您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍“怎么在Linux上创建并调试转储文件”,在日常操作中,相信很多人在怎么在Linux上创建并调试转储文件问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”怎么在Linux上创建并调试转储文件”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
崩溃转储、内存转储、核心转储、系统转储……这些全都会产生同样的产物:一个包含了当应用崩溃时,在那个特定时刻应用的内存状态的文件。
这是一篇指导文章,你可以通过克隆示例的应用仓库来跟随学习:
git clone https://github.com/hANSIc99/core_dump_example.git
信号如何关联到转储
信号是操作系统和用户应用之间的进程间通讯。Linux 使用 POSIX 标准中定义的信号。在你的系统上,你可以在 /usr/include/bits/signum-generic.h 找到标准信号的定义。如果你想知道更多关于在你的应用程序中使用信号的信息,这有一个信息丰富的 signal 手册页。简单地说,Linux 基于预期的或意外的信号来触发进一步的活动。
当你退出一个正在运行的应用程序时,应用程序通常会收到 SIGTERM 信号。因为这种类型的退出信号是预期的,所以这个操作不会创建一个内存转储。
以下信号将导致创建一个转储文件(来源:GNU C库):
SIGFPE:错误的算术操作
SIGILL:非法指令
SIGSEGV:对存储的无效访问
SIGBUS:总线错误
SIGABRT:程序检测到的错误,并通过调用 abort() 来报告
SIGIOT:这个信号在 Fedora 上已经过时,过去在 PDP-11 上用 abort() 时触发,现在映射到 SIGABRT
创建转储文件
导航到 core_dump_example 目录,运行 make,并使用 -c1 开关执行该示例二进制:
./coredump -c1
该应用将以状态 4 退出,带有如下错误:
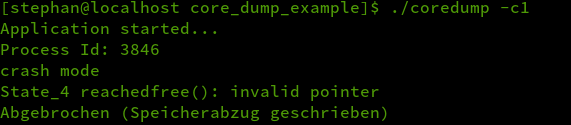
Dump written“Abgebrochen (Speicherabzug geschrieben) ”(LCTT 译注:这是德语,应该是因为本文作者系统是德语环境)大致翻译为“分段故障(核心转储)”。
是否创建核心转储是由运行该进程的用户的资源限制决定的。你可以用 ulimit 命令修改资源限制。
检查当前创建核心转储的设置:
ulimit -c
如果它输出 unlimited,那么它使用的是(建议的)默认值。否则,用以下方法纠正限制:
ulimit -c unlimited
要禁用创建核心转储,可以设置其大小为 0:
ulimit -c 0
这个数字指定了核心转储文件的大小,单位是块。
什么是核心转储?
内核处理核心转储的方式定义在:
/proc/sys/kernel/core_pattern
我运行的是 Fedora 31,在我的系统上,该文件包含的内容是:
/usr/lib/systemd/systemd-coredump %P %u %g %s %t %c %h
这表明核心转储被转发到 systemd-coredump 工具。在不同的 Linux 发行版中,core_pattern 的内容会有很大的不同。当使用 systemd-coredump 时,转储文件被压缩保存在 /var/lib/systemd/coredump 下。你不需要直接接触这些文件,你可以使用 coredumpctl。比如说:
coredumpctl list
会显示系统中保存的所有可用的转储文件。
使用 coredumpctl dump,你可以从最后保存的转储文件中检索信息:
[stephan@localhost core_dump_example]$ ./coredump Application started… (…….) Message: Process 4598 (coredump) of user 1000 dumped core. Stack trace of thread 4598: #0 0x00007f4bbaf22625 __GI_raise (libc.so.6) #1 0x00007f4bbaf0b8d9 __GI_abort (libc.so.6) #2 0x00007f4bbaf664af __libc_message (libc.so.6) #3 0x00007f4bbaf6da9c malloc_printerr (libc.so.6) #4 0x00007f4bbaf6f49c _int_free (libc.so.6) #5 0x000000000040120e n/a (/home/stephan/Dokumente/core_dump_example/coredump) #6 0x00000000004013b1 n/a (/home/stephan/Dokumente/core_dump_example/coredump) #7 0x00007f4bbaf0d1a3 __libc_start_main (libc.so.6) #8 0x000000000040113e n/a (/home/stephan/Dokumente/core_dump_example/coredump) Refusing to dump core to tty (use shell redirection or specify — output).
