жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚдәҶdataframeдёӨеҲ—зӣёд№ҳжһ„йҖ ж–°зү№еҫҒзҡ„зӨәдҫӢеҲҶжһҗпјҢе…·жңүдёҖе®ҡеҖҹйүҙд»·еҖјпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢеҸҜд»ҘеҸӮиҖғдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« д№ӢеҗҺеӨ§жңү收иҺ·пјҢдёӢйқўи®©е°Ҹзј–еёҰзқҖеӨ§е®¶дёҖиө·дәҶи§ЈдёҖдёӢгҖӮ
зӣ®зҡ„жҳҜд»ҺaдёӯзӯӣйҖүеҮәж•°еҖјеңЁ4~6д№Ӣй—ҙзҡ„ж•°жҚ®пјҢеҰӮжһңз¬ҰеҗҲе°ұжҳҜTrueпјҢеҗҰеҲҷе°ұжҳҜFalseгҖӮ
import pandas as pd
lists=pd.DataFrame({'a':[1,2,3,4,5,6,7,8,9]})
lists['b']=(lists['a']<6).mul(lists['a']>4)иЎҘе……пјҡdataframeжұӮдёӨеҲ—зҡ„зӣёд№ҳпјҢеҶҚе°Ҷиҫ“еҮәдёәж–°зҡ„дёҖеҲ—
df["new"]=df3["rate"]*df3["duration"]
newдёәж–°зҡ„дёҖеҲ—зҡ„еҲ—еҗҚ
rateе’ҢdurationдёәйңҖиҰҒзӣёд№ҳзҡ„еҲ—
еҠ пјҢеҮҸпјҢд№ҳпјҢйҷӨйғҪйҖӮз”ЁпјҒ
иЎҘе……пјҡDataFrameиЎҚз”ҹж–°зү№еҫҒж“ҚдҪң
#е°ҶLBL1зү№еҫҒзҡ„еҖјиЎҚз”ҹдёәone-hotеҪўејҸзҡ„ж–°зү№еҫҒ
piao=df_train_log.LBL1.value_counts().index
#е…Ҳжһ„йҖ дёҖдёӘдёҙж—¶зҡ„df
df_tmp=pd.DataFrame({'USRID':df_train_log.drop_duplicates('USRID').USRID.values})
#е°ҶжүҖжңүзҡ„ж–°зү№еҫҒеҲ—йғҪзҪ®дёә0
for i in piao:
df_tmp['PIAO_'+i]=0
#иҝӣиЎҢеҲҶз»„дҫҝеҲ©пјҢжңүиҝҷдёӘзү№еҫҒе°ұзҪ®дёә1пјҢеҺҹж•°жҚ®жҜҸдёӘUSRIDжңүеӨҡжқЎи®°еҪ•пјҢжүҖд»ҘеҲҶз»„з»ҹи®Ў
group=df_train_log.groupby(['USRID'])
for k in group.groups.keys():
t = group.get_group(k)
id=t.USRID.value_counts().index[0]
tmp_list=t.LBL1.value_counts().index
for j in tmp_list:
df_tmp['PIAO_'+j].loc[df_tmp.USRID==id]=1group=df_train_log.groupby(['USRID'])
lt=[]
list_max_lbl1=[]
list_max_lbl2=[]
list_max_lbl3=[]
for k in group.groups.keys():
t = group.get_group(k)
#йҖҡиҝҮvalue_countsжүҫеҮәеҮәзҺ°ж¬Ўж•°жңҖеӨҡзҡ„йЎ№
argmx = np.argmax(t['EVT_LBL'].value_counts())
lbl1_max=np.argmax(t['LBL1'].value_counts())
lbl2_max=np.argmax(t['LBL2'].value_counts())
lbl3_max=np.argmax(t['LBL3'].value_counts())
list_max_lbl1.append(lbl1_max)
list_max_lbl2.append(lbl2_max)
list_max_lbl3.append(lbl3_max)
#еҸӘз•ҷдёӢеҮәзҺ°ж¬Ўж•°жңҖеӨҡзҡ„йЎ№
c = t[t['EVT_LBL']==argmx].drop_duplicates('EVT_LBL')
#ж”ҫе…Ҙlistдёӯ
lt.append(c)
#жһ„йҖ дёҖдёӘж–°зҡ„df
df_train_log_new = pd.concat(lt)
#еҸҰеӨ–еҸҲжһ„йҖ дәҶдёүдёӘзү№еҫҒпјҢLBL1-LBL3еҲҶеҲ«еҮәзҺ°ж¬Ўж•°жңҖеӨҡзҡ„йЎ№
df_train_log_new['LBL1_MAX']=list_max_lbl1
df_train_log_new['LBL2_MAX']=list_max_lbl2
df_train_log_new['LBL3_MAX']=list_max_lbl3#еҲӣйҖ дёҙж—¶dfпјҢжҳҹжңҹдёүпјҢжҳҹжңҹе…ӯпјҢжҳҹжңҹдёғпјҢйғҪй»ҳи®ӨзҪ®дёә0
