жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮж–Үз« з»ҷеӨ§е®¶еҲҶдә«зҡ„жҳҜжңүе…іLinuxCPUиҫҫеҲ°з“¶йўҲиҜҘжҖҺж ·дјҳеҢ–пјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еӯҰд№ пјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·пјҢиҜқдёҚеӨҡиҜҙпјҢи·ҹзқҖе°Ҹзј–дёҖиө·жқҘзңӢзңӢеҗ§гҖӮ
еңЁLinuxзі»з»ҹдёӯпјҢз”ұдәҺжҲҗжң¬зҡ„йҷҗеҲ¶пјҢеҫҖеҫҖдјҡеӯҳеңЁиө„жәҗдёҠзҡ„дёҚи¶іпјҢдҫӢеҰӮ CPUгҖҒеҶ…еӯҳгҖҒзҪ‘з»ңгҖҒIO жҖ§иғҪгҖӮжң¬ж–ҮпјҢе°ұеҜ№ Linux иҝӣзЁӢе’Ң CPU зҡ„еҺҹзҗҶиҝӣиЎҢеҲҶжһҗпјҢжҖ»з»“еҮә CPU жҖ§иғҪдјҳеҢ–зҡ„ж–№жі•гҖӮ
1. еҲҶжһҗжүӢж®ө
еңЁзҗҶи§Је№іеқҮиҙҹиҪҪд№ӢеүҚпјҢе…ҲиҰҒзҗҶжё…жҘҡ Linux дёӢзҡ„иҝӣзЁӢзҠ¶жҖҒгҖӮ
1.1. иҝӣзЁӢзҠ¶жҖҒ
1.1.1. R (TASK_RUNNING)пјҢеҸҜжү§иЎҢзҠ¶жҖҒ
еҸӘжңүеңЁиҜҘзҠ¶жҖҒзҡ„иҝӣзЁӢжүҚеҸҜиғҪеңЁ CPU дёҠиҝҗиЎҢгҖӮиҖҢеҗҢдёҖж—¶еҲ»еҸҜиғҪжңүеӨҡдёӘиҝӣзЁӢеӨ„дәҺеҸҜжү§иЎҢзҠ¶жҖҒпјҢиҝҷдәӣиҝӣзЁӢзҡ„ task_struct з»“жһ„(иҝӣзЁӢжҺ§еҲ¶еқ—)иў«ж”ҫе…ҘеҜ№еә” CPU зҡ„еҸҜжү§иЎҢйҳҹеҲ—дёӯ(дёҖдёӘиҝӣзЁӢжңҖеӨҡеҸӘиғҪеҮәзҺ°еңЁдёҖдёӘ CPU зҡ„еҸҜжү§иЎҢйҳҹеҲ—дёӯ)гҖӮиҝӣзЁӢи°ғеәҰеҷЁзҡ„д»»еҠЎе°ұжҳҜд»Һеҗ„дёӘ CPU зҡ„еҸҜжү§иЎҢйҳҹеҲ—дёӯеҲҶеҲ«йҖүжӢ©дёҖдёӘиҝӣзЁӢеңЁиҜҘ CPU дёҠиҝҗиЎҢгҖӮ
еҫҲеӨҡж“ҚдҪңзі»з»ҹж•ҷ科д№Ұе°ҶжӯЈеңЁ CPU дёҠжү§иЎҢзҡ„иҝӣзЁӢе®ҡд№үдёә RUNNING зҠ¶жҖҒгҖҒиҖҢе°ҶеҸҜжү§иЎҢдҪҶжҳҜе°ҡжңӘиў«и°ғеәҰжү§иЎҢзҡ„иҝӣзЁӢе®ҡд№үдёәREADYзҠ¶жҖҒпјҢиҝҷдёӨз§ҚзҠ¶жҖҒеңЁlinuxдёӢз»ҹдёҖдёә TASK_RUNNING зҠ¶жҖҒгҖӮ
1.1.2. S (TASK_INTERRUPTIBLE)пјҢеҸҜдёӯж–ӯзҡ„зқЎзң зҠ¶жҖҒ
еӨ„дәҺиҝҷдёӘзҠ¶жҖҒзҡ„иҝӣзЁӢеӣ дёәзӯүеҫ…жҹҗжҹҗдәӢ件зҡ„еҸ‘з”ҹ(жҜ”еҰӮзӯүеҫ… socket иҝһжҺҘгҖҒзӯүеҫ…дҝЎеҸ·йҮҸ)пјҢиҖҢиў«жҢӮиө·гҖӮиҝҷдәӣиҝӣзЁӢзҡ„ task_struct з»“жһ„иў«ж”ҫе…ҘеҜ№еә”дәӢ件зҡ„зӯүеҫ…йҳҹеҲ—дёӯгҖӮеҪ“иҝҷдәӣдәӢ件еҸ‘з”ҹж—¶
(з”ұеӨ–йғЁдёӯж–ӯи§ҰеҸ‘гҖҒжҲ–з”ұе…¶д»–иҝӣзЁӢи§ҰеҸ‘)пјҢеҜ№еә”зҡ„зӯүеҫ…йҳҹеҲ—дёӯзҡ„дёҖдёӘжҲ–еӨҡдёӘиҝӣзЁӢе°Ҷиў«е”ӨйҶ’гҖӮйҖҡиҝҮ ps е‘Ҫд»ӨжҲ‘们дјҡзңӢеҲ°пјҢдёҖиҲ¬жғ…еҶөдёӢпјҢиҝӣзЁӢеҲ—иЎЁдёӯзҡ„з»қеӨ§еӨҡж•°иҝӣзЁӢйғҪеӨ„дәҺ TASK_INTERRUPTIBLE зҠ¶жҖҒ(йҷӨйқһжңәеҷЁзҡ„иҙҹиҪҪеҫҲй«ҳ)гҖӮжҜ•з«ҹ CPU е°ұиҝҷд№ҲдёҖдёӨдёӘпјҢиҝӣзЁӢеҠЁиҫ„еҮ еҚҒдёҠзҷҫдёӘпјҢеҰӮжһңдёҚжҳҜз»қеӨ§еӨҡж•°иҝӣзЁӢйғҪеңЁзқЎзң пјҢCPU еҸҲжҖҺд№Ҳе“Қеә”еҫ—иҝҮжқҘгҖӮ
1.1.3. D (TASK_UNINTERRUPTIBLE)пјҢдёҚеҸҜдёӯж–ӯзҡ„зқЎзң зҠ¶жҖҒ
дёҺ TASK_INTERRUPTIBLE зҠ¶жҖҒзұ»дјјпјҢиҝӣзЁӢеӨ„дәҺзқЎзң зҠ¶жҖҒпјҢдҪҶжҳҜжӯӨеҲ»иҝӣзЁӢжҳҜдёҚеҸҜдёӯж–ӯзҡ„гҖӮ
дёҚеҸҜдёӯж–ӯпјҢжҢҮзҡ„并дёҚжҳҜ CPU дёҚе“Қеә”еӨ–йғЁзЎ¬д»¶зҡ„дёӯж–ӯпјҢиҖҢжҳҜжҢҮиҝӣзЁӢдёҚе“Қеә”ејӮжӯҘдҝЎеҸ·гҖӮ
з»қеӨ§еӨҡж•°жғ…еҶөдёӢпјҢиҝӣзЁӢеӨ„еңЁзқЎзң зҠ¶жҖҒж—¶пјҢжҖ»жҳҜеә”иҜҘиғҪеӨҹе“Қеә”ејӮжӯҘдҝЎеҸ·зҡ„гҖӮеҗҰеҲҷдҪ е°ҶжғҠеҘҮзҡ„еҸ‘зҺ°пјҢkill -9 з«ҹ然жқҖдёҚжӯ»дёҖдёӘжӯЈеңЁзқЎзң зҡ„иҝӣзЁӢдәҶ!дәҺжҳҜжҲ‘们д№ҹеҫҲеҘҪзҗҶи§ЈпјҢдёәд»Җд№Ҳ ps е‘Ҫд»ӨзңӢеҲ°зҡ„иҝӣзЁӢеҮ д№ҺдёҚдјҡеҮәзҺ° TASK_UNINTERRUPTIBLE зҠ¶жҖҒпјҢиҖҢжҖ»жҳҜ TASK_INTERRUPTIBLE зҠ¶жҖҒгҖӮ
иҖҢ TASK_UNINTERRUPTIBLE зҠ¶жҖҒеӯҳеңЁзҡ„ж„Ҹд№үе°ұеңЁдәҺпјҢеҶ…ж ёзҡ„жҹҗдәӣеӨ„зҗҶжөҒзЁӢжҳҜдёҚиғҪиў«жү“ж–ӯзҡ„гҖӮеҰӮжһңе“Қеә”ејӮжӯҘдҝЎеҸ·пјҢзЁӢеәҸзҡ„жү§иЎҢжөҒзЁӢдёӯе°ұдјҡиў«жҸ’е…ҘдёҖж®өз”ЁдәҺеӨ„зҗҶејӮжӯҘдҝЎеҸ·зҡ„жөҒзЁӢ(иҝҷдёӘжҸ’е…Ҙзҡ„жөҒзЁӢеҸҜиғҪеҸӘеӯҳеңЁдәҺеҶ…ж ёжҖҒпјҢд№ҹеҸҜиғҪ延伸еҲ°з”ЁжҲ·жҖҒ)пјҢдәҺжҳҜеҺҹжңүзҡ„жөҒзЁӢе°ұиў«дёӯж–ӯдәҶгҖӮ
(еҸӮи§ҒгҖҠlinux еҶ…ж ёејӮжӯҘдёӯж–ӯжө…жһҗгҖӢ) еңЁиҝӣзЁӢеҜ№жҹҗдәӣ硬件иҝӣиЎҢж“ҚдҪңж—¶(жҜ”еҰӮиҝӣзЁӢи°ғз”Ё read зі»з»ҹи°ғз”ЁеҜ№жҹҗдёӘи®ҫеӨҮж–Ү件иҝӣиЎҢиҜ»ж“ҚдҪңпјҢиҖҢ read зі»з»ҹи°ғз”ЁжңҖз»Ҳжү§иЎҢеҲ°еҜ№еә”и®ҫеӨҮй©ұеҠЁзҡ„д»Јз ҒпјҢ并дёҺеҜ№еә”зҡ„зү©зҗҶи®ҫеӨҮиҝӣиЎҢдәӨдә’)пјҢеҸҜиғҪйңҖиҰҒдҪҝз”Ё TASK_UNINTERRUPTIBLE зҠ¶жҖҒеҜ№иҝӣзЁӢиҝӣиЎҢдҝқжҠӨпјҢд»ҘйҒҝе…ҚиҝӣзЁӢдёҺи®ҫеӨҮдәӨдә’зҡ„иҝҮзЁӢиў«жү“ж–ӯпјҢйҖ жҲҗи®ҫеӨҮйҷ·е…ҘдёҚеҸҜжҺ§зҡ„зҠ¶жҖҒгҖӮиҝҷз§Қжғ…еҶөдёӢзҡ„ TASK_UNINTERRUPTIBLE зҠ¶жҖҒжҖ»жҳҜйқһеёёзҹӯжҡӮзҡ„пјҢйҖҡиҝҮ ps е‘Ҫд»Өеҹәжң¬дёҠдёҚеҸҜиғҪжҚ•жҚүеҲ°гҖӮ
