жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№дё»иҰҒи®Іи§ЈвҖңеҰӮдҪ•з”ЁPythonеҶҷдёҖдёӘз”өдҝЎе®ўжҲ·жөҒеӨұйў„жөӢжЁЎеһӢвҖқпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢдёҚеҰЁжқҘзңӢзңӢгҖӮжң¬ж–Үд»Ӣз»Қзҡ„ж–№жі•ж“ҚдҪңз®ҖеҚ•еҝ«жҚ·пјҢе®һз”ЁжҖ§ејәгҖӮдёӢйқўе°ұи®©е°Ҹзј–жқҘеёҰеӨ§е®¶еӯҰд№ вҖңеҰӮдҪ•з”ЁPythonеҶҷдёҖдёӘз”өдҝЎе®ўжҲ·жөҒеӨұйў„жөӢжЁЎеһӢвҖқеҗ§!
01гҖҒе•ҶдёҡзҗҶи§Ј
жөҒеӨұе®ўжҲ·жҳҜжҢҮйӮЈдәӣжӣҫз»ҸдҪҝз”ЁиҝҮдә§е“ҒжҲ–жңҚеҠЎпјҢз”ұдәҺеҜ№дә§е“ҒеӨұеҺ»е…ҙи¶Јзӯүз§Қз§ҚеҺҹеӣ пјҢдёҚеҶҚдҪҝз”Ёдә§е“ҒжҲ–жңҚеҠЎзҡ„йЎҫе®ўгҖӮ
з”өдҝЎжңҚеҠЎе…¬еҸёгҖҒдә’иҒ”зҪ‘жңҚеҠЎжҸҗдҫӣе•ҶгҖҒдҝқйҷ©е…¬еҸёзӯүз»ҸеёёдҪҝз”Ёе®ўжҲ·жөҒеӨұеҲҶжһҗе’Ңе®ўжҲ·жөҒеӨұзҺҮдҪңдёә他们зҡ„е…ій”®дёҡеҠЎжҢҮж Үд№ӢдёҖпјҢеӣ дёәз•ҷдҪҸдёҖдёӘиҖҒе®ўжҲ·зҡ„жҲҗжң¬иҝңиҝңдҪҺдәҺиҺ·еҫ—дёҖдёӘж–°е®ўжҲ·гҖӮ
йў„жөӢеҲҶжһҗдҪҝз”Ёе®ўжҲ·жөҒеӨұйў„жөӢжЁЎеһӢпјҢйҖҡиҝҮиҜ„дј°е®ўжҲ·жөҒеӨұзҡ„йЈҺйҷ©еҖҫеҗ‘жқҘйў„жөӢе®ўжҲ·жөҒеӨұгҖӮз”ұдәҺиҝҷдәӣжЁЎеһӢз”ҹжҲҗдәҶдёҖдёӘжөҒеӨұжҰӮзҺҮжҺ’еәҸеҗҚеҚ•пјҢеҜ№дәҺжҪңеңЁзҡ„й«ҳжҰӮзҺҮжөҒеӨұе®ўжҲ·пјҢ他们еҸҜд»Ҙжңүж•Ҳең°е®һж–Ҫе®ўжҲ·дҝқз•ҷиҗҘй”Җи®ЎеҲ’гҖӮ
дёӢйқўжҲ‘们е°ұж•ҷдҪ еҰӮдҪ•з”ЁPythonеҶҷдёҖдёӘз”өдҝЎз”ЁжҲ·жөҒеӨұйў„жөӢжЁЎеһӢпјҢд»ҘдёӢжҳҜе…·дҪ“жӯҘйӘӨе’Ңе…ій”®д»Јз ҒгҖӮ
02гҖҒж•°жҚ®зҗҶи§Ј
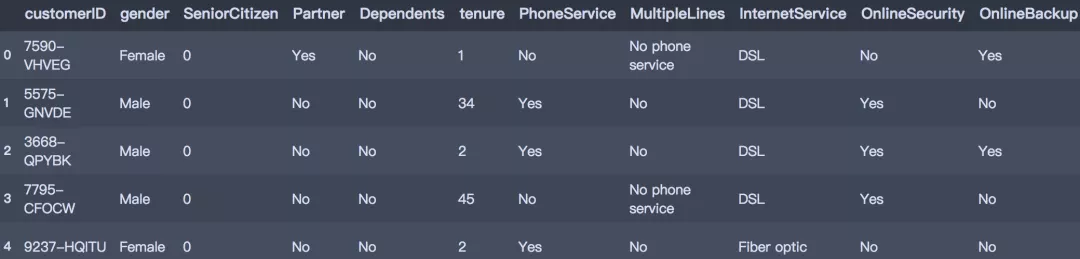
жӯӨж¬ЎеҲҶжһҗж•°жҚ®жқҘиҮӘдәҺIBM Sample Data SetsпјҢз»ҹи®ЎиҮӘжҹҗз”өдҝЎе…¬еҸёдёҖж®өж—¶й—ҙеҶ…зҡ„ж¶Ҳиҙ№ж•°жҚ®гҖӮе…ұжңү7043笔客жҲ·иө„ж–ҷпјҢжҜҸ笔客жҲ·иө„ж–ҷеҢ…еҗ«21дёӘеӯ—ж®өпјҢе…¶дёӯ1дёӘе®ўжҲ·IDеӯ—ж®өпјҢ19дёӘиҫ“е…Ҙеӯ—ж®өеҸҠ1дёӘзӣ®ж Үеӯ—ж®ө-Churn(Yesд»ЈиЎЁжөҒеӨұпјҢNoд»ЈиЎЁжңӘжөҒеӨұ)пјҢиҫ“е…Ҙеӯ—ж®өдё»иҰҒеҢ…еҗ«д»ҘдёӢдёүдёӘз»ҙеәҰжҢҮж Үпјҡз”ЁжҲ·з”»еғҸжҢҮж ҮгҖҒж¶Ҳиҙ№дә§е“ҒжҢҮж ҮгҖҒж¶Ҳиҙ№дҝЎжҒҜжҢҮж ҮгҖӮеӯ—ж®өзҡ„е…·дҪ“иҜҙжҳҺеҰӮдёӢпјҡ

