жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮж–Үз« з»ҷеӨ§е®¶еҲҶдә«зҡ„жҳҜжңүе…іеҰӮдҪ•дҪҝз”ЁPythonзј–еҶҷеӨҡзәҝзЁӢзҲ¬иҷ«жҠ“еҸ–зҷҫеәҰиҙҙеҗ§йӮ®з®ұдёҺжүӢжңәеҸ·пјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еӯҰд№ пјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·пјҢиҜқдёҚеӨҡиҜҙпјҢи·ҹзқҖе°Ҹзј–дёҖиө·жқҘзңӢзңӢеҗ§гҖӮ
дёҚзҹҘйҒ“еӨ§е®¶иҝҮе№ҙйғҪжҳҜжҖҺд№ҲиҝҮзҡ„пјҢеҸҚжӯЈж Ҹдё»жҳҜеңЁе®¶зқЎдәҶдёҖеӨ©пјҢйҶ’жқҘзҡ„ж—¶еҖҷзҷ»QQеҸ‘зҺ°жңүдәәжүҫжҲ‘иҰҒдёҖд»Ҫиҙҙеҗ§зҲ¬иҷ«зҡ„жәҗд»Јз ҒпјҢжғіиө·д№ӢеүҚз»ғжүӢзҡ„ж—¶еҖҷеҶҷиҝҮдёҖдёӘжҠ“еҸ–зҷҫеәҰиҙҙеҗ§еҸ‘её–и®°еҪ•дёӯзҡ„йӮ®з®ұдёҺжүӢжңәеҸ·зҡ„зҲ¬иҷ«пјҢдәҺжҳҜејҖжәҗеҲҶдә«з»ҷеӨ§е®¶еӯҰд№ дёҺеҸӮиҖғгҖӮ
жң¬зҲ¬иҷ«дё»иҰҒжҳҜеҜ№зҷҫеәҰиҙҙеҗ§дёӯеҗ„з§Қеё–еӯҗзҡ„еҶ…е®№иҝӣиЎҢжҠ“еҸ–пјҢ并且еҲҶжһҗеё–еӯҗеҶ…е®№е°Ҷе…¶дёӯзҡ„жүӢжңәеҸ·е’ҢйӮ®з®ұең°еқҖжҠ“еҸ–еҮәжқҘгҖӮдё»иҰҒжөҒзЁӢеңЁд»Јз ҒжіЁйҮҠдёӯжңүиҜҰз»Ҷи§ЈйҮҠгҖӮ
д»Јз ҒеңЁWindows7 64bitпјҢpython 2.7 64bitпјҲе®үиЈ…mysqldbжү©еұ•пјүд»ҘеҸҠcentos 6.5пјҢpython 2.7пјҲеёҰmysqldbжү©еұ•пјүзҺҜеўғдёӢжөӢиҜ•йҖҡиҝҮ
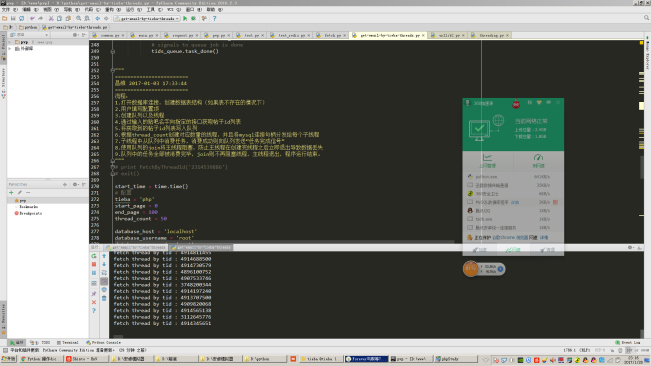
е·Ҙж¬Іе–„е…¶дәӢеҝ…е…ҲеҲ©е…¶еҷЁпјҢеӨ§е®¶еҸҜд»Ҙд»ҺжҲӘеӣҫзңӢеҮәжҲ‘зҡ„зҺҜеўғжҳҜWindows 7 + PyCharmгҖӮжҲ‘зҡ„PythonзҺҜеўғжҳҜPython 2.7 64bitгҖӮиҝҷжҳҜжҜ”иҫғйҖӮеҗҲж–°жүӢдҪҝз”Ёзҡ„ејҖеҸ‘зҺҜеўғгҖӮ然еҗҺжҲ‘еҶҚе»әи®®еӨ§е®¶е®үиЈ…дёҖдёӘeasy_installпјҢеҗ¬еҗҚеӯ—е°ұзҹҘйҒ“иҝҷжҳҜдёҖдёӘе®үиЈ…еҷЁпјҢе®ғжҳҜз”ЁжқҘе®үиЈ…дёҖдәӣжү©еұ•еҢ…зҡ„пјҢжҜ”еҰӮиҜҙеңЁpythonдёӯеҰӮжһңжҲ‘们иҰҒж“ҚдҪңmysqlж•°жҚ®еә“зҡ„иҜқпјҢpythonеҺҹз”ҹжҳҜдёҚж”ҜжҢҒзҡ„пјҢжҲ‘们еҝ…йЎ»е®үиЈ…mysqldbеҢ…жқҘи®©pythonеҸҜд»Ҙж“ҚдҪңmysqlж•°жҚ®еә“пјҢеҰӮжһңжңүeasy_installзҡ„иҜқжҲ‘们еҸӘйңҖиҰҒдёҖиЎҢе‘Ҫд»Өе°ұеҸҜд»Ҙеҝ«йҖҹе®үиЈ…еҸ·mysqldbжү©еұ•еҢ…пјҢд»–е°ұеғҸphpдёӯзҡ„composerпјҢcentosдёӯзҡ„yumпјҢUbuntuдёӯзҡ„apt-getдёҖж ·ж–№дҫҝгҖӮ
зӣёе…іе·Ҙе…·еҸҜеңЁжҲ‘зҡ„githubдёӯжүҫеҲ°пјҡcw1997/python-toolsпјҢе…¶дёӯeasy_installзҡ„е®үиЈ…еҸӘйңҖиҰҒеңЁpythonе‘Ҫд»ӨиЎҢдёӢиҝҗиЎҢйӮЈдёӘpyи„ҡжң¬з„¶еҗҺзЁҚзӯүзүҮеҲ»еҚіеҸҜпјҢд»–дјҡиҮӘеҠЁеҠ е…ҘWindowsзҡ„зҺҜеўғеҸҳйҮҸпјҢеңЁWindowsе‘Ҫд»ӨиЎҢдёӢеҰӮжһңиҫ“е…Ҙeasy_installжңүеӣһжҳҫиҜҙжҳҺе®үиЈ…жҲҗеҠҹгҖӮ
иҮідәҺз”ө脑硬件еҪ“然жҳҜи¶Ҡеҝ«и¶ҠеҘҪпјҢеҶ…еӯҳиө·з Ғ8Gиө·жӯҘпјҢеӣ дёәзҲ¬иҷ«жң¬иә«йңҖиҰҒеӨ§йҮҸеӯҳеӮЁе’Ңи§Јжһҗдёӯй—ҙж•°жҚ®пјҢе°Өе…¶жҳҜеӨҡзәҝзЁӢзҲ¬иҷ«пјҢеңЁзў°еҲ°жҠ“еҸ–еёҰжңүеҲҶйЎөзҡ„еҲ—иЎЁе’ҢиҜҰжғ…йЎөпјҢ并且жҠ“еҸ–ж•°жҚ®йҮҸеҫҲеӨ§зҡ„жғ…еҶөдёӢдҪҝз”ЁqueueйҳҹеҲ—еҲҶй…ҚжҠ“еҸ–д»»еҠЎдјҡйқһеёёеҚ еҶ…еӯҳгҖӮеҢ…жӢ¬жңүзҡ„ж—¶еҖҷжҲ‘们жҠ“еҸ–зҡ„ж•°жҚ®жҳҜдҪҝз”ЁjsonпјҢеҰӮжһңдҪҝз”Ёmongodbзӯүnosqlж•°жҚ®еә“еӯҳеӮЁпјҢд№ҹдјҡеҫҲеҚ еҶ…еӯҳгҖӮ
