您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
Graphlab怎么实现分析图的存储,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
前一段时间参与了一个迭代计算平台的开发,对于内存计算和图计算产生了比较浓厚的兴趣,这期间也阅读了spark和pregel的相关论文,了解一下BSP模型,但总觉得看论文太抽象了,于是选择阅读graphlab源码,作为深入了解图计算的一个契机。接下去如果有时间的话,会详细记录下我对graphlab的一些肤浅的理解。
在graphlab中,采用邻接矩阵来表示顶点之间的相邻关系,给定一个图G(V, E),使用一个一维数组存储V的顶点信息,使用一个稀疏矩阵来存储E的边信息。
在graphlab中,图是分布在多个机器之上,每个机器中存储着图的一部分,在这里我们讨论graphlab中,每个节点是如何实现图的本地存储。
在graphlab的图相关接口中有两个接口,分别是获取顶点的in edges和out edges。那么在graphlab中需要考虑如何有效地存储一个图的边集合,并可以快速地对顶点的in edges和out edges进行快速索引,并尽可能地减少空间开销。
Graphlab中采用的思路是同时采用稀疏矩阵的csr(compressed sparse row)和csc(compressed sparse column)存储格式来存储图的边集合,并高效地实现获取顶点的in edges和out edges的接口。
Graphlab分别实现了图的静态存储和动态存储,静态存储是指一旦完成对图的顶点和边的存储之后,不会添加新的顶点和边。而动态存储,可以动态地往图中新增顶点和边,这两者都没有删除顶点和边的操作。静态存储和动态存储的思路都是同时采用稀疏矩阵的csr和csc格式来存储边集合,不过csr和csr采用的数据结构不一样,静态存储采用数组实现,动态存储采用链表实现。在本篇博客中,只对静态存储进行介绍,动态存储会在下一篇博客中进行介绍。
首先会介绍一下稀疏矩阵的csr和csc格式以及计数排序,然后会举一个实际的例子来分析graphlab图的静态存储,介绍一下graphlab实现图静态存储的相关类。
1 稀疏矩阵csr和csc格式和计数排序简介
1.1 csr和csc格式介绍
csr是使用三个数组来表示一个稀疏矩阵,稀疏矩阵用A表示,三个数组分别是values、rowptrs和columns;values中按行顺序存储着A中的非零单元的值。Columns中存储着values数组中的单元的列索引,values(k) = A(i, j),则columns[k] = j。Rowptrs中存储着行在values中的起始地址,如果values(k) = A(i, j),则rowptrs(i) <= k <rowptrs(i + 1),行i中的非零单元的数目为rowptrs(i + 1) - rowptrs(i)。
比如稀疏矩阵A = 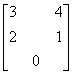
假设下标都从0开始,那么行是{0,1,2},列也是{0,1,2};稀疏矩阵A的csr格式就可以用如下三个数组表示:

csc格式类似于,只不过是把行换成了列,csc可以用values,columnptrs和rows表示矩阵A。values中按列顺序存储着A中的非零值;rows中存储着values数组中单元的行索引,values(k) = A(i, j),则rows(k) = i;columnptrs中存储着列在values中的起始地址,values(k) = A(i,j),则columns(j) <= k < columns(j + 1),j列的非零单元数目为columns(j + 1) - columns(j)。

