жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңPythonжҖҺд№ҲиҜҶеҲ«еӣҫеғҸвҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁPythonжҖҺд№ҲиҜҶеҲ«еӣҫеғҸй—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқPythonжҖҺд№ҲиҜҶеҲ«еӣҫеғҸвҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
жҲ‘зңӢи§Ғзҡ„ж—¶еҖҷиҮӘ然дјҡзҹҘйҒ“
еҸӘйңҖиҰҒ10еҮ иЎҢPythonд»Јз ҒпјҢдҪ е°ұиғҪжһ„е»әиҮӘе·ұзҡ„жңәеҷЁи§Ҷи§үжЁЎеһӢпјҢеҝ«йҖҹеҮҶзЎ®иҜҶеҲ«жө·йҮҸеӣҫзүҮгҖӮеҝ«жқҘиҜ•иҜ•еҗ§пјҒ
0гҖҒи§Ҷи§ү
иҝӣеҢ–зҡ„дҪңз”ЁпјҢи®©дәәзұ»еҜ№еӣҫеғҸзҡ„еӨ„зҗҶйқһеёёй«ҳж•ҲгҖӮ
иҝҷйҮҢпјҢжҲ‘з»ҷдҪ еұ•зӨәдёҖеј з…§зүҮгҖӮ

еҰӮжһңжҲ‘иҝҷж ·й—®дҪ пјҡ
дҪ иғҪеҗҰеҲҶиҫЁеҮәеӣҫзүҮдёӯе“ӘдёӘжҳҜзҢ«пјҢе“ӘдёӘжҳҜзӢ—пјҹ
дҪ еҸҜиғҪз«ӢеҚідјҡи§үеҫ—иҮӘе·ұйҒӯеҸ—еҲ°дәҶиҺ«еӨ§зҡ„дҫ®иҫұгҖӮ并且еӨ§еЈ°иҙЁй—®жҲ‘пјҡдҪ и§үеҫ—жҲ‘жҷәе•Ҷжңүй—®йўҳеҗ—пјҹпјҒ
жҒҜжҖ’гҖӮ
жҚўдёҖдёӘй—®жі•пјҡ
дҪ иғҪеҗҰжҠҠиҮӘе·ұеҲҶиҫЁзҢ«зӢ—еӣҫзүҮзҡ„ж–№жі•пјҢжҸҸиҝ°жҲҗдёҘж јзҡ„规еҲҷпјҢж•ҷз»ҷи®Ўз®—жңәпјҢд»Ҙдҫҝи®©е®ғжӣҝжҲ‘们дәәзұ»еҲҶиҫЁжҲҗеҚғдёҠдёҮеј еӣҫзүҮе‘ўпјҹ
еҜ№еӨ§еӨҡж•°дәәжқҘиҜҙпјҢжӯӨж—¶ж„ҹеҸ—еҲ°зҡ„пјҢе°ұдёҚжҳҜзҫһиҫұпјҢиҖҢжҳҜеҺӢеҠӣдәҶгҖӮ
еҰӮжһңдҪ жҳҜдёӘжңүжҜ…еҠӣзҡ„дәәпјҢеҸҜиғҪдјҡе°қиҜ•еҗ„з§ҚеҲӨеҲ«ж ҮеҮҶпјҡеӣҫзүҮжҹҗдёӘдҪҚзҪ®зҡ„еғҸзҙ йўңиүІгҖҒжҹҗдёӘеұҖйғЁзҡ„иҫ№зјҳеҪўзҠ¶гҖҒжҹҗдёӘж°ҙе№ідҪҚзҪ®зҡ„иҝһз»ӯйўңиүІй•ҝеәҰ……
дҪ жҠҠиҝҷдәӣжҸҸиҝ°е‘ҠиҜүи®Ўз®—жңәпјҢе®ғжһң然е°ұеҸҜд»ҘеҲӨж–ӯеҮәе·Ұиҫ№зҡ„зҢ«е’ҢеҸіиҫ№зҡ„зӢ—дәҶгҖӮ
й—®йўҳжҳҜпјҢи®Ўз®—жңәзңҹзҡ„дјҡеҲҶиҫЁзҢ«зӢ—еӣҫзүҮдәҶеҗ—пјҹ
жҲ‘еҸҲжӢҝеҮәдёҖеј з…§зүҮз»ҷдҪ гҖӮ

дҪ дјҡеҸ‘зҺ°пјҢеҮ д№ҺжүҖжңүзҡ„规еҲҷе®ҡд№үпјҢйғҪйңҖиҰҒж”№еҶҷгҖӮ
еҪ“жңәеҷЁеҘҪдёҚе®№жҳ“еҸҜд»Ҙз”Ёиҝ‘дјјжҠ•жңәеҸ–е·§зҡ„ж–№жі•жӯЈзЎ®еҲҶиҫЁдәҶиҝҷдёӨеј еӣҫзүҮйҮҢйқўзҡ„еҠЁзү©ж—¶пјҢжҲ‘еҸҲжӢҝеҮәжқҘдёҖеј ж–°еӣҫзүҮ……

еҮ дёӘе°Ҹж—¶д»ҘеҗҺпјҢдҪ еҶіе®ҡж”ҫејғгҖӮ
еҲ«ж°”йҰҒгҖӮ
дҪ йҒӯйҒҮеҲ°зҡ„пјҢ并дёҚжҳҜж–°й—®йўҳгҖӮе°ұиҝһеӨ§жі•е®ҳпјҢд№ҹжңүиҝҮеҗҢж ·зҡ„зғҰжҒјгҖӮ

1964е№ҙпјҢзҫҺеӣҪ***жі•йҷўзҡ„еӨ§жі•е®ҳPotter StewartеңЁвҖңJacobellis v. OhioвҖқдёҖжЎҲдёӯпјҢжӣҫз»Ҹе°ұжҹҗйғЁз”өеҪұдёӯеҮәзҺ°зҡ„жҹҗз§Қе…·дҪ“еӣҫеғҸеҲҶзұ»й—®йўҳпјҢиҜҙиҝҮдёҖеҸҘеҗҚиЁҖвҖңжҲ‘дёҚеҮҶеӨҮе°ұе…¶жҰӮеҝөз»ҷеҮәз®ҖзҹӯиҖҢжҳҺзЎ®зҡ„е®ҡд№ү……дҪҶжҳҜпјҢжҲ‘зңӢи§Ғзҡ„ж—¶еҖҷиҮӘ然дјҡзҹҘйҒ“вҖқпјҲI know it when I see itпјүгҖӮ
еҺҹж–ҮеҰӮдёӢпјҡ
I shall not today attempt further to define the kinds of material I understand to be embraced within that shorthand description (вҖңhard-core pornographyвҖқ), and perhaps I could never succeed in intelligibly doing so. But I know it when I see it, and the motion picture involved in this case is not that.
иҖғиҷ‘еҲ°зІҫзҘһж–ҮжҳҺе»әи®ҫзҡ„йңҖиҰҒпјҢиҝҷдёҖж®өе°ұдёҚзҝ»иҜ‘дәҶгҖӮ
дәәзұ»жІЎжі•жҠҠеӣҫзүҮеҲҶиҫЁзҡ„规еҲҷиҜҰз»ҶгҖҒе…·дҪ“иҖҢеҮҶзЎ®ең°жҸҸиҝ°з»ҷи®Ўз®—жңәпјҢжҳҜдёҚжҳҜж„Ҹе‘ізқҖи®Ўз®—жңәдёҚиғҪиҫЁиҜҶеӣҫзүҮе‘ўпјҹ
еҪ“然дёҚжҳҜгҖӮ
2017е№ҙ12жңҲд»Ҫзҡ„гҖҠ科еӯҰзҫҺеӣҪдәәгҖӢжқӮеҝ—пјҢе°ұжҠҠвҖңи§Ҷи§үдәәе·ҘжҷәиғҪвҖқпјҲAI that sees like humansпјүе®ҡд№үдёә2017е№ҙж–°е…ҙжҠҖжңҜд№ӢдёҖгҖӮ

дҪ ж—©е·Іеҗ¬иҜҙиҝҮиҮӘеҠЁй©ҫ驶жұҪиҪҰзҡ„зҘһеҘҮеҗ§пјҹжІЎжңүжңәеҷЁеҜ№еӣҫеғҸзҡ„иҫЁиҜҶпјҢиғҪеҒҡеҲ°еҗ—пјҹ
дҪ зҡ„еҘҪеҸӢеҸҜиғҪпјҲдёҚжӯўдёҖж¬Ўпјүз»ҷдҪ жј”зӨәеҰӮдҪ•з”Ёж–°д№°зҡ„iPhone XеҒҡйқўйғЁиҜҶеҲ«и§Јй”ҒдәҶеҗ§пјҹжІЎжңүжңәеҷЁеҜ№еӣҫеғҸзҡ„иҫЁиҜҶпјҢиғҪеҒҡеҲ°еҗ—пјҹ

