқҘи®©з”ЁжҲ·еӯҰд№ sparkзҡ„еҗ„йЎ№еҠҹиғҪгҖӮ
вҖғвҖғеңЁsparkзҡ„ж—©жңҹзүҲжң¬дёӯпјҢSparkContextжҳҜsparkзҡ„дё»иҰҒеҲҮе…ҘзӮ№пјҢз”ұдәҺRDDжҳҜдё»иҰҒзҡ„APIпјҢжҲ‘们йҖҡиҝҮsparkcontextжқҘеҲӣе»әе’Ңж“ҚдҪңRDDгҖӮеҜ№дәҺжҜҸдёӘе…¶д»–зҡ„APIпјҢжҲ‘们йңҖиҰҒдҪҝз”ЁдёҚеҗҢзҡ„contextгҖӮдҫӢеҰӮпјҢеҜ№дәҺStremingпјҢжҲ‘们йңҖиҰҒдҪҝз”ЁStreamingContextпјӣеҜ№дәҺsqlпјҢдҪҝз”ЁsqlContextпјӣеҜ№дәҺHiveпјҢдҪҝз”ЁhiveContextгҖӮдҪҶжҳҜйҡҸзқҖDataSetе’ҢDataFrameзҡ„APIйҖҗжёҗжҲҗдёәж ҮеҮҶзҡ„APIпјҢе°ұйңҖиҰҒдёә他们е»әз«ӢжҺҘе…ҘзӮ№гҖӮжүҖд»ҘеңЁspark2.0дёӯпјҢеј•е…ҘSparkSessionдҪңдёәDataSetе’ҢDataFrame APIзҡ„еҲҮе…ҘзӮ№пјҢSparkSessionе°ҒиЈ…дәҶSparkConfгҖҒSparkContextе’ҢSQLContextгҖӮдёәдәҶеҗ‘еҗҺе…је®№пјҢSQLContextе’ҢHiveContextд№ҹиў«дҝқеӯҳдёӢжқҘгҖӮ
гҖҖгҖҖ
гҖҖгҖҖSparkSessionе®һиҙЁдёҠжҳҜSQLContextе’ҢHiveContextзҡ„з»„еҗҲпјҲжңӘжқҘеҸҜиғҪиҝҳдјҡеҠ дёҠStreamingContextпјүпјҢжүҖд»ҘеңЁSQLContextе’ҢHiveContextдёҠеҸҜз”Ёзҡ„APIеңЁSparkSessionдёҠеҗҢж ·жҳҜеҸҜд»ҘдҪҝз”Ёзҡ„гҖӮSparkSessionеҶ…йғЁе°ҒиЈ…дәҶsparkContextпјҢжүҖд»Ҙи®Ўз®—е®һйҷ…дёҠжҳҜз”ұsparkContextе®ҢжҲҗзҡ„гҖӮ
зү№зӮ№пјҡ
гҖҖгҖҖ ---- дёәз”ЁжҲ·жҸҗдҫӣдёҖдёӘз»ҹдёҖзҡ„еҲҮе…ҘзӮ№дҪҝз”ЁSpark еҗ„йЎ№еҠҹиғҪ
---- е…Ғи®ёз”ЁжҲ·йҖҡиҝҮе®ғи°ғз”Ё DataFrame е’Ң Dataset зӣёе…і API жқҘзј–еҶҷзЁӢеәҸ
---- еҮҸе°‘дәҶз”ЁжҲ·йңҖиҰҒдәҶи§Јзҡ„дёҖдәӣжҰӮеҝөпјҢеҸҜд»ҘеҫҲе®№жҳ“зҡ„дёҺ Spark иҝӣиЎҢдәӨдә’
---- дёҺ Spark дәӨдә’д№Ӣж—¶дёҚйңҖиҰҒжҳҫзӨәзҡ„еҲӣе»ә SparkConf, SparkContext д»ҘеҸҠ SQlContextпјҢиҝҷдәӣеҜ№иұЎе·Із»Ҹе°Ғй—ӯеңЁ SparkSession дёӯ