关于csr的详细描述见:http://web.eecs.utk.edu/~dongarra/etemplates/node373.html
1.2 计数排序
计数排序的思路如下:假设n个输入元素中的每一个都是介于0-k的整数,此处k为某个整数。对每一个输入元素x,统计小于x的数目s,那么可以通过s来确定x在最终输出数组中的位置。
在graphlab中,计数排序的输入是一个未经排序的原始数组A;输出是两个数组,分别是P和I;P数组长度等于原始数组的长度,是按从小到大对原始数组进行排序后生成的序列数组,P[i]表示排序后的第i个值在原始数组中的下标;I数组表示值为i的整型在排序后的数组中的起始位置,I数组的长度为max{A[i]} + 1(+1的原因是从0开始计数)。
Graphlab中计数排序算法的伪码:

比如给定一个原始数组A,数组长度为7,数组中存储着整型值(可能有重复),如下图所示:
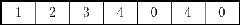
运行结果:
在counting_sort函数中12-13行的循环运行完后,原始数组(A)和统计数组(c)如下所示:

c[i]存储着在A中,值小于等于i的元素数目。
第15-16的运行步骤如下,总共有:
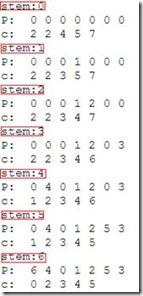
***P数组存储着排序后的数值在原数组中的下标。c数组中的每个单元c[i]中则存储着在A数组中,值小于i的元素数目。i在A中的数目等于:c[i + 1] - c[i],i < k或n - c[i] ,i == k;c[i]表示i值在P数组出现的***个值的下标。
最终I数组的结果等于stem 6中的c:

这三个数组之间的关系如下:
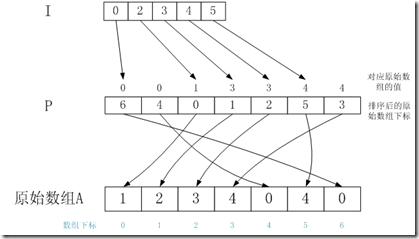
给定一个值2,那么2在A中的数目为:I[3] - I[2] = 1;2在A中的位置为A[P[I[2]] ] = A[1]。
2 使用csr和csc存储图
我们可以将边集合表示为一个邻接矩阵,使用稀疏矩阵的csr和csc格式来存储邻接矩阵。
因为稀疏矩阵的csr存储格式是对row进行压缩,可以根据row来快速对稀疏矩阵的某一行进行检索,所以使用csr来对out_edges进行检索(边(v,w)是顶点v的out edges,顶点v对于边(v,w)相当于行)。同理,稀疏矩阵的csc存储格式是对column进行压缩,可以根据column来快速对稀疏矩阵的某一列进行检索,所以使用csc对in_edges进行检索。
我们先单独分别从csr和csc角度考虑边集合的存储。然后再分析graphlab是如何同时使用csr和csc巧妙地实现对边集合进行存储,并实现对顶点的in edges和out edges快速检索。
2.1 CSR格式存储
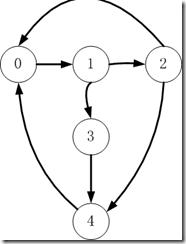
如上图所示,给定以一个有向图G(V,E),V为顶点集合,E为边集合。一条边包括顶点对(边从source vertex指向targe vertex)和值,边集合可以表示成如下的邻近矩阵,对于边(v,w),将v作为行,w作为列(source vertex对应行,target vertex对应列)。
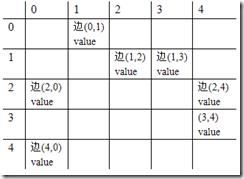
假设E中边的输入顺序如下所示:
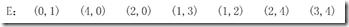
那么我们就可以用如下三个数组来表示输入的边集合E:
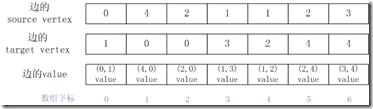
那么如何将输入的E转化为按照csr格式存储的稀疏矩阵呢?