03гҖҒж•°жҚ®иҜ»е…Ҙе’ҢжҰӮи§Ҳ
йҰ–е…ҲеҜје…ҘжүҖйңҖеҢ…гҖӮ
df = pd.read_csv('./Telco-Customer-Churn.csv') df.head()иҜ»е…Ҙж•°жҚ®йӣҶ
df = pd.read_csv('./Telco-Customer-Churn.csv')
df.head()
04гҖҒж•°жҚ®еҲқжӯҘжё…жҙ—
йҰ–е…ҲиҝӣиЎҢеҲқжӯҘзҡ„ж•°жҚ®жё…жҙ—е·ҘдҪңпјҢеҢ…еҗ«й”ҷиҜҜеҖје’ҢејӮеёёеҖјеӨ„зҗҶпјҢ并еҲ’еҲҶзұ»еҲ«еһӢе’Ңж•°еҖјеһӢеӯ—ж®өзұ»еһӢпјҢе…¶дёӯжё…жҙ—йғЁеҲҶеҢ…еҗ«пјҡ
OnlineSecurityгҖҒOnlineBackupгҖҒDeviceProtectionгҖҒTechSupportгҖҒStreamingTVгҖҒStreamingMoviesпјҡй”ҷиҜҜеҖјеӨ„зҗҶ
TotalChargesпјҡејӮеёёеҖјеӨ„зҗҶ
tenureпјҡиҮӘе®ҡд№үеҲҶз®ұ
е®ҡд№үзұ»еҲ«еһӢе’Ңж•°еҖјеһӢеӯ—ж®ө
# й”ҷиҜҜеҖјеӨ„зҗҶ repl_columns = ['OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport','StreamingTV', 'StreamingMovies'] for i in repl_columns: df[i] = df[i].replace({'No internet service' : 'No'}) # жӣҝжҚўеҖјSeniorCitizendf["SeniorCitizen"] = df["SeniorCitizen"].replace({1: "Yes", 0: "No"}) # жӣҝжҚўеҖјTotalChargesdf['TotalCharges'] = df['TotalCharges'].replace(' ', np.nan) # TotalChargesз©әеҖјпјҡж•°жҚ®йҮҸе°ҸпјҢзӣҙжҺҘеҲ йҷӨdf = df.dropna(subset=['TotalCharges']) df.reset_index(drop=True, inplace=True) # йҮҚзҪ®зҙўеј•# иҪ¬жҚўж•°жҚ®зұ»еһӢdf['TotalCharges'] = df['TotalCharges'].astype('float') # иҪ¬жҚўtenuredef transform_tenure(x): if x <= 12: return 'Tenure_1' elif x <= 24: return 'Tenure_2' elif x <= 36: return 'Tenure_3' elif