жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢpandasжҖҺд№ҲдҪҝз”Ёmergeе®һзҺ°зҷҫеҖҚеҠ йҖҹзҡ„ж“ҚдҪңпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« д№ӢеҗҺйғҪжңүжүҖ收иҺ·пјҢдёӢйқўи®©жҲ‘们дёҖиө·еҺ»жҺўи®Ёеҗ§пјҒ
е…Ҳз”ҹжҲҗдёҖдёІзӣ®ж Үж—¶й—ҙеәҸеҲ—пјҢд»ҺжҹҗдёӘејҖе§Ӣж—ҘеҲ°д»ҠеӨ©дёәжӯўпјҢжҜҸдёғеӨ©дёҖдёӘж—ҘжңҹгҖӮ
жҠҠиҝҷдәӣж—ҘжңҹmapеҲ°ж•°жҚ®йӣҶзҡ„ж—Ҙжңҹ, Eg. {вҖң2019-06-18вҖқ:вҖң2019-06-15вҖқвҖҰ} гҖӮ
жҠҠmapеҲ°зҡ„ж•°жҚ®жҠҪеҮәжқҘз”Ёpd.concatжҺҘиө·жқҘгҖӮ
target_dates = pd.date_range(end=now, periods=100, freq="7D") full_dates = pd.date_range(start, now).tolist() org_dates = df.date.tolist() last_date = None for d in full_dates: if d in org_dates: date_map[d] = d last_date = d elif last_date is not None: date_map[d] = last_date else: continue new_df = pd.DataFrame() for td in target_dates: new_df = pd.concatпјҲ[new_df, df[df["date"]==date_map[td]]пјү
иҝҷж ·зҡ„дёҖдёӘз®—жі•еӨ„зҗҶдёҖдёӘжҺҘиҝ‘еҚғдёҮйҮҸзә§зҡ„ж•°жҚ®йӣҶдёҠеӨ§жҰӮйңҖиҰҒеҚҒеӨҡеҲҶй’ҹгҖӮд»”з»ҶжЈҖжҹҘеҸ‘зҺ°пјҢжҜҸдёҖж¬ЎеҗҲ并зҡ„dataframeж•°жҚ®йҮҸ并дёҚе°ҸпјҢиҖҢдё”жҖ»зҡ„ж“ҚдҪңж¬Ўж•°иҫҫеҲ°дёҠдёҮж¬ЎгҖӮ
жүҖд»Ҙе°ұжғіеҰӮдҪ•йҒҝе…Қй«ҳйў‘ж¬Ўең°дҪҝз”Ёpd.concatеҺ»еҗҲ并dataframeгҖӮ
жңҖз»ҲжғіеҲ°дәҶдёҖдёӘе·§еҰҷзҡ„ж–№жі•пјҢеҸӘйңҖиҰҒдҝ®ж”№дёҖдёӢеүҚйқўзҡ„第дёүжӯҘпјҢжҠҠж—Ҙжңҹзҡ„mapиҪ¬жҚўжҲҗdataframeпјҢ然еҗҺе’ҢеҺҹе§Ӣж•°жҚ®йӣҶеҒҡmergeж“ҚдҪңе°ұеҸҜд»ҘдәҶгҖӮ
target_dates = pd.date_range(end=now, periods=100, freq="7D")
full_dates = pd.date_range(start, now).tolist()
org_dates = df.date.tolist()
last_date = None
for d in full_dates:
if d in org_dates:
date_map[d] = d
last_date = d
elif last_date is not None:
date_map[d] = last_date
else:
continue
#### main change is from here #####
date_map_list = []
for td in target_dates:
date_map_list.append({"target_date":td, "org_date":date_map[td]})
date_map_df = pd.DataFrame(date_map_list)
