жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮж–Үз« дёәеӨ§е®¶еұ•зӨәдәҶеҲ©з”ЁpythonзҲ¬иҷ«жҖҺд№Ҳз ҙи§ЈеҠ еҜҶеӯ—дҪ“пјҢеҶ…е®№з®ҖжҳҺжүјиҰҒ并且容жҳ“зҗҶи§ЈпјҢз»қеҜ№иғҪдҪҝдҪ зңјеүҚдёҖдә®пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« зҡ„иҜҰз»Ҷд»Ӣз»ҚеёҢжңӣдҪ иғҪжңүжүҖ收иҺ·гҖӮ
PythonжҳҜдёҖз§Қи·Ёе№іеҸ°зҡ„гҖҒе…·жңүи§ЈйҮҠжҖ§гҖҒзј–иҜ‘жҖ§гҖҒдә’еҠЁжҖ§е’Ңйқўеҗ‘еҜ№иұЎзҡ„и„ҡжң¬иҜӯиЁҖпјҢе…¶жңҖеҲқзҡ„и®ҫи®ЎжҳҜз”ЁдәҺзј–еҶҷиҮӘеҠЁеҢ–и„ҡжң¬пјҢйҡҸзқҖзүҲжң¬зҡ„дёҚж–ӯжӣҙж–°е’Ңж–°еҠҹиғҪзҡ„ж·»еҠ пјҢеёёз”ЁдәҺз”ЁдәҺејҖеҸ‘зӢ¬з«Ӣзҡ„йЎ№зӣ®е’ҢеӨ§еһӢйЎ№зӣ®гҖӮ
жЎҲдҫӢзӣ®зҡ„пјҡ
йҖҡиҝҮзҲ¬еҸ–иө·е°ҸзӮ№е°ҸиҜҙжңҲзҘЁжҰңзҡ„еҗҚз§°е’ҢжңҲзҘЁж•°пјҢд»Ӣз»ҚеҰӮдҪ•з ҙи§Јеӯ—дҪ“еҠ еҜҶзҡ„еҸҚзҲ¬пјҢе°ҶеҠ еҜҶзҡ„ж•°жҚ®иҪ¬еҢ–жҲҗжҳҺж–Үж•°жҚ®гҖӮ
зЁӢеәҸеҠҹиғҪпјҡ
иҫ“е…ҘиҰҒзҲ¬еҸ–зҡ„йЎөж•°пјҢеҫ—еҲ°жҜҸдёҖйЎөеҜ№еә”зҡ„е°ҸиҜҙеҗҚз§°е’ҢжңҲзҘЁж•°гҖӮ