x <= 48: return 'Tenure_4' elif x <= 60: return 'Tenure_5' else: return 'Tenure_over_5' df['tenure_group'] = df.tenure.apply(transform_tenure) # ж•°еҖјеһӢе’Ңзұ»еҲ«еһӢеӯ—ж®өId_col = ['customerID'] target_col = ['Churn'] cat_cols = df.nunique()[df.nunique() < 10].index.tolist() num_cols = [i for i in df.columns if i not in cat_cols + Id_col] print('зұ»еҲ«еһӢеӯ—ж®өпјҡ\n', cat_cols) print('-' * 30) print('ж•°еҖјеһӢеӯ—ж®өпјҡ\n', num_cols)зұ»еҲ«еһӢеӯ—ж®өпјҡ ['gender', 'SeniorCitizen', 'Partner', 'Dependents', 'PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod', 'Churn', 'tenure_group'] ------------------------------ ж•°еҖјеһӢеӯ—ж®өпјҡ ['tenure', 'MonthlyCharges', 'TotalCharges']
05гҖҒжҺўзҙўжҖ§еҲҶжһҗ
еҜ№жҢҮж ҮиҝӣиЎҢеҪ’зәіжўізҗҶпјҢеҲҶз”ЁжҲ·з”»еғҸжҢҮж ҮпјҢж¶Ҳиҙ№дә§е“ҒжҢҮж ҮпјҢж¶Ҳиҙ№дҝЎжҒҜжҢҮж ҮгҖӮжҺўзҙўеҪұе“Қз”ЁжҲ·жөҒеӨұзҡ„е…ій”®еӣ зҙ гҖӮ
1. зӣ®ж ҮеҸҳйҮҸChurnеҲҶеёғ
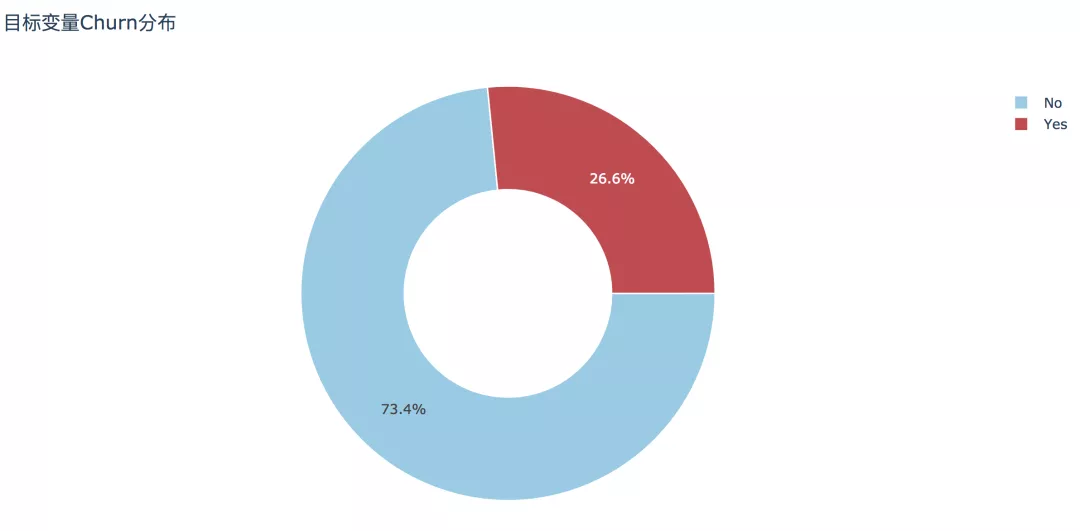
з»ҸиҝҮеҲқжӯҘжё…жҙ—д№ӢеҗҺзҡ„ж•°жҚ®йӣҶеӨ§е°Ҹдёә7032жқЎи®°еҪ•пјҢе…¶дёӯжөҒеӨұе®ўжҲ·дёә1869жқЎпјҢеҚ жҜ”26.6%пјҢжңӘжөҒеӨұе®ўжҲ·еҚ жҜ”73.4%гҖӮ
df['Churn'].value_counts() No 5163 Yes 1869 Name: Churn, dtype: int64
trace0 = go.Pie(labels=df['Churn'].value_counts().index, values=df['Churn'].value_counts().values, hole=.5, rotation=90, marker=dict(colors=['rgb(154,203,228)', 'rgb(191,76,81)'], line=dict(color='white', width=1.3)) )data = [trace0] layout = go.Layout(title='зӣ®ж ҮеҸҳйҮҸChurnеҲҶеёғ') fig = go.Figure(data=data, layout=layout) py.offline.plot(fig, filename='./html/ж•ҙдҪ“жөҒеӨұжғ…еҶөеҲҶеёғ.html')
