您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容主要讲解“Redis中的BloomFilter简介及使用方法”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Redis中的BloomFilter简介及使用方法”吧!
介绍以及场景使用
BloomFilter 中文名就是 布隆过滤器,作为过滤器,有没有感觉很像 LOL 中布隆的 E技能(坚不可摧) ?
布隆过滤器是一个叫 布隆 的人提出来的,它是通过一个 大型位数组和几个不同的hash函数 来实现的,我们可以把布隆过滤器理解为一个 不精确的set 。我们都知道 set 可以去重,使用 set 可以帮我们判断集合中是否已经存在某些元素并且或者帮我们实现去重功能。
但是,set 提供精确的去重功能的同时也给我们带来了一个更大的问题——空间消耗。
比如这个时候我们进行网页爬虫,需要对爬过的 url 进行去重以避免爬到已经爬过的网站,如果我们使用 set 那么也就意味着我们需要将所有爬过的 url 放入集合中,假设一个 url 64字节,那么一亿个 url 意味着我们需要占用 6GB,十亿就是 60GB 左右。
请注意,是内存。
比如这个时候我们要进行垃圾邮件或者垃圾短信的过滤,我们需要从数十亿个垃圾邮件列表或者垃圾电话列表中进行判断此时的邮件或者短信是否是垃圾的。如果我们此时使用 set 那么占用空间不用我多说了,也是 百GB级别 的。
上面的面试中我提到了 缓存穿透 ,用户故意请求数据库本来就不存在的(比如ID = -1),这个时候如果不做处理那么肯定会穿透缓存去查询数据库,一个查询还好,如果几千,几万个同时进来呢?你的数据库顶得住吗?那么此时我们使用 set 进行处理,占用那么多内存空间,你觉得值得吗???或者说,还有没有更好的方法了?
上面所讲的三个典型场景,网站去重,垃圾邮件过滤,缓存穿透 ,这三个只要使用 BloomFilter 就能完美解决。
你有没有发现,上面三个场景其实对精度要求都不是很高,尤其是垃圾邮件过滤,其实偶尔收到几个垃圾邮件也无所谓的。像缓存穿透,也正好符合了 BloomFilter 的一个特性 他说有的不一定有,他说没有的肯定没有,我说你这个 ID 在数据库不存在那就真的不存在,老子把你过滤了就是这么自信,怎么,你打我???
聊了这么久的概念和应用场景,是不是还对 BloomFilter 怎么能进行去重的还是一脸懵逼? 下面我们就聊一聊 BloomFilter 的实现原理。首先给大家放一张结构图。
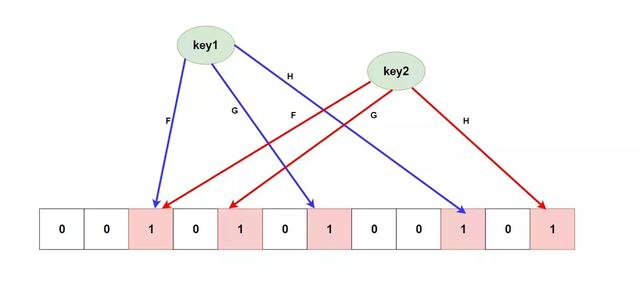
其中 F、G、H 是几种 无偏 Hash 函数,底下是一个 大型的位数组,当我们向 BloomFilter 添加数据的时候,它首先会将我们的数据(key)做几次hash运算(这里就是FGH),每个hash运算都会得到一个不用的位数组索引下标,此时我们就将算出的几个下标的位置的值改成1就行。如果判断元素是否存在,只要 判断所在的所有索引下标的值都是1 就行了。
其实你也发现了,在 BloomFilter 中会出现不同key所算出的下标重复了,如上图所示,这就是误差的来源( 你可以配置初始大小和错误率来控制误差 )也是他说有的不一定有,他说没有的肯定没有 这一特性的根本原因,因为如果全是0或者存在0那么肯定不存在,如果全是1也有可能是别的几个key给放进去的1。
因为 BloomFilter 是 Redis 的扩展模块,所以需要额外下载,你可以使用 Docker 进行拉取。安装步骤我不做详细解释,你可以到它的github上学习怎么安装
安装完之后我们就可以愉快的使用啦。
bf.add key element 添加
bf.exists key element 判断是否存在
bf.madd key element1 element2 ... 批量添加
bf.mexists key element1 element2 ... 批量判断
命令很简单,你可以自己去尝试。
介绍以及场景使用
在 Redis 中还有一个会存在误差的数据结构 HyperLogLog。
我们首先思考一个场景,当老板让我们计算页面的 UV 我们该怎么办?