зҪ‘з»ңиҝһжҺҘе»әи®®дҪҝз”ЁжңүзәҝзҪ‘пјҢеӣ дёәеёӮйқўдёҠдёҖдәӣеҠЈиҙЁзҡ„ж— зәҝи·Ҝз”ұеҷЁе’Ңжҷ®йҖҡзҡ„ж°‘з”Ёж— зәҝзҪ‘еҚЎеңЁзәҝзЁӢејҖзҡ„жҜ”иҫғеӨ§зҡ„жғ…еҶөдёӢдјҡеҮәзҺ°й—ҙжӯҮжҖ§ж–ӯзҪ‘жҲ–иҖ…ж•°жҚ®дёўеӨұпјҢжҺүеҢ…зӯүжғ…еҶөпјҢиҝҷдёӘжҲ‘дәІжңүдҪ“дјҡгҖӮ
иҮідәҺж“ҚдҪңзі»з»ҹе’ҢpythonеҪ“然иӮҜе®ҡжҳҜйҖүжӢ©64дҪҚгҖӮеҰӮжһңдҪ дҪҝз”Ёзҡ„жҳҜ32дҪҚзҡ„ж“ҚдҪңзі»з»ҹпјҢйӮЈд№Ҳж— жі•дҪҝз”ЁеӨ§еҶ…еӯҳгҖӮеҰӮжһңдҪ дҪҝз”Ёзҡ„жҳҜ32дҪҚзҡ„pythonпјҢеҸҜиғҪеңЁе°Ҹ规模жҠ“еҸ–ж•°жҚ®зҡ„ж—¶еҖҷж„ҹи§үдёҚеҮәжңүд»Җд№Ҳй—®йўҳпјҢдҪҶжҳҜеҪ“ж•°жҚ®йҮҸеҸҳеӨ§зҡ„ж—¶еҖҷпјҢжҜ”еҰӮиҜҙжҹҗдёӘеҲ—иЎЁпјҢйҳҹеҲ—пјҢеӯ—е…ёйҮҢйқўеӯҳеӮЁдәҶеӨ§йҮҸж•°жҚ®пјҢеҜјиҮҙpythonзҡ„еҶ…еӯҳеҚ з”Ёи¶…иҝҮ2gзҡ„ж—¶еҖҷдјҡжҠҘеҶ…еӯҳжәўеҮәй”ҷиҜҜгҖӮеҺҹеӣ еңЁжҲ‘жӣҫз»ҸsegmentfaultдёҠжҸҗиҝҮзҡ„й—®йўҳдёӯдҫқдә‘зҡ„еӣһзӯ”жңүи§ЈйҮҠпјҲjava – pythonеҸӘиҰҒеҚ з”ЁеҶ…еӯҳиҫҫеҲ°1.9Gд№ӢеҗҺhttplibжЁЎеқ—е°ұејҖе§ӢжҠҘеҶ…еӯҳжәўеҮәй”ҷиҜҜ – SegmentFaultпјү
еҰӮжһңдҪ еҮҶеӨҮдҪҝз”ЁmysqlеӯҳеӮЁж•°жҚ®пјҢе»әи®®дҪҝз”Ёmysql5.5д»ҘеҗҺзҡ„зүҲжң¬пјҢеӣ дёәmysql5.5зүҲжң¬ж”ҜжҢҒjsonж•°жҚ®зұ»еһӢпјҢиҝҷж ·зҡ„иҜқеҸҜд»ҘжҠӣејғmongodbдәҶгҖӮпјҲжңүдәәиҜҙmysqlдјҡжҜ”mongodbзЁіе®ҡдёҖзӮ№пјҢиҝҷдёӘжҲ‘дёҚзЎ®е®ҡгҖӮпјү
иҮідәҺзҺ°еңЁpythonйғҪе·Із»ҸеҮәдәҶ3.xзүҲжң¬дәҶпјҢдёәд»Җд№ҲжҲ‘иҝҷйҮҢиҝҳдҪҝз”Ёзҡ„жҳҜpython2.7пјҹжҲ‘дёӘдәәйҖүжӢ©2.7зүҲжң¬зҡ„еҺҹеӣ жҳҜиҮӘе·ұеҪ“еҲқеҫҲж—©д»ҘеүҚд№°зҡ„pythonж ёеҝғзј–зЁӢиҝҷжң¬д№ҰжҳҜ第дәҢзүҲзҡ„пјҢд»Қ然д»Ҙ2.7дёәзӨәдҫӢзүҲжң¬гҖӮ并且зӣ®еүҚзҪ‘дёҠд»Қ然жңүеӨ§йҮҸзҡ„ж•ҷзЁӢиө„ж–ҷжҳҜд»Ҙ2.7дёәзүҲжң¬и®Іи§ЈпјҢ2.7еңЁжҹҗдәӣж–№йқўдёҺ3.xиҝҳжҳҜжңүеҫҲеӨ§е·®еҲ«пјҢеҰӮжһңжҲ‘们没жңүеӯҰиҝҮ2.7пјҢеҸҜиғҪеҜ№дәҺдёҖдәӣз»Ҷеҫ®зҡ„иҜӯжі•е·®еҲ«дёҚжҳҜеҫҲжҮӮдјҡеҜјиҮҙжҲ‘们зҗҶи§ЈдёҠеҮәзҺ°еҒҸе·®пјҢжҲ–иҖ…зңӢдёҚжҮӮdemoд»Јз ҒгҖӮиҖҢдё”зҺ°еңЁиҝҳжҳҜжңүйғЁеҲҶдҫқиө–еҢ…еҸӘе…је®№2.7зүҲжң¬гҖӮжҲ‘зҡ„е»әи®®жҳҜеҰӮжһңдҪ жҳҜеҮҶеӨҮжҖҘзқҖеӯҰpython然еҗҺеҺ»е…¬еҸёе·ҘдҪңпјҢ并且公еҸёжІЎжңүиҖҒд»Јз ҒйңҖиҰҒз»ҙжҠӨпјҢйӮЈд№ҲеҸҜд»ҘиҖғиҷ‘зӣҙжҺҘдёҠжүӢ3.xпјҢеҰӮжһңдҪ жңүжҜ”иҫғе……иЈ•зҡ„ж—¶й—ҙпјҢ并且没жңүеҫҲзі»з»ҹзҡ„еӨ§зүӣеёҰпјҢеҸӘиғҪдҫқйқ зҪ‘дёҠйӣ¶йӣ¶ж•Јж•Јзҡ„еҚҡе®ўж–Үз« жқҘеӯҰд№ пјҢйӮЈд№ҲиҝҳжҳҜе…ҲеӯҰ2.7еңЁеӯҰ3.xпјҢжҜ•з«ҹеӯҰдјҡдәҶ2.7д№ӢеҗҺ3.xдёҠжүӢд№ҹеҫҲеҝ«гҖӮ
е…¶е®һеҜ№дәҺд»»дҪ•иҪҜ件项зӣ®иҖҢиЁҖпјҢжҲ‘们еҮЎжҳҜжғізҹҘйҒ“зј–еҶҷиҝҷдёӘйЎ№зӣ®йңҖиҰҒд»Җд№ҲзҹҘиҜҶзӮ№пјҢжҲ‘们йғҪеҸҜд»Ҙи§ӮеҜҹдёҖдёӢиҝҷдёӘйЎ№зӣ®зҡ„дё»иҰҒе…ҘеҸЈж–Ү件йғҪеҜје…ҘдәҶе“ӘдәӣеҢ…гҖӮ
