жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
йҰ–е…Ҳиҝҷж¬ЎеӯҰд№ зҡ„жҳҜеҲ©з”ЁеҶҷPythonи„ҡжң¬еҜ№зҪ‘йЎөдҝЎжҒҜзҡ„иҺ·еҸ–пјҢ并且жҠҠд»–дҝқеӯҳеҲ°жҲ‘们зҡ„ж•°жҚ®еә“йҮҢжңҖеҗҺеҪўжҲҗдёҖдёӘExcelиЎЁж ј
еҲҡејҖе§ӢжҲ‘们йңҖиҰҒеҒҡдёҖдәӣеҮҶеӨҮпјҡ
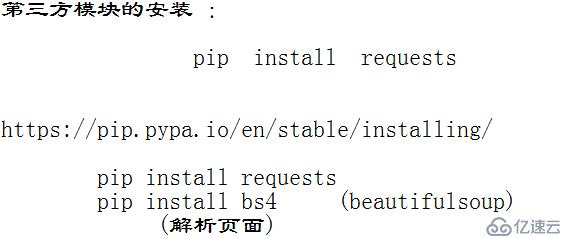
е…Ҳе®ү装第дёүж–№жЁЎеқ—
https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-3.2.5.tgz

жҖқи·ҜеҰӮдёӢпјҡ
headersиҺ·еҸ–пјҡ
и„ҡжң¬1пјҡ
иҝҗиЎҢеүҚжү“ејҖmongod :
./mongod & 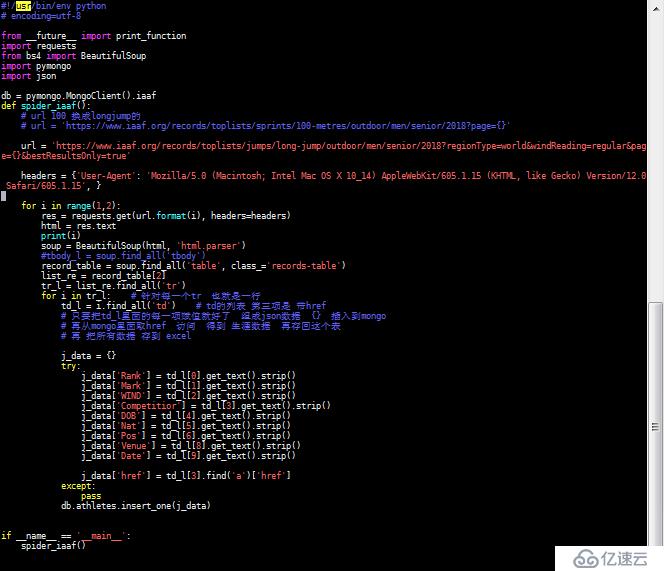
и„ҡжң¬2пјҡ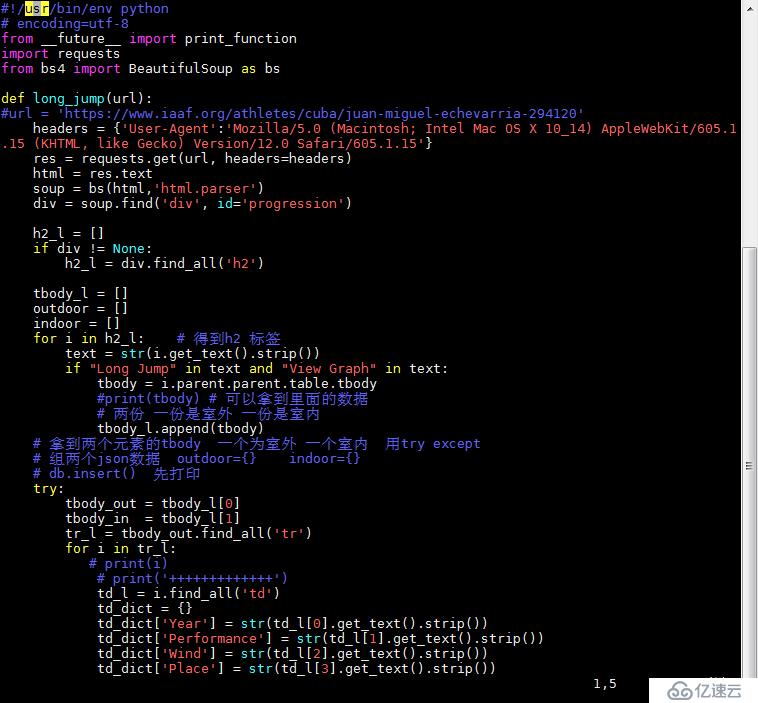
Long Jump е’Ң View Graph жҳҜж №жҚ®д»–们еҸҜд»Ҙе®ҡдҪҚеҲ°жҲ‘们жғіиҺ·еҸ–зҡ„дҝЎжҒҜзҡ„ж ҮзӯҫдёҠ