еҢ»еӯҰйўҶеҹҹйҮҢпјҢи®Ўз®—жңәеҜ№дәҺ科еӯҰеҪұеғҸпјҲеҰӮXе…үзүҮпјүзҡ„еҲҶжһҗиғҪеҠӣпјҢе·Із»Ҹи¶…иҝҮжңүеӨҡе№ҙд»Һдёҡз»ҸйӘҢзҡ„еҢ»з”ҹдәҶгҖӮжІЎжңүжңәеҷЁеҜ№еӣҫеғҸзҡ„иҫЁиҜҶпјҢиғҪеҒҡеҲ°еҗ—пјҹ
дҪ еҸҜиғҪдёҖдёӢеӯҗи§үеҫ—жңүдәӣиҝ·иҢ«дәҶ——иҝҷйҡҫйҒ“жҳҜеҘҮиҝ№пјҹ
дёҚжҳҜгҖӮ
и®Ўз®—жңәжүҖеҒҡзҡ„пјҢжҳҜеӯҰд№ гҖӮ
йҖҡиҝҮеӯҰд№ и¶іеӨҹж•°йҮҸзҡ„ж ·жң¬пјҢжңәеҷЁеҸҜд»Ҙд»Һж•°жҚ®дёӯиҮӘе·ұжһ„е»әжЁЎеһӢгҖӮе…¶дёӯпјҢеҸҜиғҪж¶үеҸҠеӨ§йҮҸзҡ„еҲӨж–ӯеҮҶеҲҷгҖӮдҪҶжҳҜпјҢдәәзұ»дёҚйңҖиҰҒе‘ҠиҜүжңәеҷЁд»»дҪ•дёҖжқЎгҖӮе®ғжҳҜе®Ңе…ЁиҮӘе·ұйўҶжӮҹе’ҢжҺҢжҸЎзҡ„гҖӮ
дҪ еҸҜиғҪдјҡи§үеҫ—еҫҲе…ҙеҘӢгҖӮ
йӮЈд№ҲпјҢдёӢйқўжҲ‘жқҘе‘ҠиҜүдҪ дёҖдёӘжӣҙд»ӨдҪ е…ҙеҘӢзҡ„ж¶ҲжҒҜ——дҪ иҮӘе·ұд№ҹиғҪеҫҲиҪ»жҳ“ең°жһ„е»әеӣҫзүҮеҲҶзұ»зі»з»ҹпјҒ
дёҚдҝЎпјҹиҜ·и·ҹзқҖжҲ‘дёӢйқўзҡ„д»Ӣз»ҚпјҢжқҘиҜ•иҜ•зңӢгҖӮ
1гҖҒж•°жҚ®
е’ұ们е°ұдёҚиҫЁиҜҶзҢ«е’ҢзӢ—дәҶпјҢиҝҷдёӘй—®йўҳжңүзӮ№дёҚеӨҹж–°йІңгҖӮ
е’ұ们жқҘеҲҶиҫЁжңәеҷЁзҢ«пјҢеҘҪдёҚеҘҪпјҹ
еҜ№пјҢжҲ‘иҜҙзҡ„е°ұжҳҜе“Ҷе•ҰaжўҰгҖӮ

жҠҠе®ғе’Ңи°ҒиҝӣиЎҢеҢәеҲҶе‘ўпјҹ
дёҖејҖе§ӢжҲ‘жғіжүҫйңёзҺӢйҫҷпјҢеҗҺжқҘи§үеҫ—иҝҷж ·з®ҖзӣҙжҳҜдҪңејҠпјҢеӣ дёәд»–дҝ©й•ҝеҫ—е®һеңЁе·®еҲ«еӨӘеӨ§гҖӮ

既然е“Ҷе•ҰaжўҰжҳҜжңәеҷЁдәәпјҢе’ұ们е°ұеҸҰеӨ–жүҫдёӘжңәеҷЁдәәжқҘеҢәеҲҶеҗ§гҖӮ
дёҖжҸҗеҲ°жңәеҷЁдәәпјҢжҲ‘з«ӢеҲ»е°ұжғіиө·жқҘдәҶе®ғгҖӮ

еҜ№пјҢжңәеҷЁдәәз“ҰеҠӣпјҲWALLEпјүгҖӮ
жҲ‘з»ҷдҪ еҮҶеӨҮеҘҪдәҶ119еј е“Ҷе•ҰaжўҰзҡ„з…§зүҮпјҢе’Ң80еј з“ҰеҠӣзҡ„з…§зүҮгҖӮеӣҫзүҮе·Із»ҸдёҠдј еҲ°дәҶиҝҷдёӘGithubйЎ№зӣ®пјҲhttps://link.jianshu.com/?t=https%3A%2F%2Fgithub.com%2Fwshuyi%2Fdemo-python-image-classificationпјүгҖӮ
иҜ·зӮ№еҮ»иҝҷдёӘй“ҫжҺҘпјҲhttps://link.jianshu.com/?t=https%3A%2F%2Fgithub.com%2Fwshuyi%2Fdemo-python-image-classification%2Farchive%2Fmaster.zipпјүпјҢдёӢиҪҪеҺӢзј©еҢ…гҖӮ然еҗҺеңЁжң¬ең°и§ЈеҺӢгҖӮдҪңдёәе’ұ们зҡ„жј”зӨәзӣ®еҪ•гҖӮ
и§ЈеҺӢеҗҺпјҢдҪ дјҡзңӢеҲ°зӣ®еҪ•дёӢжңүдёӘimageж–Ү件еӨ№пјҢе…¶дёӯеҢ…еҗ«дёӨдёӘеӯҗзӣ®еҪ•пјҢеҲҶеҲ«жҳҜdoraemonе’ҢwalleгҖӮ
жү“ејҖе…¶дёӯdoraemonзҡ„зӣ®еҪ•пјҢжҲ‘们зңӢзңӢйғҪжңүе“ӘдәӣеӣҫзүҮгҖӮ

еҸҜд»ҘзңӢеҲ°пјҢе“Ҷе•ҰaжўҰзҡ„еӣҫзүҮзңҹжҳҜдә”иҠұе…«й—ЁгҖӮеҗ„з§ҚеңәжҷҜгҖҒиғҢжҷҜйўңиүІгҖҒиЎЁжғ…гҖҒеҠЁдҪңгҖҒи§’еәҰ……дёҚдёҖиҖҢи¶ігҖӮ
иҝҷдәӣеӣҫзүҮпјҢеӨ§е°ҸдёҚдёҖпјҢй•ҝе®ҪжҜ”дҫӢд№ҹеҗ„дёҚзӣёеҗҢгҖӮ
жҲ‘们еҶҚжқҘзңӢзңӢз“ҰеҠӣпјҢд№ҹжҳҜзұ»дјјзҡ„зҠ¶еҶөгҖӮ
ж•°жҚ®е·Із»ҸжңүдәҶпјҢдёӢйқўжҲ‘们жқҘеҮҶеӨҮдёҖдёӢзҺҜеўғй…ҚзҪ®гҖӮ
2гҖҒзҺҜеўғ
жҲ‘们дҪҝз”ЁPythonйӣҶжҲҗиҝҗиЎҢзҺҜеўғAnacondaгҖӮ
иҜ·еҲ°иҝҷдёӘзҪ‘еқҖпјҲhttps://link.jianshu.com/?t=https%3A%2F%2Fwww.continuum.io%2Fdownloadsпјү дёӢиҪҪ***зүҲзҡ„AnacondaгҖӮ
дёӢжӢүйЎөйқўпјҢжүҫеҲ°дёӢиҪҪдҪҚзҪ®гҖӮж №жҚ®дҪ зӣ®еүҚдҪҝз”Ёзҡ„зі»з»ҹпјҢзҪ‘з«ҷдјҡиҮӘеҠЁжҺЁиҚҗз»ҷдҪ йҖӮеҗҲзҡ„зүҲжң¬дёӢиҪҪгҖӮжҲ‘дҪҝз”Ёзҡ„жҳҜmacOSпјҢдёӢиҪҪж–Үд»¶ж јејҸдёәpkgгҖӮ