1. 将source vertex数组作为输入数组,使用1.2张中的counting_sort进行排序,输出的数组为P和I。因为source vertex相当于邻接矩阵的行,这一步骤等同于将稀疏矩阵的非零单元按照行顺序存储在一个数组中(这里不需要考虑同一行内的各个边的顺序)。那么P是按行的从小到大顺序对原始数组进行排序后生成的序列数组;I等于csr中的rowptrs;
2. 使用P对输入边集合E的target vertex数组和value数组按照行大小进行重新排序,那么排序后的target vertex数组就是csr中的columns,value数组就是csr的values。这里的排序可以使用不同的方式实现,最简单的方法就是引入一个临时数组,按照P数组中的下标对target vertex和value进行排序。
counting_sort具体过程见1.2章(1.2张的例子就是本例),最终E的CSR格式如下图所示。
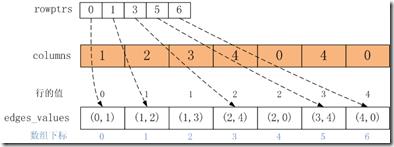
1.edges_values数组:是按行顺序进行排序后边集合的值数组。
2.rowptrs数组:保存行在edges_values中的起始偏移地址, rowptrs[i]是第i行在edges_values中的起始偏移位置;那么第i行的边数目等于rowptrs[i + 1] –rowptrs[i]或edges_values长度 – rowptrs[i ];rowptrs数组的长度为顶点的***值。
3.columns数组:列索引,columns[i]是edges_values[i]值对应的边的列的值。如edges_values[2]的列为columns[2],等于3。
那么用csr存储的边集合E,给定一个顶点v,可以快速检索v的所有out edges的值。v的值相当于行,那么v的所有out edges的值可以通过如下的方式获取:

拿上面的例子,顶点1的out edges的数目为rowptrs[2] – rowptrs[1] = 2,那么可以得到顶点1的两个out edges在edges_values数组的下标分别为1和2,那么out edges集合为{edges_values[1], edges_values[2]} = {(1,2), (1, 3)}。
2.2 CSC格式存储
使用csc来存储边集合E的边关系和值,与csr基本相同。首先将target vertex数组作为输入数组进行counting_sort,得到P和I,I为csc的columnptrs。使用P对E的source vertex数组和value数组进行排序,生成了csc的rows和values。E以csc格式存储的最终结果如下所示。
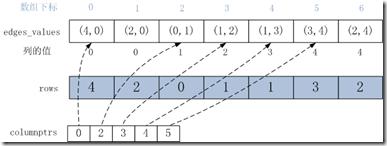
1.edges_values数组:是按列顺序进行排序后边集合的值数组。
2.columnptrs数组:保存列在edges_values中的起始偏移地址,columnptrs[i]是第i列在edges_values中的起始偏移位置;
3.rows数组:列索引,rows[i]是edges_values[i]值对应的边的列的值。
通过csc获取一个顶点的in edges类似于在csr中获取out edges,不在赘述。
2.3 Graphlab图的静态存储
Graphlab对图的静态存储是同时采用了csr和csc格式。在graphlab中,会首先对边集合按照csr方式进行存储(通过对source vertex进行counting_sort),然后再建立csc格式,通过shuffle方式,在csc和csr之间进行转换。把csr和csc整合到一起,同时实现对顶点的out edges和in edges的快速索引。如下图所示。
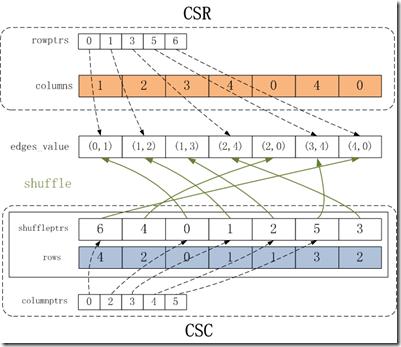
edges_value:同CSR中的rowptrs。
rowptrs:同CSR中的rowptrs。
columns:同CSR中的columns。
shuffleptrs:这个数组用于将按列顺序排列的稀疏矩阵转换为按行顺序排列的稀疏矩阵。Shuffleptrs[i]表示按列顺序排序的边集合的第i条边在edges_value数组中的下标。
rows:同CSC中的rows。
columnptrs:同CSC中的columnptrs。
如上图所示,在内存中存储边集合E,需要维持边的值数组,csr和csc。CSR有两个整型数组,rowptrs和columns,分别用来存储行偏移地址和列索引。CSC有三个整型数组,shuffleptrs、rows和columnptrs,分别存储着从按列顺序排序的稀疏矩阵到按行顺序排列的稀疏矩阵转换的下标,行索引和列偏移地址,shuffleptrs和rows具有相同的下标,可以合并成一个数组。
具体步骤如下:
E的原始输入由三个相同长度的数组组成,source_arr、target_arr和data_arr,分别存储着边的source vertex、target vertex和边的值。source vertex相当于邻接矩阵的行,target vertex相当于邻近矩阵的列。如果要形成最终的结果,需要以下这些步骤,才能形成上图中的存储。
1. counter_sort(source_arr, P, rowptrs)
2. sort(P, E)
//使用P按照行顺序对E中的三个数组进行排序,P数组是按照行的顺序保存着E的下标,
3. columns = target_arr
4. csr = {rowptrs, columns}
5. counter_sourt(target_arr, P, columnptrs)
6. sort(P, source_arr)
//对source_arr按列顺序进行排列,***作为行索引
7. rows = source_arr; shuffleptrs = P.