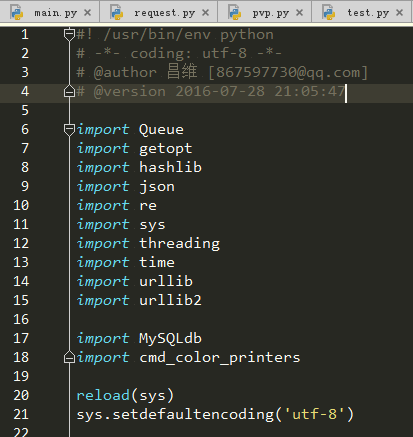
зҺ°еңЁжқҘзңӢдёҖдёӢжҲ‘们иҝҷдёӘйЎ№зӣ®пјҢдҪңдёәдёҖдёӘеҲҡжҺҘи§Ұpythonзҡ„дәәпјҢеҸҜиғҪжңүдёҖдәӣеҢ…еҮ д№ҺйғҪжІЎжңүз”ЁиҝҮпјҢйӮЈд№ҲжҲ‘们еңЁжң¬е°ҸиҠӮе°ұжқҘз®ҖеҚ•зҡ„иҜҙиҜҙиҝҷдәӣеҢ…иө·д»Җд№ҲдҪңз”ЁпјҢиҰҒжҺҢжҸЎд»–们еҲҶеҲ«дјҡж¶үеҸҠеҲ°д»Җд№ҲзҹҘиҜҶзӮ№пјҢиҝҷдәӣзҹҘиҜҶзӮ№зҡ„е…ій”®иҜҚжҳҜд»Җд№ҲгҖӮиҝҷзҜҮж–Үз« е№¶дёҚдјҡиҠұиҙ№й•ҝзҜҮеӨ§и®әжқҘд»ҺеҹәзЎҖи®Іиө·пјҢеӣ жӯӨжҲ‘们иҰҒеӯҰдјҡе–„з”ЁзҷҫеәҰпјҢжҗңзҙўиҝҷдәӣзҹҘиҜҶзӮ№зҡ„е…ій”®иҜҚжқҘиҮӘеӯҰгҖӮдёӢйқўе°ұжқҘдёҖдёҖеҲҶжһҗдёҖдёӢиҝҷдәӣзҹҘиҜҶзӮ№гҖӮ
жҲ‘们зҡ„зҲ¬иҷ«жҠ“еҸ–ж•°жҚ®жң¬иҙЁдёҠе°ұжҳҜдёҚеҒңзҡ„еҸ‘иө·httpиҜ·жұӮпјҢиҺ·еҸ–httpе“Қеә”пјҢе°Ҷе…¶еӯҳе…ҘжҲ‘们зҡ„з”өи„‘дёӯгҖӮдәҶи§ЈhttpеҚҸи®®жңүеҠ©дәҺжҲ‘们еңЁжҠ“еҸ–ж•°жҚ®зҡ„ж—¶еҖҷеҜ№дёҖдәӣиғҪеӨҹеҠ йҖҹжҠ“еҸ–йҖҹеәҰзҡ„еҸӮж•°иғҪеӨҹзІҫеҮҶзҡ„жҺ§еҲ¶пјҢжҜ”еҰӮиҜҙkeep-aliveзӯүгҖӮ
жҲ‘们平时编еҶҷзҡ„зЁӢеәҸйғҪжҳҜеҚ•зәҝзЁӢзЁӢеәҸпјҢжҲ‘们еҶҷзҡ„д»Јз ҒйғҪеңЁдё»зәҝзЁӢйҮҢйқўиҝҗиЎҢпјҢиҝҷдёӘдё»зәҝзЁӢеҸҲиҝҗиЎҢеңЁpythonиҝӣзЁӢдёӯгҖӮе…ідәҺзәҝзЁӢе’ҢиҝӣзЁӢзҡ„и§ЈйҮҠеҸҜд»ҘеҸӮиҖғйҳ®дёҖеі°зҡ„еҚҡе®ўпјҡиҝӣзЁӢдёҺзәҝзЁӢзҡ„дёҖдёӘз®ҖеҚ•и§ЈйҮҠ – йҳ®дёҖеі°зҡ„зҪ‘з»ңж—Ҙеҝ—
еңЁpythonдёӯе®һзҺ°еӨҡзәҝзЁӢжҳҜйҖҡиҝҮдёҖдёӘеҗҚеӯ—еҸ«еҒҡthreadingзҡ„жЁЎеқ—жқҘе®һзҺ°гҖӮд№ӢеүҚиҝҳжңүthreadжЁЎеқ—пјҢдҪҶжҳҜthreadingеҜ№дәҺзәҝзЁӢзҡ„жҺ§еҲ¶жӣҙејәпјҢеӣ жӯӨжҲ‘们еҗҺжқҘйғҪж”№з”ЁthreadingжқҘе®һзҺ°еӨҡзәҝзЁӢзј–зЁӢдәҶгҖӮ
е…ідәҺthreadingеӨҡзәҝзЁӢзҡ„дёҖдәӣз”Ёжі•пјҢжҲ‘и§үеҫ—иҝҷзҜҮж–Үз« дёҚй”ҷпјҡ[python] дё“йўҳе…«.еӨҡзәҝзЁӢзј–зЁӢд№Ӣthreadе’Ңthreading еӨ§е®¶еҸҜд»ҘеҸӮиҖғеҸӮиҖғгҖӮ
з®ҖеҚ•жқҘиҜҙпјҢдҪҝз”ЁthreadingжЁЎеқ—зј–еҶҷеӨҡзәҝзЁӢзЁӢеәҸпјҢе°ұжҳҜе…ҲиҮӘе·ұе®ҡд№үдёҖдёӘзұ»пјҢ然еҗҺиҝҷдёӘзұ»иҰҒ继жүҝthreading.ThreadпјҢ并且жҠҠжҜҸдёӘзәҝзЁӢиҰҒеҒҡзҡ„е·ҘдҪңд»Јз ҒеҶҷеҲ°дёҖдёӘзұ»зҡ„runж–№жі•дёӯпјҢеҪ“然еҰӮжһңзәҝзЁӢжң¬иә«еңЁеҲӣе»әзҡ„ж—¶еҖҷеҰӮжһңиҰҒеҒҡдёҖдәӣеҲқе§ӢеҢ–е·ҘдҪңпјҢйӮЈд№Ҳе°ұиҰҒеңЁд»–зҡ„__init__ж–№жі•дёӯзј–еҶҷеҘҪеҲқе§ӢеҢ–е·ҘдҪңжүҖиҰҒжү§иЎҢзҡ„д»Јз ҒпјҢиҝҷдёӘж–№жі•е°ұеғҸphpпјҢjavaдёӯзҡ„жһ„йҖ ж–№жі•дёҖж ·гҖӮ