дёӢиҪҪйЎөйқўеҢәе·Ұдҫ§жҳҜPython 3.6зүҲпјҢеҸідҫ§жҳҜ2.7зүҲгҖӮиҜ·йҖүжӢ©2.7зүҲжң¬гҖӮ
еҸҢеҮ»дёӢиҪҪеҗҺзҡ„pkgж–Ү件пјҢж №жҚ®дёӯж–ҮжҸҗзӨәдёҖжӯҘжӯҘе®үиЈ…еҚіеҸҜгҖӮ
е®үиЈ…еҘҪAnacondaеҗҺпјҢжҲ‘们йңҖиҰҒе®үиЈ…TuriCreateгҖӮ
иҜ·еҲ°дҪ зҡ„вҖңз»Ҳз«ҜвҖқпјҲLinux, macOSпјүжҲ–иҖ…вҖңе‘Ҫд»ӨжҸҗзӨәз¬ҰвҖқпјҲWindowsпјүдёӢйқўпјҢиҝӣе…Ҙе’ұ们еҲҡеҲҡдёӢиҪҪи§ЈеҺӢеҗҺзҡ„ж ·дҫӢзӣ®еҪ•гҖӮ
жү§иЎҢд»ҘдёӢе‘Ҫд»ӨпјҢжҲ‘们жқҘеҲӣе»әдёҖдёӘAnacondaиҷҡжӢҹзҺҜеўғпјҢеҗҚеӯ—еҸ«еҒҡturiгҖӮ
然еҗҺпјҢжҲ‘们жҝҖжҙ»turiиҷҡжӢҹзҺҜеўғгҖӮ
еңЁиҝҷдёӘзҺҜеўғдёӯпјҢжҲ‘们е®үиЈ…***зүҲзҡ„TuriCreateгҖӮ
е®үиЈ…е®ҢжҜ•еҗҺпјҢжү§иЎҢпјҡ
иҝҷж ·е°ұиҝӣе…ҘеҲ°дәҶJupyter笔记жң¬зҺҜеўғгҖӮжҲ‘们新е»әдёҖдёӘPython 2笔记жң¬гҖӮ
иҝҷж ·е°ұеҮәзҺ°дәҶдёҖдёӘз©әзҷҪ笔记жң¬гҖӮ
зӮ№еҮ»е·ҰдёҠ角笔记жң¬еҗҚз§°пјҢдҝ®ж”№дёәжңүж„Ҹд№үзҡ„笔记жң¬еҗҚвҖңdemo-python-image-classificationвҖқгҖӮ
еҮҶеӨҮе·ҘдҪңе®ҢжҜ•пјҢдёӢйқўжҲ‘们е°ұеҸҜд»ҘејҖе§Ӣзј–еҶҷзЁӢеәҸдәҶгҖӮ
3гҖҒд»Јз Ғ
йҰ–е…ҲпјҢжҲ‘们иҜ»е…ҘTuriCreateиҪҜ件еҢ…гҖӮе®ғжҳҜиӢ№жһң并иҙӯжқҘзҡ„жңәеҷЁеӯҰд№ жЎҶжһ¶пјҢдёәејҖеҸ‘иҖ…жҸҗдҫӣйқһеёёз®Җдҫҝзҡ„ж•°жҚ®еҲҶжһҗдёҺдәәе·ҘжҷәиғҪжҺҘеҸЈгҖӮ
import turicreate as tc
жҲ‘们жҢҮе®ҡеӣҫеғҸжүҖеңЁзҡ„ж–Ү件еӨ№imageгҖӮ
img_folder = 'image'
еүҚйқўд»Ӣз»ҚдәҶпјҢimageдёӢпјҢжңүе“Ҷе•ҰaжўҰе’Ңз“ҰеҠӣиҝҷдёӨдёӘж–Ү件еӨ№гҖӮжіЁж„ҸеҰӮжһңе°ҶжқҘдҪ йңҖиҰҒиҫЁеҲ«е…¶д»–зҡ„еӣҫзүҮпјҲдҫӢеҰӮзҢ«е’ҢзӢ—пјүпјҢиҜ·жҠҠдёҚеҗҢзұ»еҲ«зҡ„еӣҫзүҮд№ҹеңЁimageдёӯеҲҶеҲ«еӯҳе…ҘдёҚеҗҢзҡ„ж–Ү件еӨ№пјҢиҝҷдәӣж–Ү件еӨ№зҡ„еҗҚз§°е°ұжҳҜеӣҫзүҮзҡ„зұ»еҲ«еҗҚ(catе’Ңdog)гҖӮ
然еҗҺпјҢжҲ‘们让TuriCreateиҜ»еҸ–жүҖжңүзҡ„еӣҫеғҸж–Ү件пјҢ并且еӯҳеӮЁеҲ°dataж•°жҚ®жЎҶгҖӮ
data = tc.image_analysis.load_images(img_folder, with_path=True)
иҝҷйҮҢеҸҜиғҪдјҡжңүй”ҷиҜҜдҝЎжҒҜгҖӮ
Unsupported image format. Supported formats are JPEG and PNG file: /Users/wsy/Dropbox/var/wsywork/learn/demo-workshops/demo-python-image-classification/image/walle/.DS_Store
жң¬дҫӢдёӯжҸҗзӨәпјҢжңүеҮ дёӘ.DS_Storeж–Ү件пјҢTuriCreateдёҚи®ӨиҜҶпјҢж— жі•еҪ“дҪңеӣҫзүҮжқҘиҜ»еҸ–гҖӮ
иҝҷдәӣ.DS_Storeж–Ү件пјҢжҳҜиӢ№жһңmacOSзі»з»ҹеҲӣе»әзҡ„йҡҗи—Ҹж–Ү件пјҢз”ЁжқҘдҝқеӯҳзӣ®еҪ•зҡ„иҮӘе®ҡд№үеұһжҖ§пјҢдҫӢеҰӮеӣҫж ҮдҪҚзҪ®жҲ–иғҢжҷҜйўңиүІгҖӮ
жҲ‘们еҝҪз•ҘиҝҷдәӣдҝЎжҒҜеҚіеҸҜгҖӮ
дёӢйқўпјҢжҲ‘们жқҘзңӢзңӢпјҢdataж•°жҚ®жЎҶйҮҢйқўйғҪжңүд»Җд№ҲгҖӮ
data
еҸҜд»ҘзңӢеҲ°пјҢdataеҢ…еҗ«дёӨеҲ—дҝЎжҒҜпјҢ***еҲ—жҳҜеӣҫзүҮзҡ„ең°еқҖпјҢ第дәҢеҲ—жҳҜеӣҫзүҮзҡ„й•ҝе®ҪжҸҸиҝ°гҖӮ
еӣ дёәжҲ‘们дҪҝз”ЁдәҶ119еј е“Ҷе•ҰaжўҰеӣҫзүҮпјҢ80еј з“ҰеҠӣеӣҫзүҮпјҢжүҖд»ҘжҖ»е…ұзҡ„ж•°жҚ®йҮҸжҳҜ199жқЎгҖӮж•°жҚ®иҜ»еҸ–е®Ңж•ҙжҖ§йӘҢиҜҒйҖҡиҝҮгҖӮ
дёӢйқўпјҢжҲ‘们йңҖиҰҒи®©TuriCreateдәҶи§ЈдёҚеҗҢеӣҫзүҮзҡ„ж Үи®°пјҲlabelпјүдҝЎжҒҜгҖӮд№ҹе°ұжҳҜпјҢдёҖеј еӣҫзүҮеҲ°еә•жҳҜе“Ҷе•ҰaжўҰпјҢиҝҳжҳҜз“ҰеҠӣе‘ўпјҹ
иҝҷе°ұжҳҜдёәд»Җд№ҲдёҖејҖе§ӢпјҢдҪ е°ұеҫ—жҠҠдёҚеҗҢзҡ„еӣҫзүҮеҲҶзұ»дҝқеӯҳеҲ°дёҚеҗҢзҡ„ж–Ү件еӨ№дёӢйқўгҖӮ
жӯӨж—¶пјҢжҲ‘们еҲ©з”Ёж–Ү件еӨ№еҗҚз§°пјҢжқҘз»ҷеӣҫзүҮжү“ж Үи®°гҖӮ
data['label'] = data['path'].apply(lambda path: 'doraemon' if 'doraemon' in path else 'walle')
иҝҷжқЎиҜӯеҸҘпјҢжҠҠdoraemonзӣ®еҪ•дёӢзҡ„еӣҫзүҮпјҢеңЁdataж•°жҚ®жЎҶйҮҢжү“ж Үи®°дёәdoraemonгҖӮеҸҚд№Ӣе°ұйғҪи§Ҷдёәз“ҰеҠӣпјҲwalleпјүгҖӮ
жҲ‘们жқҘзңӢзңӢж Үи®°д№ӢеҗҺзҡ„dataж•°жҚ®жЎҶгҖӮ
data
еҸҜд»ҘзңӢеҲ°пјҢж•°жҚ®зҡ„жқЎзӣ®ж•°йҮҸпјҲиЎҢж•°пјүжҳҜдёҖиҮҙзҡ„пјҢеҸӘжҳҜеӨҡеҮәжқҘдәҶдёҖдёӘж Үи®°еҲ—пјҲlabelпјүпјҢиҜҙжҳҺеӣҫзүҮзҡ„зұ»еҲ«гҖӮ
жҲ‘们жҠҠж•°жҚ®еӯҳеӮЁдёҖдёӢгҖӮ
data.save('doraemon-walle.sframe')иҝҷдёӘеӯҳеӮЁеҠЁдҪңпјҢи®©жҲ‘们дҝқеӯҳеҲ°зӣ®еүҚзҡ„ж•°жҚ®еӨ„зҗҶз»“жһңгҖӮд№ӢеҗҺзҡ„еҲҶжһҗпјҢеҸӘйңҖиҰҒиҜ»е…ҘиҝҷдёӘsframeж–Ү件е°ұеҸҜд»ҘдәҶпјҢдёҚйңҖиҰҒд»ҺеӨҙеҺ»и·ҹж–Ү件еӨ№жү“дәӨйҒ“дәҶгҖӮ
д»ҺиҝҷдёӘдҫӢеӯҗйҮҢпјҢдҪ еҸҜиғҪзңӢдёҚеҮәд»Җд№ҲдјҳеҠҝгҖӮдҪҶжҳҜжғіиұЎдёҖдёӢпјҢеҰӮжһңдҪ зҡ„еӣҫзүҮжңүеҘҪеҮ дёӘGпјҢз”ҡиҮіеҮ дёӘTпјҢжҜҸж¬ЎеҒҡеҲҶжһҗеӨ„зҗҶпјҢйғҪд»ҺеӨҙиҜ»еҸ–ж–Ү件е’Ңжү“ж Үи®°пјҢе°ұдјҡйқһеёёиҖ—ж—¶гҖӮ
жҲ‘们ж·ұе…ҘжҺўзҙўдёҖдёӢж•°жҚ®жЎҶгҖӮ
TuriCreateжҸҗдҫӣдәҶйқһеёёж–№дҫҝзҡ„explore()еҮҪж•°пјҢеё®еҠ©жҲ‘们зӣҙи§ӮжҺўзҙўж•°жҚ®жЎҶдҝЎжҒҜгҖӮ
data.explore()
иҝҷж—¶еҖҷпјҢTuriCreateдјҡеј№еҮәдёҖдёӘйЎөйқўпјҢз»ҷжҲ‘们еұ•зӨәж•°жҚ®жЎҶйҮҢйқўзҡ„еҶ…е®№гҖӮ
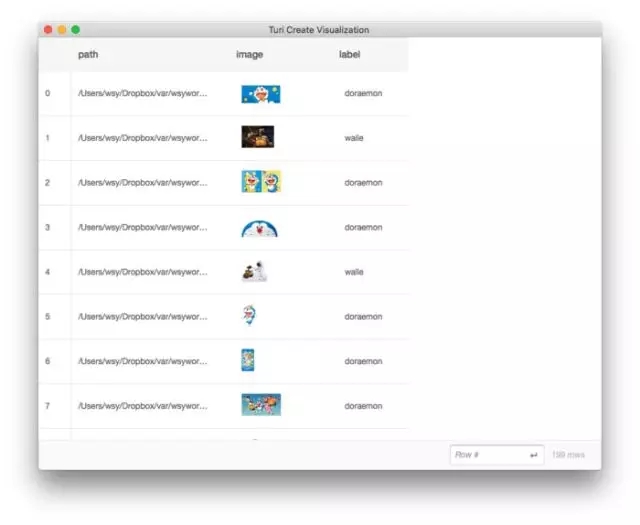
еҺҹе…Ҳжү“еҚ°dataж•°жҚ®жЎҶпјҢжҲ‘们еҸӘиғҪзңӢеҲ°еӣҫзүҮзҡ„е°әеҜёпјҢжӯӨж—¶еҚҙеҸҜд»ҘжөҸи§ҲеӣҫзүҮзҡ„еҶ…е®№гҖӮ
еҰӮжһңдҪ и§үеҫ—еӣҫзүҮеӨӘе°ҸпјҢжІЎе…ізі»гҖӮжҠҠйј ж ҮжӮ¬еҒңеңЁжҹҗеј зј©з•ҘеӣҫдёҠйқўпјҢе°ұеҸҜд»ҘзңӢеҲ°еӨ§еӣҫгҖӮ