new_df = date_map_df.merge(df, left_on=["org_date"], right_on=["date"], how="inner")ж”№иҝӣд№ӢеҗҺпјҢжүҖжңүзҡ„еҫӘзҺҜж“ҚдҪңйғҪеңЁдёҖдёӘеҫ®ж•°йҮҸзә§дёҠпјҢжңҖеҗҺдёҖдёӘmergeж“ҚдҪңеҫ—еҲ°дәҶжүҖжңүжңүз”Ёзҡ„ж•°жҚ®пјҢиҝҗиЎҢж—¶й—ҙеңЁ5з§’е·ҰеҸіпјҢеӨ§еӨ§жҸҗеҚҮдәҶжҖ§иғҪгҖӮ
иЎҘе……пјҡPandas DataFrames дёӯ merge еҗҲ并зҡ„еқ‘зӮ№(еҮәзҺ°йҮҚеӨҚиҝһжҺҘй”®)
еңЁжҲ‘зҡ„е®һйҷ…ејҖеҸ‘дёӯйҒҮеҲ°зҡ„еқ‘зӮ№пјҢжҹҘйҳ…дәҶзӣёе…іж–ҮжЎЈ жҖ»з»“дёҖдёӢ
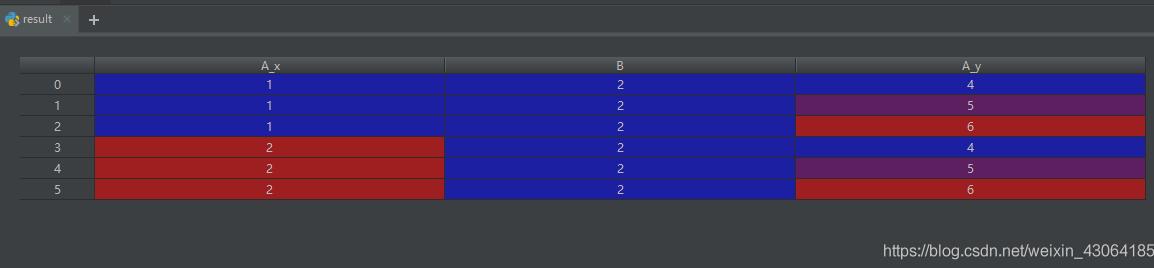
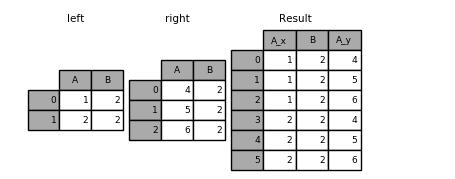
left = pd.DataFrame({'A': [1, 2], 'B': [2, 2]})
right = pd.DataFrame({'A': [4, 5, 6], 'B': [2, 2, 2]})
result = pd.merge(left, right, on='B', how='outer')
иӯҰе‘Ҡ:еңЁйҮҚеӨҚй”®дёҠеҠ е…Ҙ/еҗҲ并еҸҜиғҪеҜјиҮҙиҝ”еӣһзҡ„её§жҳҜиЎҢз»ҙеәҰзҡ„д№ҳжі•пјҢиҝҷеҸҜиғҪеҜјиҮҙеҶ…еӯҳжәўеҮәгҖӮеңЁеҠ е…ҘеӨ§еһӢDataFrameд№ӢеүҚпјҢйҮҚеӨҚеҖјгҖӮ
жЈҖжҹҘйҮҚеӨҚй”®
еҰӮжһңзҹҘйҒ“еҸідҫ§зҡ„йҮҚеӨҚйЎ№DataFrameдҪҶеёҢжңӣзЎ®дҝқе·Ұдҫ§DataFrameдёӯжІЎжңүйҮҚеӨҚйЎ№пјҢеҲҷеҸҜд»ҘдҪҝз”ЁиҜҘ validate='one_to_many'еҸӮж•°пјҢиҝҷдёҚдјҡеј•еҸ‘ејӮеёёгҖӮ
pd.merge(left, right, on='B', how='outer', validate="one_to_many") # жү“еҚ°зҡ„з»“жһң: A_x B A_y 0 1 1 NaN 1 2 2 4.0 2 2 2 5.0 3 2 2 6.0
еҸӮж•°пјҡ
validate : str, optional If specified, checks if merge is of specified type. вҖңone_to_oneвҖқ or вҖң1:1вҖқ: check if merge keys are unique in both left and right datasets. вҖңone_to_manyвҖқ or вҖң1:mвҖқ: check if merge keys are unique in left dataset. вҖңmany_to_oneвҖқ or вҖңm:1вҖқ: check if merge keys are unique in right dataset. вҖңmany_to_manyвҖқ or вҖңm:mвҖқ: allowed, but does not result in checks.
зңӢе®ҢдәҶиҝҷзҜҮж–Үз« пјҢзӣёдҝЎдҪ еҜ№вҖңpandasжҖҺд№ҲдҪҝз”Ёmergeе®һзҺ°зҷҫеҖҚеҠ йҖҹзҡ„ж“ҚдҪңвҖқжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеҰӮжһңжғідәҶи§ЈжӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