您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
前几天给大家介绍了unicode编码和utf-8编码的理论知识,没来得及上车的小伙伴们可以戳这篇文章:浅谈unicode编码和utf-8编码的关系。下面在Python2环境中进行代码演示,分别Windows和Linux操作系统下进行演示,以加深对字符串编码的理解。

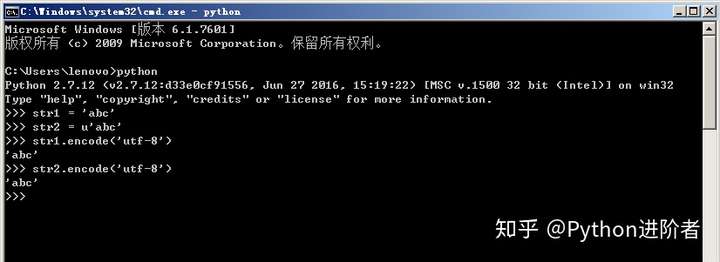
1、首先在Windows操作系统下的Python2环境中进行演示,我们都知道Python2中的编码问题经常出现,需要通过编码(encode)和解码(decode)进行实现。通过cmd进入命令行窗口,然后输入两个字符串’abc’和u’abc’,如下图所示。需要注意的是这两个字符串的编码格式是不一样的,前者是string,后者是unicode。接下来对其进行编码,指定编码为utf-8,可以发现两个都正常显示,没有报错。
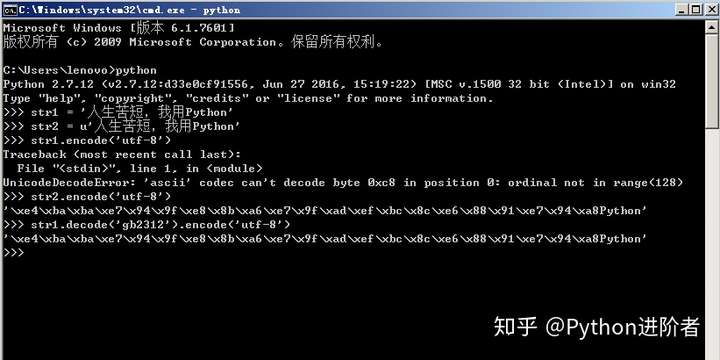
当字符串变为中文的时候,尔后对其再次进行编码演示的时候,如下图所示,可以看到前者有报错产生,而后者没有报错。这个报错在Python2中经常出现,所以需要特别注意,Python字符串在内存中它是通过unicode来进行编码的。此时定义的str1它传递过来的是utf-8编码,非unicode编码,使用encode()函数的前提是待转换的字符串编码为unicode编码。所以可以看到str1会报错,而str2并没有报错。在Windows下字符串的编码格式是GB2312编码,在Linux下字符串的编码格式是utf-8编码。如果想要将str1顺利的转换为utf-8编码的话,则需要先将str1进行解码成unicode编码,再进行编码即可,此时得到的结果同str2转换的结果是一致的。
2、现在在Linux操作系统下的Python2环境中进行演示,使用一样的字符串,结果最后是一样的,但是过程有些不同,如下图所示。
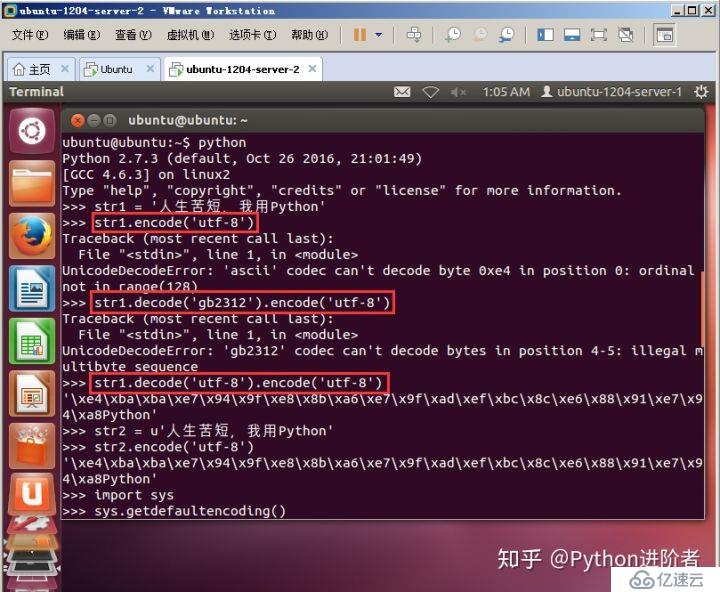
在Windows下字符串的编码格式是GB2312编码,在Linux下字符串的编码格式是utf-8编码。所以当输入有中文的字符串的时候,直接编码为utf-8会报错;通过gb2312编码进行解码也会报错。只要通过utf-8编码进行解码,然后再通过utf-8进行编码才可以正确的输出结果。
有个地方大家可能会觉得很奇怪,就是一开始str1.encode(‘utf-8’),表面上看上去str1已经是unicode编码了,之后进行编码,按说没有什么问题,可是为什么还是会报错呢?其实主要原因还是在于str1并不是真正的解码成了unicode格式。其实str1.encode(‘utf-8’),它默认的会进行一步解码,但是其decode()的过程调用的是默认的编码格式,而这个默认的编码格式却是ASCII编码,如下图所示。
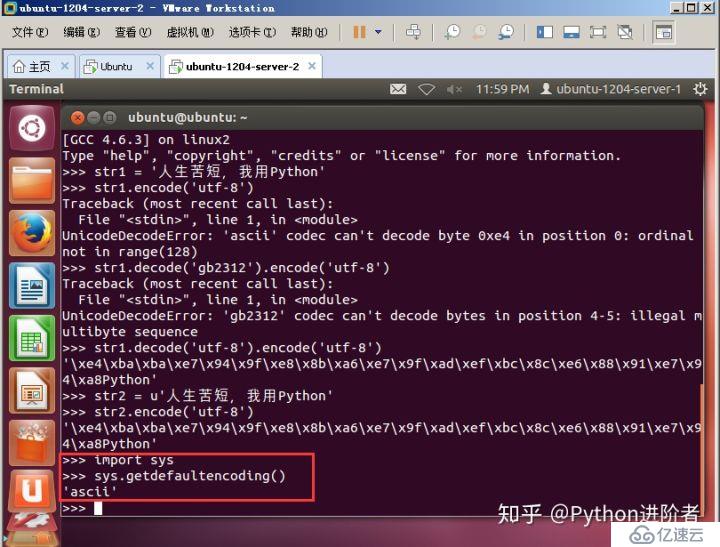
当中文字符串使用ASCII编码进行解码之后,本身就报错了,后边的encode(‘utf-8’)根本就没有执行到。
关于Python2中字符串编码的问题,就先介绍到这里了,相信大家应该有了一个初步的认识了,下一篇文章将介绍Python3中字符串编码的问题。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。