1.1.4. T (TASK_STOPPED or TASK_TRACED)пјҢжҡӮеҒңзҠ¶жҖҒжҲ–и·ҹиёӘзҠ¶жҖҒ
еҗ‘иҝӣзЁӢеҸ‘йҖҒдёҖдёӘ SIGSTOP дҝЎеҸ·пјҢе®ғе°ұдјҡеӣ е“Қеә”иҜҘдҝЎеҸ·иҖҢиҝӣе…Ҙ TASK_STOPPED зҠ¶жҖҒ(йҷӨйқһиҜҘиҝӣзЁӢжң¬иә«еӨ„дәҺ TASK_UNINTERRUPTIBLE зҠ¶жҖҒиҖҢдёҚе“Қеә”дҝЎеҸ·)гҖӮ(SIGSTOP дёҺ SIGKILL дҝЎеҸ·дёҖж ·пјҢжҳҜйқһеёёејәеҲ¶зҡ„гҖӮдёҚе…Ғи®ёз”ЁжҲ·иҝӣзЁӢйҖҡиҝҮ signal зі»еҲ—зҡ„зі»з»ҹи°ғз”ЁйҮҚж–°и®ҫзҪ®еҜ№еә”зҡ„дҝЎеҸ·еӨ„зҗҶеҮҪж•°гҖӮ)
еҗ‘иҝӣзЁӢеҸ‘йҖҒдёҖдёӘ SIGCONT дҝЎеҸ·пјҢеҸҜд»Ҙи®©е…¶д»Һ TASK_STOPPED зҠ¶жҖҒжҒўеӨҚеҲ° TASK_RUNNING зҠ¶жҖҒгҖӮ
еҪ“иҝӣзЁӢжӯЈеңЁиў«и·ҹиёӘж—¶пјҢе®ғеӨ„дәҺ TASK_TRACED иҝҷдёӘзү№ж®Ҡзҡ„зҠ¶жҖҒгҖӮ"жӯЈеңЁиў«и·ҹиёӘ"жҢҮзҡ„жҳҜиҝӣзЁӢжҡӮеҒңдёӢжқҘпјҢзӯүеҫ…и·ҹиёӘе®ғзҡ„иҝӣзЁӢеҜ№е®ғиҝӣиЎҢж“ҚдҪңгҖӮжҜ”еҰӮеңЁ gdb дёӯеҜ№иў«и·ҹиёӘзҡ„иҝӣзЁӢдёӢдёҖдёӘж–ӯзӮ№пјҢиҝӣзЁӢеңЁж–ӯзӮ№еӨ„еҒңдёӢжқҘзҡ„ж—¶еҖҷе°ұеӨ„дәҺ TASK_TRACED зҠ¶жҖҒгҖӮиҖҢеңЁе…¶д»–ж—¶еҖҷпјҢиў«и·ҹиёӘзҡ„иҝӣзЁӢиҝҳжҳҜеӨ„дәҺеүҚйқўжҸҗеҲ°зҡ„йӮЈдәӣзҠ¶жҖҒгҖӮ
еҜ№дәҺиҝӣзЁӢжң¬иә«жқҘиҜҙпјҢTASK_STOPPED е’Ң TASK_TRACED зҠ¶жҖҒеҫҲзұ»дјјпјҢйғҪжҳҜиЎЁзӨәиҝӣзЁӢжҡӮеҒңдёӢжқҘгҖӮиҖҢ TASK_TRACED зҠ¶жҖҒзӣёеҪ“дәҺеңЁ TASK_STOPPED д№ӢдёҠеӨҡдәҶдёҖеұӮдҝқжҠӨпјҢеӨ„дәҺ TASK_TRACED зҠ¶жҖҒзҡ„иҝӣзЁӢдёҚиғҪе“Қеә” SIGCONT дҝЎеҸ·иҖҢиў«е”ӨйҶ’гҖӮеҸӘиғҪзӯүеҲ°и°ғиҜ•иҝӣзЁӢйҖҡиҝҮ ptrace зі»з»ҹи°ғз”Ёжү§иЎҢ PTRACE_CONTгҖҒPTRACE_DETACH зӯүж“ҚдҪң(йҖҡиҝҮ ptrace зі»з»ҹи°ғз”Ёзҡ„еҸӮж•°жҢҮе®ҡж“ҚдҪң)пјҢжҲ–и°ғиҜ•иҝӣзЁӢйҖҖеҮәпјҢиў«и°ғиҜ•зҡ„иҝӣзЁӢжүҚиғҪжҒўеӨҚ TASK_RUNNING зҠ¶жҖҒгҖӮ
1.1.5. Z (TASK_DEAD - EXIT_ZOMBIE)пјҢйҖҖеҮәзҠ¶жҖҒпјҢиҝӣзЁӢжҲҗдёәеғөе°ёиҝӣзЁӢ
иҝӣзЁӢеңЁйҖҖеҮәзҡ„иҝҮзЁӢдёӯпјҢеӨ„дәҺ TASK_DEAD зҠ¶жҖҒгҖӮеңЁиҝҷдёӘйҖҖеҮәиҝҮзЁӢдёӯпјҢиҝӣзЁӢеҚ жңүзҡ„жүҖжңүиө„жәҗе°Ҷиў«еӣһ收пјҢйҷӨдәҶ task_struct з»“жһ„(д»ҘеҸҠе°‘ж•°иө„жәҗ)д»ҘеӨ–гҖӮдәҺжҳҜиҝӣзЁӢе°ұеҸӘеү©дёӢ task_struct иҝҷд№ҲдёӘз©әеЈіпјҢж•…з§°дёәеғөе°ёгҖӮд№ӢжүҖд»Ҙдҝқз•ҷ task_structпјҢжҳҜеӣ дёә task_struct йҮҢйқўдҝқеӯҳдәҶиҝӣзЁӢзҡ„йҖҖеҮәз ҒгҖҒд»ҘеҸҠдёҖдәӣз»ҹи®ЎдҝЎжҒҜгҖӮиҖҢе…¶зҲ¶иҝӣзЁӢеҫҲеҸҜиғҪдјҡе…іеҝғиҝҷдәӣдҝЎжҒҜгҖӮжҜ”еҰӮеңЁ shell дёӯпјҢ$?еҸҳйҮҸе°ұдҝқеӯҳдәҶжңҖеҗҺдёҖдёӘйҖҖеҮәзҡ„еүҚеҸ°иҝӣзЁӢзҡ„йҖҖеҮәз ҒпјҢиҖҢиҝҷдёӘйҖҖеҮәз ҒеҫҖеҫҖиў«дҪңдёә if иҜӯеҸҘзҡ„еҲӨж–ӯжқЎд»¶гҖӮ
еҪ“然пјҢеҶ…ж ёд№ҹеҸҜд»Ҙе°ҶиҝҷдәӣдҝЎжҒҜдҝқеӯҳеңЁеҲ«зҡ„ең°ж–№пјҢиҖҢе°Ҷ task_struct з»“жһ„йҮҠж”ҫжҺүпјҢд»ҘиҠӮзңҒдёҖдәӣз©әй—ҙгҖӮдҪҶжҳҜдҪҝз”Ё task_struct з»“жһ„жӣҙдёәж–№дҫҝпјҢеӣ дёәеңЁеҶ…ж ёдёӯе·Із»Ҹе»әз«ӢдәҶд»Һ pid еҲ° task_struct жҹҘжүҫе…ізі»пјҢиҝҳжңүиҝӣзЁӢй—ҙзҡ„зҲ¶еӯҗе…ізі»гҖӮйҮҠж”ҫжҺү task_structпјҢеҲҷйңҖиҰҒе»әз«ӢдёҖдәӣж–°зҡ„ж•°жҚ®з»“жһ„пјҢд»Ҙдҫҝи®©зҲ¶иҝӣзЁӢжүҫеҲ°е®ғзҡ„еӯҗиҝӣзЁӢзҡ„йҖҖеҮәдҝЎжҒҜгҖӮ
зҲ¶иҝӣзЁӢеҸҜд»ҘйҖҡиҝҮ wait зі»еҲ—зҡ„зі»з»ҹи°ғз”Ё(еҰӮ wait4гҖҒwaitid)жқҘзӯүеҫ…жҹҗдёӘжҲ–жҹҗдәӣеӯҗиҝӣзЁӢзҡ„йҖҖеҮәпјҢ并иҺ·еҸ–е®ғзҡ„йҖҖеҮәдҝЎжҒҜгҖӮ然еҗҺ wait зі»еҲ—зҡ„зі»з»ҹи°ғз”ЁдјҡйЎәдҫҝе°ҶеӯҗиҝӣзЁӢзҡ„е°ёдҪ“(task_struct)д№ҹйҮҠж”ҫжҺүгҖӮ
еӯҗиҝӣзЁӢеңЁйҖҖеҮәзҡ„иҝҮзЁӢдёӯпјҢеҶ…ж ёдјҡз»ҷе…¶зҲ¶иҝӣзЁӢеҸ‘йҖҒдёҖдёӘдҝЎеҸ·пјҢйҖҡзҹҘзҲ¶иҝӣзЁӢжқҘ"收尸"гҖӮиҝҷдёӘдҝЎеҸ·й»ҳи®ӨжҳҜ SIGCHLDпјҢдҪҶжҳҜеңЁйҖҡиҝҮ clone зі»з»ҹи°ғз”ЁеҲӣе»әеӯҗиҝӣзЁӢж—¶пјҢеҸҜд»Ҙи®ҫзҪ®иҝҷдёӘдҝЎеҸ·гҖӮ
1.2. е№іеқҮиҙҹиҪҪ
еҚ•дҪҚж—¶й—ҙеҶ…пјҢзі»з»ҹеӨ„дәҺеҸҜиҝҗиЎҢзҠ¶жҖҒе’ҢдёҚеҸҜдёӯж–ӯзҠ¶жҖҒзҡ„е№іеқҮиҝӣзЁӢж•°пјҢд№ҹе°ұжҳҜе№іеқҮжҙ»и·ғиҝӣзЁӢж•°пјҢе®ғе’Ң CPU дҪҝз”ЁзҺҮ并没жңүзӣҙжҺҘе…ізі»гҖӮ
既然жҳҜе№іеқҮзҡ„жҙ»и·ғиҝӣзЁӢж•°пјҢйӮЈд№ҲжңҖзҗҶжғізҡ„пјҢе°ұжҳҜжҜҸдёӘcpu дёҠйғҪеҲҡеҘҪиҝҗиЎҢзқҖдёҖдёӘиҝӣзЁӢпјҢиҝҷж ·жҜҸдёӘ cpu йғҪеҫ—еҲ°дәҶе……еҲҶеҲ©з”ЁпјҢжҜ”еҰӮеҪ“е№іеқҮиҙҹиҪҪ 2ж—¶пјҢж„Ҹе‘ізқҖд»Җд№Ҳе‘ў?
1гҖҒ еңЁеҸӘжңү2 дёӘ CPUзҡ„зі»з»ҹдёҠпјҢж„Ҹе‘ізқҖжүҖжңүзҡ„ CPUйғҪеҲҡеҘҪиў«е®Ңе…ЁеҚ з”Ё
2гҖҒ еңЁ 4 дёӘCPUзҡ„зі»з»ҹдёҠпјҢж„Ҹе‘ізқҖ CPU жңү 50%зҡ„з©әй—І
3гҖҒ иҖҢеңЁеҸӘжңү 1 дёӘCPU зҡ„зі»з»ҹдёҠпјҢеҲҷж„Ҹе‘ізқҖжңүдёҖеҚҠзҡ„иҝӣзЁӢз«һдәүдёҚеҲ° CPU
1.2.1. е№іеқҮиҙҹиҪҪеӨҡе°‘еҗҲзҗҶ?
