жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңеңЁScrapyдёӯжҖҺд№ҲеҲ©з”ЁCSSйҖүжӢ©еҷЁд»ҺзҪ‘йЎөдёӯйҮҮйӣҶзӣ®ж Үж•°жҚ®вҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁеңЁScrapyдёӯжҖҺд№ҲеҲ©з”ЁCSSйҖүжӢ©еҷЁд»ҺзҪ‘йЎөдёӯйҮҮйӣҶзӣ®ж Үж•°жҚ®й—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқеңЁScrapyдёӯжҖҺд№ҲеҲ©з”ЁCSSйҖүжӢ©еҷЁд»ҺзҪ‘йЎөдёӯйҮҮйӣҶзӣ®ж Үж•°жҚ®вҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
/CSSеҹәзЎҖ/
CSSйҖүжӢ©еҷЁе’ҢXpathйҖүжӢ©еҷЁзҡ„еҠҹиғҪжҳҜдёҖиҮҙзҡ„пјҢйғҪжҳҜеё®еҠ©жҲ‘们еҺ»е®ҡдҪҚзҪ‘йЎөз»“жһ„дёӯзҡ„жҹҗдёҖдёӘе…·дҪ“зҡ„е…ғзҙ пјҢдҪҶжҳҜеңЁиҜӯжі•иЎЁиҫҫдёҠжңүеҢәеҲ«гҖӮXpathйҖүжӢ©еҷЁжҳҺжҳҺе·Із»ҸеҸҜд»Ҙеё®еҠ©жҲ‘们жҸҗеҸ–дҝЎжҒҜдәҶпјҢдёәд»Җд№ҲиҝҳиҰҒеӯҰд№ CSSйҖүжӢ©еҷЁе‘ўпјҹ
иҗқеҚңйқ’иҸңеҗ„жңүжүҖзҲұпјҢеҜ№дәҺдёҚеҗҢзҹҘиҜҶиғҢжҷҜзҡ„е°ҸдјҷдјҙпјҢйғҪеҸҜд»ҘжқҘжҸҗеҸ–зҪ‘йЎөдҝЎжҒҜгҖӮеҸӘиҰҒжҳҜиғҪжҠ“еҲ°иҖҒйј зҡ„зҢ«пјҢйғҪжҳҜеҘҪзҢ«пјҢеҗҢж ·зҡ„пјҢеҸӘиҰҒиғҪжҸҗеҸ–дҝЎжҒҜпјҢдёҚи®әжҳҜжӯЈеҲҷиЎЁиҫҫејҸгҖҒBeateafulSoupгҖҒXpathйҖүжӢ©еҷЁдәҰжҲ–жҳҜCSSйҖүжӢ©еҷЁпјҢйғҪжҳҜеҘҪзҡ„йҖүжӢ©еҷЁпјҢеҸӘдёҚиҝҮеңЁж•ҲзҺҮе’Ңйҡҫжҳ“зЁӢеәҰдёҠдёҚдёҖж ·гҖӮжӯӨеӨ–пјҢеҜ№еә”еүҚз«Ҝзҡ„е°ҸдјҷдјҙжқҘиҜҙпјҢCSSйҖүжӢ©еҷЁеҜ№д»–们жқҘиҜҙе°ұз®ҖеҚ•еҫҲеӨҡгҖӮ