жЎҲдҫӢеҲҶжһҗпјҡ жүҫеҲ°зӣ®ж Үзҡ„urlпјҡ
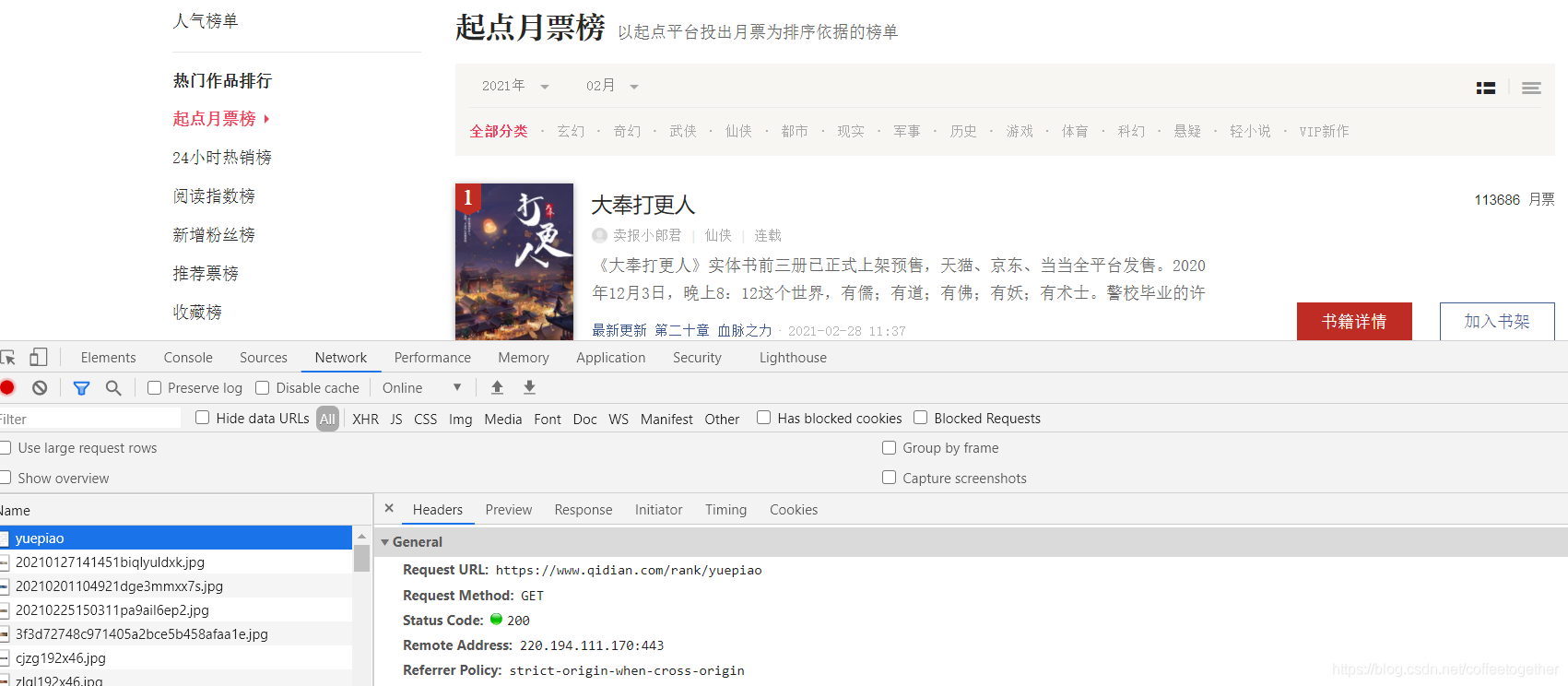
пјҲеҸій”®жЈҖжҹҘпјүжүҫеҲ°е°ҸиҜҙеҗҚз§°жүҖеңЁзҡ„дҪҚзҪ®пјҡ
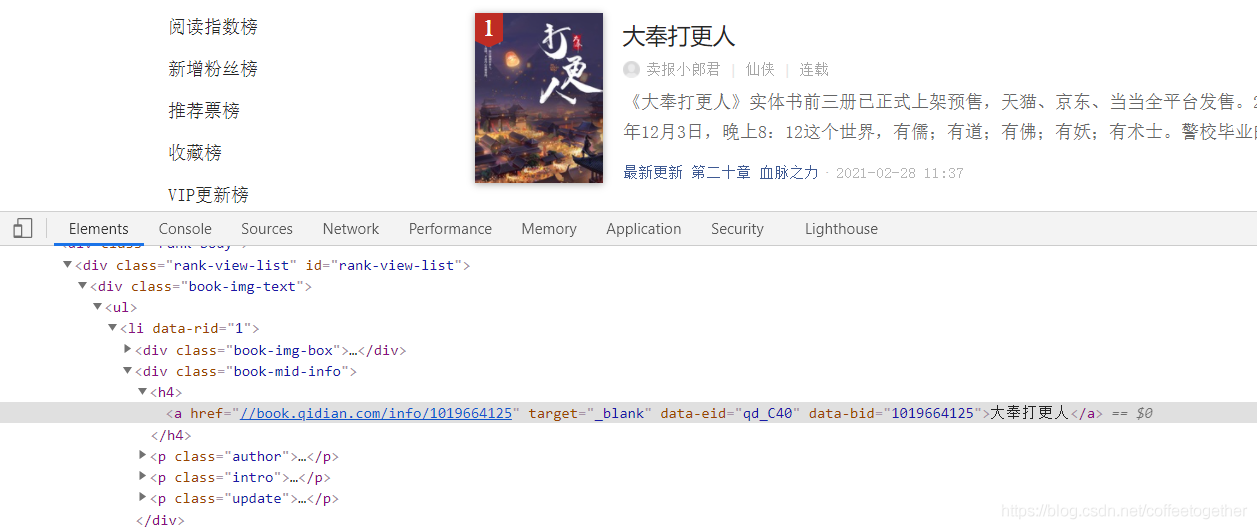
йҖҡиҝҮеҗҚз§°жүҖеңЁзҡ„иҠӮзӮ№дҪҚзҪ®пјҢжүҫеҲ°е°ҸиҜҙеҗҚз§°зҡ„xpathиҜӯжі•пјҡ
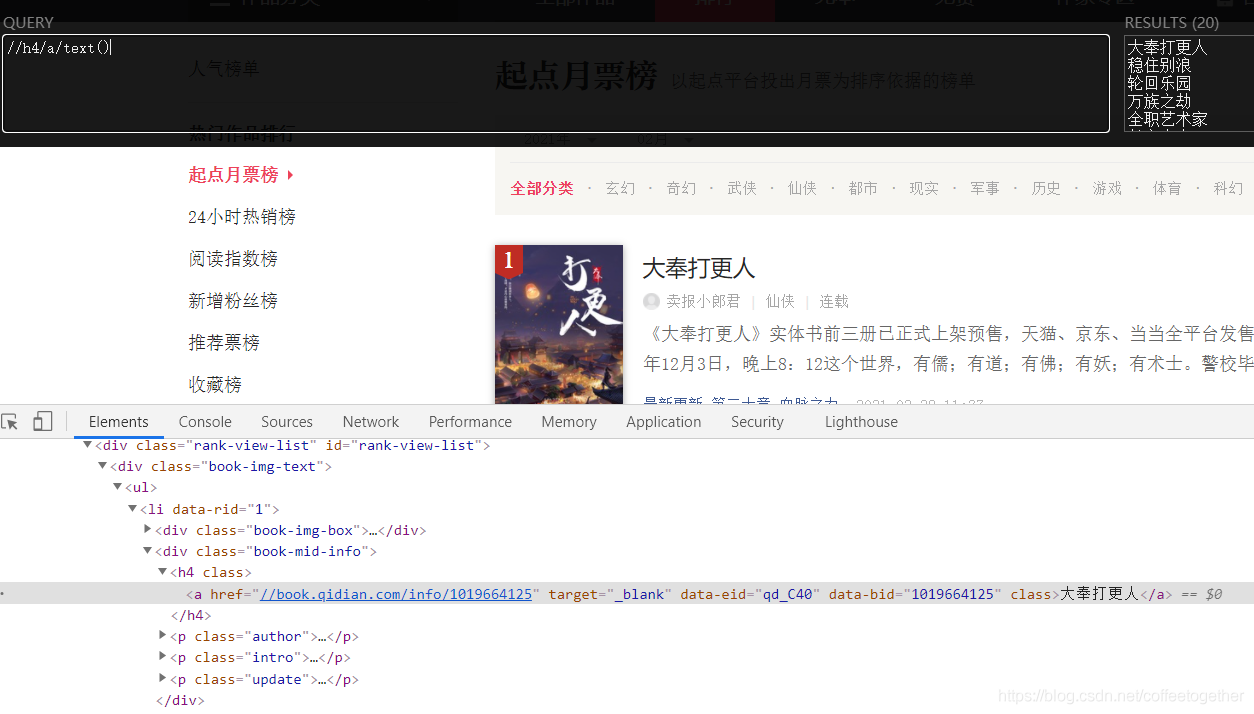
пјҲеҸій”®жЈҖжҹҘпјүжүҫеҲ°жңҲзҘЁж•°жүҖеңЁзҡ„дҪҚзҪ®пјҡ
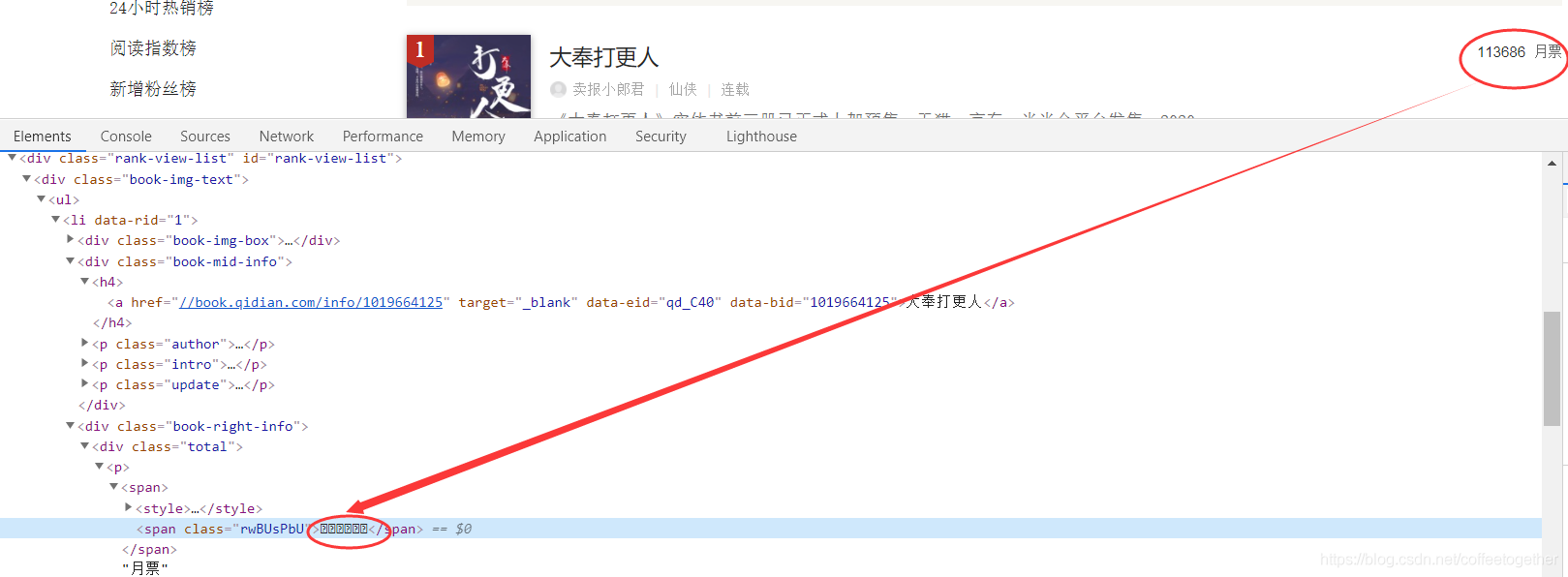
з”ұдёҠеӣҫеҸ‘зҺ°пјҢжЈҖжҹҘжңҲзҘЁж•°жҚ®зҡ„ж–Үжң¬пјҢеҫ—еҲ°дёҖдёІеҠ еҜҶж•°жҚ®гҖӮ
жҲ‘们йҖҡиҝҮxpathhelperиҝӣиЎҢи°ғиҜ•еҸ‘зҺ°пјҢж— жі•жүҫеҲ°еҠ еҜҶж•°жҚ®зҡ„иҜӯжі•гҖӮеӣ жӯӨпјҢйңҖиҰҒйҖҡиҝҮжӯЈеҲҷиЎЁиҫҫејҸиҝӣиЎҢжҸҗеҸ–гҖӮ
йҖҡиҝҮжӯЈеҲҷиҝӣиЎҢж•°жҚ®жҸҗеҸ–гҖӮ

жӯЈеҲҷиЎЁиҫҫејҸеҰӮдёӢпјҡ

еҫ—еҲ°зҡ„еҠ еҜҶж•°жҚ®еҰӮдёӢпјҡ

з ҙи§ЈеҠ еҜҶж•°жҚ®жҳҜжң¬ж¬ЎжЎҲдҫӢзҡ„е…ій”®пјҡ