иҝҷдёӘи„ҡжң¬еҶҷе®ҢдёҚйңҖиҰҒиҝҗиЎҢпјҢд»–зҡ„urlжҳҜз”ұ第дёүдёӘи„ҡжң¬еҜје…Ҙзҡ„
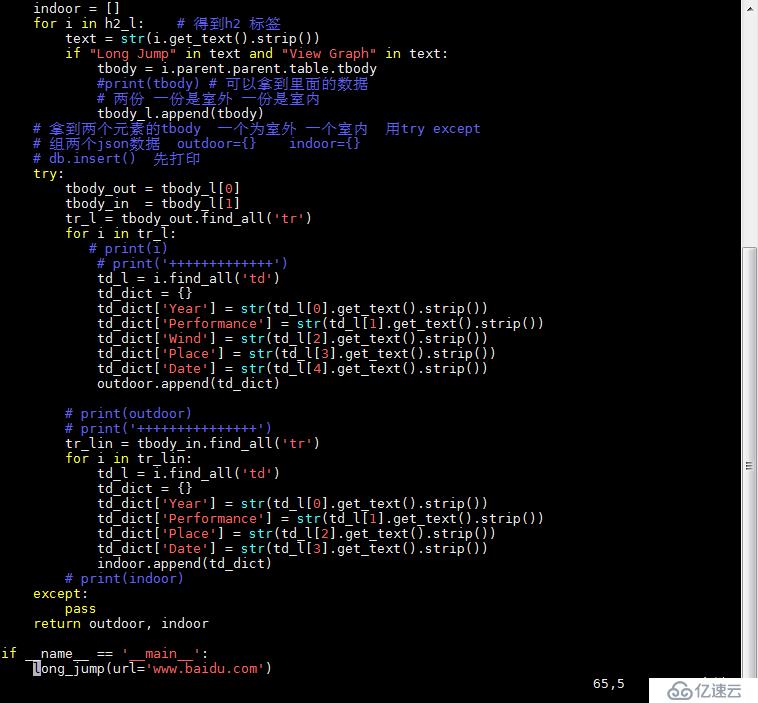
и„ҡжң¬3пјҡ
иҝҗиЎҢеүҚйғҪиҰҒжЈҖжҹҘMongoDжҳҜеҗҰиҝҗиЎҢпјҢиҝҗиЎҢеҗҺеҸҜиҝӣе…Ҙж•°жҚ®еә“еҺ»зңӢжҲ‘们еӯҳе…Ҙзҡ„дҝЎжҒҜ
еңЁMongoDBзҡ„binдёӢ
./mongo
use iaaf
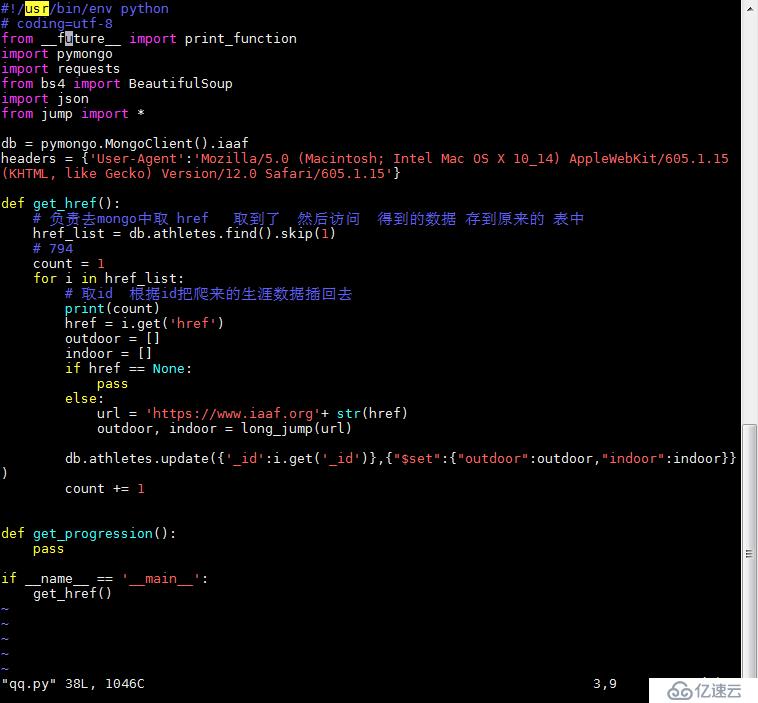
db.athletes.find()и„ҡжң¬4пјҡ
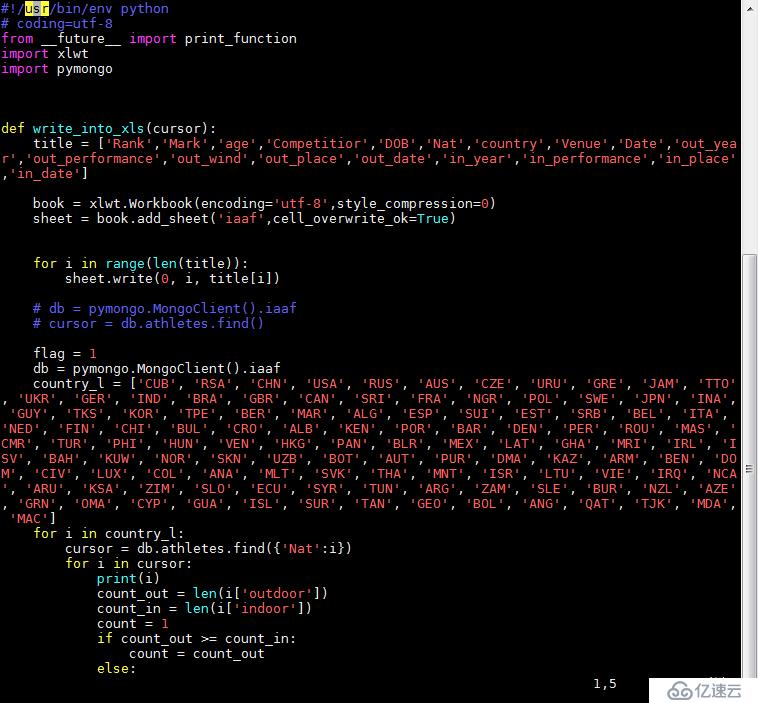
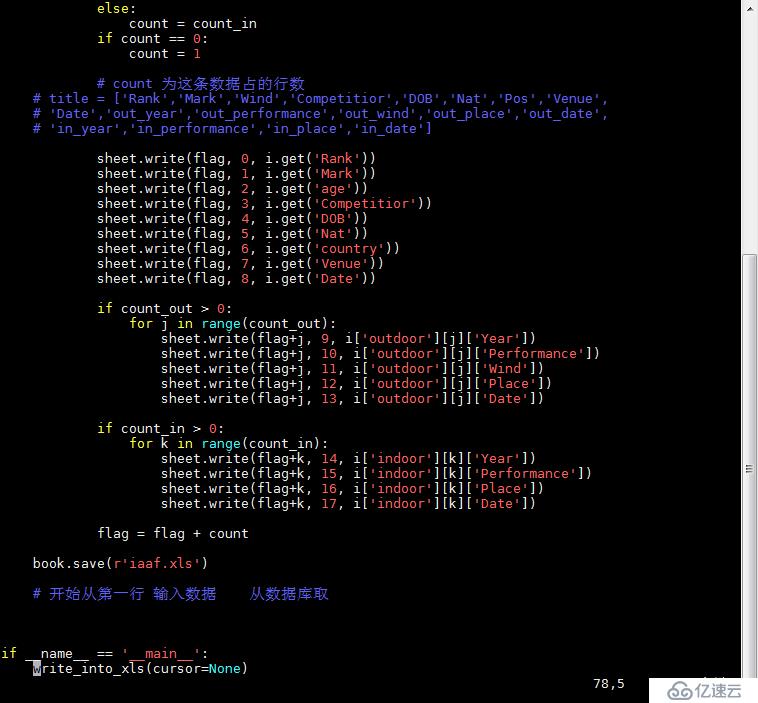
requestsжҳҜдёҖдёӘеҫҲе®һз”Ёзҡ„Python HTTPе®ўжҲ·з«Ҝеә“пјҢзј–еҶҷзҲ¬иҷ«е’ҢжөӢиҜ•жңҚеҠЎеҷЁе“Қеә”ж•°жҚ®ж—¶з»Ҹеёёдјҡз”ЁеҲ°гҖӮеҸҜд»ҘиҜҙпјҢRequests е®Ңе…Ёж»Ўи¶іеҰӮд»ҠзҪ‘з»ңзҡ„йңҖжұӮ
