жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
дҪҝз”ЁceleryжҖҺд№ҲеҠЁжҖҒи®ҫзҪ®е®ҡж—¶д»»еҠЎпјҹеҫҲеӨҡж–°жүӢеҜ№жӯӨдёҚжҳҜеҫҲжё…жҘҡпјҢдёәдәҶеё®еҠ©еӨ§е®¶и§ЈеҶіиҝҷдёӘйҡҫйўҳпјҢдёӢйқўе°Ҹзј–е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§ЈпјҢжңүиҝҷж–№йқўйңҖжұӮзҡ„дәәеҸҜд»ҘжқҘеӯҰд№ дёӢпјҢеёҢжңӣдҪ иғҪжңүжүҖ收иҺ·гҖӮ
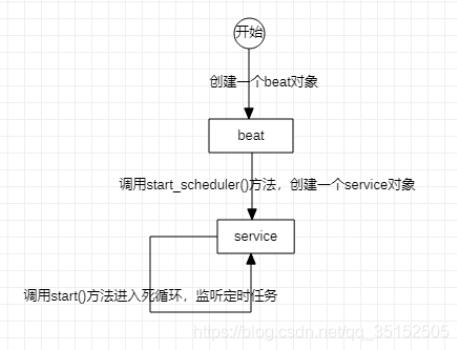
celeryзҡ„beatиҝҗиЎҢиҝҮзЁӢгҖӮ
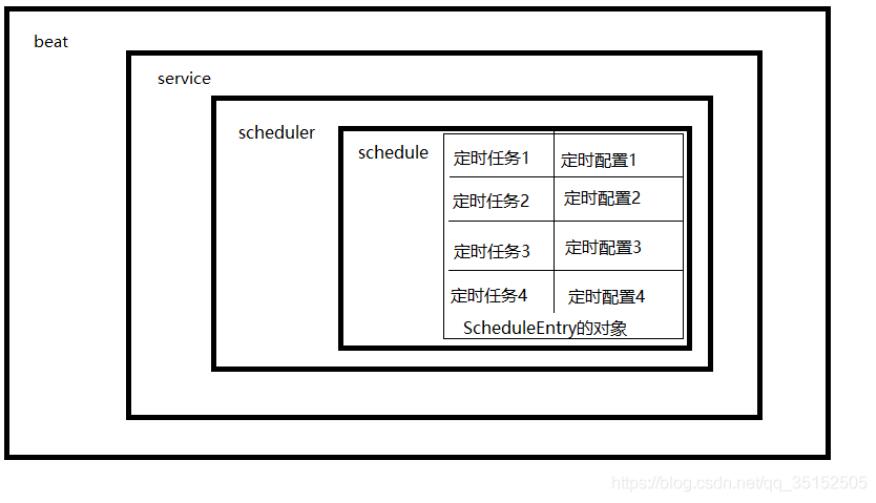
дёҠеӣҫжҳҜbeatзҡ„дё»иҰҒз»„жҲҗз»“жһ„пјҢbeatдёӯеҢ…еҗ«дәҶдёҖдёӘserviceеҜ№иұЎпјҢserviceдёӯеҢ…еҗ«дәҶдёҖдёӘschedulerеҜ№иұЎпјҢschedulerдёӯеҢ…еҗ«дәҶдёҖдёӘscheduleеӯ—е…ёпјҢscheduleдёӯkeyеҜ№еә”зҡ„зҡ„valueжүҚжҳҜзңҹжӯЈзҡ„е®ҡж—¶д»»еҠЎпјҢжҳҜж•ҙдёӘbeatдёӯжңҖе°Ҹзҡ„еҚ•е…ғгҖӮ
йҰ–е…ҲеҲҶеҲ«д»Ӣз»ҚдёҖдёӢеҗ„дёӘеҜ№иұЎе’Ңе®ғ们иҝҗиЎҢзҡ„иҝҮзЁӢпјҢbeatжҳҜcelery.apps.beat.Beatзұ»еҲӣе»әзҡ„еҜ№иұЎпјҢи°ғз”Ёbeat.run()ж–№жі•е°ұеҸҜд»ҘеҗҜеҠЁbeat,дёӢйқўжҳҜbeat.run()ж–№жі•зҡ„жәҗз ҒгҖӮ
def run(self):
print(str(self.colored.cyan(
'celery beat v{0} is starting.'.format(VERSION_BANNER))))
self.init_loader()
self.set_process_title()
self.start_scheduler()йҮҚзӮ№жҳҜеңЁrun()ж–№жі•йҮҢи°ғз”ЁдәҶstart_scheduler()ж–№жі•пјҢиҖҢstart_scheduler()ж–№жі•жң¬иҙЁдёҠжҳҜеҲӣе»әдәҶдёҖдёӘserviceеҜ№иұЎпјҲcelery.beat.Serviceзұ»пјүпјҢ并и°ғз”Ёservice.start()ж–№жі•пјҢдёӢйқўжҳҜbeat.start_scheduler()ж–№жі•зҡ„жәҗз ҒгҖӮ
def start_scheduler(self):
if self.pidfile:
platforms.create_pidlock(self.pidfile)
service = self.Service(
app=self.app,
max_interval=self.max_interval,
scheduler_cls=self.scheduler_cls,
schedule_filename=self.schedule,
)
print(self.banner(service))
self.setup_logging()
if self.socket_timeout:
logger.debug('Setting default socket timeout to %r',
self.socket_timeout)
socket.setdefaulttimeout(self.socket_timeout)
try:
self.install_sync_handler(service)
service.start()
except Exception as exc:
logger.critical('beat raised exception %s: %r',
exc.__class__, exc,
exc_info=True)