既然жҳҜеҠ еҜҶж•°жҚ®пјҢе°ұдјҡжңүеҠ еҜҶж•°жҚ®жүҖеҜ№еә”зҡ„еҠ еҜҶ规еҲҷзҡ„Fontж–Ү件гҖӮ
йҖҡиҝҮжүҫеҲ°Fontеӯ—дҪ“ж–Ү件дёӯж•°жҚ®еҠ еҜҶж–Ү件зҡ„urlпјҢеҸ‘йҖҒиҜ·жұӮпјҢиҺ·еҸ–е“Қеә”пјҢеҫ—еҲ°еҠ еҜҶж•°жҚ®зҡ„woffж–Ү件гҖӮ
жіЁпјҡжҲ‘们йңҖиҰҒзҡ„woffж–Ү件пјҢеҗҚз§°дёҺеҠ еҜҶжңҲзҘЁж•°еүҚйқўзҡ„classеұһжҖ§зӣёеҗҢгҖӮ
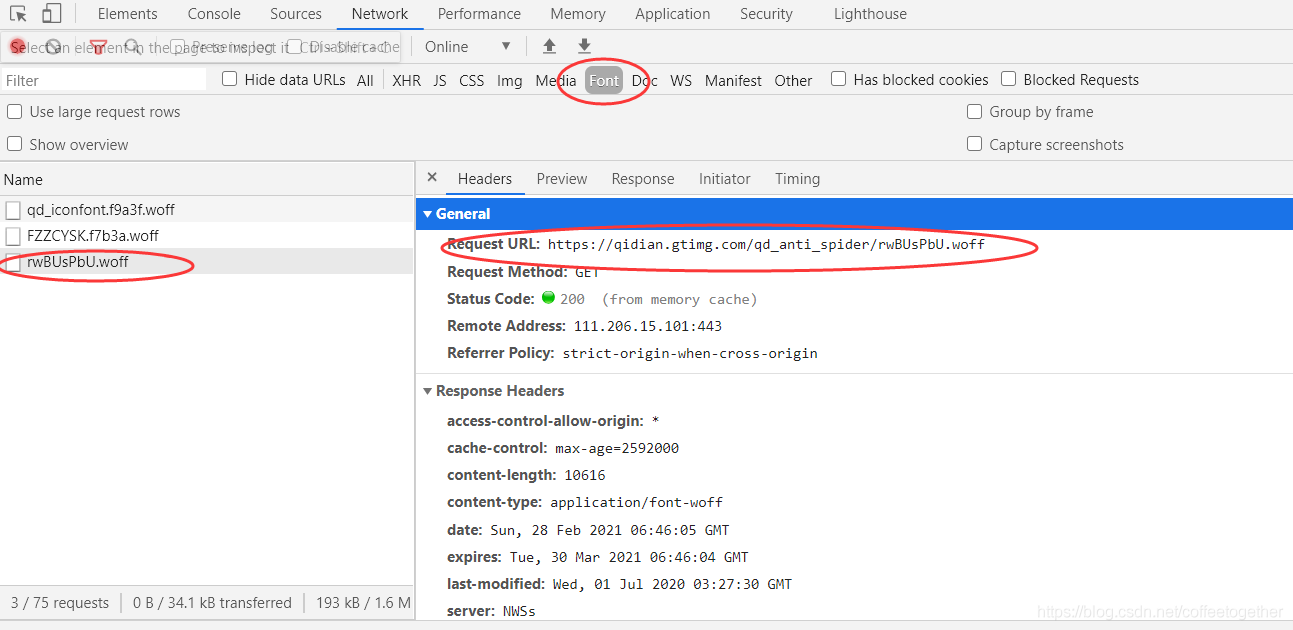
еҰӮдёӢеӣҫпјҢдёӢиҪҪwoffж–Ү件пјҡ
жүҫеҲ°16иҝӣеҲ¶зҡ„ж•°еӯ—еҜ№еә”зҡ„иӢұж–Үж•°еӯ—гҖӮ
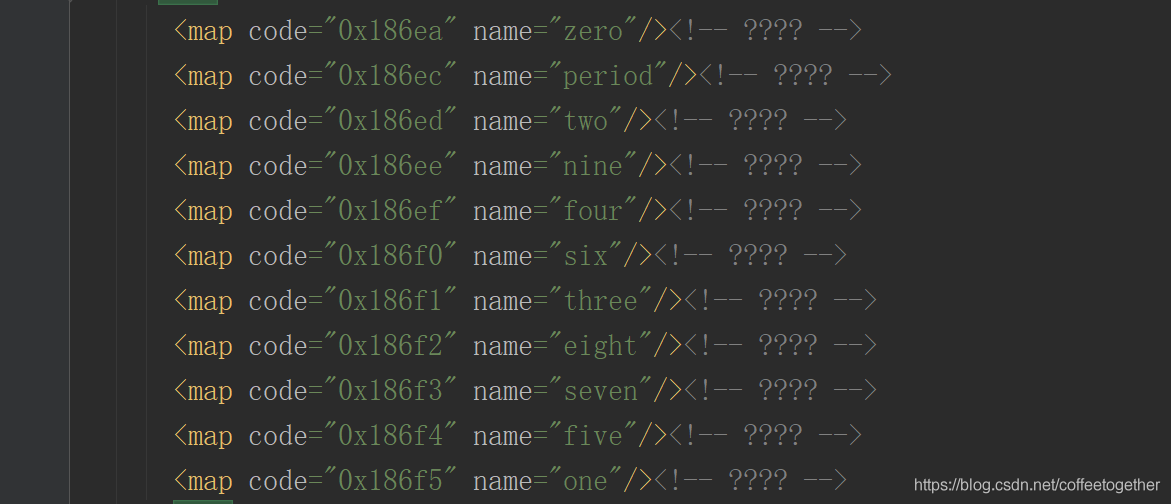
е…¶ж¬ЎпјҢжҲ‘们йңҖиҰҒйҖҡиҝҮ第дёүж–№еә“TTFontе°Ҷж–Ү件дёӯзҡ„16иҝӣеҲ¶ж•°иҪ¬жҚўжҲҗ10иҝӣеҲ¶пјҢе°ҶиӢұж–Үж•°еӯ—иҪ¬жҚўжҲҗйҳҝжӢүдјҜж•°еӯ—гҖӮеҰӮдёӢеӣҫпјҡ

и§ЈжһҗеҮәжҜҸдёӘеҠ еҜҶж•°жҚ®еҜ№еә”зҡ„еҜ№еә”зҡ„жңҲзҘЁж•°зҡ„ж•°еӯ—еҰӮдёӢпјҡ

жіЁж„Ҹпјҡ
з”ұдәҺжҲ‘们еңЁдёҠйқўйҖҡиҝҮжӯЈеҲҷиЎЁејҸиҺ·еҫ—зҡ„еҠ еҜҶж•°жҚ®жҗәеёҰзү№ж®Ҡз¬ҰеҸ·
