您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
安装:Installing Beautiful Soup4
功能:BeautifulSoup用于从HTML和XML文件中提取数据
常用场景:网页爬取数据或文本资源后,对其进行解析,获取所需信息
以下详细的介绍了beautifulsoup的基础用法
BeautifulSoup 将html文档转换成树形结构对象,包含:
① tag(原html标签,有name和attribute属性)
② NavigableString(包装tag中的字符串,通过string获得字符串)
③ BeautifulSoup(表示一个文档的全部内容)
yourhtml = '<b class="boldest">Extremely bold</b>'
soup = BeautifulSoup(yourhtml, parse_method)
# 获取tag名称
soup.tag.name
# 还可改变soup对象的tag名称b
tag.name = "blockquote" # 变为<blockquote class="boldest">Extremely bold</blockquote>
# 获取tag的属性
soup.tag.attrs # {u'class': u'boldest'}
# 取得标签下的属性class对应的值(类似字典取值)
soup.tag["class"] # u'boldest'
# 如果yourhtml有多值属性,比如'<p class="body strikeout"></p>',class对应的属性为["body", "strikeout"]列表
# 获取NavigableString类包装的字符串
soup.tag.string # u'Extremely bold'
# NavigableString类包装的子符串不能编辑但可替换,tag.string.replace_with("No longer bold")1.2 解析方法parse_method
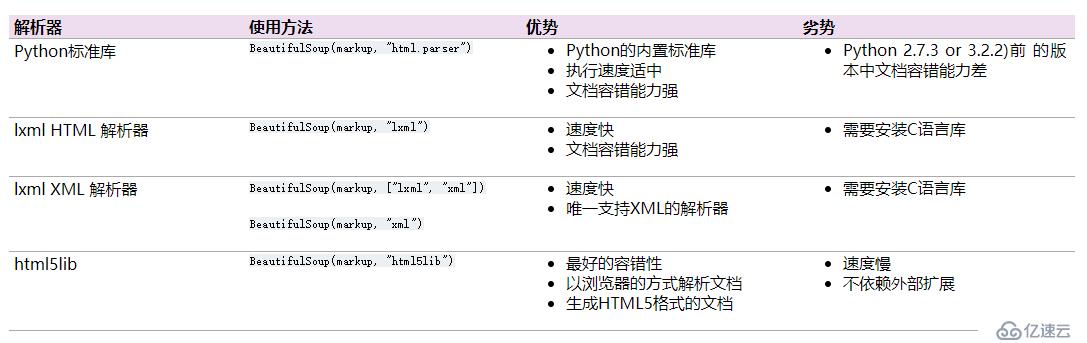
BeautifulSoup 为不同的解析器提供了相同的接口,但是如果不是标准格式的文档结构,不同的解析器可能解析出不同结构的树型文档(特别是XML解析器和HTML解析器),如果是标准格式文档,则不同解析器只是解析速度不同,解析结果是一致的。
# 直接获取tag_name标签
soup.tag_name # 如soup.head, soup.title, soup.body.b
# 将tag_name的直接子字节以列表方式返回
soup.tag_name.contents # 字符没有子节点所以没有contents属性
# 返回标签直接子节点的生成器,通过遍历获取每一个子节点内容
soup.tag_name.children
# 返回tag_name下所有子孙节点内容的生成器
soup.tag_name.descendants
soup.tag_name.string # 仅当tag_name下只有一个字符串字节时,可返回子字节,但若有多个子字节,.string方法无法确定应调用哪个子节点内容,所以会返回None。所以应通过.strings 来循环获取,.stripped_strings 同时可以去除多余的空白内容
for string in soup.stripped_strings:
print(repr(string))
"""
u'Once upon a time there were three little sisters; and their names were'
u'Elsie'
u','
u'Lacie'
"""第3、4点暂时不做详细的讨论
5.1 find
查找符合条件的第一个内容
5.1.1 参数:
find( name # 查找标签
,attrs # 查找标签属性
,recursive # 循环
,text # 查找文本) 找目标首次出现的结果,返回一个beautfulsoup的标签对象
from bs4 import BeautifulSoup
with open('ecologicalpyramid.html', 'r') as ecological_pyramid:
soup = BeautifulSoup(ecological_pyramid, 'html')
producer_string = soup.find(text = 'plants') # 通过文本查找:plants
producer_entries = soup.find('ul') # 标签查找
soup.find(id="link3") # 通过id查找5.1.2 通过class属性查找
class属性规定了元素的类名,但是查找时没办法将class当做变量名,有以下查询方法。以下find替换为find_all同样可行
soup.find("span",{"class":{"green","red"}})
或
soup.find(name="span", attrs={"green" :"red"}
或
soup.find(class_="green") # 注意class_有下划线
或
soup.find("", {"class":"green"})5.2 正则表达式
在没有标签或者文本的情况下可使用正则查询,比如查找邮箱
import re
from bs4 import BeautifulSoup
email_id_example = """<br/>
<div>The below HTML has the information that has email ids.</div>
abc@example.com
<div>xyz@example.com</div>
<span>foo@example.com</span>
"""
soup = BeautifulSoup(email_id_example)
emailid_regexp = re.compile("\w+@\w+\.\w+") # \w+ 匹配字母或数字或下划线或汉字一次或多次
first_email_id = soup.find(text=emailid_regexp) # 用正则表达式匹配文本
print(first_email_id)
输出结果:abc@example.com5.3 find_all
soup.find_all()查找符合条件的所有内容
5.3.1 参数:
find_all(name, attrs, recursive, text, limit)
limit参数可以限制得到的结果的数目(当limit=1即和find()一样的结果)
recursive=False表示只返回最近的子节点
text可传递指定寻找的字符串(可以是列表)
5.3.2 正则结合find_all()使用
目的:查找所有a标签,且字符串内容包含关键字“Elsie”
for x in soup.find_all('a',href = re.compile('lacie')):
print(x)
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>5.3.3 get
一般href属性对应的值为链接
目的:1.获取所有链接,保存在列表中;2.查询所有a标签,输出所有标签中的“字符串”内容;3.查找所有含"id"属性的tag
linklist = []
for x in soup.find_all('a'):
link = x.get('href') # 获取属性值的技巧
if link:
linklist.append(link)
"""
linklist:
http://example.com/elsie
http://example.com/lacie
http://example.com/tillie
"""
string = x.get_text() # 获取所有标签中所有的“字符串”内容
soup.find_all(id=True) # 查找所有含"id"属性的tag,无论id值是什么免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。