е№іеқҮиҙҹиҪҪжңҖзҗҶжғізҡ„жғ…еҶөжҳҜзӯүдәҺ CPU дёӘж•°гҖӮжҹҘзңӢзі»з»ҹ CPU зҡ„е‘Ҫд»ӨеҰӮдёӢпјҡ
cat /proc/cpuinfo
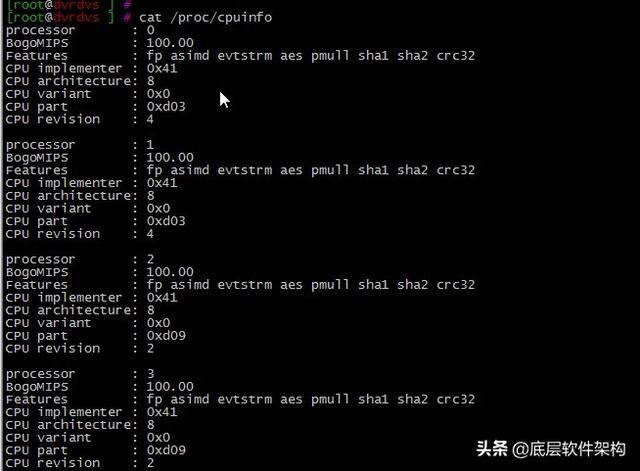
Figure 1 еӣӣж ё CPU жҹҘзңӢе№іеқҮиҙҹиҪҪзҡ„е‘Ҫд»Өпјҡ
з»ҷдәҶжҲ‘们дёүдёӘдёҚеҗҢж—¶й—ҙй—ҙйҡ”зҡ„е№іеқҮеҖјпјҢз»ҷжҲ‘们жҸҗдҫӣдәҶеҲҶжһҗзі»з»ҹиҙҹиҪҪи¶ӢеҠҝзҡ„ж•°жҚ®жқҘжәҗпјҢи®©жҲ‘们жӣҙе…ЁйқўгҖҒжӣҙз«ӢдҪ“ең°зҗҶи§Јзӣ®еүҚзҡ„иҙҹиҪҪжғ…еҶөгҖӮ

1 еҲҶй’ҹгҖҒ5 еҲҶй’ҹгҖҒ15 еҲҶй’ҹ зҡ„дёүдёӘеҖјеҹәжң¬зӣёеҗҢпјҢжҲ–иҖ…зӣёе·®дёҚеӨ§пјҢиҜҙжҳҺзі»з»ҹиҙҹиҪҪеҫҲе№і
еҰӮжһң1 еҲҶй’ҹзҡ„еҖјиҝңе°ҸдәҺ15 еҲҶй’ҹ зҡ„еҖјпјҢиҜҙжҳҺзі»з»ҹжңҖиҝ‘ 1 еҲҶй’ҹзҡ„иҙҹиҪҪеңЁеҮҸе°‘пјҢиҖҢиҝҮеҺ»
15 еҲҶй’ҹеҶ…еҚҙжңүеҫҲеӨ§зҡ„иҙҹиҪҪ
еҰӮжһң1 еҲҶй’ҹ зҡ„еҖјиҝңеӨ§дәҺ 15 еҲҶй’ҹзҡ„еҖјпјҢе°ұиҜҙжҳҺжңҖиҝ‘ 1 еҲҶй’ҹзҡ„иҙҹиҪҪеңЁеўһеҠ гҖӮдёҖж—Ұ 1 еҲҶй’ҹзҡ„е№іеқҮиҙҹиҪҪжҺҘиҝ‘жҲ–и¶…иҝҮдәҶ CPU зҡ„дёӘж•°пјҢе°ұж„Ҹе‘ізқҖзі»з»ҹжӯЈеңЁеҸ‘з”ҹиҝҮиҪҪзҡ„й—®йўҳгҖӮ
uptime е‘Ҫд»ӨеңЁжңүдәӣеөҢе…ҘејҸи®ҫеӨҮдёӯпјҢдјҡиў«иЈҒеҮҸжҺүпјҢдҪҶжҳҜеҸҜд»ҘйҖҡиҝҮ proc ж–Ү件系з»ҹжқҘиҺ·еҸ–гҖӮе‘Ҫд»Өпјҡ
cat /proc/loadavg
еҫҲжҳҫ然пјҢеҪ“еүҚе‘Ҫд»Өеұ•зӨәзҡ„е№іеқҮиҙҹиҪҪеңЁ CPU дёә 4 дёӘж—¶еҖҷе·Із»ҸиҝҮиҪҪ
1.2.2. е№іеқҮиҙҹиҪҪдёҺ CPU дҪҝз”ЁзҺҮ
е№іеқҮиҙҹиҪҪдёҚд»…еҢ…жӢ¬дәҶжӯЈеңЁдҪҝз”Ё CPU зҡ„иҝӣзЁӢпјҢиҝҳеҢ…жӢ¬дәҶзӯүеҫ… CPU е’Ңзӯүеҫ… I/O зҡ„иҝӣзЁӢгҖӮ
CPU дҪҝз”ЁзҺҮжҳҜжҢҮеҚ•дҪҚж—¶й—ҙеҶ… CPU з№Ғеҝҷжғ…еҶөзҡ„з»ҹи®ЎпјҢи·ҹе№іеқҮиҙҹиҪҪ并дёҚдёҖе®ҡе®Ңе…ЁеҜ№еә”гҖӮжҜ”еҰӮпјҡ
CPU еҜҶйӣҶеһӢиҝӣзЁӢпјҢдҪҝз”ЁеӨ§йҮҸ CPU дјҡеҜјиҮҙе№іеқҮиҙҹиҪҪеҚҮй«ҳпјҢжӯӨж—¶иҝҷдёӨиҖ…жҳҜдёҖиҮҙзҡ„;
I/O еҜҶйӣҶеһӢиҝӣзЁӢпјҢзӯүеҫ… I/O д№ҹдјҡеҜјиҮҙе№іеқҮиҙҹиҪҪеҚҮй«ҳпјҢдҪҶ CPU дҪҝз”ЁзҺҮдёҚдёҖе®ҡеҫҲй«ҳ
еӨ§йҮҸзӯүеҫ… CPU зҡ„иҝӣзЁӢи°ғеәҰд№ҹдјҡеҜјиҮҙе№іеқҮиҙҹиҪҪеҚҮй«ҳпјҢжӯӨж—¶зҡ„ CPU дҪҝз”ЁзҺҮд№ҹдјҡжҜ”иҫғй«ҳгҖӮ
1.3. CPU дёҠдёӢж–ҮеҲҮжҚў
еңЁжҜҸдёӘд»»еҠЎиҝҗиЎҢеүҚпјҢ CPU йғҪйңҖиҰҒзҹҘйҒ“д»»еҠЎд»Һе“ӘйҮҢеҠ иҪҪгҖҒеҸҲд»Һе“ӘйҮҢејҖе§ӢиҝҗиЎҢгҖҒд№ҹе°ұжҳҜиҜҙпјҢйңҖиҰҒзі»з»ҹдәӢе…Ҳз»ҷд»–и®ҫзҪ®еҘҪ CPU еҜ„еӯҳеҷЁе’ҢзЁӢеәҸи®Ўж•°еҷЁ(Program CounterпјҢ PC)
CPU еҜ„еӯҳеҷЁпјҡжҳҜ CPU еҶ…зҪ®зҡ„е®№йҮҸе°ҸгҖҒдҪҶйҖҹеәҰжһҒеҝ«зҡ„еҶ…еӯҳгҖӮ
зЁӢеәҸи®Ўж•°еҷЁпјҡжҳҜз”ЁжқҘеӯҳеӮЁ CPU жӯЈеңЁжү§иЎҢзҡ„жҢҮд»ӨдҪҚзҪ®гҖҒжҲ–иҖ…еҚіе°Ҷжү§иЎҢзҡ„дёӢдёҖжқЎжҢҮд»ӨдҪҚзҪ®гҖӮ
е®ғ们йғҪжҳҜ CPU еңЁиҝҗиЎҢд»»дҪ•д»»еҠЎеүҚпјҢжҜ”еҰӮзҡ„дҫқиө–зҺҜеўғпјҢеӣ жӯӨд№ҹиў«еҸ«еҒҡ CPU дёҠдёӢж–ҮгҖӮ
дёҠдёӢж–ҮеҲҮжҚўпјҡе°ұжҳҜе…ҲжҠҠеүҚдёҖдёӘд»»еҠЎзҡ„ CPU дёҠдёӢж–Ү(д№ҹе°ұжҳҜ CPU еҜ„еӯҳеҷЁе’ҢзЁӢеәҸи®Ўж•°еҷЁ)дҝқеӯҳиө·жқҘпјҢ然еҗҺеҠ иҪҪж–°д»»еҠЎзҡ„дёҠдёӢж–ҮеҲ°иҝҷдәӣеҜ„еӯҳеҷЁе’ҢзЁӢеәҸи®Ўж•°еҷЁпјҢжңҖеҗҺеҶҚи·іиҪ¬еҲ°зЁӢеәҸи®Ўж•°еҷЁжүҖжҢҮзҡ„ж–°дҪҚзҪ®пјҢиҝҗиЎҢж–°д»»еҠЎгҖӮ
CPU зҡ„дёҠдёӢж–ҮеҲҮжҚўеҸҜд»ҘеҲҶдёәиҝӣзЁӢдёҠдёӢж–ҮеҲҮжҚўгҖҒзәҝзЁӢдёҠдёӢж–ҮеҲҮжҚўд»ҘеҸҠдёӯж–ӯдёҠдёӢж–ҮеҲҮжҚўгҖӮ
1.3.1. иҝӣзЁӢдёҠдёӢж–ҮеҲҮжҚў
Linux жҢүз…§зү№жқғзӯүзә§пјҢжҠҠиҝӣзЁӢзҡ„иҝҗиЎҢз©әй—ҙеҲҶдёәеҶ…ж ёз©әй—ҙе’Ңз”ЁжҲ·з©әй—ҙ
еҶ…ж ёз©әй—ҙ(Ring 0)е…·жңүжңҖй«ҳжқғйҷҗпјҢеҸҜд»ҘзӣҙжҺҘи®ҝй—®жүҖжңүиө„жәҗгҖӮ
з”ЁжҲ·з©әй—ҙ(Ring 3)еҸӘиғҪи®ҝй—®еҸ—йҷҗиө„жәҗпјҢдёҚиғҪзӣҙжҺҘи®ҝй—®еҶ…еӯҳзӯү硬件и®ҫеӨҮпјҢеҝ…йЎ»йҖҡиҝҮзі»з»ҹи°ғз”Ёйҷ·е…ҘеҲ°еҶ…ж ёдёӯпјҢжүҚиғҪи®ҝй—®иҝҷдәӣзү№жқғиө„жәҗгҖӮ
1.3.2. иҝӣзЁӢдёҠдёӢж–ҮеҲҮжҚўе’Ңзі»з»ҹи°ғз”Ёзҡ„еҢәеҲ«
иҝӣзЁӢжҳҜз”ұеҶ…ж ёжқҘз®ЎзҗҶе’Ңи°ғеәҰзҡ„пјҢиҝӣзЁӢзҡ„еҲҮжҚўеҸӘиғҪеҸ‘з”ҹеңЁеҶ…ж ёжҖҒгҖӮжүҖд»ҘпјҢиҝӣзЁӢзҡ„дёҠдёӢж–ҮдёҚд»…еҢ…жӢ¬дәҶиҷҡжӢҹеҶ…еӯҳгҖҒж ҲгҖҒе…ЁеұҖеҸҳйҮҸзӯүз”ЁжҲ·з©әй—ҙзҡ„иө„жәҗпјҢиҝҳеҢ…жӢ¬дәҶеҶ…ж ёе Ҷж ҲгҖҒеҜ„еӯҳеҷЁзӯүеҶ…ж ёз©әй—ҙзҡ„зҠ¶жҖҒгҖӮ
зі»з»ҹи°ғз”ЁиҝҮзЁӢдёӯпјҢ并дёҚж¶үеҸҠеҲ°иҷҡжӢҹеҶ…еӯҳзӯүиҝӣзЁӢз”ЁжҲ·жҖҒзҡ„иө„жәҗпјҢд№ҹдёҚдјҡеҲҮжҚўиҝӣзЁӢгҖӮ
иҝӣзЁӢдёҠдёӢж–ҮеҲҮжҚўпјҢжҳҜжҢҮд»ҺдёҖдёӘиҝӣзЁӢеҲҮжҚўеҲ°еҸҰдёҖдёӘиҝӣзЁӢиҝӣиЎҢгҖӮ
зі»з»ҹи°ғз”ЁиҝҮзЁӢдёӯдёҖзӣҙжҳҜеҗҢдёҖдёӘиҝӣзЁӢеңЁиҝҗиЎҢгҖӮ
еӣ жӯӨпјҢиҝӣзЁӢзҡ„дёҠдёӢж–ҮеҲҮжҚўжҜ”зі»з»ҹи°ғз”Ёж—¶еӨҡдәҶдёҖжӯҘпјҡеңЁдҝқеӯҳеҪ“еүҚиҝӣзЁӢзҡ„еҶ…ж ёзҠ¶жҖҒе’Ң CPU еҜ„еӯҳеҷЁд№ӢеүҚпјҢйңҖиҰҒе…ҲжҠҠиҜҘиҝӣзЁӢзҡ„иҷҡжӢҹеҶ…еӯҳгҖҒж ҲзӯүдҝқеӯҳдёӢжқҘ;иҖҢеҠ иҪҪдәҶдёӢдёҖдёӘиҝӣзЁӢзҡ„еҶ…ж ёжҖҒеҗҺпјҢиҝҳйңҖиҰҒеҲ·ж–°иҝӣзЁӢзҡ„иҷҡжӢҹеҶ…еӯҳе’Ңз”ЁжҲ·ж ҲгҖӮ