2.жҖ§еҲ«
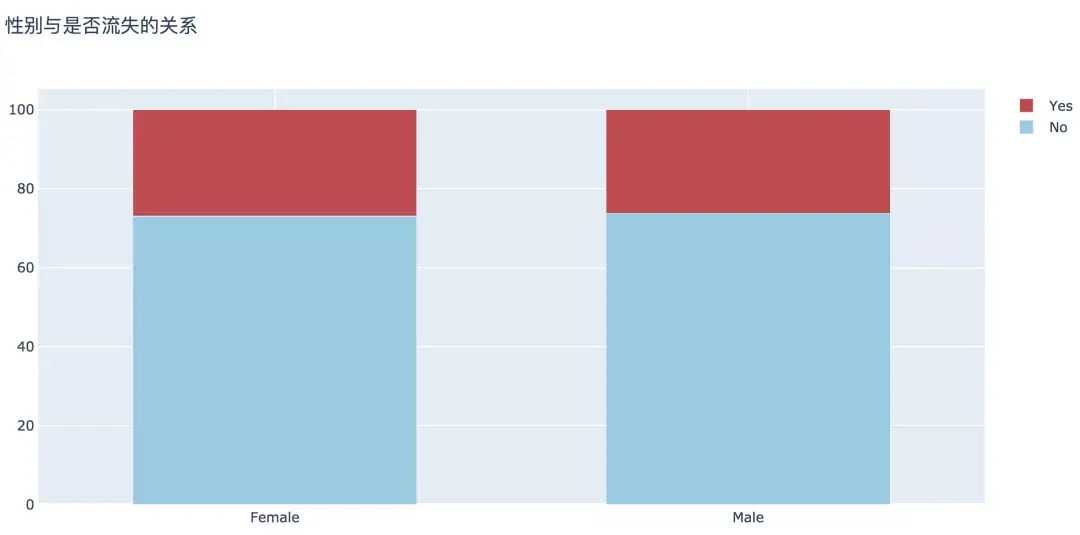
еҲҶжһҗеҸҜи§ҒпјҢз”·жҖ§е’ҢеҘіжҖ§еңЁе®ўжҲ·жөҒеӨұжҜ”дҫӢдёҠжІЎжңүжҳҫи‘—е·®ејӮгҖӮ
plot_bar(input_col='gender', target_col='Churn', title_name='жҖ§еҲ«дёҺжҳҜеҗҰжөҒеӨұзҡ„е…ізі»')
3. иҖҒе№ҙз”ЁжҲ·
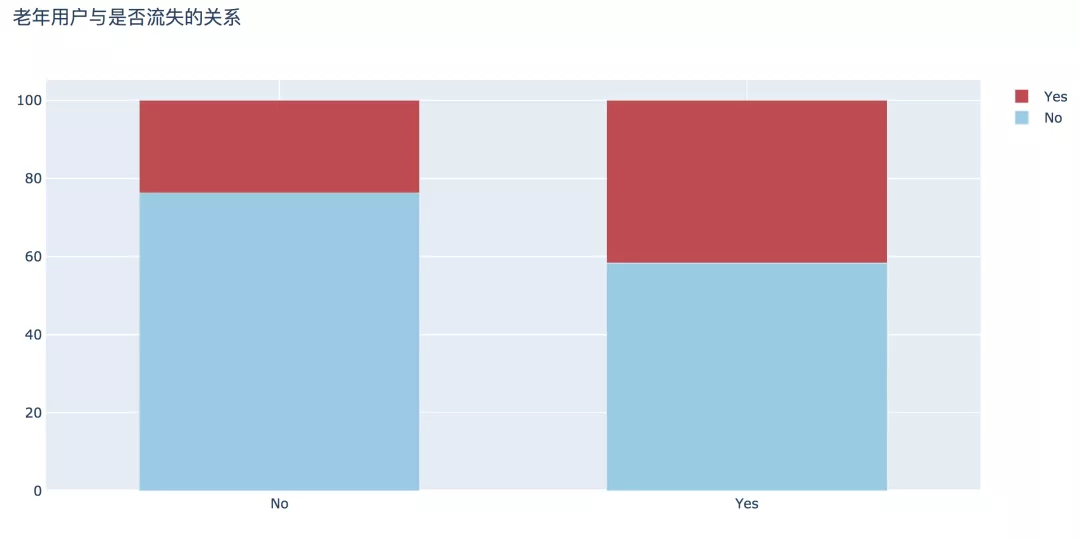
иҖҒе№ҙз”ЁжҲ·жөҒеӨұжҜ”дҫӢжӣҙй«ҳпјҢдёә41.68%пјҢжҜ”йқһиҖҒе№ҙз”ЁжҲ·й«ҳиҝ‘дёӨеҖҚпјҢжӯӨйғЁеҲҶеҺҹеӣ жңүеҫ…иҝӣдёҖжӯҘжҺўи®ЁгҖӮ
plot_bar(input_col='SeniorCitizen', target_col='Churn', title_name='иҖҒе№ҙз”ЁжҲ·дёҺжҳҜеҗҰжөҒеӨұзҡ„е…ізі»')
4. жҳҜеҗҰжңүй…ҚеҒ¶
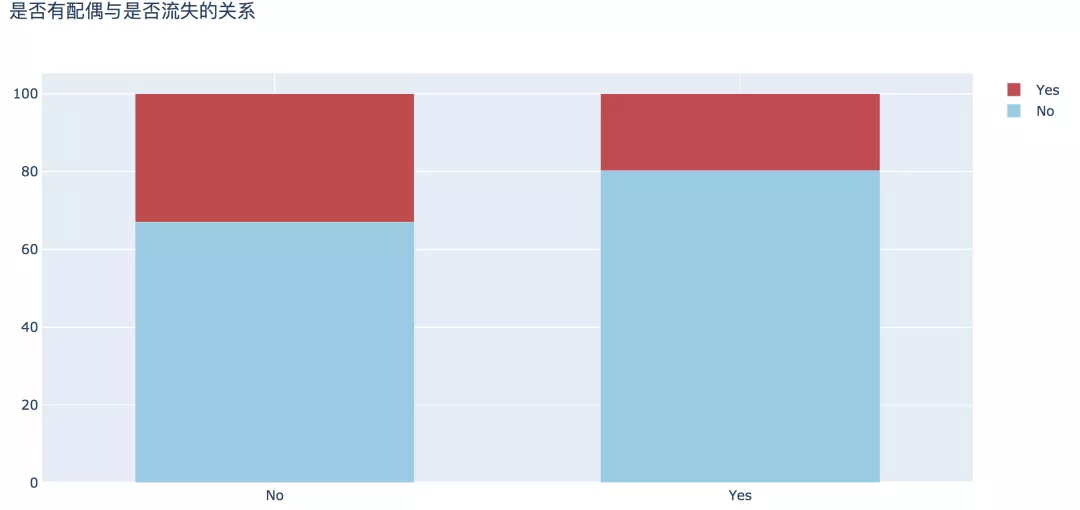
д»Һе©ҡ姻жғ…еҶөжқҘзңӢпјҢж•°жҚ®жҳҫзӨәпјҢжңӘе©ҡдәәзҫӨдёӯжөҒеӨұзҡ„жҜ”дҫӢжҜ”е·Іе©ҡдәәж•°й«ҳеҮә13%гҖӮ
plot_bar(input_col='Partner', target_col='Churn', title_name='жҳҜеҗҰжңүй…ҚеҒ¶дёҺжҳҜеҗҰжөҒеӨұзҡ„е…ізі»')
5. дёҠзҪ‘ж—¶й•ҝ
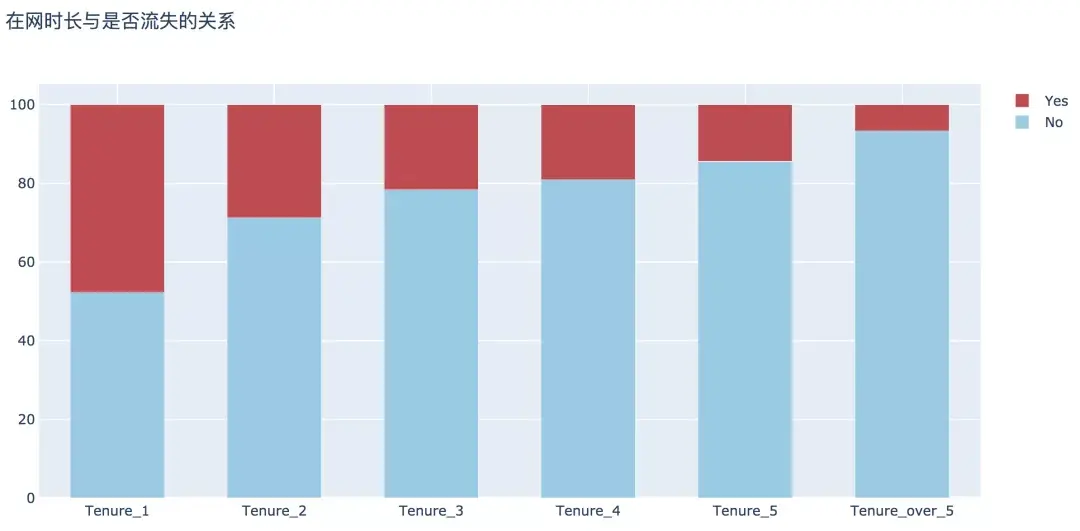
з»ҸиҝҮеҲҶжһҗпјҢиҝҷж–№йқўеҸҜд»Ҙеҫ—еҮәдёӨдёӘз»“и®әпјҡ
з”ЁжҲ·зҡ„еңЁзҪ‘ж—¶й•ҝи¶Ҡй•ҝпјҢиЎЁзӨәз”ЁжҲ·зҡ„еҝ иҜҡеәҰи¶Ҡй«ҳпјҢе…¶жөҒеӨұзҡ„жҰӮзҺҮи¶ҠдҪҺ;
ж–°з”ЁжҲ·еңЁ1е№ҙеҶ…зҡ„жөҒеӨұзҺҮжҳҫи‘—й«ҳдәҺж•ҙдҪ“жөҒеӨұзҺҮпјҢдёә47.68%гҖӮ
plot_bar(input_col='tenure_group', target_col='Churn', title_name='еңЁзҪ‘ж—¶й•ҝдёҺжҳҜеҗҰжөҒеӨұзҡ„е…ізі»')
6. д»ҳж¬ҫж–№ејҸ
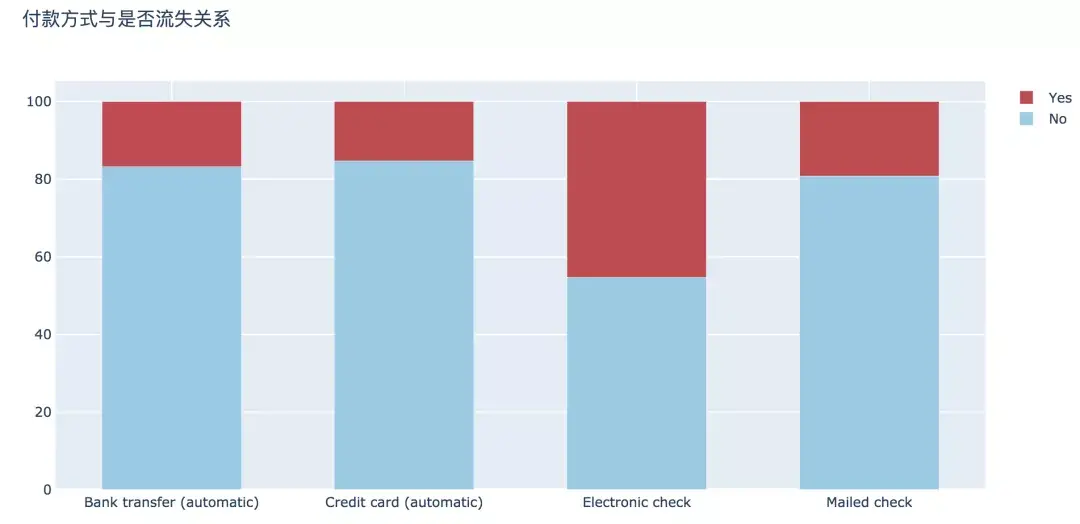
ж”Ҝд»ҳж–№ејҸдёҠпјҢж”Ҝд»ҳдёҠпјҢйҖүжӢ©з”өеӯҗж”ҜзҘЁж”Ҝд»ҳж–№ејҸзҡ„з”ЁжҲ·жөҒеӨұжңҖй«ҳпјҢиҫҫеҲ°45.29%пјҢе…¶д»–дёүз§Қж”Ҝд»ҳж–№ејҸзҡ„жөҒеӨұзҺҮзӣёе·®дёҚеӨ§гҖӮ
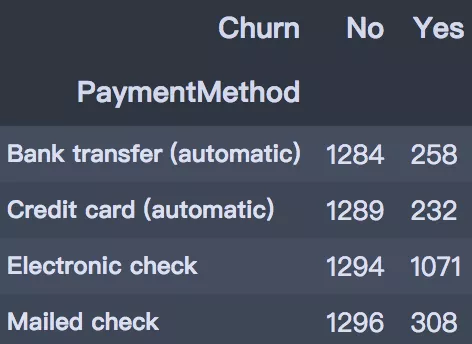