ж•°жҚ®жЎҶжҺўзҙўе®ҢжҜ•гҖӮжҲ‘们еӣһеҲ°notebookдёӢйқўпјҢ继з»ӯеҶҷд»Јз ҒгҖӮ
иҝҷйҮҢжҲ‘们让TuriCreateжҠҠdataж•°жҚ®жЎҶеҲҶдёәи®ӯз»ғйӣҶеҗҲе’ҢжөӢиҜ•йӣҶеҗҲгҖӮ
train_data, test_data = data.random_split(0.8, seed=2)
и®ӯз»ғйӣҶеҗҲжҳҜз”ЁжқҘи®©жңәеҷЁиҝӣиЎҢи§ӮеҜҹеӯҰд№ зҡ„гҖӮз”өи„‘дјҡеҲ©з”Ёи®ӯз»ғйӣҶеҗҲзҡ„ж•°жҚ®иҮӘе·ұе»әз«ӢжЁЎеһӢгҖӮдҪҶжҳҜжЁЎеһӢзҡ„ж•ҲжһңпјҲдҫӢеҰӮеҲҶзұ»зҡ„еҮҶзЎ®зЁӢеәҰпјүеҰӮдҪ•пјҹжҲ‘们йңҖиҰҒз”ЁжөӢиҜ•йӣҶжқҘиҝӣиЎҢйӘҢиҜҒжөӢиҜ•гҖӮ
иҝҷе°ұеҰӮеҗҢиҖҒеёҲдёҚеә”иҜҘжҠҠиҖғиҜ•йўҳзӣ®йғҪжӢҝжқҘз»ҷеӯҰз”ҹеҒҡдҪңдёҡе’Ңз»ғд№ дёҖж ·гҖӮеҸӘжңүиҖғеӯҰз”ҹжІЎи§ҒиҝҮзҡ„йўҳпјҢжүҚиғҪеҢәеҲҶеӯҰз”ҹжҳҜжҺҢжҸЎдәҶжӯЈзЎ®зҡ„и§Јйўҳж–№жі•пјҢиҝҳжҳҜжӯ»и®°зЎ¬иғҢдәҶдҪңдёҡзӯ”жЎҲгҖӮ
жҲ‘们让TuriCreateжҠҠ80%зҡ„ж•°жҚ®еҲҶз»ҷдәҶи®ӯз»ғйӣҶпјҢжҠҠеү©дҪҷ20%зҡ„ж•°жҚ®жӢҝеҲ°дёҖиҫ№пјҢзӯүеҫ…жөӢиҜ•гҖӮиҝҷйҮҢжҲ‘и®ҫе®ҡдәҶйҡҸжңәз§ҚеӯҗеҸ–еҖјдёә2пјҢиҝҷжҳҜдёәдәҶдҝқиҜҒж•°жҚ®жӢҶеҲҶзҡ„дёҖиҮҙжҖ§гҖӮд»ҘдҫҝйҮҚеӨҚйӘҢиҜҒжҲ‘们зҡ„з»“жһңгҖӮ
еҘҪдәҶпјҢдёӢйқўжҲ‘们让жңәеҷЁејҖе§Ӣи§ӮеҜҹеӯҰд№ и®ӯз»ғйӣҶдёӯзҡ„жҜҸдёҖдёӘж•°жҚ®пјҢ并且е°қиҜ•иҮӘе·ұе»әз«ӢжЁЎеһӢгҖӮ
дёӢйқўд»Јз Ғ***ж¬Ўжү§иЎҢзҡ„ж—¶еҖҷпјҢйңҖиҰҒзӯүеҖҷдёҖж®өж—¶й—ҙгҖӮеӣ дёәTuriCreateйңҖиҰҒд»ҺиӢ№жһңејҖеҸ‘иҖ…е®ҳзҪ‘дёҠдёӢиҪҪдёҖдәӣж•°жҚ®гҖӮиҝҷдәӣж•°жҚ®еӨ§жҰӮ100Mе·ҰеҸігҖӮ
йңҖиҰҒзҡ„ж—¶й•ҝпјҢдҫқдҪ е’ҢиӢ№жһңжңҚеҠЎеҷЁзҡ„иҝһжҺҘйҖҹеәҰиҖҢејӮгҖӮеҸҚжӯЈеңЁжҲ‘иҝҷе„ҝпјҢдёӢиҪҪжҢәж…ўзҡ„гҖӮ
еҘҪеңЁеҸӘжңү***ж¬ЎйңҖиҰҒдёӢиҪҪгҖӮд№ӢеҗҺзҡ„йҮҚеӨҚжү§иЎҢпјҢдјҡи·іиҝҮдёӢиҪҪжӯҘйӘӨгҖӮ
model = tc.image_classifier.create(train_data, target='label')
дёӢиҪҪе®ҢжҜ•еҗҺпјҢдҪ дјҡзңӢеҲ°TuriCreateзҡ„и®ӯз»ғдҝЎжҒҜгҖӮ
Resizing images... Performing feature extraction on resized images... Completed 168/168 PROGRESS: Creating a validation set from 5 percent of training data. This may take a while. You can set ``validation_set=None`` to disable validation tracking.
дҪ дјҡеҸ‘зҺ°пјҢTuriCreatehдјҡеё®еҠ©дҪ жҠҠеӣҫзүҮиҝӣиЎҢе°әеҜёеҸҳжҚўпјҢ并且иҮӘеҠЁжҠ“еҸ–еӣҫзүҮзҡ„зү№еҫҒгҖӮ然еҗҺе®ғдјҡд»Һи®ӯз»ғйӣҶйҮҢйқўжҠҪеҸ–5%зҡ„ж•°жҚ®дҪңдёәйӘҢиҜҒйӣҶпјҢдёҚж–ӯиҝӯд»ЈеҜ»жүҫ***зҡ„еҸӮж•°й…ҚзҪ®пјҢиҫҫеҲ°***жЁЎеһӢгҖӮ
иҝҷйҮҢеҸҜиғҪдјҡжңүдёҖдәӣиӯҰе‘ҠдҝЎжҒҜпјҢеҝҪз•Ҙе°ұеҸҜд»ҘдәҶгҖӮ
еҪ“дҪ зңӢеҲ°дёӢеҲ—дҝЎжҒҜзҡ„ж—¶еҖҷпјҢж„Ҹе‘ізқҖи®ӯз»ғе·ҘдҪңе·Із»ҸйЎәеҲ©е®ҢжҲҗдәҶгҖӮ
еҸҜд»ҘзңӢеҲ°пјҢеҮ дёӘиҪ®ж¬ЎдёӢжқҘпјҢдёҚи®әжҳҜи®ӯз»ғзҡ„еҮҶзЎ®еәҰпјҢиҝҳжҳҜйӘҢиҜҒзҡ„еҮҶзЎ®еәҰпјҢйғҪе·Із»Ҹйқһеёёй«ҳдәҶгҖӮ