иҝҷйҮҢиҝҳиҰҒйўқеӨ–и®Ізҡ„дёҖзӮ№е°ұжҳҜзәҝзЁӢе®үе…ЁиҝҷдёӘжҰӮеҝөгҖӮйҖҡеёёжғ…еҶөдёӢжҲ‘们еҚ•зәҝзЁӢжғ…еҶөдёӢжҜҸдёӘж—¶еҲ»еҸӘжңүдёҖдёӘзәҝзЁӢеңЁеҜ№иө„жәҗпјҲж–Ү件пјҢеҸҳйҮҸпјүж“ҚдҪңпјҢжүҖд»ҘдёҚеҸҜиғҪдјҡеҮәзҺ°еҶІзӘҒгҖӮдҪҶжҳҜеҪ“еӨҡзәҝзЁӢзҡ„жғ…еҶөдёӢпјҢеҸҜиғҪдјҡеҮәзҺ°еҗҢдёҖдёӘж—¶еҲ»дёӨдёӘзәҝзЁӢеңЁж“ҚдҪңеҗҢдёҖдёӘиө„жәҗпјҢеҜјиҮҙиө„жәҗжҚҹеқҸпјҢжүҖд»ҘжҲ‘们йңҖиҰҒдёҖз§ҚжңәеҲ¶жқҘи§ЈеҶіиҝҷз§ҚеҶІзӘҒеёҰжқҘзҡ„з ҙеқҸпјҢйҖҡеёёжңүеҠ й”Ғзӯүж“ҚдҪңпјҢжҜ”еҰӮиҜҙmysqlж•°жҚ®еә“зҡ„innodbиЎЁеј•ж“ҺжңүиЎҢзә§й”ҒзӯүпјҢж–Ү件ж“ҚдҪңжңүиҜ»еҸ–й”ҒзӯүзӯүпјҢиҝҷдәӣйғҪжҳҜ他们зҡ„зЁӢеәҸеә•еұӮеё®жҲ‘们е®ҢжҲҗдәҶгҖӮжүҖд»ҘжҲ‘们йҖҡеёёеҸӘиҰҒзҹҘйҒ“йӮЈдәӣж“ҚдҪңпјҢжҲ–иҖ…йӮЈдәӣзЁӢеәҸеҜ№дәҺзәҝзЁӢе®үе…Ёй—®йўҳеҒҡдәҶеӨ„зҗҶпјҢ然еҗҺе°ұеҸҜд»ҘеңЁеӨҡзәҝзЁӢзј–зЁӢдёӯеҺ»дҪҝз”Ёе®ғ们дәҶгҖӮиҖҢиҝҷз§ҚиҖғиҷ‘еҲ°зәҝзЁӢе®үе…Ёй—®йўҳзҡ„зЁӢеәҸдёҖиҲ¬е°ұеҸ«еҒҡвҖңзәҝзЁӢе®үе…ЁзүҲжң¬вҖқпјҢжҜ”еҰӮиҜҙphpе°ұжңүTSзүҲжң¬пјҢиҝҷдёӘTSе°ұжҳҜThread SafetyзәҝзЁӢе®үе…Ёзҡ„ж„ҸжҖқгҖӮдёӢйқўжҲ‘们иҰҒи®ІеҲ°зҡ„QueueжЁЎеқ—е°ұжҳҜдёҖз§ҚзәҝзЁӢе®үе…Ёзҡ„йҳҹеҲ—ж•°жҚ®з»“жһ„пјҢжүҖд»ҘжҲ‘们еҸҜд»Ҙж”ҫеҝғзҡ„еңЁеӨҡзәҝзЁӢзј–зЁӢдёӯдҪҝз”Ёе®ғгҖӮ
***жҲ‘们е°ұиҰҒжқҘи®Іи®ІиҮіе…ійҮҚиҰҒзҡ„зәҝзЁӢйҳ»еЎһиҝҷдёӘжҰӮеҝөдәҶгҖӮеҪ“жҲ‘们иҜҰз»ҶеӯҰд№ е®ҢthreadingжЁЎеқ—д№ӢеҗҺпјҢеӨ§жҰӮе°ұзҹҘйҒ“еҰӮдҪ•еҲӣе»әе’ҢеҗҜеҠЁзәҝзЁӢдәҶгҖӮдҪҶжҳҜеҰӮжһңжҲ‘们жҠҠзәҝзЁӢеҲӣе»әеҘҪдәҶпјҢ然еҗҺи°ғз”ЁдәҶstartж–№жі•пјҢйӮЈд№ҲжҲ‘们дјҡеҸ‘зҺ°еҘҪеғҸж•ҙдёӘзЁӢеәҸз«Ӣ马е°ұз»“жқҹдәҶпјҢиҝҷжҳҜжҖҺд№ҲеӣһдәӢе‘ўпјҹе…¶е®һиҝҷжҳҜеӣ дёәжҲ‘们еңЁдё»зәҝзЁӢдёӯеҸӘжңүиҙҹиҙЈеҗҜеҠЁеӯҗзәҝзЁӢзҡ„д»Јз ҒпјҢд№ҹе°ұж„Ҹе‘ізқҖдё»зәҝзЁӢеҸӘжңүеҗҜеҠЁеӯҗзәҝзЁӢзҡ„еҠҹиғҪпјҢиҮідәҺеӯҗзәҝзЁӢжү§иЎҢзҡ„йӮЈдәӣд»Јз ҒпјҢ他们жң¬иҙЁдёҠеҸӘжҳҜеҶҷеңЁзұ»йҮҢйқўзҡ„дёҖдёӘж–№жі•пјҢ并没еңЁдё»зәҝзЁӢйҮҢйқўзңҹжӯЈеҺ»жү§иЎҢд»–пјҢжүҖд»Ҙдё»зәҝзЁӢеҗҜеҠЁе®ҢеӯҗзәҝзЁӢд№ӢеҗҺд»–зҡ„жң¬иҒҢе·ҘдҪңе°ұе·Із»Ҹе…ЁйғЁе®ҢжҲҗдәҶпјҢе·Із»Ҹе…үиҚЈйҖҖеңәдәҶгҖӮ既然主зәҝзЁӢйғҪйҖҖеңәдәҶпјҢйӮЈд№ҲpythonиҝӣзЁӢе°ұи·ҹзқҖз»“жқҹдәҶпјҢйӮЈд№Ҳе…¶д»–зәҝзЁӢд№ҹе°ұжІЎжңүеҶ…еӯҳз©әй—ҙ继з»ӯжү§иЎҢдәҶгҖӮжүҖд»ҘжҲ‘们еә”иҜҘжҳҜиҰҒи®©дё»зәҝзЁӢеӨ§е“ҘзӯүеҲ°жүҖжңүзҡ„еӯҗзәҝзЁӢе°Ҹејҹе…ЁйғЁжү§иЎҢе®ҢжҜ•еҶҚе…үиҚЈйҖҖеңәпјҢйӮЈд№ҲеңЁзәҝзЁӢеҜ№иұЎдёӯжңүд»Җд№Ҳж–№жі•иғҪеӨҹжҠҠдё»зәҝзЁӢеҚЎдҪҸе‘ўпјҹthread.sleepеҳӣпјҹиҝҷзЎ®е®һжҳҜдёӘеҠһжі•пјҢдҪҶжҳҜ究з«ҹеә”иҜҘи®©дё»зәҝзЁӢsleepеӨҡд№…е‘ўпјҹжҲ‘们并дёҚиғҪеҮҶзЎ®зҹҘйҒ“жү§иЎҢе®ҢдёҖдёӘд»»еҠЎиҰҒеӨҡд№…ж—¶й—ҙпјҢиӮҜе®ҡдёҚиғҪз”ЁиҝҷдёӘеҠһжі•гҖӮжүҖд»ҘжҲ‘们иҝҷдёӘж—¶еҖҷеә”иҜҘдёҠзҪ‘жҹҘиҜўдёҖдёӢжңүд»Җд№ҲеҠһжі•иғҪеӨҹи®©еӯҗзәҝзЁӢвҖңеҚЎдҪҸвҖқдё»зәҝзЁӢе‘ўпјҹвҖңеҚЎдҪҸвҖқиҝҷдёӘиҜҚеҘҪеғҸеӨӘзІ—й„ҷдәҶпјҢе…¶е®һиҜҙдё“дёҡдёҖзӮ№пјҢеә”иҜҘеҸ«еҒҡвҖңйҳ»еЎһвҖқпјҢжүҖд»ҘжҲ‘们еҸҜд»ҘжҹҘиҜўвҖңpython