еңЁSparkдёӯпјҢDataFrameжҳҜдёҖз§Қд»ҘRDDдёәеҹәзЎҖзҡ„еҲҶеёғејҸж•°жҚ®йӣҶпјҢзұ»дјјдәҺдј з»ҹж•°жҚ®еә“дёӯзҡ„дәҢз»ҙиЎЁж јгҖӮDataFrameдёҺRDDзҡ„дё»иҰҒеҢәеҲ«еңЁдәҺпјҢеүҚиҖ…еёҰжңүschemaе…ғдҝЎжҒҜпјҢеҚіDataFrameжүҖиЎЁзӨәзҡ„дәҢз»ҙиЎЁж•°жҚ®йӣҶзҡ„жҜҸдёҖеҲ—йғҪеёҰжңүеҗҚз§°е’Ңзұ»еһӢгҖӮиҝҷдҪҝеҫ—Spark SQLеҫ—д»ҘжҙһеҜҹжӣҙеӨҡзҡ„з»“жһ„дҝЎжҒҜпјҢд»ҺиҖҢеҜ№и—ҸдәҺDataFrameиғҢеҗҺзҡ„ж•°жҚ®жәҗд»ҘеҸҠдҪңз”ЁдәҺDataFrameд№ӢдёҠзҡ„еҸҳжҚўиҝӣиЎҢдәҶй’ҲеҜ№жҖ§зҡ„дјҳеҢ–пјҢжңҖз»ҲиҫҫеҲ°еӨ§е№…жҸҗеҚҮиҝҗиЎҢж—¶ж•ҲзҺҮзҡ„зӣ®ж ҮгҖӮеҸҚи§ӮRDDпјҢз”ұдәҺж— д»Һеҫ—зҹҘжүҖеӯҳж•°жҚ®е…ғзҙ зҡ„е…·дҪ“еҶ…йғЁз»“жһ„пјҢSpark CoreеҸӘиғҪеңЁstageеұӮйқўиҝӣиЎҢз®ҖеҚ•гҖҒйҖҡз”Ёзҡ„жөҒж°ҙзәҝдјҳеҢ–гҖӮ
дҪҝз”Ёspark1.xзүҲжң¬зҡ„ж–№ејҸ
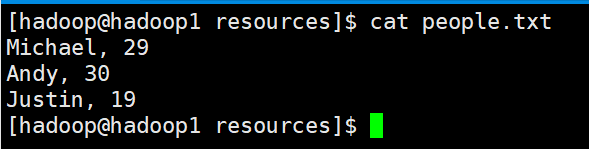
жөӢиҜ•ж•°жҚ®зӣ®еҪ•пјҡspark/examples/src/main/resourcesпјҲsparkзҡ„е®үиЈ…зӣ®еҪ•йҮҢйқўпјү
people.txt
//е®ҡд№үcase classпјҢзӣёеҪ“дәҺиЎЁз»“жһ„
case class People(var name:String,var age:Int)
object TestDataFrame1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDDToDataFrame").setMaster("local")
val sc = new SparkContext(conf)
val context = new SQLContext(sc)
// е°Ҷжң¬ең°зҡ„ж•°жҚ®иҜ»е…Ҙ RDDпјҢ 并е°Ҷ RDD дёҺ case class е…іиҒ”
val peopleRDD = sc.textFile("E:\\666\\people.txt")
.map(line => People(line.split(",")(0), line.split(",")(1).trim.toInt))
import context.implicits._
// е°ҶRDD иҪ¬жҚўжҲҗ DataFrames
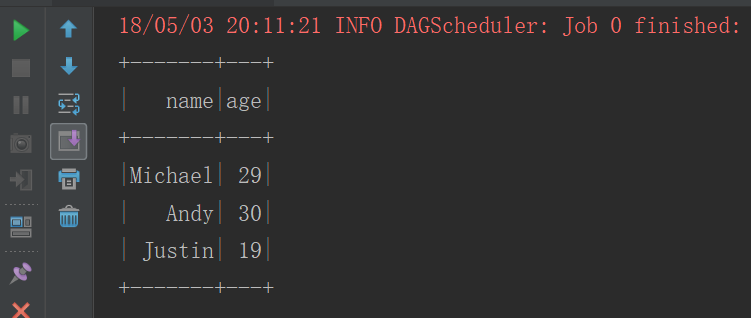
val df = peopleRDD.toDF
//е°ҶDataFramesеҲӣе»әжҲҗдёҖдёӘдёҙж—¶зҡ„и§Ҷеӣҫ
df.createOrReplaceTempView("people")
//дҪҝз”ЁSQLиҜӯеҸҘиҝӣиЎҢжҹҘиҜў
context.sql("select * from people").show()
}
}иҝҗиЎҢз»“жһң
object TestDataFrame2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("TestDataFrame2").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val fileRDD = sc.textFile("E:\\666\\people.txt")