еӣ жӯӨи§ЈжһҗеҮәжңҲзҘЁж•°жҚ®дёӯзҡ„ж•°еӯ—д№ӢеҗҺпјҢйҷӨдәҶе°Ҷзү№ж®Ҡз¬ҰеҸ·еҺ»йҷӨпјҢиҝҳйңҖжҠҠжҜҸдёӘж•°еӯ—иҝӣиЎҢжӢјжҺҘпјҢеҫ—еҲ°жңҖеҗҺзҡ„зҘЁж•°гҖӮ
жңҖеҗҺпјҢйҖҡиҝҮеҜ№жҜ”дёҚеҗҢйЎөзҡ„urlпјҢжүҫеҲ°зҝ»йЎөзҡ„规еҫӢпјҡ



еҜ№жҜ”дёүдёӘдёҚеҗҢurlеҸ‘зҺ°пјҢзҝ»йЎөзҡ„规еҫӢеңЁдәҺеҸӮж•°page
жүҖд»Ҙй—®йўҳеҲҶжһҗе®ҢжҜ•пјҢејҖе§Ӣд»Јз Ғпјҡ
import requests
from lxml import etree
import re
from fontTools.ttLib import TTFont
import json
if __name__ == '__main__':
# иҫ“е…ҘзҲ¬еҸ–зҡ„йЎөж•°гҖҒ
pages = int(input('иҜ·иҫ“е…ҘиҰҒзҲ¬еҸ–зҡ„йЎөж•°пјҡ')) # eg:pages=1,2
for i in range(pages): # i=0,(0,1)
page = i+1 # 1,(1,2)
# зЎ®и®Өзӣ®ж Үзҡ„url
url_ = f'https://www.qidian.com/rank/yuepiao?page={page}'
# жһ„йҖ иҜ·жұӮеӨҙеҸӮж•°
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36'
}