CSSйҖүжӢ©еҷЁеҠҹиғҪејәеӨ§пјҢд»Һе®һз”ЁжҖ§еҮәеҸ‘пјҢдёӢйқўжҳҜйғЁеҲҶжҜ”иҫғеёёз”Ёзҡ„дёҖдәӣCSSйҖүжӢ©еҷЁиҜӯжі•пјҢзӣёеҜ№жқҘиҜҙжҜ”иҫғз®ҖеҚ•пјҢдҪҶжҳҜд№ҹжҳҜйқһеёёе®һз”Ёзҡ„иҜӯжі•пјҢеёҢжңӣеӨ§е®¶йғҪеҸҜд»ҘзүўзүўжҺҢжҸЎпјҢеҗҺжңҹеңЁжҸҗеҸ–зҪ‘йЎөдҝЎжҒҜзҡ„ж—¶еҖҷе°ҶдјҡдәӢеҚҠеҠҹеҖҚгҖӮ

жңүдәҶд»ҘдёҠзҡ„CSSеҹәзЎҖд№ӢеҗҺпјҢжҺҘдёӢжқҘжҲ‘们иҝӣиЎҢе®һйҷ…еә”з”ЁгҖӮ
/е®һйҷ…еә”з”Ё/
д»Қ然д»Ҙд№ӢеүҚзҡ„зҪ‘з«ҷдёәдҫӢиҝӣиЎҢиҜҙжҳҺпјҢжҲ‘们зҡ„зӣ®ж Үж•°жҚ®жҳҜж ҮйўҳгҖҒеҸ‘еёғж—ҘжңҹгҖҒдё»йўҳгҖҒжӯЈж–ҮеҶ…е®№гҖҒзӮ№иөһж•°гҖҒ收и—Ҹж•°гҖҒиҜ„и®әж•°зӯүгҖӮ
1гҖҒе…ідәҺж ҮйўҳйғЁеҲҶпјҢд№ӢеүҚжҲ‘们еҲ©з”ЁXpathзҡ„иЎЁиҫҫејҸзҡ„ж—¶еҖҷе°ұеҲҶжһҗиҝҮпјҢеҫ—еҲ°дәҶе”ҜдёҖжҖ§зҡ„е®ҡдҪҚж ҮзӯҫпјҢеңЁжӯӨдёҚеҶҚиөҳиҝ°пјҢеҰӮдёӢеӣҫжүҖзӨәгҖӮ
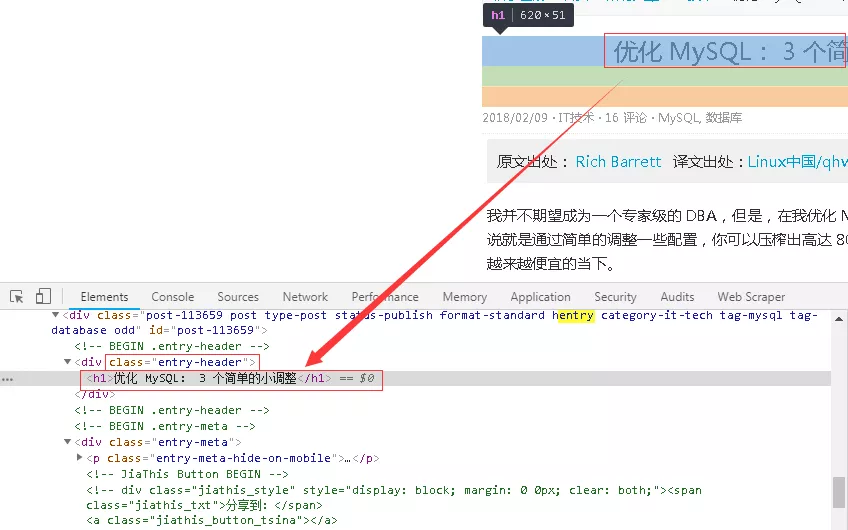
2гҖҒд»Қ然еҲ©з”Ёscrapyshellзҡ„и°ғиҜ•жЁЎејҸиҝӣиЎҢеҠ©ж”»пјҢз»“еҗҲдёҠиҫ№зҡ„CSSеҹәзЎҖиҜӯжі•пјҢж Үйўҳзҡ„е…·дҪ“CSSиЎЁиҫҫејҸеҰӮдёӢеӣҫжүҖзӨәгҖӮ