// е°Ҷ RDD ж•°жҚ®жҳ е°„жҲҗ RowпјҢйңҖиҰҒ import org.apache.spark.sql.Row
val rowRDD: RDD[Row] = fileRDD.map(line => {
val fields = line.split(",")
Row(fields(0), fields(1).trim.toInt)
})
// еҲӣе»ә StructType жқҘе®ҡд№үз»“жһ„
val structType: StructType = StructType(
//еӯ—ж®өеҗҚпјҢеӯ—ж®өзұ»еһӢпјҢжҳҜеҗҰеҸҜд»Ҙдёәз©ә
StructField("name", StringType, true) ::
StructField("age", IntegerType, true) :: Nil
)
/**
* rows: java.util.List[Row],
* schema: StructType
* */
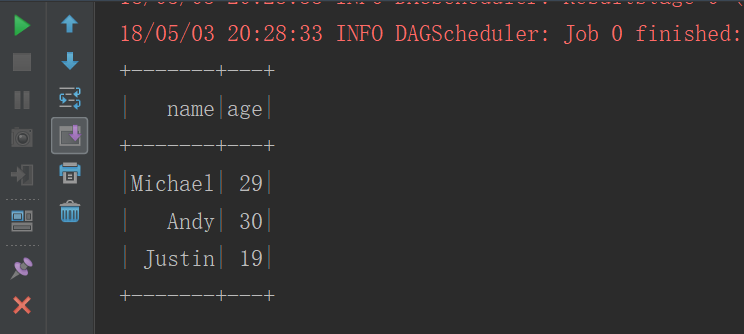
val df: DataFrame = sqlContext.createDataFrame(rowRDD,structType)
df.createOrReplaceTempView("people")
sqlContext.sql("select * from people").show()
}
}иҝҗиЎҢз»“жһң
object TestDataFrame3 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("TestDataFrame2").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val df: DataFrame = sqlContext.read.json("E:\\666\\people.json")
df.createOrReplaceTempView("people")
sqlContext.sql("select * from people").show()
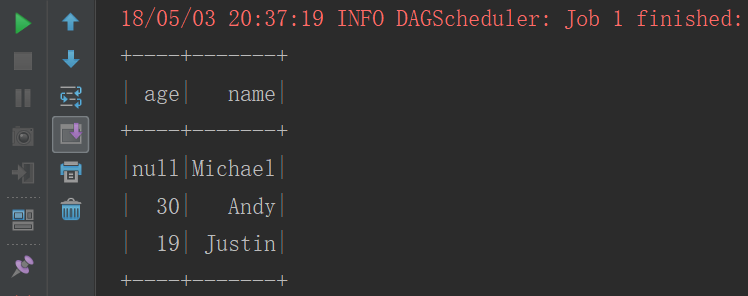
}
}
object TestRead {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("TestDataFrame2").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
//ж–№ејҸдёҖ
val df1 = sqlContext.read.json("E:\\666\\people.json")
val df2 = sqlContext.read.parquet("E:\\666\\users.parquet")
//ж–№ејҸдәҢ
val df3 = sqlContext.read.format("json").load("E:\\666\\people.json")
val df4 = sqlContext.read.format("parquet").load("E:\\666\\users.parquet")
//ж–№ејҸдёүпјҢй»ҳи®ӨжҳҜparquetж јејҸ
val df5 = sqlContext.load("E:\\666\\users.parquet")
}