8. csc = {columnptrs, rows, shuffleptrs}
Graphlab中的具体类:
在graphlab中,图的本地静态存储是由local_graph来实现,local_graph中保存图使用了四个数据结构:
std::vector<VertexData> vertices:存储顶点数据的数组,顶点的ID为0到数组的长度。
std::vector<EdgeData> edges:存储边的值的数组,相当于edges_values。
csr_type _csr_storage:表示csr,由csr_storage这个类来实现。
csc_type _csc_storage:表示csc,由csr_storage这个类来实现。
csr_storage中有两个成员变量,分别是:
std::vector<sizetype> value_ptrs;
std::vector<valuetype> values;
当csr_storage表示csr时,value_ptrs等同于rowptrs,是一个uint64_t数组;values等同于columns,也是一个uint64_t数组。
当csr_storage表示csc时,value_ptrs等同于columnptrs,是一个uint64_t数组;values则被定义成std::vector< std::pair<lvid_type, edge_id_type> >,相当于将rows和shuffleptrs存储在同一个vector中。
3 存储结构
Graphlab实现对图的动态存储也是基于csr和csc格式,不过在csr和csc的底层数据结构设计上做了一些调整,将数组替换为分块链表。如果实现对图的动态存储,那么需要把底层的数据结构从数组换成链表,但需要对原先在静态图存储中所用的那套算法做些调整。
动态存储格式的CSR、CSC和边的值数数组如下图所示:
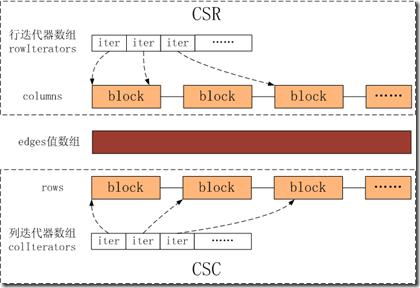
1. Edges是一个数组,数据结构使用vector,只是将批量插入的边的权值按顺序放入到vector中。
2. CSR是由行迭代器数组rowIterators和columns组成。columns是一个分块链表,表示按邻近矩阵的行(即边的source vertex)大小排序的列的链表,如上图所示,Block的内容如下,Block是固定长度的pair< uint64_t, uint64_t>数组,多个block组成一个链,pair的first是邻接矩阵的列(即边的target vertex),second是列所在的边在edges数组中的位置。CSR的rowIterators是对链表的行建立索引,rowIterator[i]指向行i在columns中的起始位置偏移地址。

3. 对于CSC是有列迭代器数组colIterators和rows组成。Rows是一个分块链表,表示按邻接矩阵的列(即边的target vertex)大小排序的行的链表,如上图所示,Block的内容如下,Block是固定长度的pair<uint64_t, uint64_t>的数组,多个block组成一个链,pair的first是邻接矩阵的行(即边的target vertex),second是行所在的边在edges数组中的位置。colIterators是对链表的列建立索引,colIterators[j]指向列j在rows中的起始位置偏移地址。

4 实现步骤
源码中对csr和csc的构建和动态插入的整体流程:
批量输入的边可以用三个数组来表示,source_vertex数组(边的源顶点),target_vertex数组(边的目标顶点)和边的值数组edge_values。
1. 对source_vertex数组进行计数排序,输出P1和rowptrs,P1是按行从小到大顺序对source_vertex进行排序后生成的序列数组;rowptrs[i]指向第i行在P1中的起始偏移地址,P1[rowptrs[i] + k ]表示第i行的第k个元素在edges数组中的位置,其中 0 <= k < (rowptrs[i + 1] - rowptrs[i])。