raiseи°ғз”ЁдәҶservice.start()д№ӢеҗҺпјҢдјҡиҝӣе…ҘдёҖдёӘжӯ»еҫӘзҺҜпјҢе…ҲдҪҝз”Ёself.scheduler.tick()иҺ·еҸ–дёӢдёҖдёӘд»»еҠЎaзҡ„е®ҡж—¶зӮ№еҲ°зҺ°еңЁж—¶й—ҙзҡ„й—ҙйҡ”пјҢ然еҗҺиҝӣе…ҘзқЎзң пјҢзқЎзң з»“жқҹд№ӢеҗҺеҲӨж–ӯеҰӮжһңself.schedulerйҮҢзҡ„дёӢдёҖдёӘд»»еҠЎaеҸҜд»Ҙжү§иЎҢпјҢе°ұз«ӢеҚіжү§иЎҢпјҢ并иҺ·еҸ–self.schedulerйҮҢзҡ„дёӢдёӢдёҖдёӘд»»еҠЎbзҡ„е®ҡж—¶зӮ№еҲ°зҺ°еңЁж—¶й—ҙзҡ„й—ҙйҡ”пјҢиҝӣе…ҘдёӢдёҖж¬ЎеҫӘзҺҜгҖӮдёӢйқўжҳҜservice.start()зҡ„жәҗз ҒгҖӮ
def start(self, embedded_process=False):
info('beat: Starting...')
debug('beat: Ticking with max interval->%s',
humanize_seconds(self.scheduler.max_interval))
signals.beat_init.send(sender=self)
if embedded_process:
signals.beat_embedded_init.send(sender=self)
platforms.set_process_title('celery beat')
try:
while not self._is_shutdown.is_set():
interval = self.scheduler.tick()
if interval and interval > 0.0:
debug('beat: Waking up %s.',
humanize_seconds(interval, prefix='in '))
time.sleep(interval)
if self.scheduler.should_sync():
self.scheduler._do_sync()
except (KeyboardInterrupt, SystemExit):
self._is_shutdown.set()
finally:
self.sync()service.schedulerй»ҳи®ӨжҳҜcelery.beat.PersistentSchedulerзұ»зҡ„е®һдҫӢеҜ№иұЎпјҢиҖҢcelery.beat.PersistentSchedulerе…¶е®һжҳҜcelery.beat.Schedulerзҡ„еӯҗзұ»пјҢжүҖд»Ҙscheduler.scheduleжҳҜcelery.beat.Schedulerзұ»дёӯзҡ„еӯ—е…ёпјҢдҝқеӯҳзҡ„жҳҜcelery.beat.ScheduleEntryзұ»еһӢзҡ„еҜ№иұЎгҖӮScheduleEntryзҡ„е®һдҫӢеҜ№иұЎдҝқеӯҳдәҶе®ҡж—¶д»»еҠЎзҡ„еҗҚз§°гҖҒеҸӮж•°гҖҒе®ҡж—¶дҝЎжҒҜгҖҒиҝҮжңҹж—¶й—ҙзӯүдҝЎжҒҜгҖӮcelery.beat.Schedulerзұ»е®һзҺ°дәҶеҜ№scheduleзҡ„жӣҙж–°ж–№жі•еҚіupdate_from_dict(self, dict_)ж–№жі•гҖӮдёӢйқўжҳҜupdate_from_dict(self, dict_)ж–№жі•зҡ„жәҗз ҒгҖӮ
def _maybe_entry(self, name, entry):
if isinstance(entry, self.Entry):
entry.app = self.app
return entry
return self.Entry(**dict(entry, name=name, app=self.app))
def update_from_dict(self, dict_):
self.schedule.update({
name: self._maybe_entry(name, entry)
for name, entry in items(dict_)
})еҸҜд»ҘзңӢеҲ°update_from_dict(self, dict_)ж–№жі•е®һйҷ…дёҠжҳҜеҗ‘scheduleдёӯжӣҙж–°дәҶself.Entryзҡ„е®һдҫӢеҜ№иұЎпјҢиҖҢself.Entryд»Һcelery.beat.Schedulerзҡ„жәҗз ҒзҹҘйҒ“жҳҜcelery.beat.ScheduleEntryгҖӮ
еҲ°иҝҷйҮҢж•ҙдёӘжөҒзЁӢе°ұзІ—з•Ҙзҡ„д»Ӣз»Қе®ҢдәҶпјҢеҹәжң¬иҝҮзЁӢжҳҜиҝҷдёӘж ·еӯҗгҖӮ