# еҸ‘йҖҒиҜ·жұӮпјҢиҺ·еҸ–е“Қеә”
response_ = requests.get(url_,headers=headers)
# е“Қеә”зұ»еһӢдёәhtmlй—®ж–Үжң¬
str_data = response_.text
# е°Ҷhtmlж–Үжң¬иҪ¬жҚўжҲҗpythonж–Ү件
py_data = etree.HTML(str_data)
# жҸҗеҸ–ж–Үжң¬дёӯзҡ„зӣ®ж Үж•°жҚ®
title_list = py_data.xpath('//h5/a[@target="_blank"]/text() ')
# жҸҗеҸ–жңҲзҘЁж•°,з”ұдәҺеҲ©з”ЁxpathиҜӯжі•ж— жі•жҸҗеҸ–пјҢеӣ жӯӨжҚўз”ЁжӯЈеҲҷиЎЁиҫҫејҸпјҢжӯЈеҲҷжҸҗеҸ–зҡ„зӣ®ж Үдёәresponse_.text
mon_list = re.findall('</style><span class=".*?">(.*?)</span></span>',str_data)
print(mon_list)
# иҺ·еҸ–еӯ—дҪ“еҸҚзҲ¬woffж–Ү件еҜ№еә”зҡ„urlпјҢxpathй…ҚеҗҲжӯЈеҲҷдҪҝз”Ё
fonturl_str = py_data.xpath('//p/span/style/text()')
font_url = re.findall(r"format\('eot'\); src: url\('(.*?)'\) format\('woff'\)",str_data)[0]
print(font_url)