1.дҪңз”ЁпјҡеҸ‘йҖҒиҜ·жұӮиҺ·еҸ–е“Қеә”дёәд»Җд№ҲдҪҝз”Ёrequesstпјҹ
1)requestsеә•еұӮе®һзҺ°зҡ„жҳҜurllib2)requestsеңЁpython2е’Ңpython3дёӯйҖҡз”ЁпјҢж–№жі•е®Ңе…ЁдёҖж ·
3пјүrequestsз®ҖеҚ•жҳ“з”ЁпјҲpythonзү№жҖ§пјү
4пјүrequestsиғҪеӨҹеё®еҠ©жҲ‘们解еҺӢе“Қеә”еҶ…е®№пјҲиҮӘеҠЁи§ЈеҺӢе®Ңе–„иҜ·жұӮеӨҙпјҢиҮӘеҠЁиҺ·еҸ–cookieпјү
pymongoжҳҜpythonж“ҚдҪң mongodbзҡ„е·Ҙе…·еҢ…
bs4жҰӮеҝөпјҡ
bs4еә“жҳҜи§ЈжһҗгҖҒйҒҚеҺҶгҖҒз»ҙжҠӨгҖҒ"ж Үзӯҫж ‘"зҡ„еҠҹиғҪеә“
йҖҡдҝ—дёҖзӮ№иҜҙе°ұжҳҜпјҡbs4еә“жҠҠHTMLжәҗд»Јз ҒйҮҚж–°иҝӣиЎҢдәҶж јејҸеҢ–пјҢ
д»ҺиҖҢж–№дҫҝжҲ‘们еҜ№е…¶дёӯзҡ„иҠӮзӮ№гҖҒж ҮзӯҫгҖҒеұһжҖ§зӯүиҝӣиЎҢж“ҚдҪң