pd.crosstab(df['PaymentMethod'], df['Churn'])
plot_bar(input_col='PaymentMethod', target_col='Churn', title_name='д»ҳж¬ҫж–№ејҸдёҺжҳҜеҗҰжөҒеӨұе…ізі»')
7. жңҲиҙ№з”Ё
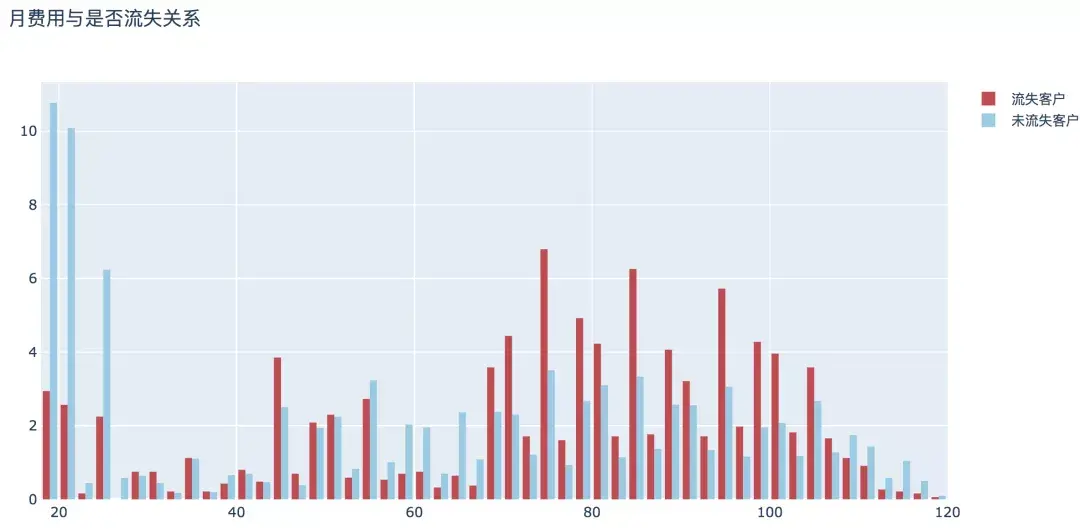
ж•ҙдҪ“жқҘзңӢпјҢйҡҸзқҖжңҲиҙ№з”Ёзҡ„еўһеҠ пјҢжөҒеӨұз”ЁжҲ·зҡ„жҜ”дҫӢе‘ҲзҺ°й«ҳй«ҳдҪҺдҪҺзҡ„еҸҳеҢ–пјҢжңҲж¶Ҳиҙ№80-100е…ғзҡ„з”ЁжҲ·зӣёеҜ№иҫғй«ҳгҖӮ
plot_histogram(input_col='MonthlyCharges', title_name='жңҲиҙ№з”ЁдёҺжҳҜеҗҰжөҒеӨұе…ізі»')
8. ж•°еҖјеһӢеұһжҖ§зӣёе…іжҖ§
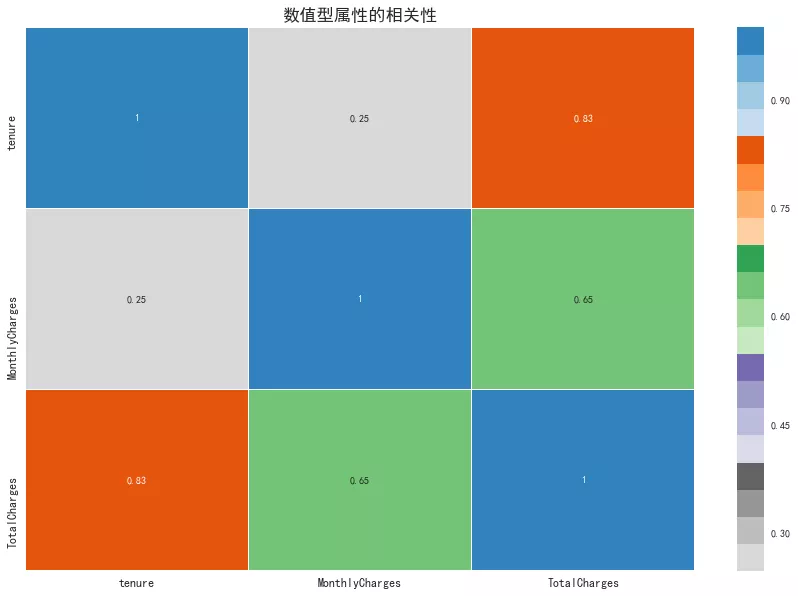
д»Һзӣёе…іжҖ§зҹ©йҳөеӣҫеҸҜд»ҘзңӢеҮәпјҢз”ЁжҲ·зҡ„еҫҖжқҘжңҹй—ҙе’ҢжҖ»иҙ№з”Ёе‘ҲзҺ°й«ҳеәҰзӣёе…іпјҢеҫҖжқҘжңҹй—ҙи¶Ҡй•ҝпјҢеҲҷжҖ»иҙ№з”Ёи¶Ҡй«ҳгҖӮжңҲж¶Ҳиҙ№е’ҢжҖ»ж¶Ҳиҙ№е‘ҲзҺ°жҳҫи‘—зӣёе…ігҖӮ
plt.figure(figsize=(15, 10)) sns.heatmap(df.corr(), linewidths=0.1, cmap='tab20c_r', annot=True) plt.title('ж•°еҖјеһӢеұһжҖ§зҡ„зӣёе…іжҖ§', fontdict={'fontsize': 'xx-large', 'fontweight':'heavy'}) plt.xticks(fontsize=12) plt.yticks(fontsize=12) plt.show()06гҖҒзү№еҫҒйҖүжӢ©
дҪҝз”Ёз»ҹи®ЎжЈҖе®ҡж–№ејҸиҝӣиЎҢзү№еҫҒзӯӣйҖүгҖӮ
# еҲ йҷӨtenure df = df.drop('tenure', axis=1) from feature_selection import Feature_select# еҲ’еҲҶXе’ҢyX = df.drop(['customerID', 'Churn'], axis=1) y = df['Churn'] fs = Feature_select(num_method='anova', cate_method='kf', pos_label='Yes') x_sel = fs.fit_transform(X, y) 2020 09:30:02 INFO attr select success! After select attr: ['DeviceProtection', 'MultipleLines', 'OnlineSecurity', 'TechSupport', 'tenure_group', 'PaperlessBilling', 