您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
我家中笔记本的环境非常简单:
Scrapy重度依赖于lxml和twisted两个框架。这也正是问题所在。开源环境下工具的安装往往需要我们事先确定要安装的工具库依赖于哪些第三方库及其相关的依赖。如果有一个依赖安装要求满足不了,则安装失败。因此,安装前要做好必要的调查分析。
最开始时,我在DOS命令行下使用如下命令安装,但是失败了:
pip install scrapy
运行上述命令时,pip会默认从https://files.pythonhosted.org网站上下载并安装最新版本的scrapy库,当然它会自动分析当前系统中已经安装的python版本。尽管如此,其所依赖的其他第三方库并不会作严格检查,结果会导致整个安装仅查最后的百分之几却是以失败结果而告终。
绝大多数网站上推荐的Lxml安装思路是从Python第三方库的网站http://www.lfd.uci.edu/~gohlke/pythonlibs/上下载编译好的.whl压缩文件,如下图:

但是,很遗憾,当我现在跳转到此网站找Python 3.4对应版本的.WHL文件时,早已不存在了。但是,以它提供的合适的文件作参考lxml-3.7.3-cp34-cp34m-win32.whl,我再次从网络上搜索,最终从开源网站github(https://github.com/Lucterios2/core/blob/master/packages/lxml-3.4.4-cp34-none-win32.whl)上找到一个文件lxml-3.4.4-cp34-none-win32.whl。
下载没有问题,安装前需要先安装wheel,也很容易,最后安装成功!
值得庆幸的是,Scrapy当前最新版本也正是1.7.3,我从网络上搜索到的文件名是Scrapy-1.7.3-py2.py3-none-any.whl。
下载地址也很经典,是https://pypi.org/project/Scrapy/#files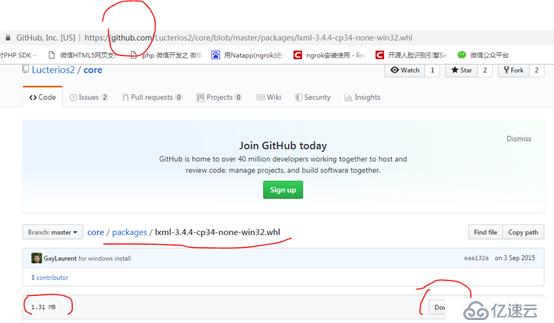
下载容易,安装也非常简单,成功安装!
而没有直接使用命令pip install scrapy安装。
安装过程中经历的挫折很多很多,尽管没有细述,但是经验却已经写了最前面。希望有兴趣的读者在行动前先要做到心中有数,而不是盲目地跟着某些文章中介绍的那样上来就直接安装,这样的话,很可能会导致安装了一些半成品——甚至算是垃圾,给自己的清理后的重新安装都带来很多麻烦!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。