2.BS4зҡ„4дёӯеҜ№иұЎ
в‘ TagеҜ№иұЎпјҡжҳҜhtmlдёӯзҡ„дёҖдёӘж ҮзӯҫпјҢз”ЁBeautifulSoupе°ұиғҪи§ЈжһҗеҮәжқҘTagзҡ„е…·дҪ“еҶ…е®№пјҢе…·дҪ“
зҡ„ж јејҸдёәвҖҳsoup.nameвҖҳ,е…¶дёӯnameжҳҜhtmlдёӢзҡ„ж ҮзӯҫгҖӮ
в‘ЎBeautifulSoupеҜ№иұЎпјҡж•ҙдёӘhtmlж–Үжң¬еҜ№иұЎпјҢеҸҜеҪ“дҪңTagеҜ№иұЎ
в‘ўNavigableStringеҜ№иұЎпјҡж ҮзӯҫеҶ…зҡ„ж–Үжң¬еҜ№иұЎ
в‘ЈCommentеҜ№иұЎпјҡжҳҜдёҖдёӘзү№ж®Ҡзҡ„NavigableStringеҜ№иұЎпјҢеҰӮжһңhtmlж ҮзӯҫеҶ…еӯҳеңЁжіЁйҮҠпјҢйӮЈд№Ҳе®ғеҸҜд»ҘиҝҮж»ӨжҺүжіЁйҮҠз¬ҰеҸ·дҝқз•ҷжіЁйҮҠж–Үжң¬
жңҖеёёз”Ёзҡ„иҝҳжҳҜBeautifulSoupеҜ№иұЎе’ҢTagеҜ№иұЎ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