1.3.3. д»Җд№Ҳж—¶еҖҷдјҡеҲҮжҚўиҝӣзЁӢдёҠж–Ү
иҝӣзЁӢжү§иЎҢз»ҲжӯўпјҢе®ғд№ӢеүҚдҪҝз”Ёзҡ„ CPU дјҡйҮҠж”ҫеҮәжқҘпјҢиҝҷж—¶еҶҚд»Һе°ұз»ӘйҳҹеҲ—йҮҢпјҢжӢҝдёҖдёӘж–°зҡ„иҝӣзЁӢиҝҮжқҘиҝҗиЎҢгҖӮ
еҪ“жҹҗдёӘиҝӣзЁӢзҡ„ж—¶й—ҙзүҮиҖ—е°ҪдәҶпјҢе°ұдјҡиў«зі»з»ҹжҢӮиө·пјҢеҲҮжҚўеҲ°е…¶д»–жӯЈеңЁзӯүеҫ… CPU зҡ„иҝӣзЁӢиҝӣиЎҢ
иҝӣзЁӢеңЁзі»з»ҹиө„жәҗдёҚи¶і(жҜ”еҰӮеҶ…еӯҳдёҚи¶і)ж—¶пјҢзӯүеҲ°иө„жәҗж»Ўи¶іеҗҺжүҚеҸҜд»ҘиҝҗиЎҢпјҢиҝҷдёӘж—¶еҖҷиҝӣзЁӢд№ҹдјҡиў«жҢӮиө·пјҢ并з”ұзі»з»ҹи°ғеәҰе…¶д»–иҝӣзЁӢиҝҗиЎҢгҖӮ
еҪ“иҝӣзЁӢйҖҡиҝҮзқЎзң еҮҪж•° sleep иҝҷж ·зҡ„ж–№жі•е°ҶиҮӘе·ұдё»еҠЁжҢӮиө·ж—¶пјҢиҮӘ然д№ҹдјҡйҮҚж–°и°ғеәҰгҖӮ
еҪ“жңүдјҳе…Ҳзә§жӣҙй«ҳзҡ„иҝӣзЁӢиҝҗиЎҢж—¶пјҢдёәдәҶдҝқиҜҒй«ҳдјҳе…Ҳзә§иҝӣзЁӢзҡ„иҝҗиЎҢпјҢеҪ“еүҚиҝӣзЁӢдјҡиў«жҢӮиө·пјҢз”ұй«ҳдјҳе…Ҳзә§иҝӣзЁӢжқҘиҝҗиЎҢгҖӮ
еҸ‘з”ҹ硬件дёӯж–ӯж—¶пјҢCPU дёҠзҡ„иҝӣзЁӢдјҡиў«дёӯж–ӯжҢӮиө·пјҢиҪ¬иҖҢжү§иЎҢеҶ…ж ёдёӯзҡ„дёӯж–ӯзЁӢеәҸжңҚеҠЎгҖӮ
1.3.4. зәҝзЁӢдёҠдёӢж–ҮеҲҮжҚў
зәҝзЁӢе’ҢиҝӣзЁӢзҡ„еҢәеҲ«
зәҝзЁӢжҳҜи°ғеәҰзҡ„еҹәжң¬еҚ•дҪҚпјҢиҖҢиҝӣзЁӢеҲҷжҳҜиө„жәҗжӢҘжңүзҡ„еҹәжң¬еҚ•дҪҚгҖӮ
еҪ“иҝӣзЁӢеҸӘжңүдёҖдёӘзәҝзЁӢж—¶пјҢеҸҜд»Ҙи®ӨдёәиҝӣзЁӢе°ұзӯүдәҺзәҝзЁӢгҖӮ
еҪ“иҝӣзЁӢжӢҘжңүеӨҡдёӘзәҝзЁӢж—¶пјҢиҝҷдәӣзәҝзЁӢдјҡе…ұдә«зӣёеҗҢзҡ„иҷҡжӢҹеҶ…еӯҳе’Ңе…ЁеұҖеҸҳйҮҸзӯүиө„жәҗгҖӮиҝҷдәӣиө„жәҗеңЁдёҠдёӢж–ҮеҲҮжҚўж—¶жҳҜдёҚйңҖиҰҒдҝ®ж”№зҡ„гҖӮ
зәҝзЁӢд№ҹжңүиҮӘе·ұзҡ„з§Ғжңүж•°жҚ®пјҢжҜ”еҰӮж Ҳе’ҢеҜ„еӯҳеҷЁзӯүпјҢиҝҷдәӣеңЁдёҠдёӢж–ҮеҲҮжҚўж—¶д№ҹжҳҜйңҖиҰҒдҝқеӯҳзҡ„гҖӮ
зәҝзЁӢзҡ„дёҠдёӢж–ҮеҲҮжҚўдёӨз§Қжғ…еҶө
еүҚеҗҺдёӨдёӘзәҝзЁӢеұһдәҺдёҚеҗҢиҝӣзЁӢгҖӮжӯӨж—¶пјҢеӣ дёәиө„жәҗдёҚе…ұдә«пјҢжүҖд»ҘеҲҮжҚўиҝҮзЁӢе°ұи·ҹиҝӣзЁӢдёҠдёӢж–ҮеҲҮжҚўжҳҜдёҖж ·зҡ„гҖӮ
еүҚеҗҺдёӨдёӘзәҝзЁӢеұһдәҺеҗҢдёҖдёӘиҝӣзЁӢгҖӮжӯӨж—¶пјҢеӣ дёәиҷҡжӢҹеҶ…еӯҳжҳҜе…ұдә«зҡ„пјҢжүҖд»ҘеңЁеҲҮжҚўж—¶пјҢиҷҡжӢҹеҶ…еӯҳиҝҷдәӣиө„жәҗе°ұдҝқжҢҒдёҚеҠЁпјҢеҸӘйңҖиҰҒеҲҮжҚўзәҝзЁӢзҡ„з§Ғжңүж•°жҚ®гҖҒеҜ„еӯҳеҷЁзӯүдёҚе…ұдә«зҡ„ж•°жҚ®гҖӮ
1.3.5. дёӯж–ӯдёҠдёӢж–ҮеҲҮжҚў
дёӯж–ӯеӨ„зҗҶдјҡжү“ж–ӯиҝӣзЁӢзҡ„жӯЈеёёи°ғеәҰе’Ңжү§иЎҢгҖӮеңЁжү“ж–ӯе…¶д»–иҝӣзЁӢж—¶пјҢйңҖиҰҒе°ҶиҝӣзЁӢеҪ“еүҚзҡ„зҠ¶жҖҒдҝқеӯҳдёӢжқҘпјҢдёӯж–ӯз»“жқҹеҗҺпјҢиҝӣзЁӢд»Қ然еҸҜд»Ҙд»ҺеҺҹжқҘзҡ„зҠ¶жҖҒжҒўеӨҚиҝҗиЎҢгҖӮ
иҝӣзЁӢдёҠдёӢж–ҮеҲҮжҚўе’Ңдёӯж–ӯдёҠдёӢж–ҮеҲҮжҚўзҡ„еҢәеҲ«
дёӯж–ӯдёҠдёӢж–ҮеҲҮжҚўе№¶дёҚж¶үеҸҠеҲ°иҝӣзЁӢзҡ„з”ЁжҲ·жҖҒгҖӮжүҖд»ҘпјҢеҚідҫҝдёӯж–ӯиҝҮзЁӢжү“ж–ӯдәҶдёҖдёӘжӯЈеӨ„еңЁз”ЁжҲ·жҖҒзҡ„иҝӣзЁӢпјҢд№ҹдёҚйңҖиҰҒдҝқеӯҳе’ҢжҒўеӨҚиҝҷдёӘиҝӣзЁӢзҡ„иҷҡжӢҹеҶ…еӯҳгҖҒе…ЁеұҖеҸҳйҮҸзӯүз”ЁжҲ·жҖҒиө„жәҗгҖӮдёӯж–ӯдёҠдёӢж–ҮпјҢе…¶е®һеҸӘеҢ…жӢ¬еҶ…ж ёжҖҒдёӯж–ӯжңҚеҠЎзЁӢеәҸжү§иЎҢжүҖеҝ…йЎ»зҡ„зҠ¶жҖҒпјҢеҢ…жӢ¬ CPU еҜ„еӯҳеҷЁгҖҒеҶ…ж ёе Ҷж ҲгҖҒ硬件дёӯж–ӯеҸӮж•°зӯүгҖӮ
еҜ№еҗҢдёҖдёӘ CPU жқҘиҜҙпјҢдёӯж–ӯеӨ„зҗҶжҜ”иҝӣзЁӢжӢҘжңүжӣҙй«ҳзҡ„дјҳе…Ҳзә§гҖӮ
иҝӣзЁӢдёҠдёӢж–ҮеҲҮжҚўе’Ңдёӯж–ӯдёҠж–ҮеҲҮжҚўзҡ„зӣёеҗҢд№ӢеӨ„
йғҪйңҖиҰҒж¶ҲиҖ— CPUпјҢеҲҮжҚўж¬Ўж•°иҝҮеӨҡдјҡиҖ—иҙ№еӨ§йҮҸ CPUпјҢз”ҡиҮідёҘйҮҚйҷҚдҪҺзі»з»ҹзҡ„ж•ҙдҪ“жҖ§иғҪгҖӮ
1.3.6. CPU дёҠдёӢж–ҮеҲҮжҚўе°Ҹз»“
CPU дёҠдёӢж–ҮеҲҮжҚўпјҢжҳҜдҝқиҜҒ Linux зі»з»ҹжӯЈеёёе·ҘдҪңзҡ„ж ёеҝғеҠҹиғҪд№ӢдёҖпјҢдёҖиҲ¬жғ…еҶөдёӢдёҚйңҖиҰҒжҲ‘们зү№еҲ«е…іжіЁгҖӮ
дҪҶиҝҮеӨҡзҡ„дёҠдёӢж–ҮеҲҮжҚўпјҢдјҡжҠҠ CPU ж—¶й—ҙж¶ҲиҖ—еңЁеҜ„еӯҳеҷЁгҖҒеҶ…ж ёж Ҳд»ҘеҸҠиҷҡжӢҹеҶ…еӯҳзӯүж•°жҚ®зҡ„дҝқеӯҳе’ҢжҒўеӨҚдёҠпјҢд»ҺиҖҢзј©зҹӯиҝӣзЁӢзңҹжӯЈиҝҗиЎҢзҡ„ж—¶й—ҙпјҢеҜјиҮҙзі»з»ҹзҡ„ж•ҙдҪ“жҖ§иғҪеӨ§е№…дёӢйҷҚ
1.3.7. еҰӮдҪ•жҹҘзңӢзі»з»ҹзҡ„дёҠдёӢж–ҮеҲҮжҚў
еёёз”Ёзҡ„зі»з»ҹжҖ§иғҪеҲҶжһҗе·Ҙе…·пјҢдё»иҰҒз”ЁжқҘеҲҶжһҗзі»з»ҹзҡ„еҶ…еӯҳдҪҝз”Ёжғ…еҶөпјҢд№ҹеёёз”ЁжқҘеҲҶжһҗ
CPU дёҠдёӢж–ҮеҲҮжҚўе’Ңдёӯж–ӯж¬Ўж•°гҖӮ
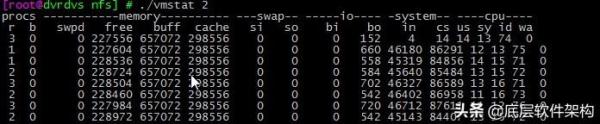
Figure 2 жҜҸйҡ” 2 з§’иҫ“еҮәдёҖз»„ж•°жҚ®
йңҖиҰҒзү№еҲ«е…іжіЁзҡ„еӣӣеҲ—еҶ…е®№пјҡ
cs (context switch)пјҡжҜҸз§’дёҠдёӢж–ҮеҲҮжҚўзҡ„ж¬Ўж•°гҖӮ
in (interrupt)пјҡжҜҸз§’дёӯж–ӯзҡ„ж¬Ўж•°гҖӮ
r (Running or Runnable) пјҡе°ұз»ӘйҳҹеҲ—зҡ„й•ҝеәҰпјҢд№ҹе°ұжҳҜжӯЈеңЁиҝҗиЎҢе’Ңзӯүеҫ… CPU зҡ„иҝӣзЁӢж•°гҖӮ
b (Blocked)пјҡеӨ„еңЁдёҚеҸҜдёӯж–ӯзқЎзң зҠ¶жҖҒзҡ„иҝӣзЁӢж•°гҖӮ