еӯҗзәҝзЁӢйҳ»еЎһдё»зәҝзЁӢвҖқпјҢеҰӮжһңжҲ‘们дјҡжӯЈзЎ®дҪҝз”Ёжҗңзҙўеј•ж“Һзҡ„иҜқпјҢеә”иҜҘдјҡжҹҘеҲ°дёҖдёӘж–№жі•еҸ«еҒҡjoin()пјҢжІЎй”ҷпјҢиҝҷдёӘjoin()ж–№жі•е°ұжҳҜеӯҗзәҝзЁӢз”ЁдәҺйҳ»еЎһдё»зәҝзЁӢзҡ„ж–№жі•пјҢеҪ“еӯҗзәҝзЁӢиҝҳжңӘжү§иЎҢе®ҢжҜ•зҡ„ж—¶еҖҷпјҢдё»зәҝзЁӢиҝҗиЎҢеҲ°еҗ«жңүjoin()ж–№жі•зҡ„иҝҷдёҖиЎҢе°ұдјҡеҚЎеңЁйӮЈйҮҢпјҢзӣҙеҲ°жүҖжңүзәҝзЁӢйғҪжү§иЎҢе®ҢжҜ•жүҚдјҡжү§иЎҢjoin()ж–№жі•еҗҺйқўзҡ„д»Јз ҒгҖӮ
еҒҮи®ҫжңүдёҖдёӘиҝҷж ·зҡ„еңәжҷҜпјҢжҲ‘们йңҖиҰҒжҠ“еҸ–дёҖдёӘдәәзҡ„еҚҡе®ўпјҢжҲ‘们зҹҘйҒ“иҝҷдёӘдәәзҡ„еҚҡе®ўжңүдёӨдёӘйЎөйқўпјҢдёҖдёӘlist.phpйЎөйқўжҳҫзӨәзҡ„жҳҜжӯӨеҚҡе®ўзҡ„жүҖжңүж–Үз« й“ҫжҺҘпјҢиҝҳжңүдёҖдёӘview.phpйЎөйқўжҳҫзӨәзҡ„жҳҜдёҖзҜҮж–Үз« зҡ„е…·дҪ“еҶ…е®№гҖӮ
еҰӮжһңжҲ‘们иҰҒжҠҠиҝҷдёӘдәәзҡ„еҚҡе®ўйҮҢйқўжүҖжңүж–Үз« еҶ…е®№жҠ“еҸ–дёӢжқҘпјҢзј–еҶҷеҚ•зәҝзЁӢзҲ¬иҷ«зҡ„жҖқи·ҜжҳҜпјҡе…Ҳз”ЁжӯЈеҲҷиЎЁиҫҫејҸжҠҠиҝҷдёӘlist.phpйЎөйқўзҡ„жүҖжңүй“ҫжҺҘaж Үзӯҫзҡ„hrefеұһжҖ§жҠ“еҸ–дёӢжқҘпјҢеӯҳе…ҘдёҖдёӘеҗҚеӯ—еҸ«еҒҡarticle_listзҡ„ж•°з»„пјҲеңЁpythonдёӯдёҚеҸ«ж•°з»„пјҢеҸ«еҒҡlistпјҢдёӯж–ҮеҗҚеҲ—иЎЁпјүпјҢ然еҗҺеҶҚз”ЁдёҖдёӘforеҫӘзҺҜйҒҚеҺҶиҝҷдёӘarticle_listж•°з»„пјҢз”Ёеҗ„з§ҚжҠ“еҸ–зҪ‘йЎөеҶ…е®№зҡ„еҮҪж•°жҠҠеҶ…е®№жҠ“еҸ–дёӢжқҘ然еҗҺеӯҳе…Ҙж•°жҚ®еә“гҖӮ
еҰӮжһңжҲ‘们иҰҒзј–еҶҷдёҖдёӘеӨҡзәҝзЁӢзҲ¬иҷ«жқҘе®ҢжҲҗиҝҷдёӘд»»еҠЎзҡ„иҜқпјҢе°ұеҒҮи®ҫжҲ‘们зҡ„зЁӢеәҸз”Ё10дёӘзәҝзЁӢжҠҠпјҢйӮЈд№ҲжҲ‘们е°ұиҰҒжғіеҠһжі•жҠҠд№ӢеүҚжҠ“еҸ–зҡ„article_listе№іеқҮеҲҶжҲҗ10д»ҪпјҢеҲҶеҲ«жҠҠжҜҸдёҖд»ҪеҲҶй…Қз»ҷе…¶дёӯдёҖдёӘеӯҗзәҝзЁӢгҖӮ
дҪҶжҳҜй—®йўҳжқҘдәҶпјҢеҰӮжһңжҲ‘们зҡ„article_listж•°з»„й•ҝеәҰдёҚжҳҜ10зҡ„еҖҚж•°пјҢд№ҹе°ұжҳҜж–Үз« ж•°йҮҸ并дёҚжҳҜ10зҡ„ж•ҙж•°еҖҚпјҢйӮЈд№Ҳ***дёҖдёӘзәҝзЁӢе°ұдјҡжҜ”еҲ«зҡ„зәҝзЁӢе°‘еҲҶй…ҚеҲ°дёҖдәӣд»»еҠЎпјҢйӮЈд№Ҳе®ғе°Ҷдјҡжӣҙеҝ«зҡ„з»“жқҹгҖӮ
еҰӮжһңд»…д»…жҳҜжҠ“еҸ–иҝҷз§ҚеҸӘжңүеҮ еҚғеӯ—зҡ„еҚҡе®ўж–Үз« иҝҷзңӢдјјжІЎд»Җд№Ҳй—®йўҳпјҢдҪҶжҳҜеҰӮжһңжҲ‘们дёҖдёӘд»»еҠЎпјҲдёҚдёҖе®ҡжҳҜжҠ“еҸ–зҪ‘йЎөзҡ„д»»еҠЎпјҢжңүеҸҜиғҪжҳҜж•°еӯҰи®Ўз®—пјҢжҲ–иҖ…еӣҫеҪўжёІжҹ“зӯүзӯүиҖ—ж—¶д»»еҠЎпјүзҡ„иҝҗиЎҢж—¶й—ҙеҫҲй•ҝпјҢйӮЈд№Ҳиҝҷе°ҶйҖ жҲҗжһҒеӨ§ең°иө„жәҗе’Ңж—¶й—ҙжөӘиҙ№гҖӮжҲ‘们еӨҡзәҝзЁӢзҡ„зӣ®зҡ„е°ұжҳҜе°ҪеҸҜиғҪзҡ„еҲ©з”ЁдёҖеҲҮи®Ўз®—иө„жәҗ并且计算时й—ҙпјҢжүҖд»ҘжҲ‘们иҰҒжғіеҠһжі•и®©д»»еҠЎиғҪеӨҹжӣҙеҠ 科еӯҰеҗҲзҗҶзҡ„еҲҶй…ҚгҖӮ
并且жҲ‘иҝҳиҰҒиҖғиҷ‘дёҖз§Қжғ…еҶөпјҢе°ұжҳҜж–Үз« ж•°йҮҸеҫҲеӨ§зҡ„жғ…еҶөдёӢпјҢжҲ‘们иҰҒж—ўиғҪеҝ«йҖҹжҠ“еҸ–еҲ°ж–Үз« еҶ…е®№пјҢеҸҲиғҪе°Ҫеҝ«зҡ„зңӢеҲ°жҲ‘们已з»ҸжҠ“еҸ–еҲ°зҡ„еҶ…е®№пјҢиҝҷз§ҚйңҖжұӮеңЁеҫҲеӨҡCMSйҮҮйӣҶз«ҷдёҠз»ҸеёёдјҡдҪ“зҺ°еҮәжқҘгҖӮ