дёӢйқўпјҢжҲ‘们用иҺ·еҫ—зҡ„еӣҫзүҮеҲҶзұ»жЁЎеһӢпјҢжқҘеҜ№жөӢиҜ•йӣҶеҒҡйў„жөӢгҖӮ
predictions = model.predict(test_data)
жҲ‘们жҠҠйў„жөӢзҡ„з»“жһңпјҲдёҖзі»еҲ—еӣҫзүҮеҜ№еә”зҡ„ж Үи®°еәҸеҲ—пјүеӯҳе…ҘдәҶpredictionsеҸҳйҮҸгҖӮ
然еҗҺпјҢжҲ‘们让TuriCreateе‘ҠиҜүжҲ‘们пјҢеңЁжөӢиҜ•йӣҶдёҠпјҢжҲ‘们зҡ„жЁЎеһӢиЎЁзҺ°еҰӮдҪ•гҖӮ
е…ҲеҲ«жҖҘзқҖеҫҖдёӢзңӢпјҢзҢңзҢңз»“жһңжӯЈзЎ®зҺҮеӨ§жҰӮжҳҜеӨҡе°‘пјҹд»Һ0еҲ°1д№Ӣй—ҙпјҢзҢңжөӢдёҖдёӘж•°еӯ—гҖӮ
зҢңе®ҢеҗҺпјҢиҜ·з»§з»ӯгҖӮ
metrics = model.evaluate(test_data) print(metrics['accuracy'])
иҝҷе°ұжҳҜжӯЈзЎ®зҺҮзҡ„з»“жһңпјҡ
0.967741935484
жҲ‘***ж¬ЎзңӢи§Ғзҡ„ж—¶еҖҷпјҢйңҮжғҠдёҚе·ІгҖӮ
жҲ‘们еҸӘз”ЁдәҶ100еӨҡдёӘж•°жҚ®еҒҡдәҶи®ӯз»ғпјҢеұ…然е°ұиғҪеңЁжөӢиҜ•йӣҶпјҲжңәеҷЁжІЎжңүи§ҒиҝҮзҡ„еӣҫзүҮж•°жҚ®пјүдёҠпјҢиҺ·еҫ—еҰӮжӯӨй«ҳзҡ„иҫЁиҜҶеҮҶзЎ®еәҰгҖӮ
дёәдәҶйӘҢиҜҒиҝҷдёҚжҳҜеҮҶзЎ®зҺҮи®Ўз®—йғЁеҲҶд»Јз Ғзҡ„еӨұиҜҜпјҢжҲ‘们жқҘе®һйҷ…зңӢзңӢйў„жөӢз»“жһңгҖӮ
predictions
иҝҷжҳҜжү“еҚ°еҮәзҡ„йў„жөӢж Үи®°еәҸеҲ—пјҡ
dtype: str Rows: 31 ['doraemon', 'doraemon', 'doraemon', 'doraemon', 'walle', 'doraemon', 'walle', 'doraemon', 'walle', 'walle', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'walle', 'doraemon', 'doraemon', 'walle', 'walle', 'doraemon', 'doraemon', 'walle', 'walle', 'walle', 'doraemon', 'doraemon', 'walle', 'walle', 'doraemon', 'walle']
еҶҚзңӢзңӢе®һйҷ…зҡ„ж ҮзӯҫгҖӮ
test_data['label']
иҝҷжҳҜе®һйҷ…ж Үи®°еәҸеҲ—пјҡ
dtype: str Rows: 31 ['doraemon', 'doraemon', 'doraemon', 'doraemon', 'walle', 'doraemon', 'walle', 'walle', 'walle', 'walle', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'walle', 'doraemon', 'doraemon', 'walle', 'walle', 'doraemon', 'doraemon', 'walle', 'walle', 'walle', 'doraemon', 'doraemon', 'walle', 'walle', 'doraemon', 'walle']
жҲ‘们жҹҘжүҫдёҖдёӢпјҢеҲ°еә•е“ӘдәӣеӣҫзүҮйў„жөӢеӨұиҜҜдәҶгҖӮ
дҪ еҪ“然еҸҜд»ҘдёҖдёӘдёӘеҜ№жҜ”зқҖжЈҖжҹҘгҖӮдҪҶжҳҜеҰӮжһңдҪ зҡ„жөӢиҜ•йӣҶжңүжҲҗеҚғдёҠдёҮзҡ„ж•°жҚ®пјҢиҝҷж ·еҒҡж•ҲзҺҮе°ұдјҡеҫҲдҪҺгҖӮ
жҲ‘们еҲҶжһҗзҡ„ж–№жі•пјҢжҳҜйҰ–е…ҲжүҫеҮәйў„жөӢж Үи®°еәҸеҲ—пјҲpredictionsпјүе’ҢеҺҹе§Ӣж Үи®°еәҸеҲ—пјҲtest_data['label']пјүд№Ӣй—ҙжңүе“ӘдәӣдёҚдёҖиҮҙпјҢ然еҗҺеңЁжөӢиҜ•ж•°жҚ®йӣҶйҮҢеұ•зӨәиҝҷдәӣдёҚдёҖиҮҙзҡ„дҪҚзҪ®гҖӮ
test_data[test_data['label'] != predictions]