# иҺ·еҫ—urlд№ӢеҗҺпјҢжһ„йҖ иҜ·жұӮеӨҙиҺ·еҸ–е“Қеә”
headers_ = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36',
'Referer':'https://www.qidian.com/'
}
# еҸ‘йҖҒиҜ·жұӮпјҢиҺ·еҸ–е“Қеә”
font_response = requests.get(font_url,headers=headers_)
# ж–Ү件зұ»еһӢжңӘзҹҘпјҢеӣ жӯӨз”ЁдҪҝз”Ёcontentж јејҸ
font_data = font_response.content
# дҝқеӯҳеҲ°жң¬ең°
with open('еҠ еҜҶfontж–Ү件.woff','wb')as f:
f.write(font_data)
# и§ЈжһҗеҠ еҜҶзҡ„fontж–Ү件
font_obj = TTFont('еҠ еҜҶfontж–Ү件.woff')
# е°Ҷж–Ү件иҪ¬жҲҗжҳҺж–Үзҡ„xmlж–Ү件
font_obj.saveXML('еҠ еҜҶfontж–Ү件.xml')
# иҺ·еҸ–еӯ—дҪ“еҠ еҜҶзҡ„е…ізі»жҳ е°„иЎЁпјҢе°Ҷ16иҝӣеҲ¶иҪ¬жҚўжҲҗ10иҝӣеҲ¶
cmap_list = font_obj.getBestCmap()
print('еӯ—дҪ“еҠ еҜҶе…ізі»жҳ е°„иЎЁпјҡ',cmap_list)
# еҲӣе»әиӢұж–ҮиҪ¬иӢұж–Үзҡ„еӯ—е…ё
dict_e_a = {'one':'1','two':'2','three':'3','four':'4','five':'5','six':'6',