дҪҶжҳҜд»ҺеүҚйқўstart_scheduler()зҡ„жәҗз ҒеҸҜд»ҘзңӢеҲ°пјҢbeatеңЁеҶ…йғЁеҲӣе»әдёҖдёӘserviceд№ӢеҗҺпјҢе°ұзӣҙжҺҘиҝӣе…Ҙжӯ»еҫӘзҺҜдәҶпјҢжүҖд»Ҙд»ҺеӨ–йқўж— жі•жӢҝеҲ°serviceеҜ№иұЎпјҢе°ұдёҚиғҪеҜ№serviceйҮҢзҡ„schedulerеҜ№иұЎж“ҚдҪңпјҢе°ұдёҚиғҪеҜ№schedulerзҡ„scheduleеӯ—е…ёж“ҚдҪңпјҢжүҖд»Ҙе°ұж— жі•еңЁbeatиҝҗиЎҢзҡ„иҝҮзЁӢдёӯеҠЁжҖҒж·»еҠ е®ҡж—¶д»»еҠЎгҖӮ
еүҚйқўд»Ӣз»Қе®ҢеҺҹзҗҶпјҢзҺ°еңЁжқҘи®ІдёҖдёӢи§ЈеҶіжҖқи·ҜгҖӮдё»иҰҒжҖқи·Ҝе°ұжҳҜи®©start_schedulerж–№жі•дёӯеҲӣе»әзҡ„serviceжҡҙйңІеҮәжқҘгҖӮжүҖд»Ҙе°ұжғіеҲ°жүӢеҶҷдёҖдёӘзұ»еҺ»з»§жүҝBeatпјҢйҮҚеҶҷstart_scheduler()ж–№жі•гҖӮ
import socket
from celery import platforms
from celery.apps.beat import Beat
class MyBeat(Beat):
'''
继жүҝBeat ж·»еҠ дёҖдёӘиҺ·еҸ–serviceзҡ„ж–№жі•
'''
def start_scheduler(self):
if self.pidfile:
platforms.create_pidlock(self.pidfile)
# дҝ®ж”№дәҶиҺ·еҸ–serviceзҡ„ж–№ејҸ
service = self.get_service()
print(self.banner(service))
self.setup_logging()
if self.socket_timeout:
logger.debug('Setting default socket timeout to %r',
self.socket_timeout)
socket.setdefaulttimeout(self.socket_timeout)
try:
self.install_sync_handler(service)
service.start()
except Exception as exc:
logger.critical('beat raised exception %s: %r',
exc.__class__, exc,
exc_info=True)
raise
def get_service(self):
'''
иҝҷдёӘжҳҜиҮӘе®ҡд№үзҡ„ зӣ®зҡ„жҳҜдёәдәҶжҠҠserviceжҡҙйңІеҮәжқҘпјҢж–№дҫҝеҜ№serviceзҡ„schedulerж“ҚдҪңпјҢеӣ дёәе®ҡж—¶д»»еҠЎдҝЎжҒҜйғҪеӯҳж”ҫеңЁservice.schedulerйҮҢ
:return:
'''
service = getattr(self, "service", None)
if service is None:
service = self.Service(
app=self.app,
max_interval=self.max_interval,
scheduler_cls=self.scheduler_cls,
schedule_filename=self.schedule,
)
setattr(self, "service", service)
return self.serviceеңЁMyBeatзұ»дёӯж·»еҠ дёҖдёӘget_service()ж–№жі•пјҢеҰӮжһңbeatжІЎжңүservicеҜ№иұЎе°ұеҲӣе»әдёҖдёӘпјҢеҰӮжһңжңүе°ұзӣҙжҺҘиҝ”еӣһпјҢж–№дҫҝеҜ№serviceзҡ„schedulerж“ҚдҪңгҖӮ
然еҗҺеңЁжӯӨеҹәзЎҖдёҠе®һзҺ°еҜ№е®ҡж—¶д»»еҠЎзҡ„еўһеҲ ж”№жҹҘж“ҚдҪңгҖӮ
def add_cron_task(task_name: str, cron_task: str, minute='*', hour='*', day_of_week='*', day_of_month='*',
month_of_year='*', **kwargs):
'''
еҲӣе»әжҲ–жӣҙж–°е®ҡж—¶д»»еҠЎ
:param task_name: е®ҡж—¶д»»еҠЎеҗҚз§°