жҲ‘们еҸ‘зҺ°пјҢеңЁ31дёӘжөӢиҜ•ж•°жҚ®дёӯпјҢеҸӘжңү1еӨ„ж Үи®°йў„жөӢеҸ‘з”ҹдәҶеӨұиҜҜгҖӮеҺҹе§Ӣзҡ„ж Үи®°жҳҜз“ҰеҠӣпјҢжҲ‘们зҡ„жЁЎеһӢйў„жөӢз»“жһңжҳҜе“Ҷе•ҰaжўҰгҖӮ
жҲ‘们иҺ·еҫ—иҝҷдёӘж•°жҚ®зӮ№еҜ№еә”зҡ„еҺҹе§Ӣж–Ү件и·Ҝеҫ„гҖӮ
wrong_pred_img_path = test_data[predictions != test_data['label']][0]['path']
然еҗҺпјҢжҲ‘们жҠҠеӣҫеғҸиҜ»еҸ–еҲ°imgеҸҳйҮҸгҖӮ
img = tc.Image(wrong_pred_img_path)
з”ЁTuriCreateжҸҗдҫӣзҡ„show()еҮҪж•°пјҢжҲ‘们жҹҘзңӢдёҖдёӢиҝҷеј еӣҫзүҮзҡ„еҶ…е®№гҖӮ
img.show()
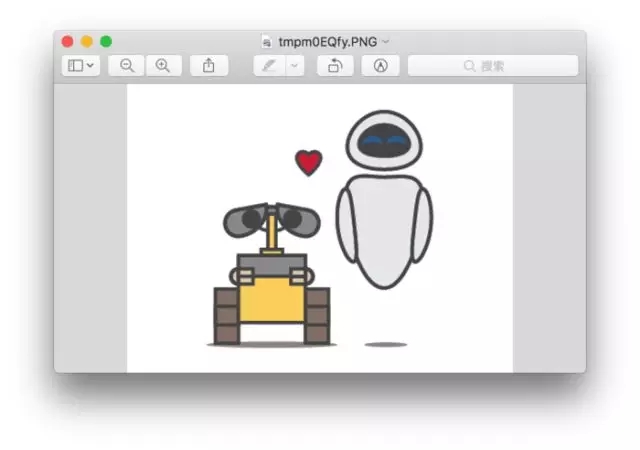
еӣ дёәж·ұеәҰеӯҰд№ зҡ„дёҖдёӘй—®йўҳеңЁдәҺжЁЎеһӢиҝҮдәҺеӨҚжқӮпјҢжүҖд»ҘжҲ‘д»¬ж— жі•зІҫзЎ®еҲӨеҲ«жңәеҷЁжҳҜжҖҺд№Ҳй”ҷиҜҜиҫЁиҜҶиҝҷеј еӣҫзҡ„гҖӮдҪҶжҳҜжҲ‘们дёҚйҡҫеҸ‘зҺ°иҝҷеј еӣҫзүҮжңүдәӣзү№еҫҒ——йҷӨдәҶз“ҰеҠӣд»ҘеӨ–пјҢиҝҳжңүеҸҰеӨ–дёҖдёӘжңәеҷЁдәәгҖӮ
еҰӮжһңдҪ зңӢиҝҮиҝҷйғЁз”өеҪұпјҢеә”иҜҘзҹҘйҒ“дёӨдёӘжңәеҷЁдәәд№Ӣй—ҙзҡ„е…ізі»гҖӮиҝҷйҮҢжҲ‘们жҢүдёӢдёҚиЎЁгҖӮй—®йўҳеңЁдәҺпјҢиҝҷдёӘеҸідёҠж–№зҡ„жңәеҷЁдәәеңҶеӨҙеңҶи„‘пјҢзңӢдёҠеҺ»дёҺжЈұи§’еҲҶжҳҺзҡ„з“ҰеҠӣе·®еҲ«еҫҲеӨ§гҖӮдҪҶжҳҜпјҢеҲ«еҝҳдәҶпјҢе“Ҷе•ҰaжўҰд№ҹжҳҜеңҶеӨҙеңҶи„‘зҡ„гҖӮ
4гҖҒеҺҹзҗҶ
жҢүз…§дёҠйқўдёҖиҠӮзҡ„д»Јз Ғжү§иЎҢеҗҺпјҢдҪ еә”иҜҘе·Із»ҸдәҶи§ЈеҰӮдҪ•жһ„е»әиҮӘе·ұзҡ„еӣҫзүҮеҲҶзұ»зі»з»ҹдәҶгҖӮеңЁжІЎжңүд»»дҪ•еҺҹзҗҶзҹҘиҜҶзҡ„жғ…еҶөдёӢпјҢдҪ з ”еҲ¶зҡ„иҝҷдёӘжЁЎеһӢе·Із»ҸеҒҡеҫ—йқһеёёжЈ’дәҶгҖӮдёҚжҳҜеҗ—пјҹ
еҰӮжһңдҪ еҜ№еҺҹзҗҶдёҚж„ҹе…ҙи¶ЈпјҢиҜ·и·іиҝҮиҝҷдёҖйғЁеҲҶпјҢзңӢвҖңе°Ҹз»“вҖқгҖӮ
еҰӮжһңдҪ еҜ№зҹҘиҜҶе–ңж¬ўеҲЁж №й—®еә•пјҢйӮЈе’ұ们жқҘи®Іи®ІеҺҹзҗҶгҖӮ
иҷҪ然дёҚиҝҮеҶҷдәҶ10еҮ иЎҢд»Јз ҒпјҢдҪҶжҳҜдҪ жһ„е»әзҡ„жЁЎеһӢеҚҙи¶іеӨҹеӨҚжқӮе’Ңй«ҳеӨ§дёҠгҖӮе®ғе°ұжҳҜдј иҜҙдёӯзҡ„еҚ·з§ҜзҘһз»ҸзҪ‘з»ңпјҲConvolutional Neural Network, CNNпјүгҖӮ
е®ғжҳҜж·ұеәҰжңәеҷЁеӯҰд№ жЁЎеһӢзҡ„дёҖз§ҚгҖӮжңҖдёәз®ҖеҚ•зҡ„еҚ·з§ҜзҘһз»ҸзҪ‘з»ңеӨ§жҰӮй•ҝиҝҷдёӘж ·еӯҗпјҡ
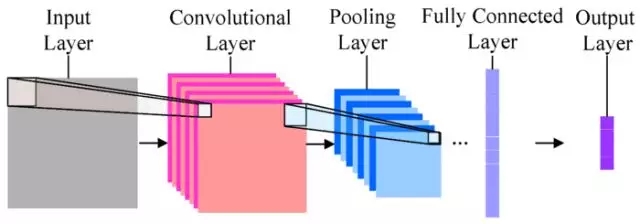
жңҖе·Ұиҫ№зҡ„пјҢжҳҜиҫ“е…ҘеұӮгҖӮд№ҹе°ұжҳҜе’ұ们иҫ“е…Ҙзҡ„еӣҫзүҮгҖӮжң¬дҫӢдёӯпјҢжҳҜе“Ҷе•ҰaжўҰе’Ңз“ҰеҠӣгҖӮ
еңЁи®Ўз®—жңәйҮҢпјҢеӣҫзүҮжҳҜжҢүз…§дёҚеҗҢйўңиүІпјҲRGBпјҢеҚіRed, Green, BlueпјүеҲҶеұӮеӯҳеӮЁзҡ„гҖӮе°ұеғҸдёӢйқўиҝҷдёӘдҫӢеӯҗгҖӮ
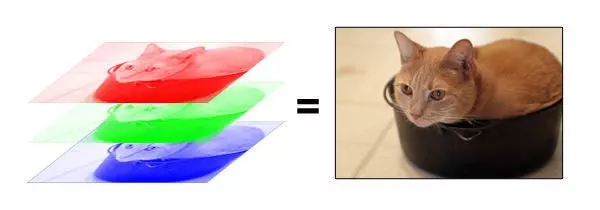
ж №жҚ®еҲҶиҫЁзҺҮдёҚеҗҢпјҢз”өи„‘дјҡжҠҠжҜҸдёҖеұӮзҡ„еӣҫзүҮеӯҳжҲҗжҹҗз§ҚеӨ§е°Ҹзҡ„зҹ©йҳөгҖӮеҜ№еә”жҹҗдёӘиЎҢеҲ—дҪҚзҪ®пјҢеӯҳзҡ„е°ұжҳҜдёӘж•°еӯ—иҖҢе·ІгҖӮ
иҝҷе°ұжҳҜдёәд»Җд№ҲпјҢеңЁиҝҗиЎҢд»Јз Ғзҡ„ж—¶еҖҷпјҢдҪ дјҡеҸ‘зҺ°TuriCreateйҰ–е…ҲеҒҡзҡ„пјҢе°ұжҳҜйҮҚж–°и®ҫзҪ®еӣҫзүҮзҡ„еӨ§е°ҸгҖӮеӣ дёәеҰӮжһңиҫ“е…ҘеӣҫзүҮеӨ§е°Ҹеҗ„ејӮзҡ„иҜқпјҢдёӢйқўжӯҘйӘӨж— жі•иҝӣиЎҢгҖӮ
жңүдәҶиҫ“е…Ҙж•°жҚ®пјҢе°ұйЎәеәҸиҝӣе…ҘдёӢдёҖеұӮпјҢд№ҹе°ұжҳҜеҚ·з§ҜеұӮпјҲConvolutional LayerпјүгҖӮ
еҚ·з§ҜеұӮеҗ¬иө·жқҘдјјд№ҺеҫҲзҘһз§ҳе’ҢеӨҚжқӮгҖӮдҪҶжҳҜеҺҹзҗҶйқһеёёз®ҖеҚ•гҖӮе®ғжҳҜз”ұиӢҘе№ІдёӘиҝҮж»ӨеҷЁз»„жҲҗзҡ„гҖӮжҜҸдёӘиҝҮж»ӨеҷЁе°ұжҳҜдёҖдёӘе°Ҹзҹ©йҳөгҖӮ
дҪҝз”Ёзҡ„ж—¶еҖҷпјҢеңЁиҫ“е…Ҙж•°жҚ®дёҠпјҢ移еҠЁиҝҷдёӘе°Ҹзҹ©йҳөпјҢи·ҹеҺҹе…ҲдёҺзҹ©йҳөйҮҚеҸ зҡ„дҪҚзҪ®дёҠзҡ„ж•°еӯ—еҒҡд№ҳжі•еҗҺеҠ еңЁдёҖиө·гҖӮиҝҷж ·еҺҹе…Ҳзҡ„дёҖдёӘзҹ©йҳөпјҢе°ұеҸҳжҲҗдәҶвҖңеҚ·з§ҜвҖқд№ӢеҗҺзҡ„дёҖдёӘж•°еӯ—гҖӮ
дёӢйқўиҝҷеј еҠЁеӣҫпјҢеҫҲеҪўиұЎең°дёәдҪ и§ЈйҮҠдәҶиҝҷдёҖиҝҮзЁӢгҖӮ
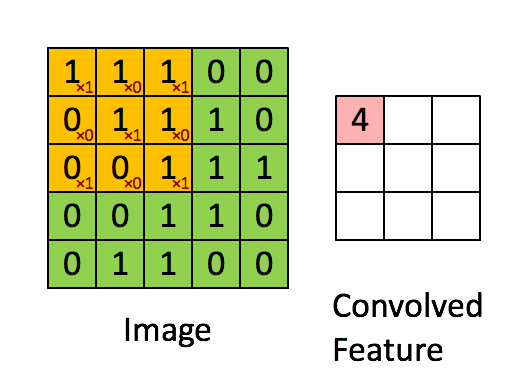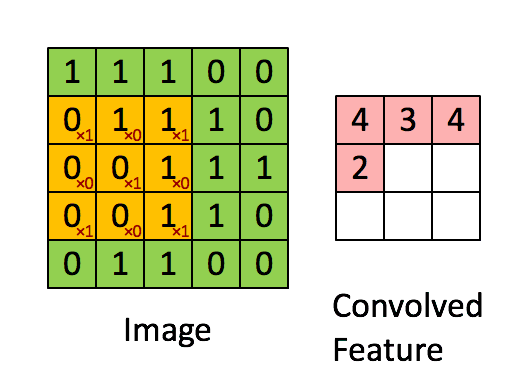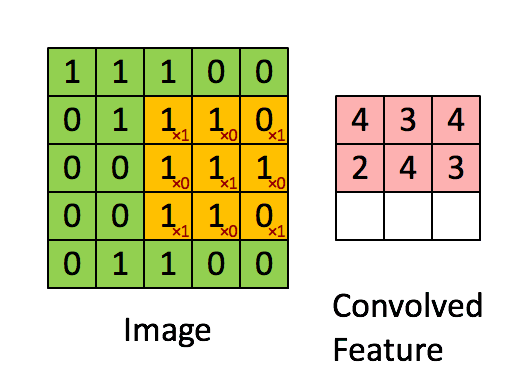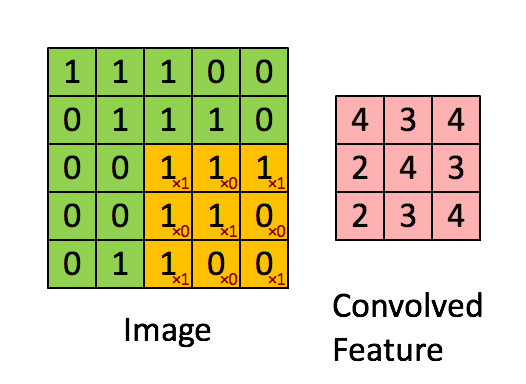
иҝҷдёӘиҝҮзЁӢпјҢе°ұжҳҜдёҚж–ӯд»ҺдёҖдёӘзҹ©йҳөдёҠеҺ»еҜ»жүҫжҹҗз§Қзү№еҫҒгҖӮиҝҷз§Қзү№еҫҒеҸҜиғҪжҳҜжҹҗдёӘиҫ№зјҳзҡ„еҪўзҠ¶д№Ӣзұ»гҖӮ
еҶҚдёӢдёҖеұӮпјҢеҸ«еҒҡвҖңжұ еҢ–еұӮвҖқпјҲPooling LayerпјүгҖӮиҝҷдёӘзҝ»иҜ‘з®Җзӣҙи®©дәәж— иҜӯгҖӮжҲ‘и§үеҫ—зҝ»иҜ‘жҲҗвҖңжұҮжҖ»еұӮвҖқжҲ–иҖ…вҖңйҮҮж ·еұӮвҖқйғҪиҰҒеҘҪи®ёеӨҡгҖӮдёӢж–ҮдёӯпјҢжҲ‘们称其дёәвҖңйҮҮж ·еұӮвҖқгҖӮ
йҮҮж ·зҡ„зӣ®зҡ„пјҢжҳҜйҒҝе…Қи®©жңәеҷЁи®ӨдёәвҖңеҝ…йЎ»еңЁе·ҰдёҠи§’зҡ„ж–№ж јдҪҚзҪ®пјҢжңүдёҖдёӘе°–е°–зҡ„иҫ№зјҳвҖқгҖӮе®һйҷ…дёҠпјҢеңЁдёҖеј еӣҫзүҮйҮҢпјҢжҲ‘们иҰҒиҜҶеҲ«зҡ„еҜ№иұЎеҸҜиғҪеҸ‘з”ҹдҪҚ移гҖӮеӣ жӯӨжҲ‘们йңҖиҰҒз”ЁжұҮжҖ»йҮҮж ·зҡ„ж–№ејҸжЁЎзіҠжҹҗдёӘзү№еҫҒзҡ„дҪҚзҪ®пјҢе°Ҷе…¶д»ҺвҖңжҹҗдёӘе…·дҪ“зҡ„зӮ№вҖқпјҢжү©еұ•жҲҗвҖңжҹҗдёӘеҢәеҹҹвҖқгҖӮ
еҰӮжһңиҝҷж ·иҜҙпјҢи®©дҪ и§үеҫ—дёҚеӨҹзӣҙи§ӮпјҢиҜ·еҸӮиҖғдёӢйқўиҝҷеј еҠЁеӣҫгҖӮ
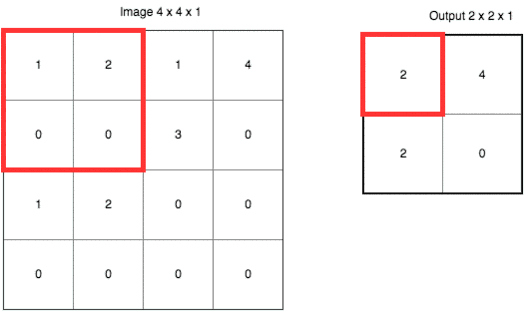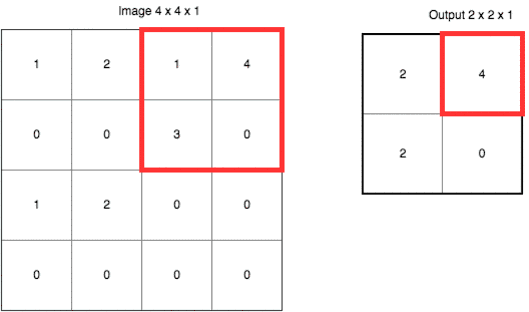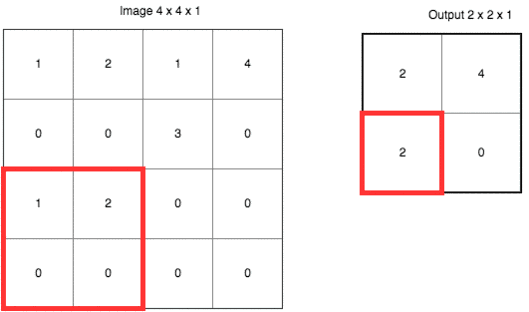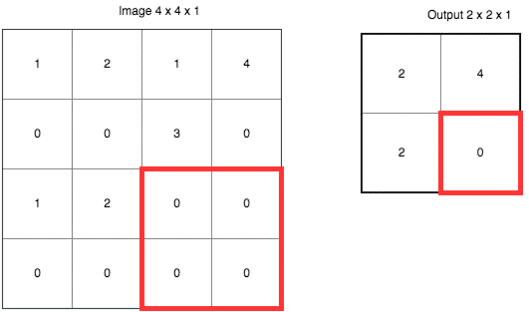
иҝҷйҮҢдҪҝз”Ёзҡ„жҳҜвҖң***еҖјйҮҮж ·вҖқпјҲMax-PoolingпјүгҖӮд»ҘеҺҹе…Ҳзҡ„2x2иҢғеӣҙдҪңдёәдёҖдёӘеҲҶеқ—пјҢд»ҺдёӯжүҫеҲ°***еҖјпјҢи®°еҪ•еңЁж–°зҡ„з»“жһңзҹ©йҳөйҮҢгҖӮ
дёҖдёӘжңүз”Ёзҡ„规еҫӢжҳҜпјҢйҡҸзқҖеұӮж•°дёҚж–ӯеҗ‘еҸіжҺЁиҝӣпјҢдёҖиҲ¬з»“жһңеӣҫеғҸпјҲе…¶е®һжӯЈи§„ең°иҜҙпјҢеә”иҜҘеҸ«еҒҡзҹ©йҳөпјүдјҡеҸҳеҫ—и¶ҠжқҘи¶Ҡе°ҸпјҢдҪҶжҳҜеұӮж•°дјҡеҸҳеҫ—и¶ҠжқҘи¶ҠеӨҡгҖӮ
еҸӘжңүиҝҷж ·пјҢжҲ‘们жүҚиғҪжҠҠеӣҫзүҮдёӯзҡ„规еҫӢдҝЎжҒҜжҠҪеҸ–еҮәжқҘпјҢ并且е°ҪйҮҸжҺҢжҸЎи¶іеӨҹеӨҡзҡ„жЁЎејҸгҖӮ
еҰӮжһңдҪ иҝҳжҳҜи§үеҫ—дёҚиҝҮзҳҫпјҢиҜ·и®ҝй—®иҝҷдёӘзҪ‘з«ҷпјҲhttps://link.jianshu.com/?t=http%3A%2F%2Fscs.ryerson.ca%2F%7Eaharley%2Fvis%2Fconv%2Fflat.htmlпјүгҖӮ
е®ғдёәдҪ з”ҹеҠЁи§ЈжһҗдәҶеҚ·з§ҜзҘһз»ҸзҪ‘з»ңдёӯпјҢеҗ„дёӘеұӮж¬ЎдёҠеҲ°еә•еҸ‘з”ҹдәҶд»Җд№ҲгҖӮ