жҜ”еҰӮиҜҙжҲ‘们зҺ°еңЁиҰҒжҠ“еҸ–зҡ„зӣ®ж ҮеҚҡе®ўпјҢжңүеҮ еҚғдёҮзҜҮж–Үз« пјҢйҖҡеёёиҝҷз§Қжғ…еҶөдёӢеҚҡе®ўйғҪдјҡеҒҡеҲҶйЎөеӨ„зҗҶпјҢйӮЈд№ҲжҲ‘们еҰӮжһңжҢүз…§дёҠйқўзҡ„дј з»ҹжҖқи·Ҝе…ҲжҠ“еҸ–е®Ңlist.phpзҡ„жүҖжңүйЎөйқўиө·з Ғе°ұиҰҒеҮ дёӘе°Ҹж—¶з”ҡиҮіеҮ еӨ©пјҢиҖҒжқҝеҰӮжһңеёҢжңӣдҪ иғҪеӨҹе°Ҫеҝ«жҳҫзӨәеҮәжҠ“еҸ–еҶ…е®№пјҢ并且е°Ҫеҝ«е°Ҷе·Із»ҸжҠ“еҸ–еҲ°зҡ„еҶ…е®№еұ•зҺ°еҲ°жҲ‘们зҡ„CMSйҮҮйӣҶз«ҷдёҠпјҢйӮЈд№ҲжҲ‘们е°ұиҰҒе®һзҺ°дёҖиҫ№жҠ“еҸ–list.php并且жҠҠе·Із»ҸжҠ“еҸ–еҲ°зҡ„ж•°жҚ®дёўе…ҘдёҖдёӘarticle_listж•°з»„пјҢдёҖиҫ№з”ЁеҸҰдёҖдёӘзәҝзЁӢд»Һarticle_listж•°з»„дёӯжҸҗеҸ–е·Із»ҸжҠ“еҸ–еҲ°зҡ„ж–Үз« URLең°еқҖпјҢ然еҗҺиҝҷдёӘзәҝзЁӢеҶҚеҺ»еҜ№еә”зҡ„URLең°еқҖдёӯз”ЁжӯЈеҲҷиЎЁиҫҫејҸеҸ–еҲ°еҚҡе®ўж–Үз« еҶ…е®№гҖӮеҰӮдҪ•е®һзҺ°иҝҷдёӘеҠҹиғҪе‘ўпјҹ
жҲ‘们е°ұйңҖиҰҒеҗҢж—¶ејҖеҗҜдёӨзұ»зәҝзЁӢпјҢдёҖзұ»зәҝзЁӢдё“й—ЁиҙҹиҙЈжҠ“еҸ–list.phpдёӯзҡ„url然еҗҺдёўе…Ҙarticle_listж•°з»„пјҢеҸҰеӨ–дёҖзұ»зәҝзЁӢдё“й—ЁиҙҹиҙЈд»Һarticle_listдёӯжҸҗеҸ–еҮәurl然еҗҺд»ҺеҜ№еә”зҡ„view.phpйЎөйқўдёӯжҠ“еҸ–еҮәеҜ№еә”зҡ„еҚҡе®ўеҶ…е®№гҖӮ
дҪҶжҳҜжҲ‘们жҳҜеҗҰиҝҳи®°еҫ—еүҚйқўжҸҗеҲ°иҝҮзәҝзЁӢе®үе…ЁиҝҷдёӘжҰӮеҝөпјҹеүҚдёҖзұ»зәҝзЁӢдёҖиҫ№еҫҖarticle_listж•°з»„дёӯеҶҷе…Ҙж•°жҚ®пјҢеҸҰеӨ–йӮЈдёҖзұ»зҡ„зәҝзЁӢд»Һarticle_listдёӯиҜ»еҸ–ж•°жҚ®е№¶дё”еҲ йҷӨе·Із»ҸиҜ»еҸ–е®ҢжҜ•зҡ„ж•°жҚ®гҖӮдҪҶжҳҜpythonдёӯlist并дёҚжҳҜзәҝзЁӢе®үе…ЁзүҲжң¬зҡ„ж•°жҚ®з»“жһ„пјҢеӣ жӯӨиҝҷж ·ж“ҚдҪңдјҡеҜјиҮҙдёҚеҸҜйў„ж–ҷзҡ„й”ҷиҜҜгҖӮжүҖд»ҘжҲ‘们еҸҜд»Ҙе°қиҜ•дҪҝз”ЁдёҖдёӘжӣҙеҠ ж–№дҫҝдё”зәҝзЁӢе®үе…Ёзҡ„ж•°жҚ®з»“жһ„пјҢиҝҷе°ұжҳҜжҲ‘们зҡ„еӯҗж ҮйўҳдёӯжүҖжҸҗеҲ°зҡ„QueueйҳҹеҲ—ж•°жҚ®з»“жһ„гҖӮ
еҗҢж ·Queueд№ҹжңүдёҖдёӘjoin()ж–№жі•пјҢиҝҷдёӘjoin()ж–№жі•е…¶е®һе’ҢдёҠдёҖдёӘе°ҸиҠӮжүҖи®ІеҲ°зҡ„threadingдёӯjoin()ж–№жі•е·®дёҚеӨҡпјҢеҸӘдёҚиҝҮеңЁQueueдёӯпјҢjoin()зҡ„йҳ»еЎһжқЎд»¶жҳҜеҪ“йҳҹеҲ—дёҚдёәз©әз©әзҡ„ж—¶еҖҷжүҚйҳ»еЎһпјҢеҗҰеҲҷ继з»ӯжү§иЎҢjoin()еҗҺйқўзҡ„д»Јз ҒгҖӮеңЁиҝҷдёӘзҲ¬иҷ«дёӯжҲ‘дҫҝдҪҝз”ЁдәҶиҝҷз§Қж–№жі•жқҘйҳ»еЎһдё»зәҝзЁӢиҖҢдёҚжҳҜзӣҙжҺҘйҖҡиҝҮзәҝзЁӢзҡ„joinж–№ејҸжқҘйҳ»еЎһдё»зәҝзЁӢпјҢиҝҷж ·зҡ„еҘҪеӨ„жҳҜеҸҜд»ҘдёҚз”ЁеҶҷдёҖдёӘжӯ»еҫӘзҺҜжқҘеҲӨж–ӯеҪ“еүҚд»»еҠЎйҳҹеҲ—дёӯжҳҜеҗҰиҝҳжңүжңӘжү§иЎҢе®Ңзҡ„д»»еҠЎпјҢи®©зЁӢеәҸиҝҗиЎҢжӣҙеҠ й«ҳж•ҲпјҢд№ҹи®©д»Јз ҒжӣҙеҠ дјҳйӣ…гҖӮ
иҝҳжңүдёҖдёӘз»ҶиҠӮе°ұжҳҜеңЁpython2.7дёӯйҳҹеҲ—жЁЎеқ—зҡ„еҗҚеӯ—жҳҜQueueпјҢиҖҢеңЁpython3.xдёӯе·Із»Ҹж”№еҗҚдёәqueueпјҢе°ұжҳҜйҰ–еӯ—жҜҚеӨ§е°ҸеҶҷзҡ„еҢәеҲ«пјҢеӨ§е®¶еҰӮжһңжҳҜеӨҚеҲ¶зҪ‘дёҠзҡ„д»Јз ҒпјҢиҰҒи®°еҫ—иҝҷдёӘе°ҸеҢәеҲ«гҖӮ