йңҖиҰҒжіЁж„Ҹзҡ„жҳҜеңЁCSSдёӯиҺ·еҸ–ж Үзӯҫж–Үжң¬еҶ…е®№зҡ„ж–№ејҸжҳҜеңЁCSSиЎЁиҫҫејҸеҗҺиҫ№зҙ§и·ҹвҖң::textвҖқпјҢи®°дҪҸжҳҜжңүдёӨдёӘеҶ’еҸ·еҷўпјҢдёҺXpathиЎЁиҫҫејҸдёҚдёҖж ·гҖӮиҝҷдёӘиЎЁиҫҫејҸзңӢдёҠеҺ»жҜ”XpathиЎЁиҫҫејҸиҰҒз®ҖжҙҒдёҖдәӣпјҢжүҖд»ҘеҪ“жҹҗдәӣжғ…еҶөдёӢпјҢеӨ§е®¶еҰӮжһңи§үеҫ—CSSйҖүжӢ©еҷЁзҡ„иЎЁиҫҫејҸжҜ”XpathиЎЁиҫҫејҸиҰҒз®ҖзҹӯжҲ–иҖ…зҗҶи§Јиө·жқҘзӣёеҜ№е®№жҳ“зҡ„иҜқпјҢеҸҜд»ҘйҰ–йҖүCSSйҖүжӢ©еҷЁпјҢжІЎжңүе…·дҪ“зҡ„иҰҒжұӮпјҢеӨ§е®¶ж №жҚ®иҮӘе·ұзҡ„е–ңзҲұжқҘиҝӣиЎҢйҖүжӢ©еҚіеҸҜпјҢеҸҚд№ӢдәҰжҲҗз«ӢпјҢеҪ“然д№ҹеҸҜд»ҘеҗҢж—¶еңЁдёҖдёӘзҲ¬иҷ«ж–Ү件е°ҶдёӨдёӘжҲ–иҖ…еӨҡдёӘйҖүжӢ©еҷЁиҝӣиЎҢдәӨеҸүдҪҝз”ЁгҖӮ
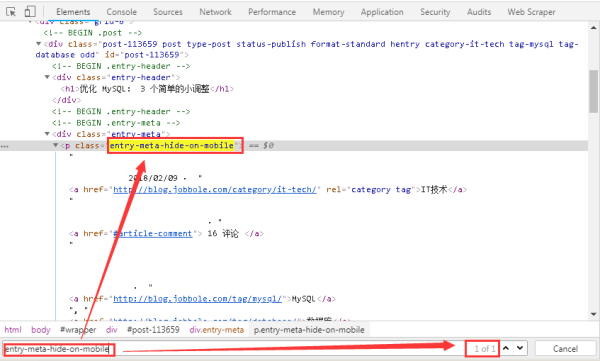
3гҖҒжҺҘдёӢжқҘжҳҜеҸ‘еёғж—Ҙжңҹзҡ„жҸҗеҸ–пјҢд»Қ然жҳҜд»ҘдәӨдә’ејҸзҡ„ж–№ејҸе®һзҺ°зҪ‘йЎөдёҺжәҗз Ғд№Ӣй—ҙзҡ„дәӨдә’пјҢе…¶дёӯж ҮзӯҫвҖңentry-meta-hide-on-mobileвҖқе…·жңүе…ЁеұҖе”ҜдёҖжҖ§пјҢеҸҜд»ҘеҫҲж–№дҫҝзҡ„е®ҡдҪҚеҲ°е…ғзҙ пјҢеҰӮдёӢеӣҫжүҖзӨәгҖӮ
4гҖҒж №жҚ®зҪ‘йЎөз»“жһ„пјҢжҲ‘们еҸҜиҪ»жҳ“зҡ„еҶҷеҮәеҸ‘еёғж—Ҙжңҹзҡ„CSSиЎЁиҫҫејҸпјҢеҸҜд»ҘеңЁscrapy shellдёӯе…ҲиҝӣиЎҢжөӢиҜ•пјҢеҶҚе°ҶйҖүжӢ©еҷЁиЎЁиҫҫејҸеҶҷе…ҘзҲ¬иҷ«ж–Ү件дёӯпјҢиҜҰжғ…еҰӮдёӢеӣҫжүҖзӨәгҖӮ