:param cron_task: taskеҗҚз§°
:param minute: д»ҘдёӢжҳҜж—¶й—ҙ
:param hour:
:param day_of_week:
:param day_of_month:
:param month_of_year:
:param kwargs:
:return:
'''
service = beat.get_service()
scheduler = service.scheduler
entries = dict()
entries[task_name] = {
'task': cron_task,
'schedule': crontab(minute=minute, hour=hour, day_of_week=day_of_week, day_of_month=day_of_month,
month_of_year=month_of_year, **kwargs),
'options': {'expires': 3600}}
scheduler.update_from_dict(entries)
def del_cron_task(task_name: str):
'''
еҲ йҷӨе®ҡж—¶д»»еҠЎ
:param task_name:
:return:
'''
service = beat.get_service()
scheduler = service.scheduler
if scheduler.schedule.get(task_name, None) is not None:
del scheduler.schedule[task_name]
def get_cron_task():
'''
иҺ·еҸ–еҪ“еүҚжүҖжңүе®ҡж—¶д»»еҠЎзҡ„й…ҚзҪ®
:return:
'''
service = beat.get_service()
scheduler = service.scheduler
ret = [{k: {"task": v.task, "crontab": v.schedule}} for k, v in scheduler.schedule.items()]
return retдҪҶжҳҜд»…д»…жҳҜиҝҷж ·иҝҳдёҚиғҪи§ЈеҶій—®йўҳпјҢд»ҺеүҚйқўзҡ„serive.start()зҡ„жәҗз ҒзңӢеҲ°пјҢbeatеҗҜеҠЁеҗҺдјҡиҝӣе…ҘдёҖдёӘжӯ»еҫӘзҺҜпјҢеҰӮжһңзӣҙжҺҘеңЁдё»зәҝзЁӢеҗҜеҠЁbeatпјҢеҝ…然дјҡйҳ»еЎһеңЁжӯ»еҫӘзҺҜдёӯпјҢжүҖд»ҘйңҖиҰҒдёәbeatеҲӣе»әдёҖдёӘеӯҗзәҝзЁӢпјҢиҝҷж ·жүҚеҪұе“Қдё»зәҝзЁӢзҡ„е…¶д»–ж“ҚдҪңгҖӮ
flag = False beat = MyBeat(max_interval=10, app=celery_app, socket_timeout=30, pidfile=None, no_color=None, loglevel='INFO', logfile=None, schedule=None, scheduler='celery.beat.PersistentScheduler', scheduler_cls=None, # XXX use scheduler redirect_stdouts=None, redirect_stdouts_level=None) # и®ҫзҪ®дё»еҠЁеҗҜеҠЁbeatжҳҜдёәдәҶйҒҝе…ҚдҪҝз”Ёcelery -A celery_demo worker е‘Ҫд»ӨйҮҚеӨҚеҗҜеҠЁworker def run(): ''' еҗҜеҠЁBeat :return: ''' beat.run() def new_thread(): ''' еҲӣе»әдёҖдёӘзәҝзЁӢеҗҜеҠЁBeat жңҖеӨҡеҸӘиғҪеҲӣе»әдёҖдёӘ :return: ''' global flag if not flag: t = threading.Thread(target=run, daemon=True) t.start() # еҗҜеҠЁжҲҗеҠҹ2sеҗҺжүҚиғҪж“ҚдҪңе®ҡж—¶д»»еҠЎ еҗҰеҲҷеҸҜиғҪдјҡжҠҘй”ҷ time.sleep(2) flag = True