}object TestSave {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("TestDataFrame2").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val df1 = sqlContext.read.json("E:\\666\\people.json")
//ж–№ејҸдёҖ
df1.write.json("E:\\111")
df1.write.parquet("E:\\222")
//ж–№ејҸдәҢ
df1.write.format("json").save("E:\\333")
df1.write.format("parquet").save("E:\\444")
//ж–№ејҸдёү
df1.write.save("E:\\555")
}
}дҪҝз”Ёmode
df1.write.format("parquet").mode(SaveMode.Ignore).save("E:\\444")
еҸӮиҖғ4.1
еҸӮиҖғ4.1
5.3гҖҖж•°жҚ®жәҗд№ӢMysql
object TestMysql {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("TestMysql").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val url = "jdbc:mysql://192.168.123.102:3306/hivedb"
val table = "dbs"
val properties = new Properties()
properties.setProperty("user","root")
properties.setProperty("password","root")
//йңҖиҰҒдј е…ҘMysqlзҡ„URLгҖҒиЎЁжҳҺгҖҒpropertiesпјҲиҝһжҺҘж•°жҚ®еә“зҡ„з”ЁжҲ·еҗҚеҜҶз Ғпјү
val df = sqlContext.read.jdbc(url,table,properties)
df.createOrReplaceTempView("dbs")
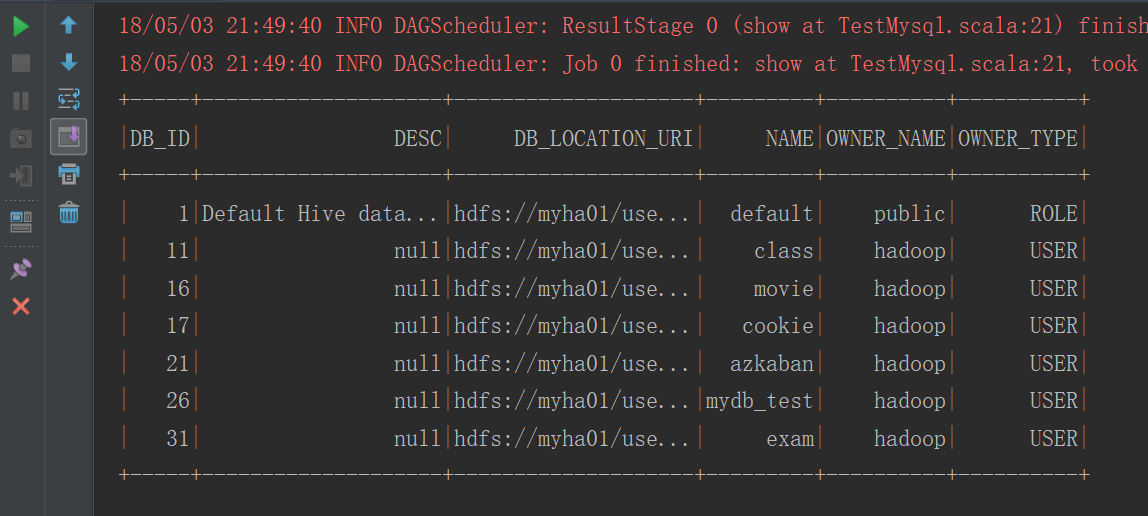
sqlContext.sql("select * from dbs").show()
}
}иҝҗиЎҢз»“жһң
пјҲ1пјүеҮҶеӨҮе·ҘдҪң
еңЁpom.xmlж–Ү件дёӯж·»еҠ дҫқиө–
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-hive --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2.11</artifactId> <version>2.3.0</version> </dependency>
ејҖеҸ‘зҺҜеўғеҲҷжҠҠresourceж–Ү件еӨ№дёӢж·»еҠ hive-site.xmlж–Ү件пјҢйӣҶзҫӨзҺҜеўғжҠҠhiveзҡ„й…ҚзҪ®ж–Ү件иҰҒеҸ‘еҲ°$SPARK_HOME/confзӣ®еҪ•дёӢ
<configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hivedb?createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description> <!-- еҰӮжһң mysql е’Ң hive еңЁеҗҢдёҖдёӘжңҚеҠЎеҷЁиҠӮзӮ№пјҢйӮЈд№ҲиҜ·жӣҙж”№ hadoop02 дёә localhost --> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root</value> <description>password to use against metastore database</description> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/hive/warehouse</value> <description>hive default warehouse, if nessecory, change it</description> </property> </configuration>
пјҲ2пјүжөӢиҜ•д»Јз Ғ
object TestHive {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName(this.getClass.getSimpleName)
val sc = new SparkContext(conf)
val sqlContext = new HiveContext(sc)
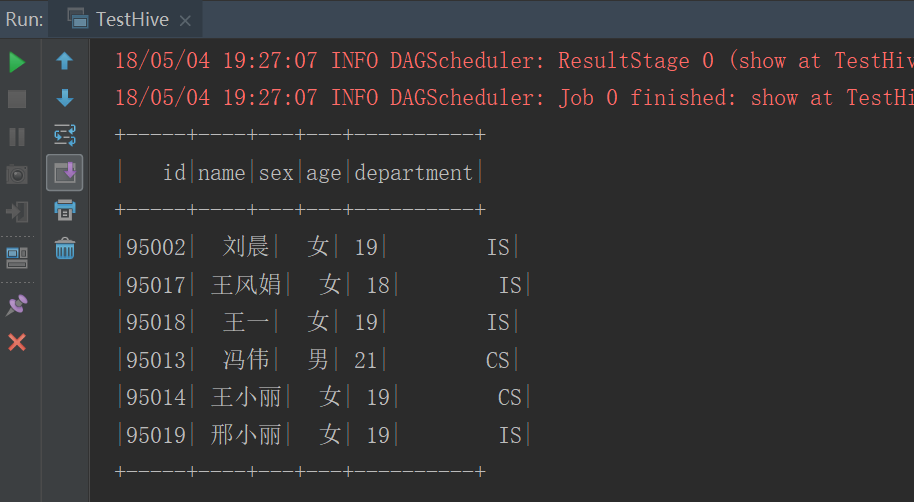
sqlContext.sql("select * from myhive.student").show()
}
}иҝҗиЎҢз»“жһң
SparkSQL зҡ„е…ғж•°жҚ®зҡ„зҠ¶жҖҒжңүдёӨз§Қпјҡ
1гҖҒin_memory,з”Ёе®ҢдәҶе…ғж•°жҚ®д№ҹе°ұдёўдәҶ
2гҖҒhive , йҖҡиҝҮhiveеҺ»дҝқеӯҳзҡ„пјҢд№ҹе°ұжҳҜиҜҙпјҢhiveзҡ„е…ғж•°жҚ®еӯҳеңЁе“Әе„ҝпјҢе®ғзҡ„е…ғж•°жҚ®д№ҹе°ұеӯҳеңЁе“Әе„ҝгҖӮ
жҚўеҸҘиҜқиҜҙпјҢSparkSQLзҡ„ж•°жҚ®д»“еә“еңЁе»әз«ӢеңЁHiveд№ӢдёҠе®һзҺ°зҡ„гҖӮжҲ‘们иҰҒз”ЁSparkSQLеҺ»жһ„е»әж•°жҚ®д»“еә“зҡ„ж—¶еҖҷпјҢеҝ…йЎ»дҫқиө–дәҺHiveгҖӮ
еҰӮжһңз”ЁжҲ·зӣҙжҺҘиҝҗиЎҢbin/spark-sqlе‘Ҫд»ӨгҖӮдјҡеҜјиҮҙжҲ‘们зҡ„е…ғж•°жҚ®жңүдёӨз§ҚзҠ¶жҖҒпјҡ
1гҖҒin-memoryзҠ¶жҖҒпјҡеҰӮжһңSPARK-HOME/confзӣ®еҪ•дёӢжІЎжңүж”ҫзҪ®hive-site.xmlж–Ү件пјҢе…ғж•°жҚ®зҡ„зҠ¶жҖҒе°ұжҳҜin-memory
2гҖҒhiveзҠ¶жҖҒпјҡеҰӮжһңжҲ‘们еңЁSPARK-HOME/confзӣ®еҪ•дёӢж”ҫзҪ®дәҶпјҢhive-site.xmlж–Ү件пјҢйӮЈд№Ҳй»ҳи®Өжғ…еҶөдёӢпјҢspark-sqlзҡ„е…ғж•°жҚ®зҡ„зҠ¶жҖҒе°ұжҳҜhive.
д»ҘдёҠжҳҜвҖңSparkSQLжҖҺд№Ҳз”ЁвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүжүҖеё®еҠ©пјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