这表明该进程被 SIGABRT 停止。这个视图中的堆栈跟踪不是很详细,因为它不包括函数名。然而,使用 coredumpctl debug,你可以简单地用调试器(默认为 GDB)打开转储文件。输入 bt(回溯backtrace的缩写)可以得到更详细的视图:
Core was generated by `./coredump -c1'. Program terminated with signal SIGABRT, Aborted. #0 __GI_raise (sigsig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:50 50 return ret; (gdb) bt #0 __GI_raise (sigsig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:50 #1 0x00007fc37a9aa8d9 in __GI_abort () at abort.c:79 #2 0x00007fc37aa054af in __libc_message (actionaction=action@entry=do_abort, fmtfmt=fmt@entry=0x7fc37ab14f4b "%s\n") at ../sysdeps/posix/libc_fatal.c:181 #3 0x00007fc37aa0ca9c in malloc_printerr (strstr=str@entry=0x7fc37ab130e0 "free(): invalid pointer") at malloc.c:5339 #4 0x00007fc37aa0e49c in _int_free (av=<optimized out>, p=<optimized out>, have_lock=0) at malloc.c:4173 #5 0x000000000040120e in freeSomething(void*) () #6 0x0000000000401401 in main ()
与后续帧相比,main() 和 freeSomething() 的内存地址相当低。由于共享对象被映射到虚拟地址空间末尾的区域,可以认为 SIGABRT 是由共享库中的调用引起的。共享对象的内存地址在多次调用之间并不是恒定不变的,所以当你看到多次调用之间的地址不同时,完全可以认为是共享对象。
堆栈跟踪显示,后续的调用源于 malloc.c,这说明内存的(取消)分配可能出了问题。
在源代码中,(即使没有任何 C++ 知识)你也可以看到,它试图释放一个指针,而这个指针并没有被内存管理函数返回。这导致了未定义的行为,并导致了 SIGABRT。
void freeSomething(void *ptr){ free(ptr); } int nTmp = 5; int *ptrNull = &nTmp; freeSomething(ptrNull);systemd 的这个 coredump 工具可以在 /etc/systemd/coredump.conf 中配置。可以在 /etc/systemd/systemd-tmpfiles-clean.timer 中配置轮换清理转储文件。
你可以在其手册页中找到更多关于 coredumpctl 的信息。
用调试符号编译
打开 Makefile 并注释掉第 9 行的最后一部分。现在应该是这样的:
CFLAGS =-Wall -Werror -std=c++11 -g
-g 开关使编译器能够创建调试信息。启动应用程序,这次使用 -c2 开关。
./coredump -c2
你会得到一个浮点异常。在 GDB 中打开该转储文件:
coredumpctl debug
这一次,你会直接被指向源代码中导致错误的那一行:
Reading symbols from /home/stephan/Dokumente/core_dump_example/coredump… [New LWP 6218] Core was generated by `./coredump -c2'. Program terminated with signal SIGFPE, Arithmetic exception. #0 0x0000000000401233 in zeroDivide () at main.cpp:29 29 nRes = 5 / nDivider; (gdb)
键入 list 以获得更好的源代码概览:
(gdb) list 24 int zeroDivide(){ 25 int nDivider = 5; 26 int nRes = 0; 27 while(nDivider > 0){ 28 nDivider--; 29 nRes = 5 / nDivider; 30 } 31 return nRes; 32 }使用命令 info locals 从应用程序失败的时间点检索局部变量的值:
(gdb) info locals nDivider = 0 nRes = 5
结合源码,可以看出,你遇到的是零除错误:
nRes = 5 / 0
结论
了解如何处理转储文件将帮助你找到并修复应用程序中难以重现的随机错误。而如果不是你的应用程序,将核心转储转发给开发人员将帮助她或他找到并修复问题。
到此,关于“怎么在Linux上创建并调试转储文件”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。