еҰӮжһңеӨ§е®¶еӯҰиҝҮcиҜӯиЁҖзҡ„иҜқпјҢеҜ№иҝҷдёӘжЁЎеқ—еә”иҜҘдјҡеҫҲзҶҹжӮүпјҢд»–е°ұжҳҜдёҖдёӘиҙҹиҙЈд»Һе‘Ҫд»ӨиЎҢдёӯзҡ„е‘Ҫд»ӨйҮҢйқўжҸҗеҸ–еҮәйҷ„еёҰеҸӮж•°зҡ„жЁЎеқ—гҖӮжҜ”еҰӮиҜҙжҲ‘们йҖҡеёёеңЁе‘Ҫд»ӨиЎҢдёӯж“ҚдҪңmysqlж•°жҚ®еә“пјҢе°ұжҳҜиҫ“е…Ҙmysql -h227.0.0.1 -uroot -pпјҢе…¶дёӯmysqlеҗҺйқўзҡ„вҖң-h227.0.0.1 -uroot -pвҖқе°ұжҳҜеҸҜд»ҘиҺ·еҸ–зҡ„еҸӮж•°йғЁеҲҶгҖӮ
жҲ‘们平时еңЁзј–еҶҷзҲ¬иҷ«зҡ„ж—¶еҖҷпјҢжңүдёҖдәӣеҸӮж•°жҳҜйңҖиҰҒз”ЁжҲ·иҮӘе·ұжүӢеҠЁиҫ“е…Ҙзҡ„пјҢжҜ”еҰӮиҜҙmysqlзҡ„дё»жңәIPпјҢз”ЁжҲ·еҗҚеҜҶз ҒзӯүзӯүгҖӮдёәдәҶи®©жҲ‘们зҡ„зЁӢеәҸжӣҙеҠ еҸӢеҘҪйҖҡз”ЁпјҢжңүдёҖдәӣй…ҚзҪ®йЎ№жҳҜдёҚйңҖиҰҒзЎ¬зј–з ҒеңЁд»Јз ҒйҮҢйқўпјҢиҖҢжҳҜеңЁжү§иЎҢд»–зҡ„ж—¶еҖҷжҲ‘们еҠЁжҖҒдј е…ҘпјҢз»“еҗҲgetoptжЁЎеқ—жҲ‘们е°ұеҸҜд»Ҙе®һзҺ°иҝҷдёӘеҠҹиғҪгҖӮ
е“ҲеёҢжң¬иҙЁдёҠе°ұжҳҜдёҖзұ»ж•°еӯҰз®—жі•зҡ„йӣҶеҗҲпјҢиҝҷз§Қж•°еӯҰз®—жі•жңүдёӘзү№жҖ§е°ұжҳҜдҪ з»ҷе®ҡдёҖдёӘеҸӮж•°пјҢд»–иғҪеӨҹиҫ“еҮәеҸҰеӨ–дёҖдёӘз»“жһңпјҢиҷҪ然иҝҷдёӘз»“жһңеҫҲзҹӯпјҢдҪҶжҳҜд»–еҸҜд»Ҙиҝ‘дјји®ӨдёәжҳҜ***зҡ„гҖӮжҜ”еҰӮиҜҙжҲ‘们平时еҗ¬иҝҮзҡ„md5пјҢsha-1зӯүзӯүпјҢ他们йғҪеұһдәҺе“ҲеёҢз®—жі•гҖӮ他们еҸҜд»ҘжҠҠдёҖдәӣж–Ү件пјҢж–Үеӯ—з»ҸиҝҮдёҖзі»еҲ—зҡ„ж•°еӯҰиҝҗз®—д№ӢеҗҺеҸҳжҲҗзҹӯзҹӯдёҚеҲ°дёҖзҷҫдҪҚзҡ„дёҖж®өж•°еӯ—иӢұж–Үж··еҗҲзҡ„еӯ—з¬ҰдёІгҖӮ
pythonдёӯзҡ„hashlibжЁЎеқ—е°ұдёәжҲ‘们е°ҒиЈ…еҘҪдәҶиҝҷдәӣж•°еӯҰиҝҗз®—еҮҪж•°пјҢжҲ‘们еҸӘйңҖиҰҒз®ҖеҚ•зҡ„и°ғз”Ёе®ғе°ұеҸҜд»Ҙе®ҢжҲҗе“ҲеёҢиҝҗз®—гҖӮ
дёәд»Җд№ҲеңЁжҲ‘иҝҷдёӘзҲ¬иҷ«дёӯз”ЁеҲ°дәҶиҝҷдёӘеҢ…е‘ўпјҹеӣ дёәеңЁдёҖдәӣжҺҘеҸЈиҜ·жұӮдёӯпјҢжңҚеҠЎеҷЁйңҖиҰҒеёҰдёҠдёҖдәӣж ЎйӘҢз ҒпјҢдҝқиҜҒжҺҘеҸЈиҜ·жұӮзҡ„ж•°жҚ®жІЎжңүиў«зҜЎж”№жҲ–иҖ…дёўеӨұпјҢиҝҷдәӣж ЎйӘҢз ҒдёҖиҲ¬йғҪжҳҜhashз®—жі•пјҢжүҖд»ҘжҲ‘们йңҖиҰҒз”ЁеҲ°иҝҷдёӘжЁЎеқ—жқҘе®ҢжҲҗиҝҷз§Қиҝҗз®—гҖӮ
еҫҲеӨҡж—¶еҖҷжҲ‘们жҠ“еҸ–еҲ°зҡ„ж•°жҚ®дёҚжҳҜhtmlпјҢиҖҢжҳҜдёҖдәӣjsonж•°жҚ®пјҢjsonжң¬иҙЁдёҠеҸӘжҳҜдёҖж®өеҗ«жңүй”®еҖјеҜ№зҡ„еӯ—з¬ҰдёІпјҢеҰӮжһңжҲ‘们йңҖиҰҒжҸҗеҸ–еҮәе…¶дёӯзү№е®ҡзҡ„еӯ—з¬ҰдёІпјҢйӮЈд№ҲжҲ‘们йңҖиҰҒjsonиҝҷдёӘжЁЎеқ—жқҘе°ҶиҝҷдёӘjsonеӯ—з¬ҰдёІиҪ¬жҚўдёәdictзұ»еһӢж–№дҫҝжҲ‘们ж“ҚдҪңгҖӮ
жңүзҡ„ж—¶еҖҷжҲ‘们жҠ“еҸ–еҲ°дәҶдёҖдәӣзҪ‘йЎөеҶ…е®№пјҢдҪҶжҳҜжҲ‘们йңҖиҰҒе°ҶзҪ‘йЎөдёӯзҡ„дёҖдәӣзү№е®ҡж јејҸзҡ„еҶ…е®№жҸҗеҸ–еҮәжқҘпјҢжҜ”еҰӮиҜҙз”өеӯҗйӮ®з®ұзҡ„ж јејҸдёҖиҲ¬йғҪжҳҜеүҚйқўеҮ дҪҚиӢұж–Үж•°еӯ—еӯ—жҜҚеҠ дёҖдёӘ@з¬ҰеҸ·еҠ http://xxx.xxxзҡ„еҹҹеҗҚпјҢиҖҢиҰҒеғҸи®Ўз®—жңәиҜӯиЁҖжҸҸиҝ°иҝҷз§Қж јејҸпјҢжҲ‘们еҸҜд»ҘдҪҝз”ЁдёҖз§ҚеҸ«еҒҡжӯЈеҲҷиЎЁиҫҫејҸзҡ„иЎЁиҫҫејҸжқҘиЎЁиҫҫеҮәиҝҷз§Қж јејҸпјҢ并且让计算жңәиҮӘеҠЁд»ҺдёҖеӨ§ж®өеӯ—з¬ҰдёІдёӯе°Ҷз¬ҰеҗҲиҝҷз§Қзү№е®ҡж јејҸзҡ„ж–Үеӯ—еҢ№й…ҚеҮәжқҘгҖӮ
иҝҷдёӘжЁЎеқ—дё»иҰҒз”ЁдәҺеӨ„зҗҶдёҖдәӣзі»з»ҹж–№йқўзҡ„дәӢжғ…пјҢеңЁиҝҷдёӘзҲ¬иҷ«дёӯжҲ‘з”Ёд»–жқҘи§ЈеҶіиҫ“еҮәзј–з Ғй—®йўҳгҖӮ