5гҖҒе…ідәҺж–Үз« дё»йўҳж Үзӯҫзҡ„CSSиЎЁиҫҫејҸпјҢеҸҜд»ҘзңӢеҲ°е…¶еңЁзҪ‘йЎөз»“жһ„дёҠеӨ„дәҺж—Ҙжңҹзҡ„дёӢж–№пјҢеҰӮдёӢеӣҫжүҖзӨәгҖӮ
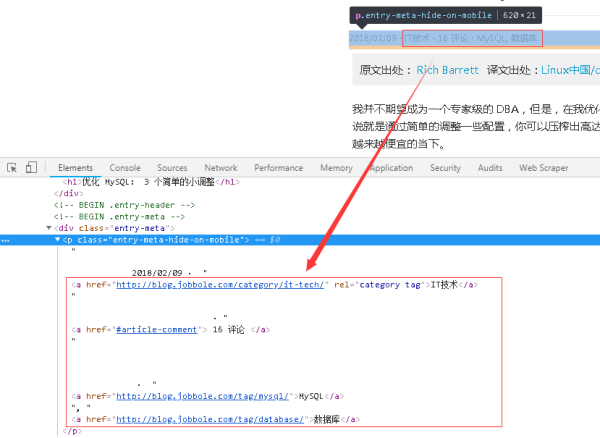
6гҖҒйҖҡиҝҮжӣҙж”№дёҖдёӢеҸ‘еёғж—Ҙжңҹзҡ„CSSиЎЁиҫҫејҸпјҢеҚіеҸҜиҺ·еҸ–еҲ°ж–Үз« дё»йўҳж ҮзӯҫгҖӮж–Үз« дё»йўҳж ҮзӯҫеӨ„дәҺaж ҮзӯҫдёӢпјҢеҰӮдёӢеӣҫжүҖзӨәгҖӮ
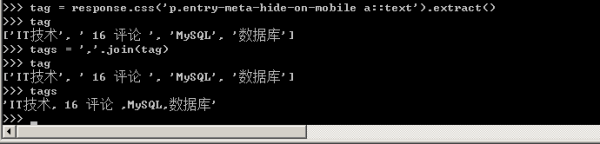
иҺ·еҸ–еҲ°ж•ҙдёӘеҲ—иЎЁд№ӢеҗҺпјҢеҲ©з”ЁjoinеҮҪж•°е°Ҷж•°з»„дёӯзҡ„е…ғзҙ д»ҘйҖ—еҸ·иҝһжҺҘз”ҹжҲҗдёҖдёӘж–°зҡ„еӯ—з¬ҰдёІеҸ«tagsпјҢ然еҗҺеҶҷе…ҘScrapyзҲ¬иҷ«ж–Ү件дёӯеҺ»гҖӮ
7гҖҒеҜ№дәҺзӮ№иөһж•°пјҢе…¶еҲҶжһҗж–№жі•еҗҢд№ӢеүҚдёҖиҮҙпјҢжүҫеҲ°е”ҜдёҖзҡ„дёҖдёӘж ҮзӯҫвҖңvote-post-upвҖқеҚіеҸҜе®ҡдҪҚеҲ°ж•°жҚ®гҖӮ
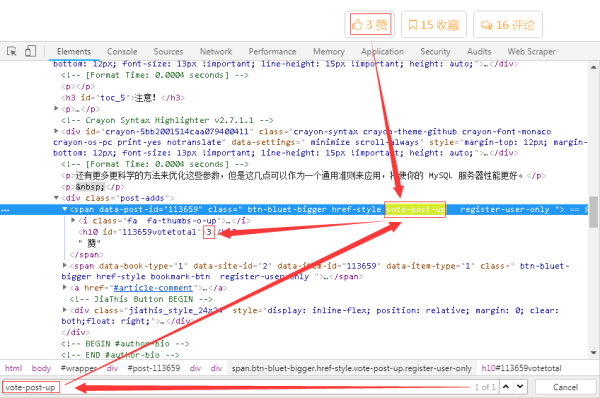
8гҖҒзӮ№иөһж•°еңЁh20ж ҮзӯҫдёӢпјҢж №жҚ®зҪ‘йЎөз»“жһ„еҶҷеҮәCSSиЎЁиҫҫејҸпјҢи°ғиҜ•зҡ„иҝҮзЁӢеҰӮдёӢеӣҫжүҖзӨәгҖӮ

еҸ–еҮәзҡ„зӮ№иөһж•°жҳҜдёӘеӯ—з¬ҰдёІпјҢйңҖиҰҒеҲ©з”Ёint()е°Ҷе…¶ејәеҲ¶иҪ¬жҚўдёәж•°еӯ—гҖӮ
еҲ°жӯӨпјҢе…ідәҺвҖңеңЁScrapyдёӯжҖҺд№ҲеҲ©з”ЁCSSйҖүжӢ©еҷЁд»ҺзҪ‘йЎөдёӯйҮҮйӣҶзӣ®ж Үж•°жҚ®вҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