'seven':'7','eight':'8','nine':'9','zero':'0'}
# е°ҶиӢұж–Үж•°жҚ®иҝӣиЎҢиҪ¬жҚў
for i in cmap_list:
for j in dict_e_a:
if j == cmap_list[i]:
cmap_list[i] = dict_e_a[j]
print('иҪ¬жҚўдёәйҳҝжӢүдјҜж•°еӯ—зҡ„жҳ е°„иЎЁдёәпјҡ',cmap_list)
# еҺ»жҺүеҠ еҜҶзҡ„жңҲзҘЁж•°жҚ®еҲ—иЎЁдёӯзҡ„з¬ҰеҸ·
new_mon_list = []
for i in mon_list:
list_ = re.findall(r'\d+',i)
new_mon_list.append(list_)
print('еҺ»жҺүз¬ҰеҸ·д№ӢеҗҺзҡ„жңҲзҘЁж•°жҚ®еҲ—иЎЁдёәпјҡ',new_mon_list)
# жңҖз»Ҳи§ЈжһҗжңҲзҘЁж•°жҚ®
for i in new_mon_list:
for j in enumerate(i):
for k in cmap_list:
if j[1] == str(k):
i[j[0]] = cmap_list[k]
print('и§Јжһҗд№ӢеҗҺзҡ„жңҲзҘЁж•°жҚ®дёә:',new_mon_list)
# е°ҶжңҲзҘЁж•°жҚ®иҝӣиЎҢжӢјжҺҘ
new_list = []
for i in new_mon_list:
j = ''.join(i)
new_list.append(j)