е·ҰдёҠи§’жҳҜз”ЁжҲ·иҫ“е…ҘдҪҚзҪ®гҖӮиҜ·еҲ©з”Ёйј ж ҮпјҢжүӢеҶҷдёҖдёӘж•°еӯ—пјҲ0-9пјүгҖӮеҶҷеҫ—йҡҫзңӢдёҖдәӣд№ҹжІЎжңүе…ізі»гҖӮ
жҲ‘иҫ“е…ҘдәҶдёҖдёӘ7гҖӮ
и§ӮеҜҹиҫ“еҮәз»“жһңпјҢжЁЎеһӢжӯЈзЎ®еҲӨж–ӯ***йҖүжӢ©дёә7пјҢ第дәҢеҸҜиғҪжҖ§дёә3гҖӮеӣһзӯ”жӯЈзЎ®гҖӮ
и®©жҲ‘们и§ӮеҜҹжЁЎеһӢе»әжһ„зҡ„з»ҶиҠӮгҖӮ
жҲ‘们жҠҠйј ж ҮжҢӘеҲ°***дёӘеҚ·з§ҜеұӮгҖӮеҒңеңЁд»»ж„ҸдёҖдёӘеғҸзҙ дёҠгҖӮз”өи„‘е°ұе‘ҠиҜүжҲ‘们иҝҷдёӘзӮ№жҳҜд»ҺдёҠдёҖеұӮеӣҫеҪўдёӯе“ӘеҮ дёӘеғҸзҙ пјҢз»ҸиҝҮзү№еҫҒжЈҖжөӢпјҲfeature detectionпјүеҫ—жқҘзҡ„гҖӮ

еҗҢзҗҶпјҢеңЁ***дёӘMax poolingеұӮдёҠжӮ¬еҒңпјҢз”өи„‘д№ҹеҸҜд»ҘеҸҜи§ҶеҢ–еұ•зӨәз»ҷжҲ‘们пјҢиҜҘеғҸзҙ жҳҜд»Һе“ӘеҮ дёӘеғҸзҙ еҢәеқ—йҮҢжҠҪж ·иҺ·еҫ—зҡ„гҖӮ

