您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
从今天开始接触Python网络爬虫,写了一个爬取百度代码,并保存到本地的小示例,主要应用的是Python的requests库,以及with open()语句。首先,我用 代码判断了能否用requests方法正常访问网页,用了status_code,结果是200,表明访问成功。然后转换编码格式,将爬下来的代码写入TXT文件保存实现代码如下:
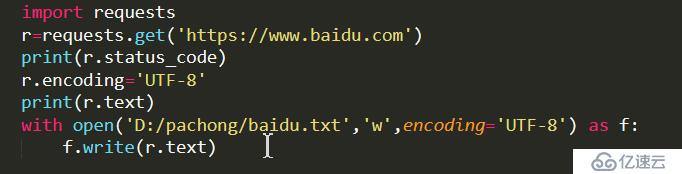
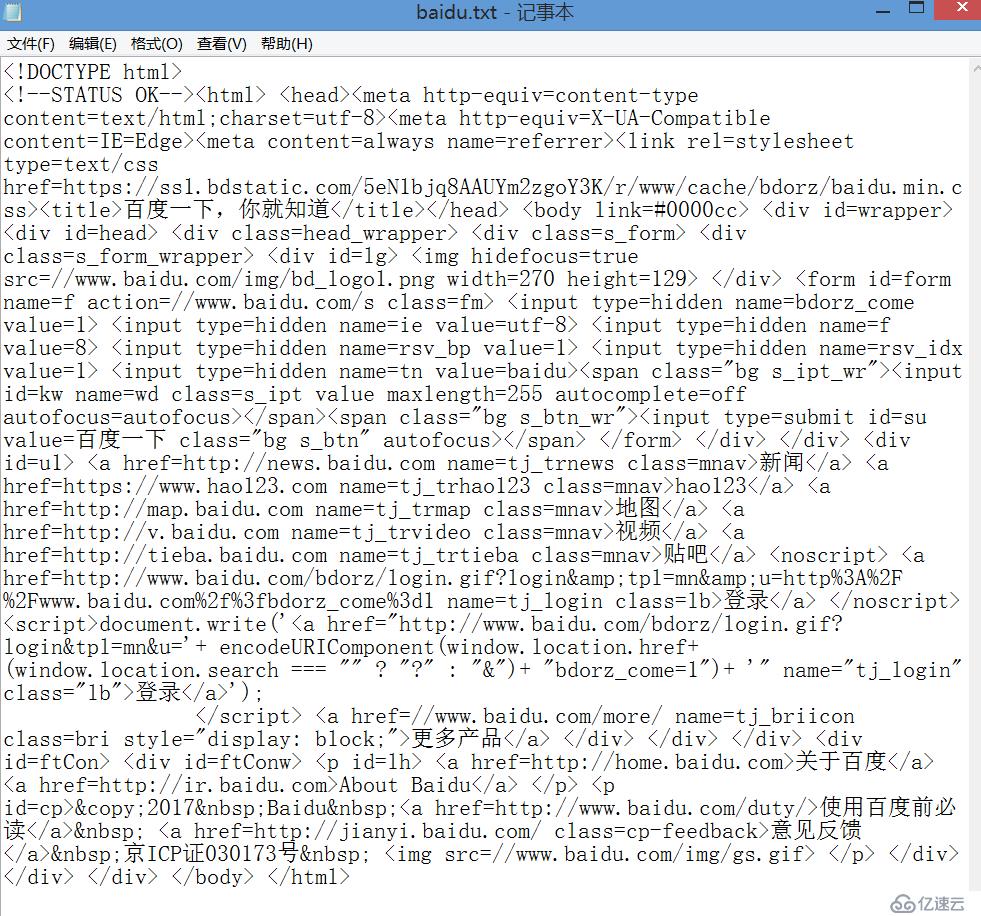
在写这个代码的过程中,遇到了两个问题,一个是编码,要转换成UTF-8,另一个是如何保存下载下来的代码。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。