еңЁеөҢе…ҘејҸ Linux и®ҫеӨҮдёӯпјҢдёҖиҲ¬ vmstat е·Ҙе…·жҳҜдёҚеӯҳеңЁзҡ„гҖӮжүҖд»ҘеҰӮжһңжғіиҰҒ vmstat е·Ҙе…·пјҢеҸҜд»ҘиҮӘе·ұе®һзҺ°д»Јз ҒпјҢд»–зҡ„еҺҹзҗҶжҳҜиҺ·еҸ–/proc/diskstats е’Ң/proc/slabinfo зҡ„дҝЎжҒҜз»„еҗҲиҖҢжҲҗгҖӮе®һзҺ°д»Јз Ғи§Ғ procps е·Ҙе…·
vmstat еҸӘз»ҷеҮәдәҶзі»з»ҹжҖ»дҪ“зҡ„дёҠдёӢж–ҮеҲҮжҚўжғ…еҶөпјҢ并дёҚиғҪжҹҘзңӢжҜҸдёӘиҝӣзЁӢзҡ„дёҠдёӢж–ҮеҲҮжҚўжғ…еҶөгҖӮ
пјҡжҹҘзңӢжҹҗдёӘиҝӣзЁӢдёӯзәҝзЁӢзҡ„дёҠдёӢж–ҮеҲҮжҚўжғ…еҶөпјҢдёӢеӣҫжҹҘзңӢзҡ„жҳҜ hicore иҝӣзЁӢдёӯжүҖжңүзҡ„зәҝзЁӢдёҠдёӢж–ҮеҲҮжҚўжғ…еҶөгҖӮ
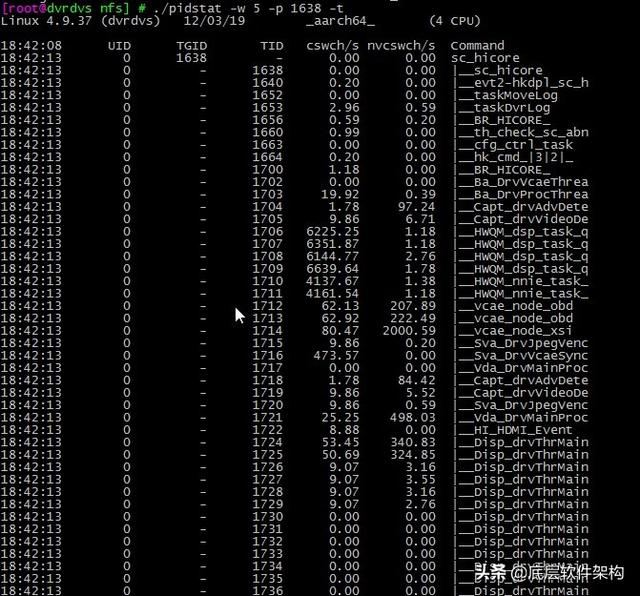
е…іжіЁдёӨеҲ—еҶ…е®№пјҡ
1. иҮӘж„ҝдёҠдёӢж–ҮеҲҮжҚўпјҡиҝӣзЁӢж— жі•иҺ·еҸ–жүҖйңҖиө„жәҗпјҢеҜјиҮҙзҡ„дёҠдёӢж–ҮеҲҮжҚўгҖӮжҜ”еҰӮпјҢ I/OгҖҒеҶ…еӯҳзӯүзі»з»ҹиө„жәҗдёҚи¶іж—¶гҖӮ
2. йқһиҮӘж„ҝдёҠдёӢж–ҮеҲҮжҚўпјҡиҝӣзЁӢз”ұдәҺж—¶й—ҙзүҮе·ІеҲ°зӯүеҺҹеӣ пјҢиў«зі»з»ҹејәеҲ¶и°ғеәҰпјҢиҝӣиҖҢеҸ‘з”ҹзҡ„дёҠдёӢж–ҮеҲҮжҚўгҖӮжҜ”еҰӮпјҢеӨ§йҮҸиҝӣзЁӢйғҪеңЁдәүжҠў CPU ж—¶гҖӮ
1.3.9. Procps е·Ҙе…·
procps жҳҜдёҖз»„е‘Ҫд»ӨиЎҢе’Ңе…ЁеұҸе·Ҙе…·пјҢжҳҜз”ұеҶ…ж ёеҠЁжҖҒз”ҹжҲҗзҡ„дёҖдёӘ "дјӘ" ж–Ү件系з»ҹпјҢеҸҜд»ҘжҸҗдҫӣиҝӣзЁӢиЎЁдёӯжқЎзӣ®зҠ¶жҖҒзҡ„дҝЎжҒҜгҖӮиҜҘж–Ү件系з»ҹдёәеҶ…ж ёж•°жҚ®з»“жһ„жҸҗдҫӣдәҶдёҖдёӘз®Җжҳ“жҺҘеҸЈпјҢprocps зЁӢеәҸйҖҡеёёе°ұйӣҶдёӯеңЁиҝҷдёӘжҸҸиҝ°дәҶзі»з»ҹиҝӣзЁӢиҝҗиЎҢзҠ¶жҖҒзҡ„ж•°жҚ®з»“жһ„дёҠгҖӮ
procps еҢ…жӢ¬д»ҘдёӢзЁӢеәҸпјҡ
free - жҠҘе‘Ҡзі»з»ҹдёӯеҸҜз”ЁеҶ…еӯҳе’Ңе·Із”ЁеҶ…еӯҳзҡ„ж•°йҮҸ
kill - еҹәдәҺ PIDпјҢеҗ‘иҝӣзЁӢеҸ‘йҖҒдҝЎеҸ·
pgrep - ж №жҚ®еҗҚз§°жҲ–е…¶д»–еұһжҖ§еҲ—еҮәиҝӣзЁӢ
pkill - ж №жҚ®еҗҚз§°жҲ–е…¶д»–еұһжҖ§еҗ‘иҝӣзЁӢеҸ‘йҖҒдҝЎеҸ·
pmap - жҠҘе‘ҠиҝӣзЁӢзҡ„еҶ…еӯҳжҳ е°„
ps - жҠҘе‘ҠиҝӣзЁӢдҝЎжҒҜ
pwdx - жҠҘе‘ҠиҝӣзЁӢзҡ„еҪ“еүҚзӣ®еҪ•
skill - pgrep/pkill зҡ„иҝҮж—¶зүҲжң¬
slabtop - е®һж—¶жҳҫзӨәеҶ…ж ё slab зј“еӯҳдҝЎжҒҜ
snice - Renice дёҖдёӘиҝӣзЁӢ
sysctl -иҝҗиЎҢж—¶еҶ…ж ёеҸӮж•°зҡ„иҜ»жҲ–еҶҷ
tload - зі»з»ҹиҙҹиҪҪеқҮеҖјзҡ„еҸҜи§ҶеҢ–
top - жӯЈиҝҗиЎҢиҝӣзЁӢзҡ„е®һж—¶еҠЁжҖҒи§Ҷеӣҫ
uptime - жҳҫзӨәзі»з»ҹзҡ„е·ІиҝҗиЎҢж—¶й—ҙе’ҢиҙҹиҪҪжғ…еҶө
vmstat - жҠҘе‘ҠиҷҡжӢҹеҶ…еӯҳз»ҹи®ЎдҝЎжҒҜ
w - жҠҘе‘Ҡзҷ»еҪ•з”ЁжҲ·пјҢд»ҘеҸҠ他们жӯЈеңЁеҒҡд»Җд№Ҳ
watch - е®ҡжңҹжү§иЎҢзЁӢеәҸпјҢжҳҫзӨәе…ЁеұҸиҫ“еҮәе®ҳзҪ‘ең°еқҖпјҡhttp://procps.sourceforge.net/
1.3.10. sysstat е·Ҙе…·
еңЁеөҢе…ҘејҸ Linux и®ҫеӨҮдёӯеҗҢж ·д№ҹдёҚеӯҳеңЁиҜҘе·Ҙе…·пјҢbusybox дёӯд№ҹжІЎжңүзӣёе…іе‘Ҫд»ӨгҖӮйңҖиҰҒе®үиЈ… Linux жҖ§иғҪзӣ‘жҺ§е·Ҙе…· sysstatпјҢд»–жҳҜдёҖдёӘе·Ҙе…·йӣҶпјҢеҢ…жӢ¬ sarгҖҒsadfгҖҒmpstatгҖҒiostatгҖҒpidstat зӯүпјҢиҝҷдәӣе·Ҙе…·еҸҜд»Ҙзӣ‘жҺ§зі»з»ҹжҖ§иғҪе’ҢдҪҝз”Ёжғ…еҶөгҖӮеҗ„е·Ҙе…·зҡ„дҪңз”ЁеҰӮдёӢпјҡ
1. iostat - жҸҗдҫӣ CPU з»ҹи®ЎпјҢеӯҳеӮЁ I/O з»ҹи®Ў(зЈҒзӣҳи®ҫеӨҮпјҢеҲҶеҢәеҸҠзҪ‘з»ңж–Ү件系з»ҹ)
2. mpstat - жҸҗдҫӣеҚ•дёӘжҲ–з»„еҗҲ CPU зӣёе…із»ҹи®Ў
3. pidstat - жҸҗдҫӣ Linux иҝӣзЁӢзә§еҲ«з»ҹи®ЎпјҡI/OгҖҒCPUгҖҒеҶ…еӯҳзӯү
4. sar - 收йӣҶгҖҒжҠҘе‘ҠгҖҒдҝқеӯҳзі»з»ҹжҙ»еҠЁдҝЎжҒҜпјҡCPUгҖҒеҶ…еӯҳгҖҒзЈҒзӣҳгҖҒдёӯж–ӯгҖҒзҪ‘з»ңжҺҘеҸЈгҖҒTTYгҖҒеҶ…ж ёиЎЁзӯү
5. sadc - зі»з»ҹжҙ»еҠЁж•°жҚ®ж”¶йӣҶеҷЁпјҢдҪңдёә sar еҗҺз«ҜдҪҝз”Ё
6. sa1 - 收йӣҶзі»з»ҹжҙ»еҠЁж—Ҙеёёж•°жҚ®пјҢ并дәҢиҝӣеҲ¶ж јејҸеӯҳеӮЁпјҢе®ғдҪңдёә sadc зҡ„е·Ҙе…·зҡ„еүҚз«ҜпјҢеҸҜд»ҘйҖҡиҝҮ cron жқҘи°ғз”Ё
7. sa2 - з”ҹжҲҗзі»з»ҹжҜҸж—Ҙжҙ»еҠЁжҠҘе‘ҠпјҢеҗҢж ·еҸҜдҪңдёә sadc зҡ„е·Ҙе…·зҡ„еүҚз«ҜпјҢеҸҜд»ҘйҖҡиҝҮ cron жқҘи°ғз”Ё
8. sadf - еҸҜд»Ҙд»Ҙ CSVгҖҒXML ж јејҸзӯүжҳҫзӨә sar 收йӣҶзҡ„жҖ§иғҪж•°жҚ®пјҢиҝҷж ·йқһеёёж–№дҫҝзҡ„е°Ҷзі»з»ҹж•°жҚ®еҜје…ҘеҲ°ж•°жҚ®еә“дёӯпјҢжҲ–еҜје…ҘеҲ° Excel дёӯжқҘз”ҹжҲҗеӣҫиЎЁ
9. nfsiostat-sysstat: жҸҗдҫӣ NFS I/O з»ҹи®Ў
10. cifsiostat: жҸҗдҫӣ CIFS з»ҹи®Ў
sysstat еҠҹиғҪејәеӨ§пјҢеҠҹиғҪд№ҹеңЁдёҚж–ӯзҡ„еўһејәпјҢжҜҸдёӘзүҲжң¬жҸҗдҫӣдәҶдёҚеҗҢзҡ„еҠҹиғҪпјҢеҸҜд»ҘеҲ° sysstat е®ҳзҪ‘дәҶ и§Ј е·Ҙ е…· жңҖ е…Ҳ еҸ‘ еұ• жғ… еҶө е’Ң иҺ· еҫ— зӣё еә” зҡ„ её® еҠ© жүӢ еҶҢ гҖӮ е®ҳ зҪ‘ ең° еқҖ пјҡ
1.3.11. дёӯж–ӯ
дёӯж–ӯжҳҜдёҖз§ҚејӮжӯҘзҡ„дәӢ件еӨ„зҗҶжңәеҲ¶пјҢеҸҜд»ҘжҸҗй«ҳзі»з»ҹзҡ„并еҸ‘еӨ„зҗҶиғҪеҠӣгҖӮдёӯж–ӯеӨ„зҗҶзЁӢеәҸдјҡжү“ж–ӯе…¶д»–иҝӣзЁӢзҡ„иҝҗиЎҢпјҢдёәдәҶеҮҸе°‘еҜ№жӯЈеёёиҝӣзЁӢиҝҗиЎҢи°ғеәҰзҡ„еҪұе“ҚпјҢдёӯж–ӯеӨ„зҗҶзЁӢеәҸе°ұйңҖиҰҒе°ҪеҸҜиғҪеҝ«ең°иҝҗиЎҢгҖӮ
Linux е°Ҷдёӯж–ӯеӨ„зҗҶиҝҮзЁӢеҲҶжҲҗдәҶдёӨдёӘйҳ¶ж®өпјҢд№ҹе°ұжҳҜдёҠеҚҠйғЁе’ҢдёӢеҚҠйғЁгҖӮ