'InternetService', 'PaymentMethod', 'SeniorCitizen', 'MonthlyCharges', 'Dependents', 'Partner', 'Contract', 'StreamingTV', 'TotalCharges', 'StreamingMovies', 'OnlineBackup']з»ҸиҝҮзү№еҫҒзӯӣйҖүпјҢgenderе’ҢPhoneServiceеӯ—ж®өиў«еҺ»жҺүгҖӮ
07гҖҒе»әжЁЎеүҚеӨ„зҗҶ
еңЁpythonдёӯпјҢдёәж»Ўи¶іе»әжЁЎйңҖиҰҒпјҢдёҖиҲ¬йңҖиҰҒеҜ№ж•°жҚ®еҒҡд»ҘдёӢеӨ„зҗҶпјҡ
еҜ№дәҺдәҢеҲҶзұ»еҸҳйҮҸпјҢзј–з Ғдёә0е’Ң1;
еҜ№дәҺеӨҡеҲҶзұ»еҸҳйҮҸпјҢиҝӣиЎҢone_hotзј–з Ғ;
еҜ№дәҺж•°еҖјеһӢеҸҳйҮҸпјҢйғЁеҲҶжЁЎеһӢеҰӮKNNгҖҒзҘһз»ҸзҪ‘з»ңгҖҒLogisticйңҖиҰҒиҝӣиЎҢж ҮеҮҶеҢ–еӨ„зҗҶгҖӮ
# зӯӣйҖүеҸҳйҮҸ select_features = x_sel.columns# е»әжЁЎж•°жҚ®df_model = pd.concat([df['customerID'], df[select_features], df['Churn']], axis=1)Id_col = ['customerID']target_col = ['Churn']# еҲҶзұ»еһӢcat_cols = df_model.nunique()[df_model.nunique() < 10].index.tolist() # дәҢеҲҶзұ»еұһжҖ§ binary_cols = df_model.nunique()[df_model.nunique() == 2].index.tolist() # еӨҡеҲҶзұ»еұһжҖ§ multi_cols = [i for i in cat_cols if i not in binary_cols] # ж•°еҖјеһӢ num_cols = [i for i in df_model.columns if i not in cat_cols + Id_col] # дәҢеҲҶзұ»-ж Үзӯҫзј–з Ғ le = LabelEncoder() for i in binary_cols: df_model[i] = le.fit_transform(df_model[i]) # еӨҡеҲҶзұ»-е“‘еҸҳйҮҸиҪ¬жҚў df_model = pd.get_dummies(data=df_model, columns=multi_cols) df_model.head()
08гҖҒжЁЎеһӢе»әз«Ӣе’ҢиҜ„дј°
йҰ–е…ҲдҪҝз”ЁеҲҶеұӮжҠҪж ·зҡ„ж–№ејҸе°Ҷж•°жҚ®еҲ’еҲҶи®ӯз»ғйӣҶе’ҢжөӢиҜ•йӣҶгҖӮ