зЁҚеҫ®еӯҰиҝҮдёҖзӮ№иӢұиҜӯзҡ„дәәйғҪиғҪеӨҹзҢңеҮәжқҘиҝҷдёӘжЁЎеқ—з”ЁдәҺеӨ„зҗҶж—¶й—ҙпјҢеңЁиҝҷдёӘзҲ¬иҷ«дёӯжҲ‘з”Ёе®ғжқҘиҺ·еҸ–еҪ“еүҚж—¶й—ҙжҲіпјҢ然еҗҺйҖҡиҝҮеңЁдё»зәҝзЁӢжң«е°ҫз”ЁеҪ“еүҚж—¶й—ҙжҲіеҮҸеҺ»зЁӢеәҸејҖе§ӢиҝҗиЎҢж—¶зҡ„ж—¶й—ҙжҲіпјҢеҫ—еҲ°зЁӢеәҸзҡ„иҝҗиЎҢж—¶й—ҙгҖӮ
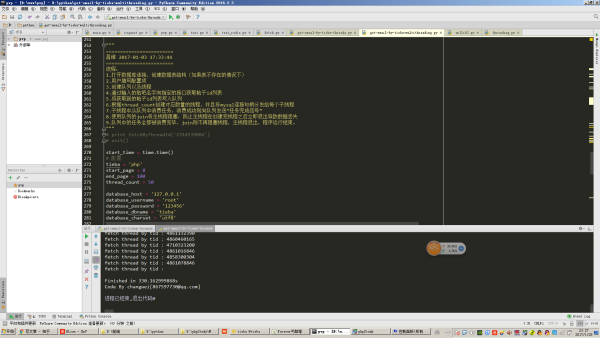
еҰӮеӣҫжүҖзӨәпјҢејҖ50дёӘзәҝзЁӢжҠ“еҸ–100йЎөпјҲжҜҸйЎө30дёӘеё–еӯҗпјҢзӣёеҪ“дәҺжҠ“еҸ–дәҶ3000дёӘеё–еӯҗпјүиҙҙеҗ§её–еӯҗеҶ…容并且д»ҺдёӯжҸҗеҸ–еҮәжүӢжңәйӮ®з®ұиҝҷдёӘжӯҘйӘӨе…ұиҖ—ж—¶330з§’гҖӮ
иҝҷдёӨдёӘжЁЎеқ—йғҪжҳҜз”ЁдәҺеӨ„зҗҶдёҖдәӣhttpиҜ·жұӮпјҢд»ҘеҸҠurlж јејҸеҢ–ж–№йқўзҡ„дәӢжғ…гҖӮжҲ‘зҡ„зҲ¬иҷ«httpиҜ·жұӮйғЁеҲҶзҡ„ж ёеҝғд»Јз Ғе°ұжҳҜдҪҝз”ЁиҝҷдёӘжЁЎеқ—е®ҢжҲҗзҡ„гҖӮ
иҝҷжҳҜдёҖдёӘ第дёүж–№жЁЎеқ—пјҢз”ЁдәҺеңЁpythonдёӯж“ҚдҪңmysqlж•°жҚ®еә“гҖӮ
иҝҷйҮҢжҲ‘们иҰҒжіЁж„ҸдёҖдёӘз»ҶиҠӮй—®йўҳпјҡmysqldbжЁЎеқ—并дёҚжҳҜзәҝзЁӢе®үе…ЁзүҲжң¬пјҢж„Ҹе‘ізқҖжҲ‘们дёҚиғҪеңЁеӨҡзәҝзЁӢдёӯе…ұдә«еҗҢдёҖдёӘmysqlиҝһжҺҘеҸҘжҹ„гҖӮжүҖд»ҘеӨ§е®¶еҸҜд»ҘеңЁжҲ‘зҡ„д»Јз ҒдёӯзңӢеҲ°пјҢжҲ‘еңЁжҜҸдёӘзәҝзЁӢзҡ„жһ„йҖ еҮҪж•°дёӯйғҪдј е…ҘдәҶдёҖдёӘж–°зҡ„mysqlиҝһжҺҘеҸҘжҹ„гҖӮеӣ жӯӨжҜҸдёӘеӯҗзәҝзЁӢеҸӘдјҡз”ЁиҮӘе·ұзӢ¬з«Ӣзҡ„mysqlиҝһжҺҘеҸҘжҹ„гҖӮ
иҝҷд№ҹжҳҜдёҖдёӘ第дёүж–№жЁЎеқ—пјҢзҪ‘дёҠиғҪеӨҹжүҫеҲ°зӣёе…ід»Јз ҒпјҢиҝҷдёӘжЁЎеқ—дё»иҰҒз”ЁдәҺеҗ‘е‘Ҫд»ӨиЎҢдёӯиҫ“еҮәеҪ©иүІеӯ—з¬ҰдёІгҖӮжҜ”еҰӮиҜҙжҲ‘们йҖҡеёёзҲ¬иҷ«еҮәзҺ°й”ҷиҜҜпјҢиҰҒиҫ“еҮәзәўиүІзҡ„еӯ—дҪ“дјҡжҜ”иҫғжҳҫзңјпјҢе°ұиҰҒдҪҝз”ЁеҲ°иҝҷдёӘжЁЎеқ—гҖӮ
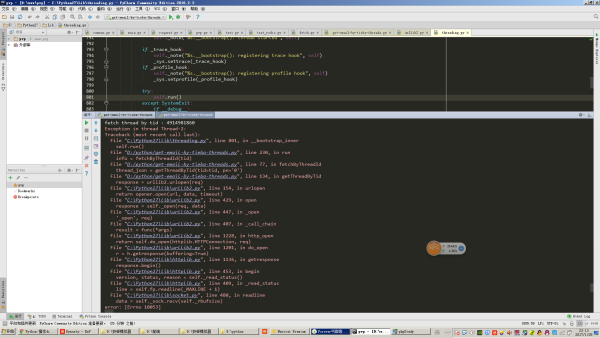
еҰӮжһңеӨ§е®¶еңЁзҪ‘з»ңиҙЁйҮҸдёҚжҳҜеҫҲеҘҪзҡ„зҺҜеўғдёӢдҪҝз”ЁиҜҘзҲ¬иҷ«пјҢдјҡеҸ‘зҺ°жңүзҡ„ж—¶еҖҷдјҡжҠҘеҰӮеӣҫжүҖзӨәзҡ„ејӮеёёпјҢиҝҷжҳҜжҲ‘дёәдәҶеҒ·жҮ’并没жңүеҶҷеҗ„з§ҚејӮеёёеӨ„зҗҶзҡ„йҖ»иҫ‘гҖӮ
йҖҡеёёжғ…еҶөдёӢжҲ‘们еҰӮжһңиҰҒзј–еҶҷй«ҳеәҰиҮӘеҠЁеҢ–зҡ„зҲ¬иҷ«пјҢйӮЈд№Ҳе°ұйңҖиҰҒйў„ж–ҷеҲ°жҲ‘们зҡ„зҲ¬иҷ«еҸҜиғҪдјҡйҒҮеҲ°зҡ„жүҖжңүејӮеёёжғ…еҶөпјҢй’ҲеҜ№иҝҷдәӣејӮеёёжғ…еҶөеҒҡеӨ„зҗҶгҖӮ
жҜ”еҰӮиҜҙеҰӮеӣҫжүҖзӨәзҡ„й”ҷиҜҜпјҢжҲ‘们е°ұеә”иҜҘжҠҠеҪ“ж—¶жӯЈеңЁеӨ„зҗҶзҡ„д»»еҠЎйҮҚж–°еЎһе…Ҙд»»еҠЎйҳҹеҲ—пјҢеҗҰеҲҷжҲ‘们е°ұдјҡеҮәзҺ°йҒ—жјҸдҝЎжҒҜзҡ„жғ…еҶөгҖӮиҝҷд№ҹжҳҜзҲ¬иҷ«зј–еҶҷзҡ„дёҖдёӘеӨҚжқӮзӮ№гҖӮ
д»ҘдёҠе°ұжҳҜеҰӮдҪ•дҪҝз”ЁPythonзј–еҶҷеӨҡзәҝзЁӢзҲ¬иҷ«жҠ“еҸ–зҷҫеәҰиҙҙеҗ§йӮ®з®ұдёҺжүӢжңәеҸ·пјҢе°Ҹзј–зӣёдҝЎжңүйғЁеҲҶзҹҘиҜҶзӮ№еҸҜиғҪжҳҜжҲ‘们ж—Ҙеёёе·ҘдҪңдјҡи§ҒеҲ°жҲ–з”ЁеҲ°зҡ„гҖӮеёҢжңӣдҪ иғҪйҖҡиҝҮиҝҷзҜҮж–Үз« еӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮжӣҙеӨҡиҜҰжғ…敬иҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