· дёҠеҚҠйғЁз”ЁжқҘеҝ«йҖҹеӨ„зҗҶдёӯж–ӯпјҢе®ғеңЁдёӯж–ӯзҰҒжӯўжЁЎејҸдёӢиҝҗиЎҢпјҢдё»иҰҒеӨ„зҗҶи·ҹ硬件зҙ§еҜҶзӣёе…ізҡ„жҲ–ж—¶й—ҙж•Ҹж„ҹзҡ„е·ҘдҪңгҖӮ
· дёӢеҚҠйғЁз”ЁжқҘ延时еӨ„зҗҶдёҠеҚҠйғЁжңӘе®ҢжҲҗзҡ„е·ҘдҪңпјҢйҖҡеёёд»ҘеҶ…ж ёзәҝзЁӢзҡ„ж–№ејҸиҝҗиЎҢгҖӮ
/proc/interruptsпјҡжҹҘзңӢзЎ¬дёӯж–ӯеҸ‘з”ҹзҡ„зұ»еһӢ
硬件дёӯж–ӯеҸ‘з”ҹйў‘з№ҒпјҢжҳҜ件еҫҲж¶ҲиҖ— CPU иө„жәҗзҡ„дәӢжғ…пјҢLinux й»ҳи®Өжғ…еҶөдёӢжҳҜе°ҶжүҖжңүзҡ„硬件дёӯж–ӯйғҪз»‘е®ҡеңЁ CPU0 дёҠпјҢеңЁеӨҡж ё CPU жқЎд»¶дёӢеҰӮжһңжңүеҠһжі•жҠҠеӨ§йҮҸ硬件дёӯж–ӯеҲҶй…Қз»ҷдёҚеҗҢзҡ„
CPU (core) еӨ„зҗҶжҳҫ然иғҪеҫҲеҘҪзҡ„е№іиЎЎжҖ§иғҪгҖӮ
1.3.13. ж №жҚ®дёҠдёӢж–ҮеҲҮжҚўзҡ„зұ»еһӢеҒҡе…·дҪ“еҲҶжһҗ
· иҮӘж„ҝдёҠдёӢж–ҮеҲҮжҚўеҸҳеӨҡпјҢиҜҙжҳҺиҝӣзЁӢйғҪеңЁзӯүеҫ…иө„жәҗпјҢжңүеҸҜиғҪеҸ‘з”ҹ I/O зӯүе…¶д»–й—®йўҳ
· йқһиҮӘж„ҝдёҠдёӢж–ҮеҲҮжҚўеҸҳеӨҡпјҢиҜҙжҳҺиҝӣзЁӢйғҪеңЁиў«ејәеҲ¶и°ғеәҰпјҢд№ҹе°ұжҳҜйғҪеңЁдәүжҠў CPUпјҢиҜҙжҳҺ CPU зҡ„зЎ®жҲҗдәҶ瓶йўҲ
· дёӯж–ӯж¬Ўж•°еҸҳеӨҡпјҢиҜҙжҳҺ CPU иў«дёӯж–ӯеӨ„зҗҶзЁӢеәҸеҚ з”ЁпјҢиҝҳйңҖиҰҒйҖҡиҝҮжҹҘзңӢ /proc/interrupts ж–Ү件жқҘеҲҶжһҗе…·дҪ“зҡ„дёӯж–ӯзұ»еһӢгҖӮ
1.4. CPU дҪҝз”ЁзҺҮ
/proc/statпјҢжҸҗдҫӣзҡ„жҳҜзі»з»ҹзҡ„ CPU е’Ңд»»еҠЎз»ҹи®ЎдҝЎжҒҜгҖӮиҝҷдёӘдҝЎжҒҜйқһеёёзҡ„еҺҹе§Ӣ

CPU дҪҝз”ЁзҺҮзӣёе…ізҡ„йҮҚиҰҒжҢҮж Ү
第дёҖеҲ—пјҡuser(us)пјҢд»ЈиЎЁз”ЁжҲ·жҖҒ CPU ж—¶й—ҙгҖӮ
第дәҢеҲ—пјҡnice(ni)пјҢд»ЈиЎЁдҪҺдјҳе…Ҳзә§з”ЁжҲ·жҖҒ CPU ж—¶й—ҙпјҢд№ҹе°ұжҳҜиҝӣзЁӢзҡ„ nice еҖјиў«и°ғж•ҙдёә 1-
19 д№Ӣй—ҙж—¶зҡ„ CPU ж—¶й—ҙгҖӮnice еҸҜеҸ–еҖјиҢғеӣҙжҳҜ -20 еҲ° 19пјҢ ж•°еҖји¶ҠеӨ§пјҢдјҳе…Ҳзә§еҸҚиҖҢи¶ҠдҪҺ
第дёүеҲ—пјҡsystem (sys)пјҢд»ЈиЎЁеҶ…ж ёжҖҒ CPU ж—¶й—ҙгҖӮ
第еӣӣеҲ—пјҡidle(us)пјҢд»ЈиЎЁз©әй—Іж—¶й—ҙгҖӮжіЁж„ҸпјҢиҝҷйҮҢе®ғдёҚеҢ…жӢ¬зӯүеҫ… I/O зҡ„ж—¶й—ҙ(iowait)гҖӮ
第дә”еҲ—пјҡiowait(wa)пјҢд»ЈиЎЁзӯүеҫ… I/O зҡ„ CPU ж—¶й—ҙгҖӮ
第е…ӯеҲ—пјҡirq(hi)пјҢд»ЈиЎЁеӨ„зҗҶзЎ¬дёӯж–ӯзҡ„ CPU ж—¶й—ҙ
第дёғеҲ—пјҡsoftirq(si)пјҢд»ЈиЎЁеӨ„зҗҶиҪҜдёӯж–ӯзҡ„ CPU ж—¶й—ҙгҖӮ
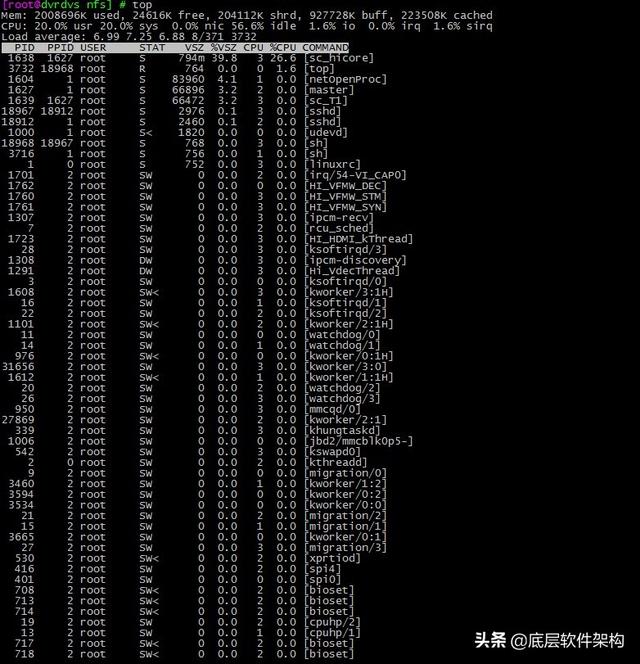
зңҹжӯЈжҹҘзңӢ CPU дҪҝз”ЁзҺҮзҡ„е‘Ҫд»ӨжҳҜйҖҡиҝҮ top е‘Ҫд»Ө
1.5. иҪҜдёӯж–ӯ
жҸҗдҫӣдәҶиҪҜдёӯж–ӯзҡ„иҝҗиЎҢжғ…еҶөгҖӮ
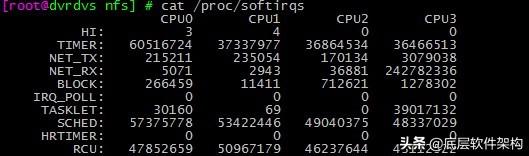
жіЁж„ҸиҪҜдёӯж–ӯзҡ„зұ»еһӢпјҢд№ҹе°ұжҳҜ第дёҖеҲ—еҶ…е®№гҖӮ
жіЁж„ҸеҗҢдёҖз§ҚиҪҜдёӯж–ӯеңЁдёҚеҗҢ CPU дёҠзҡ„еҲҶеёғжғ…еҶөпјҢд№ҹе°ұжҳҜеҗҢдёҖиЎҢеҶ…е®№гҖӮ
иҪҜдёӯж–ӯе®һйҷ…дёҠжҳҜд»ҘеҶ…ж ёзәҝзЁӢзҡ„ж–№ејҸиҝҗиЎҢзҡ„пјҢжҜҸдёӘ CPU йғҪеҜ№еә”дёҖдёӘиҪҜдёӯж–ӯеҶ…ж ёзәҝзЁӢпјҢиҝҷдёӘиҪҜдёӯж–ӯеҶ…ж ёзәҝзЁӢе°ұеҸ«еҒҡ ksoftirqd/CPU зј–еҸ·

2. дјҳеҢ–ж–№жі•
2.1 CPU дҪҝз”ЁзҺҮ
CPU дҪҝз”ЁзҺҮжҸҸиҝ°дәҶйқһз©әй—Іж—¶й—ҙеҚ жҖ» CPU ж—¶й—ҙзҡ„зҷҫеҲҶжҜ”пјҢж №жҚ® CPU дёҠиҝҗиЎҢд»»еҠЎзҡ„дёҚеҗҢпјҢеҸҲиў«еҲҶдёәз”ЁжҲ· CPUгҖҒзі»з»ҹ CPUгҖҒзӯүеҫ… I/O CPUгҖҒиҪҜдёӯж–ӯе’ҢзЎ¬дёӯж–ӯзӯүгҖӮ
з”ЁжҲ· CPU дҪҝз”ЁзҺҮпјҢеҢ…жӢ¬з”ЁжҲ·жҖҒ CPU дҪҝз”ЁзҺҮ(user) е’ҢдҪҺдјҳе…Ҳзә§з”ЁжҲ·жҖҒ CPU дҪҝз”ЁзҺҮ (nice)пјҢиЎЁзӨә CPU еңЁз”ЁжҲ·жҖҒиҝҗиЎҢзҡ„ж—¶й—ҙзҷҫеҲҶжҜ”гҖӮз”ЁжҲ· CPU дҪҝз”ЁзҺҮй«ҳпјҢйҖҡеёёиҜҙжҳҺжңүеә”з”ЁзЁӢеәҸжҜ”иҫғз№ҒеҝҷгҖӮ
зі»з»ҹ CPU дҪҝз”ЁзҺҮпјҢиЎЁзӨә CPU еңЁеҶ…ж ёжҖҒиҝҗиЎҢзҡ„ж—¶й—ҙзҷҫеҲҶжҜ”(дёҚеҢ…жӢ¬дёӯж–ӯ)гҖӮзі»з»ҹ CPU дҪҝз”ЁзҺҮй«ҳпјҢиҜҙжҳҺеҶ…ж ёжҜ”иҫғз№ҒеҝҷгҖӮ
зӯүеҫ… I/O зҡ„ CPU дҪҝз”ЁзҺҮпјҢйҖҡеёёд№ҹз§°дёә iowaitпјҢиЎЁзӨәзӯүеҫ… I/O зҡ„ж—¶й—ҙзҷҫеҲҶжҜ”гҖӮiowait й«ҳпјҢйҖҡеёёиҜҙжҳҺзі»з»ҹдёҺ硬件и®ҫеӨҮзҡ„ I/O дәӨдә’ж—¶й—ҙжҜ”иҫғй•ҝгҖӮ
иҪҜдёӯж–ӯе’ҢзЎ¬дёӯж–ӯзҡ„ CPU дҪҝз”ЁзҺҮпјҢеҲҶеҲ«иЎЁзӨәеҶ…ж ёи°ғз”ЁиҪҜдёӯж–ӯеӨ„зҗҶзЁӢеәҸгҖҒзЎ¬дёӯж–ӯеӨ„зҗҶзЁӢеәҸзҡ„ж—¶й—ҙзҷҫеҲҶжҜ”гҖӮе®ғ们зҡ„дҪҝз”ЁзҺҮй«ҳпјҢйҖҡеёёиҜҙжҳҺзі»з»ҹеҸ‘з”ҹдәҶеӨ§йҮҸзҡ„дёӯж–ӯгҖӮ
2.2 е№іеқҮиҙҹиҪҪ(Load Average)
е№іеқҮиҙҹиҪҪпјҢд№ҹе°ұжҳҜзі»з»ҹзҡ„е№іеқҮжҙ»и·ғиҝӣзЁӢж•°пјҢе®ғеҸҚжҳ дәҶзі»з»ҹзҡ„ж•ҙдҪ“иҙҹиҪҪжғ…еҶөпјҢдё»иҰҒеҢ…жӢ¬дёүдёӘж•°еҖјпјҢеҲҶеҲ«жҢҮиҝҮеҺ» 1 еҲҶй’ҹгҖҒиҝҮеҺ» 5 еҲҶй’ҹе’ҢиҝҮеҺ» 15 еҲҶй’ҹзҡ„е№іеқҮеӨҚеҲ¶еӯҗгҖӮ
зҗҶжғіжғ…еҶөдёӢпјҢе№іеқҮиҙҹиҪҪзӯүдәҺйҖ»иҫ‘ CPU дёӘж•°пјҢиҝҷиЎЁзӨәжҜҸдёӘ CPU йғҪжҒ°еҘҪиў«е……еҲҶеҲ©з”ЁгҖӮеҰӮжһңе№іеқҮиҙҹиҪҪеӨ§дәҺйҖ»иҫ‘ CPU дёӘж•°пјҢе°ұиЎЁзӨәиҙҹиҪҪжҜ”иҫғйҮҚдәҶгҖӮ
2.3 иҝӣзЁӢдёҠдёӢж–ҮеҲҮжҚў