# йҮҚж–°еҲ’еҲҶ X = df_model.drop(['customerID', 'Churn'], axis=1) y = df_model['Churn'] # еҲҶеұӮжҠҪж ·X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0, stratify=y) print(X_train.shape, X_test.shape, y_train.shape, y_test.shape) #дҝ®жӯЈзҙўеј•for i in [X_train, X_test, y_train, y_test]: i.index = range(i.shape[0])
(5625, 31) (1407, 31) (5625,) (1407,)
# дҝқеӯҳж ҮеҮҶеҢ–и®ӯз»ғе’ҢжөӢиҜ•ж•°жҚ® st = StandardScaler()num_scaled_train = pd.DataFrame(st.fit_transform(X_train[num_cols]), columns=num_cols)num_scaled_test = pd.DataFrame(st.transform(X_test[num_cols]), columns=num_cols) X_train_sclaed = pd.concat([X_train.drop(num_cols, axis=1), num_scaled_train], axis=1) X_test_sclaed = pd.concat([X_test.drop(num_cols, axis=1), num_scaled_test], axis=1)
然еҗҺе»әз«ӢдёҖзі»еҲ—еҹәеҮҶжЁЎеһӢ并жҜ”иҫғж•ҲжһңгҖӮ
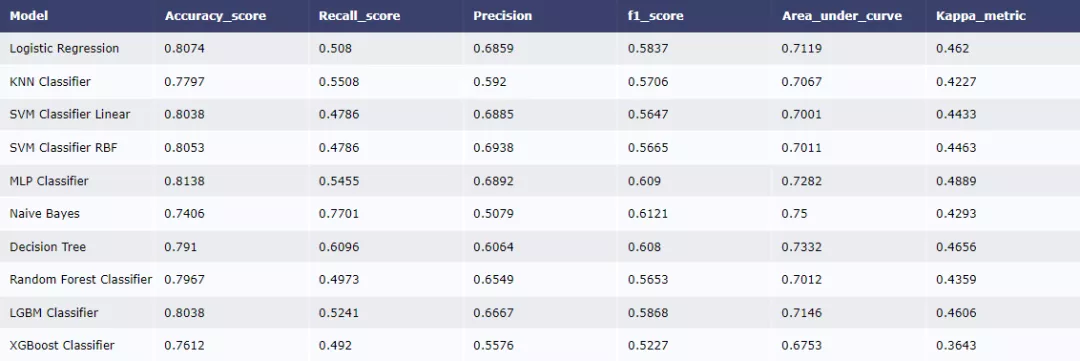
еҒҮеҰӮжҲ‘们关注rocжҢҮж ҮпјҢд»ҺжЁЎеһӢиЎЁзҺ°ж•ҲжһңжқҘзңӢпјҢNaive Bayesж•ҲжһңжңҖеҘҪгҖӮжҲ‘们д№ҹеҸҜд»ҘеҜ№жЁЎеһӢиҝӣиЎҢиҝӣдёҖжӯҘдјҳеҢ–пјҢжҜ”еҰӮеҜ№еҶізӯ–ж ‘еҸӮж•°иҝӣиЎҢи°ғдјҳгҖӮ
parameters = {'splitter': ('best','random'), 'criterion': ("gini","entropy"), "max_depth": [*range(3, 20)], }clf = DecisionTreeClassifier(random_state=25) GS = GridSearchCV(clf, parameters, scoring='f1', cv=10) GS.fit(X_train, y_train)print(GS.best_params_) print(GS.best_score_){'criterion': 'entropy', 'max_depth': 5, 'splitter': 'best'} 0.585900839405024clf = GS.best_estimator_ test_pred = clf.predict(X_test)print('жөӢиҜ•йӣҶпјҡ\n', classification_report(y_test, test_pred))жөӢиҜ•йӣҶпјҡ precision recall f1-score support 0 0.86 0.86 0.86 1033 1 0.61 0.61 0.61 374 accuracy 0.79 1407 macro avg 0.73 0.73 0.73 1407 weighted avg 0.79 0.79 0.79 1407