еҸҜиғҪзңӢеҲ°дёҠйқўзҡ„д»Јз ҒжңүдәәдјҡжғіпјҢдёәд»Җд№ҲдёҚеңЁдё»зЁӢеәҸеҠ иҪҪе®ҢжҲҗе°ұеҗҜеҠЁдёәbeatеҲӣе»әдёҖдёӘеӯҗзәҝзЁӢпјҢиҝҳйқһиҰҒеҶҷдёӘеҮҪж•°зӯүеҫ…дё»еҠЁи°ғз”ЁпјҹиҝҷжҳҜеӣ дёәдҫӢеҰӮеңЁдҪҝз”Ёdjango+celeryз»„еҗҲж—¶пјҢдёҖиҲ¬еҗҜеҠЁdjangoе’ҢеҗҜеҠЁcelery wokerжҳҜдёӨдёӘзӢ¬з«Ӣзҡ„иҝӣзЁӢпјҢеҰӮжһңи®©djangoеңЁеҠ иҪҪд»Јз Ғзҡ„ж—¶еҖҷиҮӘеҠЁеҗҜеҠЁbeatзҡ„еӯҗзәҝзЁӢпјҢйӮЈд№ҲеңЁдҪҝз”Ёcelery -A demo_name worker еҗҜеҠЁceleryж—¶пјҢдјҡйҮҚж–°еҠ иҪҪдёҖиҫ№djangoзҡ„д»Јз ҒпјҢеӣ дёәceleryйңҖиҰҒжү«жҸҸжҜҸдёӘappдёӢзҡ„tasks.pyж–Ү件пјҢеҠ иҪҪејӮжӯҘд»»еҠЎеҮҪж•°пјҢиҝҷж—¶еҗҜеҠЁcelery wokerе°ұдјҡд№ҹеҗҜеҠЁдёҖдёӘbeatеӯҗзәҝзЁӢпјҢеҸҜиғҪдјҡйҖ жҲҗе®ҡж—¶д»»еҠЎйҮҚеӨҚжү§иЎҢзҡ„жғ…еҶөгҖӮжүҖд»ҘеңЁиҝҷйҮҢи®ҫзҪ®жҲҗдё»еҠЁејҖеҗҜbeatеӯҗзәҝзЁӢпјҢзӣ®зҡ„е°ұжҳҜдёәдәҶcelery workerеҗҜеҠЁдёҚйҮҚеӨҚеҲӣе»әbeatзәҝзЁӢгҖӮ
е®Ңж•ҙзҡ„д»Јз ҒеҰӮдёӢпјҡ
import socket
import time
import threading
from celery import platforms
from celery.schedules import crontab
from celery.apps.beat import Beat
from celery.utils.log import get_logger
from celery_demo import celery_app
logger = get_logger('celery.beat')
flag = False
class MyBeat(Beat):
'''
继жүҝBeat ж·»еҠ дёҖдёӘиҺ·еҸ–serviceзҡ„ж–№жі•
'''
def start_scheduler(self):
if self.pidfile:
platforms.create_pidlock(self.pidfile)
# дҝ®ж”№дәҶиҺ·еҸ–serviceзҡ„ж–№ејҸ
service = self.get_service()
print(self.banner(service))
self.setup_logging()
if self.socket_timeout:
logger.debug('Setting default socket timeout to %r',
self.socket_timeout)
socket.setdefaulttimeout(self.socket_timeout)
try:
self.install_sync_handler(service)
service.start()
except Exception as exc:
logger.critical('beat raised exception %s: %r',
exc.__class__, exc,
exc_info=True)
raise
def get_service(self):
'''
иҝҷдёӘжҳҜиҮӘе®ҡд№үзҡ„ зӣ®зҡ„жҳҜдёәдәҶжҠҠserviceжҡҙйңІеҮәжқҘпјҢж–№дҫҝеҜ№serviceзҡ„schedulerж“ҚдҪңпјҢеӣ дёәе®ҡж—¶д»»еҠЎдҝЎжҒҜйғҪеӯҳж”ҫеңЁservice.schedulerйҮҢ
:return:
'''
service = getattr(self, "service", None)
if service is None:
service = self.Service(
app=self.app,
max_interval=self.max_interval,
scheduler_cls=self.scheduler_cls,
schedule_filename=self.schedule,
)
setattr(self, "service", service)
return self.service
beat = MyBeat(max_interval=10, app=celery_app, socket_timeout=30, pidfile=None, no_color=None,