ж— жі•иҺ·еҸ–иө„жәҗиҖҢеҜјиҮҙзҡ„иҮӘж„ҝдёҠдёӢж–ҮеҲҮжҚўгҖӮ
иў«зі»з»ҹејәеҲ¶и°ғеәҰеҜјиҮҙзҡ„йқһиҮӘж„ҝдёҠдёӢж–ҮеҲҮжҚўгҖӮ
2.4 CPU зј“еӯҳзҡ„е‘ҪдёӯзҺҮ
з”ұдәҺ CPU еҸ‘еұ•зҡ„йҖҹеәҰиҝңеҝ«дәҺеҶ…еӯҳзҡ„еҸ‘еұ•пјҢ CPU зҡ„еӨ„зҗҶйҖҹеәҰе°ұжҜ”еҶ…еӯҳзҡ„и®ҝй—®йҖҹеәҰеҝ«еҫ—еӨҡгҖӮиҝҷж ·пјҢCPU еңЁи®ҝй—®еҶ…еӯҳзҡ„ж—¶еҖҷпјҢе…ҚдёҚдәҶиҰҒзӯүеҫ…еҶ…еӯҳзҡ„е“Қеә”гҖӮдёәдәҶеҚҸи°ғиҝҷдёӨиҖ…е·ЁеӨ§зҡ„жҖ§иғҪе·®и·қпјҢCPU зј“еӯҳ(йҖҡеёёжҳҜеӨҡзә§зј“еӯҳ)е°ұеҮәзҺ°дәҶгҖӮ
ж №жҚ®дёҚж–ӯеўһй•ҝзҡ„зғӯзӮ№ж•°жҚ®пјҢиҝҷдәӣзј“еӯҳжҢүз…§еӨ§е°ҸдёҚеҗҢеҲҶдёә L1гҖҒL2гҖҒL3 зӯүдёүзә§зј“еӯҳпјҢе…¶дёӯ
L1 е’Ң L2 еёёз”ЁеңЁеҚ•ж ёдёӯпјҢL3 еҲҷз”ЁеңЁеӨҡж ёдёӯгҖӮ
д»Һ L1 еҲ° L3пјҢдёүзә§зј“еӯҳзҡ„еӨ§е°Ҹдҫқж¬ЎеўһеӨ§пјҢзӣёеә”зҡ„пјҢжҖ§иғҪдҫқж¬ЎйҷҚдҪҺ(еҪ“然жҜ”еҶ…еӯҳиҝҳжҳҜеҘҪ
еҫ—еӨҡ)гҖӮиҖҢе®ғ们зҡ„е‘ҪдёӯзҺҮпјҢиЎЎйҮҸзҡ„жҳҜ CPU зј“еӯҳзҡ„еӨҚз”Ёжғ…еҶөпјҢе‘ҪдёӯзҺҮи¶Ҡй«ҳпјҢеҲҷиЎЁзӨәжҖ§иғҪи¶ҠеҘҪгҖӮ
2.5 tcmalloc жӣҝжҚў ptmalloc
2.5.1 ptmalloc
Ptmalloc йҮҮз”Ёдё»-д»ҺеҲҶй…ҚеҢәзҡ„жЁЎејҸпјҢеҪ“дёҖдёӘзәҝзЁӢйңҖиҰҒеҲҶй…Қиө„жәҗзҡ„ж—¶еҖҷпјҢд»Һй“ҫиЎЁдёӯжүҫеҲ°дёҖдёӘжІЎеҠ й”Ғзҡ„еҲҶй…ҚеҢәпјҢеңЁиҝӣиЎҢеҶ…еӯҳеҲҶй…ҚгҖӮ
е°ҸеҶ…еӯҳеҲҶй…Қ
еңЁ ptmalloc еҶ…йғЁпјҢеҶ…еӯҳеқ—йҮҮз”Ё chunk з®ЎзҗҶпјҢ并且е°ҶеӨ§е°Ҹзӣёдјјзҡ„ chunk з”Ёй“ҫиЎЁз®ЎзҗҶпјҢдёҖдёӘй“ҫиЎЁиў«з§°дёәдёҖдёӘ binгҖӮеүҚ 64 дёӘ bin йҮҢпјҢзӣёйӮ»зҡ„ bin еҶ…зҡ„ chunk еӨ§е°Ҹзӣёе·® 8 еӯ—иҠӮпјҢз§°дёә small binпјҢеҗҺйқўзҡ„жҳҜ large binпјҢlarge bin йҮҢзҡ„ chunk жҢүе…ҲеӨ§е°ҸпјҢеҶҚжңҖиҝ‘дҪҝз”Ёзҡ„йЎәеәҸжҺ’еҲ—пјҢжҜҸж¬ЎеҲҶй…ҚйғҪжүҫдёҖдёӘжңҖе°Ҹзҡ„иғҪеӨҹдҪҝз”Ёзҡ„ chunkгҖӮ
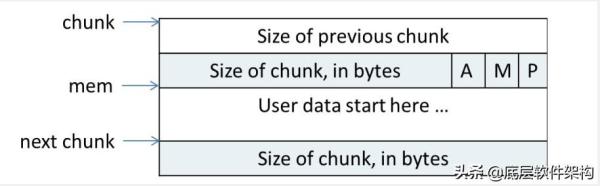
Chunk зҡ„з»“жһ„еҰӮдёҠжүҖзӨәпјҢA дҪҚиЎЁзӨәжҳҜдёҚжҳҜеңЁдё»еҲҶй…ҚеҢәпјҢM иЎЁзӨәжҳҜдёҚжҳҜ mmap еҮәжқҘзҡ„пјҢP иЎЁзӨәдёҠдёҖдёӘеҶ…еӯҳзҙ§йӮ»зҡ„ chunk жҳҜеҗҰеңЁдҪҝз”ЁпјҢеҰӮжһңжІЎеңЁдҪҝз”ЁпјҢеҲҷ size of previous
chunk жҳҜдёҠдёҖдёӘ chunk зҡ„еӨ§е°ҸпјҢеҗҰеҲҷж— ж„Ҹд№ү(иҖҢдё”иў«з”ЁдҪңиў«еҲҶй…ҚеҮәеҺ»зҡ„еҶ…еӯҳдәҶ)пјҢжӯЈејҸж №жҚ®
P ж Үи®°дҪҚе’Ң size of previous chunk еңЁ free еҶ…еӯҳеқ—зҡ„ж—¶еҖҷжқҘиҝӣиЎҢ chunk еҗҲ并зҡ„гҖӮеҪ“然пјҢеҰӮжһң chunk з©әй—ІпјҢmem йҮҢиҝҳи®°еҪ•дәҶдёҖдәӣжҢҮй’Ҳз”ЁдәҺзҙўеј•дёҙиҝ‘еӨ§е°Ҹзҡ„ chunk зҡ„пјҢе®һзҺ°еҺҹзҗҶе°ұдёҚеӨҚиҝ°дәҶпјҢзҹҘйҒ“еӨ§иҮҙдҪңз”Ёе°ұиЎҢгҖӮ
еңЁ free зҡ„ж—¶еҖҷпјҢptmalloc дјҡжЈҖжҹҘйҷ„иҝ‘зҡ„ chunkпјҢ并е°қиҜ•жҠҠиҝһз»ӯз©әй—Ізҡ„ chunk еҗҲ并жҲҗдёҖдёӘеӨ§зҡ„ chunkпјҢж”ҫеҲ° unstored bin йҮҢгҖӮдҪҶжҳҜеҪ“еҫҲе°Ҹзҡ„ chunk йҮҠж”ҫзҡ„ж—¶еҖҷпјҢptmalloc дјҡжҠҠе®ғ并е…Ҙ fast bin дёӯгҖӮеҗҢж ·пјҢжҹҗдәӣж—¶еҖҷпјҢfast bin йҮҢзҡ„иҝһз»ӯеҶ…еӯҳеқ—дјҡиў«еҗҲ并并еҠ е…ҘеҲ°дёҖдёӘ unsorted bin йҮҢпјҢ然еҗҺеҶҚжүҚиҝӣе…Ҙжҷ®йҖҡ bin йҮҢгҖӮжүҖд»Ҙ malloc е°ҸеҶ…еӯҳзҡ„ж—¶еҖҷпјҢжҳҜе…ҲжҹҘжүҫ fast
binпјҢеҶҚжҹҘжүҫ unsorted binпјҢжңҖеҗҺжҹҘжүҫжҷ®йҖҡзҡ„ binпјҢеҰӮжһң unsorted bin йҮҢзҡ„ chunk дёҚеҗҲйҖӮпјҢеҲҷдјҡжҠҠе®ғжү”еҲ° bin йҮҢгҖӮ
еӨ§еҶ…еӯҳеҲҶй…Қ
Ptmalloc зҡ„еҲҶй…Қзҡ„еҶ…еӯҳйЎ¶йғЁиҝҳжңүдёҖдёӘ top chunkпјҢеҰӮжһңеүҚйқўзҡ„ bin йҮҢзҡ„з©әй—І chunk йғҪдёҚи¶ід»Ҙж»Ўи¶ійңҖиҰҒпјҢе°ұжҳҜе°қиҜ•д»Һ top chunk йҮҢеҲҶй…ҚеҶ…еӯҳгҖӮеҰӮжһң top chunk йҮҢд№ҹдёҚеӨҹпјҢе°ұиҰҒд»Һж“ҚдҪңзі»з»ҹйҮҢжӢҝдәҶгҖӮ
иҝҳжңүе°ұжҳҜзү№еҲ«еӨ§зҡ„еҶ…еӯҳпјҢдјҡзӣҙжҺҘд»Һзі»з»ҹ mmap еҮәжқҘпјҢдёҚеҸ— chunk з®ЎзҗҶпјҢиҝҷж ·зҡ„еҶ…еӯҳеңЁеӣһ收зҡ„ж—¶еҖҷд№ҹдјҡ munmap иҝҳз»ҷж“ҚдҪңзі»з»ҹгҖӮ
з®ҖиҖҢиЁҖд№ӢпјҢе°ұжҳҜпјҡ
е°ҸеҶ…еӯҳпјҡ [иҺ·еҸ–еҲҶй…ҚеҢә(arena)并еҠ й”Ғ] -> fast bin -> unsorted bin -> small bin -> large bin
-> top chunk -> жү©еұ•е Ҷ
еӨ§еҶ…еӯҳпјҡ зӣҙжҺҘ mmap
жҖ»з»“
йҮҠж”ҫзҡ„ж—¶еҖҷпјҢеҮ д№ҺжҳҜе’ҢеҲҶй…ҚеҸҚиҝҮжқҘпјҢеҶҚеҠ дёҠеҸҜдёҖдәӣ chunk еҗҲ并е’Ңд»ҺдёҖдёӘ bin иҪ¬з§»еҲ°еҸҰдёҖдёӘ bin зҡ„ж“ҚдҪңгҖӮ并且еҰӮжһңйЎ¶йғЁжңүи¶іеӨҹеӨ§зҡ„з©әй—І chunkпјҢеҲҷ收缩е Ҷ顶并иҝҳз»ҷж“ҚдҪңзі»з»ҹгҖӮ
д»ӢдәҺжӯӨпјҢеҜ№дәҺ ptmalloc зҡ„еҶ…еӯҳеҲҶй…ҚдҪҝз”ЁжңүеҮ дёӘжіЁж„ҸдәӢйЎ№пјҡ
1. Ptmalloc й»ҳи®ӨеҗҺеҲҶй…ҚеҶ…еӯҳе…ҲйҮҠж”ҫпјҢеӣ дёәеҶ…еӯҳеӣһ收жҳҜд»Һ top chunk ејҖе§Ӣзҡ„гҖӮ
2. йҒҝе…ҚеӨҡзәҝзЁӢйў‘з№ҒеҲҶй…Қе’ҢйҮҠж”ҫеҶ…еӯҳпјҢдјҡйҖ жҲҗйў‘з№ҒеҠ и§Јй”ҒгҖӮ