df_day=pd.DataFrame({'USRID':df_train_log.drop_duplicates('USRID').USRID.values})
df_day['weekday_3']=0
df_day['weekday_6']=0
df_day['weekday_7']=0
#еҲҶз»„з»ҹи®ЎпјҢжңүе°ұзҪ®дёә1пјҢжІЎжңүзҪ®дёә0
group=df_train_log.groupby(['USRID'])
for k in group.groups.keys():
t = group.get_group(k)
id=t.USRID.value_counts().index[0]
tmp_list=t.occ_dayofweek.value_counts().index
for j in tmp_list:
if j==3:
df_day['weekday_3'].loc[df_tmp.USRID==id]=1
elif j==6:
df_day['weekday_6'].loc[df_tmp.USRID==id]=1
elif j==7:
df_day['weekday_7'].loc[df_tmp.USRID==id]=1
#йҰ–е…Ҳе°Ҷж—ҘжңҹиҪ¬еҢ–дёәж—¶й—ҙжҲіпјҢ并иөӢдәҲдёҖдёӘж–°зү№еҫҒ
tmp_list=[]
for i in df_train_log.OCC_TIM:
d=datetime.datetime.strptime(str(i),"%Y-%m-%d %H:%M:%S")
evt_time = time.mktime(d.timetuple())
tmp_list.append(evt_time)
df_train_log['time']=tmp_list
#жҜҸдёӢдёҖиЎҢеҮҸеҺ»дёҠдёҖиЎҢпјҢеҫ—еҲ°appеҒңз•ҷж—¶й—ҙ
df_train_log['diff_time']=df_train_log.time-df_train_log.time.shift(1)
#жһ„йҖ дёҖдёӘж–°зҡ„dataFrameпјҢеҲҶз»„еҫ—еҲ°жҹҘзңӢappзҡ„еӨ©ж•°
df_time=pd.DataFrame({'USRID':df_train_log.drop_duplicates('USRID').USRID.values})
#жңүеҮ еӨ©жҹҘзңӢ
df_time['days']=0
group=df_train_log.groupby(['USRID'])
for k in group.groups.keys():
t = group.get_group(k)
id=set(t.USRID).pop()
df_time['days'].loc[df_time.USRID==id]= len(t.occ_day.value_counts().index)
#еҺ»жҺүдёҖдәӣејӮеёёж—¶й—ҙжҲіпјҢжҜ”еҰӮй—ҙйҡ”дёӨеӨ©зҡ„зӣёеҮҸпјҢиӮҜе®ҡдёҚеҗҲйҖӮпјҢnaзҡ„д№ҹеҺ»жҺүдәҶ
df_train_log=df_train_log[(df_train_log.diff_time>0)&(df_train_log.diff_time<8000)]
#зҙҜи®ЎеҒңз•ҷж—¶й—ҙ
group_stayTime=df_train_log['diff_time'].groupby(df_train_log['USRID']).sum()
#еҲӣйҖ ж–°зҡ„df
df_tmp=pd.DataFrame({'USRID':list(group_stayTime.index.values),'stay_time':list(group_stayTime.values)})
#еҗҲ并жҲҗдёҖдёӘж–°зҡ„df
df=pd.merge(df_time,df_tmp,on=['USRID'],how='left')#еҗҲ并еҗҺпјҢзјәеӨұзҡ„еҒңз•ҷж—¶й—ҙпјҢзҪ®дёә0df.fillna(0,axis=1,inplace=True)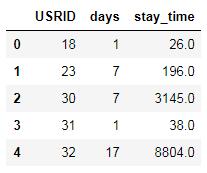
ж„ҹи°ўдҪ иғҪеӨҹи®Өзңҹйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« пјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„вҖңdataframeдёӨеҲ—зӣёд№ҳжһ„йҖ ж–°зү№еҫҒзҡ„зӨәдҫӢеҲҶжһҗвҖқиҝҷзҜҮж–Үз« еҜ№еӨ§е®¶жңүеё®еҠ©пјҢеҗҢж—¶д№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘пјҢе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢжӣҙеӨҡзӣёе…ізҹҘиҜҶзӯүзқҖдҪ жқҘеӯҰд№ !
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