loglevel='INFO', logfile=None, schedule=None, scheduler='celery.beat.PersistentScheduler',
scheduler_cls=None, # XXX use scheduler
redirect_stdouts=None,
redirect_stdouts_level=None)
# и®ҫзҪ®дё»еҠЁеҗҜеҠЁbeatжҳҜдёәдәҶйҒҝе…ҚдҪҝз”Ёcelery -A celery_demo worker е‘Ҫд»ӨйҮҚеӨҚеҗҜеҠЁworker
def run():
'''
еҗҜеҠЁBeat
:return:
'''
beat.run()
def new_thread():
'''
еҲӣе»әдёҖдёӘзәҝзЁӢеҗҜеҠЁBeat жңҖеӨҡеҸӘиғҪеҲӣе»әдёҖдёӘ
:return:
'''
global flag
if not flag:
t = threading.Thread(target=run, daemon=True)
t.start()
# еҗҜеҠЁжҲҗеҠҹ2sеҗҺжүҚиғҪж“ҚдҪңе®ҡж—¶д»»еҠЎ еҗҰеҲҷеҸҜиғҪдјҡжҠҘй”ҷ
time.sleep(2)
flag = True
def add_cron_task(task_name: str, cron_task: str, minute='*', hour='*', day_of_week='*', day_of_month='*',
month_of_year='*', **kwargs):
'''
еҲӣе»әжҲ–жӣҙж–°е®ҡж—¶д»»еҠЎ
:param task_name: е®ҡж—¶д»»еҠЎеҗҚз§°
:param cron_task: taskеҗҚз§°
:param minute: д»ҘдёӢжҳҜж—¶й—ҙ
:param hour:
:param day_of_week:
:param day_of_month:
:param month_of_year:
:param kwargs:
:return:
'''
service = beat.get_service()
scheduler = service.scheduler
entries = dict()
entries[task_name] = {
'task': cron_task,
'schedule': crontab(minute=minute, hour=hour, day_of_week=day_of_week, day_of_month=day_of_month,
month_of_year=month_of_year, **kwargs),
'options': {'expires': 3600}}
scheduler.update_from_dict(entries)
def del_cron_task(task_name: str):
'''
еҲ йҷӨе®ҡж—¶д»»еҠЎ
:param task_name:
:return:
'''
service = beat.get_service()
scheduler = service.scheduler
if scheduler.schedule.get(task_name, None) is not None:
del scheduler.schedule[task_name]
def get_cron_task():
'''
иҺ·еҸ–еҪ“еүҚжүҖжңүе®ҡж—¶д»»еҠЎзҡ„й…ҚзҪ®
:return:
'''
service = beat.get_service()
scheduler = service.scheduler
ret = [{k: {"task": v.task, "crontab": v.schedule}} for k, v in scheduler.schedule.items()]
return retзңӢе®ҢдёҠиҝ°еҶ…е®№жҳҜеҗҰеҜ№жӮЁжңүеё®еҠ©е‘ўпјҹеҰӮжһңиҝҳжғіеҜ№зӣёе…ізҹҘиҜҶжңүиҝӣдёҖжӯҘзҡ„дәҶи§ЈжҲ–йҳ…иҜ»жӣҙеӨҡзӣёе…іж–Үз« пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўжӮЁеҜ№дәҝйҖҹдә‘зҡ„ж”ҜжҢҒгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