3. дёҚиҰҒеҲҶй…Қй•ҝз”ҹе‘Ҫе‘Ёжңҹзҡ„еҶ…еӯҳеқ—пјҢе®№жҳ“йҖ жҲҗеҶ…зўҺзүҮпјҢеҪұе“ҚеҶ…еӯҳеӣһ收гҖӮ
2.5.2 Tcmalloc
е…·дҪ“е®һзҺ°еҺҹзҗҶдёҚеҠ д»Ҙиөҳиҝ°пјҢеҸҜиҮӘиЎҢзҷҫеәҰеӯҰд№ д№ӢпјҢжҖ»з»“д»ҘдёӢзү№зӮ№гҖӮ
· Tcmalloc еҚ з”Ёжӣҙе°‘зҡ„йўқеӨ–з©әй—ҙгҖӮдҫӢеҰӮпјҢеҲҶй…Қ N дёӘ 8 еӯ—иҠӮеҜ№иұЎеҸҜиғҪиҰҒдҪҝз”ЁеӨ§зәҰ 8N * 1.01
еӯ—иҠӮзҡ„з©әй—ҙгҖӮеҚіпјҢеӨҡз”ЁзҷҫеҲҶд№ӢдёҖзҡ„з©әй—ҙгҖӮPtmalloc2 дҪҝз”ЁжңҖе°‘ 8 еӯ—иҠӮжҸҸиҝ°дёҖдёӘ chunkгҖӮ
· жӣҙеҝ«гҖӮе°ҸеҜ№иұЎеҮ д№Һж— й”ҒпјҢ >32KB зҡ„еҜ№иұЎд»Һ CentralCache дёӯеҲҶй…ҚдҪҝз”ЁиҮӘж—Ӣй”ҒгҖӮ 并且>32KB еҜ№иұЎйғҪжҳҜйЎөйқўеҜ№йҪҗеҲҶй…ҚпјҢеӨҡзәҝзЁӢзҡ„ж—¶еҖҷеә”е°ҪйҮҸйҒҝе…Қйў‘з№ҒеҲҶй…ҚпјҢеҗҰеҲҷд№ҹдјҡйҖ жҲҗиҮӘж—Ӣй”Ғзҡ„з«һдәүе’ҢйЎөйқўеҜ№йҪҗйҖ жҲҗзҡ„жөӘиҙ№гҖӮ
2.6 жҖқз»ҙеҜјеӣҫ

3. еҲҶжһҗе·Ҙе…·
д»Һ CPU зҡ„жҖ§иғҪжҢҮж ҮеҮәеҸ‘гҖӮеҪ“дҪ иҰҒжҹҘзңӢжҹҗдёӘжҖ§иғҪжҢҮж Үж—¶пјҢиҰҒжё…жҘҡзҹҘйҒ“е“Әдәӣе·Ҙе…·еҸҜд»ҘеҒҡеҲ°гҖӮ
4. жҖқи·Ҝ
жҖ§иғҪдјҳеҢ–并дёҚжҳҜжІЎжңүеүҜдҪңз”Ёзҡ„пјҢйҖҡеёёжғ…еҶөдёӢ Linux зі»з»ҹжҳҜдёҚйңҖиҰҒзү№ж„Ҹи°ғж•ҙжҹҗдәӣжҢҮж ҮгҖӮеҫҖеҫҖжҖ§иғҪдјҳеҢ–дјҡеёҰжқҘж•ҙдҪ“зі»з»ҹзҡ„еӨҚжқӮеәҰзҡ„дёҠеҚҮпјҢйҷҚдҪҺдәҶеҸҜ移жӨҚжҖ§пјҢд№ҹеҸҜиғҪеңЁи°ғж•ҙжҹҗдёӘжҢҮж Үзҡ„ж—¶еҖҷеҜјиҮҙе…¶д»–жҢҮж ҮејӮеёёгҖӮ
并дёҚжҳҜжүҖжңүзҡ„жҖ§иғҪй—®йўҳйғҪйңҖиҰҒеҺ»дјҳеҢ–пјҢйңҖиҰҒеҜ№з“¶йўҲзӮ№иҝӣиЎҢдјҳеҢ–гҖӮжҜ”еҰӮеҪ“еүҚзі»з»ҹжңү瓶йўҲпјҢз”ЁжҲ· CPU дҪҝз”ЁзҺҮеҚҮй«ҳдәҶ 10%пјҢиҖҢзі»з»ҹзі»з»ҹ CPU дҪҝз”ЁзҺҮеҚҙеҚҮй«ҳдәҶ 50%пјҢиҝҷдёӘж—¶еҖҷе°ұеә”иҜҘйҰ–е…ҲдјҳеҢ–зі»з»ҹ CPU дҪҝз”ЁзҺҮгҖӮ
4.1 еә”з”ЁзЁӢеәҸдјҳеҢ–
д»Һеә”з”ЁзЁӢеәҸзҡ„и§’еәҰжқҘиҜҙпјҢйҷҚдҪҺ CPU дҪҝз”ЁзҺҮжңҖеҘҪзҡ„ж–№жі•жҳҜпјҢжҺ’йҷӨжүҖжңүдёҚеҝ…иҰҒзҡ„е·ҘдҪңпјҢеҸӘдҝқз•ҷжңҖж ёеҝғзҡ„йҖ»иҫ‘гҖӮжҜ”еҰӮеҮҸе°‘еҫӘзҺҜеұӮж¬ЎгҖҒеҮҸе°‘йҖ’еҪ’гҖҒеҮҸе°‘еҠЁжҖҒеҶ…еӯҳеҲҶй…ҚзӯүзӯүгҖӮ
еёёи§Ғзҡ„еҮ з§Қеә”з”ЁзЁӢеәҸзҡ„жҖ§иғҪдјҳеҢ–ж–№жі•пјҡ
зј–иҜ‘еҷЁдјҳеҢ–пјҡеҫҲеӨҡзј–иҜ‘еҷЁйғҪдјҡжҸҗдҫӣдјҳеҢ–йҖүйЎ№пјҢйҖӮеҪ“ејҖеҗҜе®ғ们пјҢеңЁзј–иҜ‘йҳ¶ж®өдҪ е°ұеҸҜд»ҘиҺ·еҫ—зј–иҜ‘еҷЁзҡ„её®еҠ©пјҢжқҘжҸҗеҚҮжҖ§иғҪгҖӮзӣ®еүҚи®ҫеӨҮйҮҮз”Ёзҡ„дјҳеҢ–йҖүйЎ№дёә OsпјҢзӣёеҪ“дәҺ O2.5
з®—жі•дјҳеҢ–пјҡдҪҝз”ЁејӮжӯҘеӨ„зҗҶпјҢеҸҜд»ҘйҒҝе…ҚзЁӢеәҸеӣ дёәзӯүеҫ…жҹҗдёӘиө„жәҗиҖҢдёҖзӣҙйҳ»еЎһпјҢд»ҺиҖҢжҸҗеҚҮзЁӢеәҸзҡ„并еҸ‘еӨ„зҗҶиғҪеҠӣгҖӮ
еӨҡзәҝзЁӢд»ЈжӣҝеӨҡиҝӣзЁӢпјҡзәҝзЁӢзҡ„дёҠдёӢж–ҮеҲҮжҚўе№¶дёҚеҲҮжҚўиҝӣзЁӢең°еқҖз©әй—ҙпјҢеӣ жӯӨеҸҜд»ҘйҷҚдҪҺдёҠдёӢж–ҮеҲҮжҚўзҡ„жҲҗжң¬гҖӮзӣ®еүҚи®ҫеӨҮйҮҮз”Ёзҡ„жҳҜеӨҡзәҝзЁӢжЁЎејҸгҖӮ
дҪҝз”Ё bufferпјҡз»Ҹеёёи®ҝй—®зҡ„ж•°жҚ®пјҢеҸҜд»Ҙж”ҫеңЁеҶ…еӯҳдёӯзј“еӯҳиө·жқҘпјҢиҝҷж ·еңЁдёӢж¬Ўз”Ёж—¶еҸҜд»ҘзӣҙжҺҘд»ҺеҶ…еӯҳдёӯиҺ·еҸ–пјҢеҠ еҝ«зЁӢеәҸзҡ„еӨ„зҗҶйҖҹеәҰгҖӮ
е°ҸеҶ…еӯҳдҪҝз”Ёпјҡе°ҸеҶ…еӯҳзҡ„з”іиҜ·пјҢеңЁдҝқиҜҒж Ҳз©әй—ҙдёҚжәўеҮәзҡ„жғ…еҶөдёӢпјҢе°ҪйҮҸйҮҮз”Ёж ҲдёҠз”іиҜ·пјҢе°‘дҪҝз”ЁеҠЁжҖҒеҶ…еӯҳз”іиҜ·пјҢжҸҗй«ҳзЁӢеәҸиҝҗиЎҢж•ҲзҺҮгҖӮ
4.2 зі»з»ҹдјҳеҢ–
д»Һзі»з»ҹзҡ„и§’еәҰжқҘиҜҙпјҢдјҳеҢ– CPU зҡ„иҝҗиЎҢпјҢдёҖж–№йқўиҰҒе……еҲҶеҲ©з”Ё CPU зј“еӯҳзҡ„жң¬ең°жҖ§пјҢеҠ йҖҹзј“еӯҳи®ҝй—®;еҸҰдёҖж–№йқўпјҢе°ұжҳҜиҰҒжҺ§еҲ¶иҝӣзЁӢзҡ„ CPU дҪҝз”Ёжғ…еҶөпјҢеҮҸе°‘иҝӣзЁӢй—ҙзҡ„зӣёдә’еҪұе“ҚгҖӮ
еёёи§Ғзҡ„ж–№жі•пјҡ
CPU з»‘е®ҡпјҡжҠҠиҝӣзЁӢз»‘е®ҡеҲ°дёҖдёӘжҲ–иҖ…еӨҡдёӘ CPU дёҠпјҢеҸҜд»ҘжҸҗй«ҳ CPU зј“еӯҳзҡ„е‘ҪдёӯзҺҮпјҢеҮҸе°‘и·Ё CPU и°ғеәҰеёҰжқҘзҡ„дёҠдёӢж–ҮеҲҮжҚўй—®йўҳгҖӮ
дјҳе…Ҳзә§и°ғж•ҙпјҡдҪҝз”Ё nice и°ғж•ҙиҝӣзЁӢзҡ„дјҳе…Ҳзә§пјҢжӯЈеҖји°ғдҪҺдјҳе…Ҳзә§пјҢиҙҹеҖји°ғй«ҳдјҳе…Ҳзә§гҖӮ
дёӯж–ӯиҙҹиҪҪеқҮиЎЎпјҡж— и®әжҳҜиҪҜдёӯж–ӯиҝҳжҳҜзЎ¬дёӯж–ӯпјҢе®ғ们зҡ„дёӯж–ӯеӨ„зҗҶзЁӢеәҸйғҪеҸҜиғҪж¶ҲиҖ—еӨ§йҮҸзҡ„ CPUгҖӮ
й…ҚзҪ® smp_affinityпјҢе°ұеҸҜд»ҘжҠҠдёӯж–ӯеӨ„зҗҶиҝҮзЁӢиҮӘеҠЁиҙҹиҪҪеқҮиЎЎеҲ°е…¶д»– CPU дёҠ
жӣҝжҚў ptmallocпјҡеҪ“еүҚдҪҝз”Ёзҡ„ gblic еә“пјҢе…¶еҠЁжҖҒеҶ…еӯҳз®ЎзҗҶйҮҮз”Ёе°ұжҳҜ ptmallocгҖӮеҪ“еүҚеә”з”ЁзЁӢеәҸеӨ§йҮҸдҪҝз”Ёе°Ҹе°әеҜёеҠЁжҖҒеҶ…еӯҳпјҢеҸҜд»ҘйҮҮз”Ё tcmallocпјҢеңЁе°ҸеҶ…еӯҳдёҠжӣҙеҝ«пјҢеҮ д№Һж— й”ҒгҖӮ
д»ҘдёҠе°ұжҳҜLinuxCPUиҫҫеҲ°з“¶йўҲиҜҘжҖҺж ·дјҳеҢ–пјҢе°Ҹзј–зӣёдҝЎжңүйғЁеҲҶзҹҘиҜҶзӮ№еҸҜиғҪжҳҜжҲ‘们ж—Ҙеёёе·ҘдҪңдјҡи§ҒеҲ°жҲ–з”ЁеҲ°зҡ„гҖӮеёҢжңӣдҪ иғҪйҖҡиҝҮиҝҷзҜҮж–Үз« еӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮжӣҙеӨҡиҜҰжғ…敬иҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