print('и§ЈжһҗеҮәзҡ„жҳҺж–Үж•°жҚ®дёәпјҡ',new_list)
# е°ҶеҗҚз§°е’ҢеҜ№еә”зҡ„жңҲзҘЁж•°жҚ®ж”ҫиҝӣеӯ—е…ёпјҢ并иҪ¬жҚўжҲҗjsonж јејҸеҸҠиҝӣиЎҢдҝқеӯҳ
for i in range(len(title_list)):
dict_ = {}
dict_[title_list[i]] = new_list[i]
# е°Ҷеӯ—е…ёиҪ¬жҚўжҲҗjsonж јејҸ
json_data = json.dumps(dict_,ensure_ascii=False)+',\n'
# е°Ҷж•°жҚ®дҝқеӯҳеҲ°жң¬ең°
with open('зҝ»йЎөиө·е°ҸзӮ№жңҲзҘЁжҰңж•°жҚ®зҲ¬еҸ–.json','a',encoding='utf-8')as f:
f.write(json_data)зҲ¬еҸ–дәҶдёӨйЎөзҡ„ж•°жҚ®пјҢжҜҸдёҖйЎөеҢ…еҗ«20дёӘж•°жҚ®
жү§иЎҢз»“жһңеҰӮдёӢпјҡ
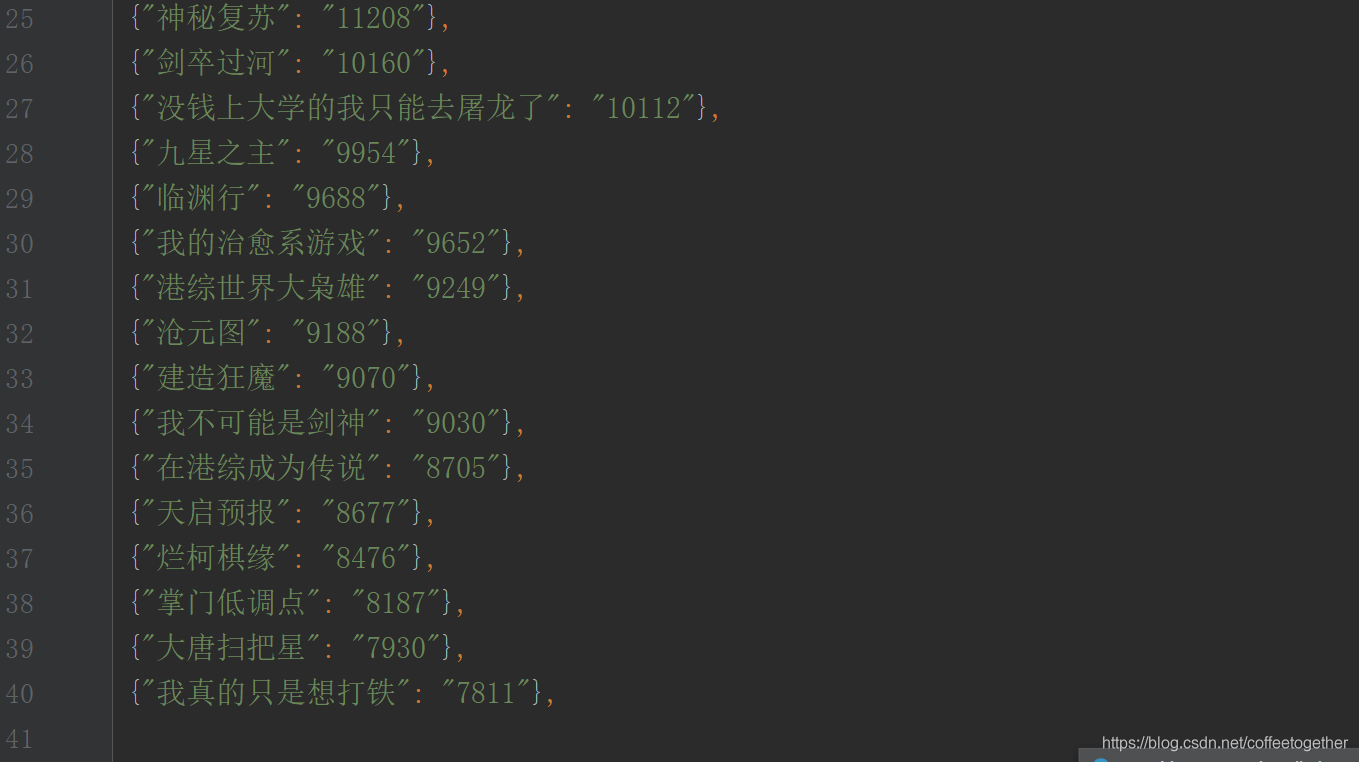
дёҠиҝ°еҶ…е®№е°ұжҳҜеҲ©з”ЁpythonзҲ¬иҷ«жҖҺд№Ҳз ҙи§ЈеҠ еҜҶеӯ—дҪ“пјҢдҪ 们еӯҰеҲ°зҹҘиҜҶжҲ–жҠҖиғҪдәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–иҖ…дё°еҜҢиҮӘе·ұзҡ„зҹҘиҜҶеӮЁеӨҮпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