е°ҶиҝҷжЈөж ‘з»ҳеҲ¶еҮәжқҘгҖӮ
import graphviz dot_data = tree.export_graphviz(decision_tree=clf, max_depth=3, out_file=None, feature_names=X_train.columns, class_names=['not_churn', 'churn'], filled=True, rounded=True )graph = graphviz.Source(dot_data)
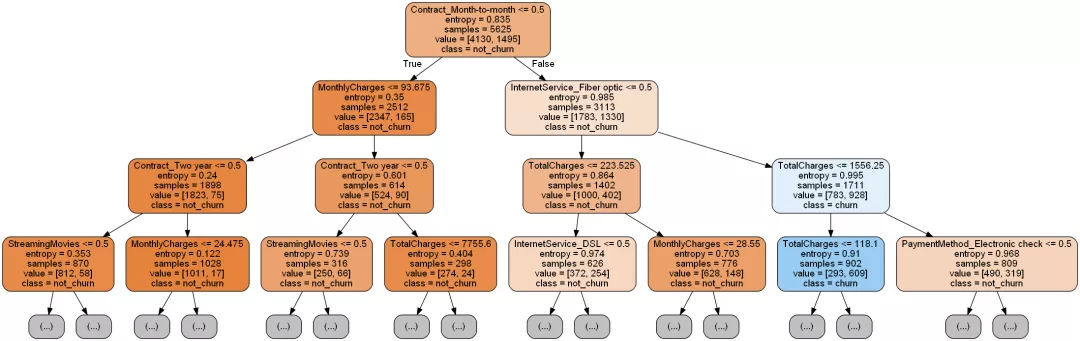
иҫ“еҮәеҶізӯ–ж ‘еұһжҖ§йҮҚиҰҒжҖ§жҺ’еәҸпјҡ
imp = pd.DataFrame(zip(X_train.columns, clf.feature_importances_)) imp.columns = ['feature', 'importances'] imp = imp.sort_values('importances', ascending=False) imp = imp[imp['importances'] != 0] table = ff.create_table(np.round(imp, 4)) py.offline.iplot(table)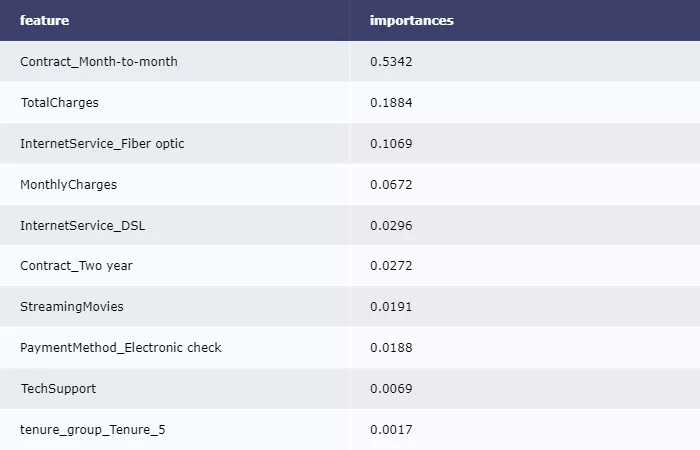
еҗҺз»ӯдјҳеҢ–ж–№еҗ‘пјҡ
ж•°жҚ®пјҡеҲҶзұ»жҠҖжңҜеә”з”ЁеңЁзӣ®ж Үзұ»еҲ«еҲҶеёғи¶ҠеқҮеҢҖзҡ„ж•°жҚ®йӣҶж—¶пјҢе…¶жүҖе»әз«Ӣд№ӢеҲҶзұ»еҷЁйҖҡеёёдјҡжңүжҜ”иҫғеҘҪзҡ„еҲҶзұ»ж•ҲиғҪгҖӮй’ҲеҜ№ж•°жҚ®еңЁзӣ®ж Үеӯ—ж®өдёҠеҲҶеёғдёҚе№іиЎЎпјҢеҸҜйҮҮз”ЁиҝҮйҮҮж ·е’Ңж¬ йҮҮж ·жқҘеӨ„зҗҶзұ»еҲ«дёҚе№іиЎЎй—®йўҳ;
еұһжҖ§пјҡиҝӣдёҖжӯҘеұһжҖ§зӯӣйҖүж–№жі•е’ҢеұһжҖ§з»„еҗҲ;
з®—жі•пјҡеҸӮж•°и°ғдјҳ;и°ғж•ҙйў„жөӢй—Ёж§ӣеҖјжқҘеўһеҠ йў„жөӢж•ҲиғҪгҖӮ
еҲ°жӯӨпјҢзӣёдҝЎеӨ§е®¶еҜ№вҖңеҰӮдҪ•з”ЁPythonеҶҷдёҖдёӘз”өдҝЎе®ўжҲ·жөҒеӨұйў„жөӢжЁЎеһӢвҖқжңүдәҶжӣҙж·ұзҡ„дәҶи§ЈпјҢдёҚеҰЁжқҘе®һйҷ…ж“ҚдҪңдёҖз•Әеҗ§пјҒиҝҷйҮҢжҳҜдәҝйҖҹдә‘зҪ‘з«ҷпјҢжӣҙеӨҡзӣёе…іеҶ…е®№еҸҜд»Ҙиҝӣе…Ҙзӣёе…ійў‘йҒ“иҝӣиЎҢжҹҘиҜўпјҢе…іжіЁжҲ‘们пјҢ继з»ӯеӯҰд№ пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