2. 对target_vertex数组进行计数排序,输出P2和colptrs,P2是按列从小到大顺序对target_vertex进行排序后生成的序列数组;colptrs[j]指向第j列在P2中的起始偏移地址,P2[colptrs[j] + k]表示第j列的第k个元素在edges数组中的位置,其中0 <= k < (colptrs[j + 1] - colptrs[j]);
3. 由于CSR的底层数据结构是分块链表和行迭代器数组指针,所以需要将计数排序后得到的rowptrs、P1和target_vertex转化为迭代器数组和pair<col,pos>数组。分块链表的block是固定长度的pair<col, pos>数组,所以利用P1和target_vertex来构建pair<col, pos>数组csr_values,第i个输入的边在csr_values中的值为{target_vertex[P1[i]], length(edges) + P1[i]}。
3.1 如果图为空,则用rowptrs和csr_values,来初始化CSR,即将csr_values中的值赋值给CSR的columns,然后将rowptrs的行起始位置转化为columns中的迭代器,放入到rowIterators中。
3.2 如果图不为空,则按行向CSR插入数据,一次插入一行,第i行在csr_values中的值是从csr_values[P1[i]]至csr_values[P1[i + 1]]这一段数据。如下图所示的CSR,rowIterators是一个迭代器的数组,rowIterators[i]存放第i行在columns中的起始位置,rowIterators[i + 1]为第i行的结束位置也是第i + 1行的起始位置;columns是一个分块链表。蓝色为第i行的数据,橙色为i+1行的数据。绿色为需要新插入的第i行的数据。
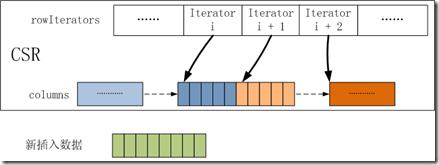
往第i行插入新数据,CSR插入行的步骤如下:
A. 首先会找到rowIterators[i+1]所指向的第i行的结束位置Pos,将此block中位于Pos之后的第i+1行的数据段预先保存起来。
B. 将第i行的新数据拷贝到Pos之后位置上,如果新插入的数据过长,那么会创建一个或多个新的block来容纳。
C. 将预先保存的第i+1行的数据重新拷贝到新插入数据之后。
如下图所示:
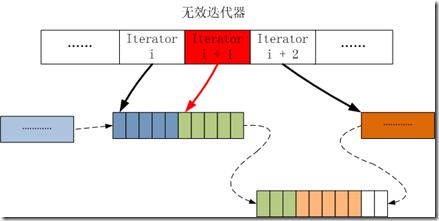
D. 在上述操作完成之后,第i+1行的迭代器指针变为无效,指向的数据位置为第i行新插入的数据,所以要调整第i+1行的迭代器指针。
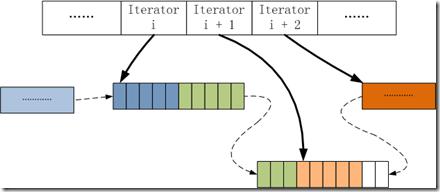
E. ***因为按行将数据插入到CSR中会产生一些空隙,如上图block中的白色空格,所以会在所有行都插入后,进行repack操作,将空白的内存进行压缩,变为下图所示:
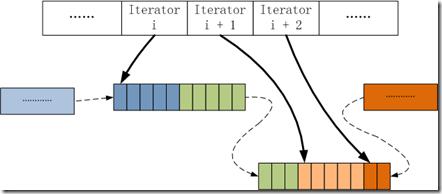
CSC的处理类似于CSR,不在赘述,这种做法的只能支持动态地批量插入,随机插入的性能开销太大。
5 Graphlab中相关的类
dynamic_block:图的动态存储的底层数据结构采用内存块的链表,可以进行动态的插入。Dynamic_block就是实现这个内存块的类,dynamic_block组成了一个块的链表。
block_linked_list:分块链表,是使用dynamic_block组成的一个单向链表。
dynamic_csr_storage:实现csr和csc动态存储的数据结构,将底层的数组替换为链表,然后使用链表的迭代器数组来实现记录行或列的起始位置。
dynamic_local_graph:实现图的动态存储的类,图的动态存储针对的情况是批量更新,而不是随机插入。
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。