иҝҷдёӘзҪ‘з«ҷпјҢеҖјеҫ—дҪ иҠұж—¶й—ҙеӨҡзҺ©е„ҝдёҖдјҡе„ҝгҖӮе®ғеҸҜд»Ҙеё®еҠ©дҪ зҗҶи§ЈеҚ·з§ҜзҘһз»ҸзҪ‘з»ңзҡ„еҶ…ж¶өгҖӮ
еӣһйЎҫжҲ‘们зҡ„зӨәдҫӢеӣҫпјҡ
дёӢдёҖеұӮеҸ«еҒҡе…ЁиҝһжҺҘеұӮпјҲFully Connected LayerпјүпјҢе®ғе…¶е®һе°ұжҳҜжҠҠдёҠдёҖеұӮиҫ“еҮәзҡ„иӢҘе№ІдёӘзҹ©йҳөе…ЁйғЁеҺӢзј©еҲ°дёҖз»ҙпјҢеҸҳжҲҗдёҖдёӘй•ҝй•ҝзҡ„иҫ“еҮәз»“жһңгҖӮ
д№ӢеҗҺжҳҜиҫ“еҮәеұӮпјҢеҜ№еә”зҡ„з»“жһңе°ұжҳҜжҲ‘们йңҖиҰҒи®©жңәеҷЁжҺҢжҸЎзҡ„еҲҶзұ»гҖӮ
еҰӮжһңеҸӘзңӢ***дёӨеұӮпјҢдҪ дјҡеҫҲе®№жҳ“жҠҠе®ғи·ҹд№ӢеүҚеӯҰиҝҮзҡ„ж·ұеәҰзҘһз»ҸзҪ‘з»ңпјҲDeep Neural Network, DNNпјүиҒ”зі»иө·жқҘгҖӮ
既然жҲ‘们已з»ҸжңүдәҶж·ұеәҰзҘһз»ҸзҪ‘з»ңпјҢдёәд»Җд№ҲиҝҳиҰҒеҰӮжӯӨиҙ№еҠӣеҺ»дҪҝз”ЁеҚ·з§ҜеұӮе’ҢйҮҮж ·еұӮпјҢеҜјиҮҙжЁЎеһӢеҰӮжӯӨеӨҚжқӮе‘ўпјҹ
иҝҷйҮҢеҮәдәҺдёӨдёӘиҖғиҷ‘пјҡ
йҰ–е…ҲжҳҜи®Ўз®—йҮҸгҖӮеӣҫзүҮж•°жҚ®зҡ„иҫ“е…ҘйҮҸдёҖиҲ¬жҜ”иҫғеӨ§пјҢеҰӮжһңжҲ‘们зӣҙжҺҘз”ЁиӢҘе№Іж·ұеәҰзҘһз»ҸеұӮе°Ҷе…¶иҝһжҺҘеҲ°иҫ“еҮәеұӮпјҢеҲҷжҜҸдёҖеұӮзҡ„иҫ“е…Ҙиҫ“еҮәж•°йҮҸйғҪеҫҲеәһеӨ§пјҢжҖ»и®Ўз®—йҮҸжҳҜйҡҫд»ҘжғіеғҸзҡ„гҖӮ
е…¶ж¬ЎжҳҜжЁЎејҸзү№еҫҒзҡ„жҠ“еҸ–гҖӮеҚідҫҝжҳҜдҪҝз”ЁйқһеёёеәһеӨ§зҡ„и®Ўз®—йҮҸпјҢж·ұеәҰзҘһз»ҸзҪ‘з»ңеҜ№дәҺеӣҫзүҮжЁЎејҸзҡ„иҜҶеҲ«ж•Ҳжһңд№ҹжңӘеҝ…е°ҪеҰӮдәәж„ҸгҖӮеӣ дёәе®ғеӯҰд№ дәҶеӨӘеӨҡеҷӘеЈ°гҖӮиҖҢеҚ·з§ҜеұӮе’ҢйҮҮж ·еұӮзҡ„еј•е…ҘпјҢеҸҜд»Ҙжңүж•ҲиҝҮж»ӨжҺүеҷӘеЈ°пјҢзӘҒеҮәеӣҫзүҮдёӯзҡ„жЁЎејҸеҜ№и®ӯз»ғз»“жһңзҡ„еҪұе“ҚгҖӮ
дҪ еҸҜиғҪдјҡжғіпјҢе’ұ们еҸӘзј–еҶҷдәҶ10еҮ иЎҢд»Јз ҒиҖҢе·ІпјҢдҪҝз”Ёзҡ„еҚ·з§ҜзҘһз»ҸзҪ‘з»ңдёҖе®ҡи·ҹдёҠеӣҫе·®дёҚеӨҡпјҢеҸӘжңү4гҖҒ5еұӮзҡ„ж ·еӯҗеҗ§пјҹ
дёҚжҳҜиҝҷж ·зҡ„пјҢдҪ з”Ёзҡ„еұӮж•°пјҢжңүи¶іи¶і50еұӮе‘ўпјҒ
е®ғзҡ„еӯҰеҗҚпјҢеҸ«еҒҡResnet-50пјҢжҳҜеҫ®иҪҜзҡ„з ”еҸ‘жҲҗжһңпјҢжӣҫз»ҸеңЁ2015е№ҙпјҢиөўеҫ—иҝҮILSRVCжҜ”иөӣгҖӮеңЁImageNetж•°жҚ®йӣҶдёҠпјҢе®ғзҡ„еҲҶзұ»иҫЁиҜҶж•ҲжһңпјҢе·Із»Ҹи¶…и¶Ҡдәәзұ»гҖӮ
жҲ‘жҠҠеҜ№еә”и®әж–Үзҡ„ең°еқҖйҷ„еңЁиҝҷйҮҢпјҲhttps://link.jianshu.com/?t=https%3A%2F%2Farxiv.org%2Fabs%2F1512.03385пјүпјҢеҰӮжһңдҪ жңүе…ҙи¶ЈпјҢеҸҜд»ҘеҸӮиҖғгҖӮ
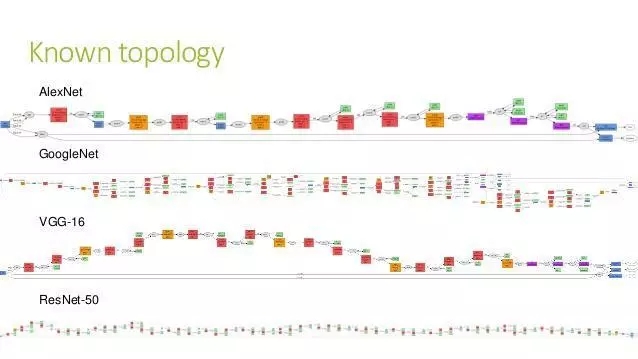
иҜ·зңӢдёҠеӣҫдёӯжңҖдёӢйқўзҡ„йӮЈдёҖдёӘпјҢе°ұжҳҜе®ғзҡ„еӨ§з•Ҙж ·еӯҗгҖӮ
и¶іеӨҹж·ұеәҰпјҢи¶іеӨҹеӨҚжқӮеҗ§гҖӮ
еҰӮжһңдҪ д№ӢеүҚеҜ№ж·ұеәҰзҘһз»ҸзҪ‘з»ңжңүдёҖдәӣдәҶи§ЈпјҢдёҖе®ҡдјҡжӣҙеҠ и§үеҫ—дёҚеҸҜжҖқи®®гҖӮиҝҷд№ҲеӨҡеұӮпјҢиҝҷд№Ҳе°‘зҡ„и®ӯз»ғж•°жҚ®йҮҸпјҢжҖҺд№ҲиғҪиҺ·еҫ—еҰӮжӯӨеҘҪзҡ„жөӢиҜ•з»“жһңе‘ўпјҹиҖҢеҰӮжһңиҰҒиҺ·еҫ—еҘҪзҡ„и®ӯз»ғж•ҲжһңпјҢеӨ§йҮҸеӣҫзүҮзҡ„и®ӯз»ғиҝҮзЁӢпјҢеІӮдёҚжҳҜеә”иҜҘиҠұеҫҲй•ҝж—¶й—ҙеҗ—пјҹ
жІЎй”ҷпјҢеҰӮжһңдҪ иҮӘе·ұд»ҺеӨҙжҗӯе»әдёҖдёӘResnet-50пјҢ并且еңЁImageNetж•°жҚ®йӣҶдёҠеҒҡи®ӯз»ғпјҢйӮЈд№ҲеҚідҫҝдҪ жңүеҫҲеҘҪзҡ„硬件и®ҫеӨҮпјҲGPUпјүпјҢд№ҹйңҖиҰҒеҫҲй•ҝж—¶й—ҙгҖӮ
еҰӮжһңдҪ еңЁиҮӘе·ұзҡ„笔记жң¬дёҠи®ӯз»ғ……з®—дәҶеҗ§гҖӮ
йӮЈд№ҲпјҢTuriCreateйҡҫйҒ“зңҹзҡ„жҳҜдёӘеҘҮиҝ№пјҹж—ўдёҚйңҖиҰҒиҠұиҙ№й•ҝж—¶й—ҙи®ӯз»ғпјҢеҸҲеҸӘйңҖиҰҒе°Ҹж ·жң¬пјҢе°ұиғҪиҺ·еҫ—й«ҳж°ҙе№ізҡ„еҲҶзұ»ж•Ҳжһңпјҹ
дёҚпјҢж•°жҚ®з§‘еӯҰйҮҢжІЎжңүд»Җд№ҲеҘҮиҝ№гҖӮ
еҲ°жӯӨпјҢе…ідәҺвҖңPythonжҖҺд№ҲиҜҶеҲ«еӣҫеғҸвҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