如果访问量不大使用 set 进行用户去重完全可以,但是访问量如果有几百万,几千万,那么就会又遇到上面提到的 浪费空间 的问题。如果我们这个时候有一个能 进行去重且能进行计数的数据结构就好了。
这个时候 HyperLogLog 就闪亮登场了!它能提供不精确的去重计数方案(误差值在 0.81% 左右),不精确就不精确哇,UV 要你多精确?0.81%我们也能接受。最重要的是 HyperLogLog 只占用 12KB 的内存。
使用方法和场景实践
pfadd key element 添加
pfcount key 计算
pfmerge destkey sourcekey1 sourcekey2 ... 合并
命令都是 pf 开头是因为这是一个名叫 Philippe Flajolet 的教授发明的。
可以看到就这三个基本命令,很简单很容易掌握。那我们来动手实践一下吧。

介绍和使用场景
首先我们再来思考一个比较有意思的场景,老板想让你统计一年内多个用户之间他们同时在线的天数,这个时候你怎么办?
你可能会想到使用 hash 存储,这太浪费空间了,有没有更好的办法呢?答案是有的,Redis 中使用了 bitmap位图。

我们知道,字符串中一个字符是使用8个比特来表示的(如上图),在 Redis 中 bitmap 底层就是 string,也可以说 string 底层就是 bitmap。
如果有了这个我们是不是可以用来计算一个用户在指定时间内签到的次数?也就是一个位置代表一天,0代表未签到,1代表签到,在上图中,该用户在八天内签到了四次。
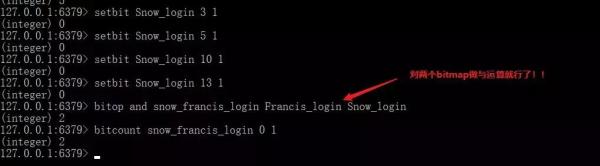
Redis 中的 bitmap 还提供了多个 bitmap 进行与,或,异或运算的命令,当然还有单个 bitmap 的 非 运算。这是不是给你提供了一点思路对于我们一开始的需求呢?
setbit key index 0/1 设置某位的值
getbit key index 获取某位的值
bitcount key start end 获取指定范围内为1的数量
需要注意的是,这里的start 和 end是指的字符位置不是比特位置!!!包括下面的 bitpos 也是
bitpos key bit start end 获取第一个值为bit的从start到end字符索引范围的位置
bitop and/or/xor/not destkey key1 key2 对多个 bitmap 进行逻辑运算。
对于bitmap还有一个好玩的指令就是 bitfield ,这里我不做过多介绍,感兴趣的同学自己可以了解一下。
我们首先来实现一下统计用户签到次数的功能。
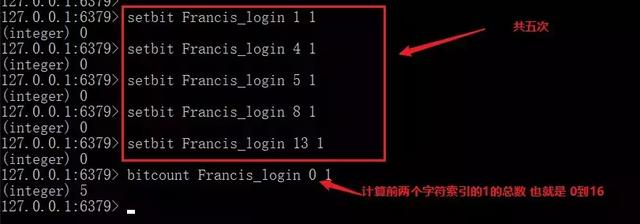
还记得我们一开始的问题吗?统计一年内多个用户之间他们同时在线的天数,我们有了 bitmap 还怕什么。
介绍和场景运用
GeoHash 常用来计算 附近的人,附近的商店。
试想一下如果我们使用 关系数据库 来存储某个元素的地址 (id,经度,纬度) 。这个时候我们该如何计算附近的人?难道我们要遍历所有元素位置并做距离计算?这显然不可能。
当然你可以使用划分区域并使用 SQL 语句圈出区域,然后建立 双向复合索引 来提升性能,但是数据库的并发能力毕竟有限,我们能不能使用 Redis 来做呢?
答案是可以的,Redis 中使用了 GeoHash 提供了很好的解决方案。具体原理是将地球看成一个平面,并把二维坐标映射成一维(精度损失的原因)。如果对其中的算法感兴趣你可以自己额外去了解,篇幅有限不做过多说明。
基本命令和使用实战
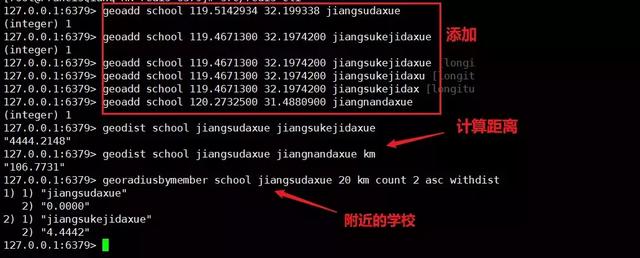
geoadd key longitude latitude element(后面可配置多个三元组) 添加元素
geodist key element1 element2 unit 计算两个元素的距离
geopos key element [element] 获取元素的位置
geohash key element 获取元素hash
georadiusbymember key element distanceValue unit count countValue ASC/DESC [withdist] [withhash] [withcoord] 获取元素附近的元素 可附加后面选项[距离][hash][坐标]
georadius key longitude latitude distanceValue unit count countValue ASC/DESC [withdist] [withhash] [withcoord] 和上面一样只是元素改成了指定坐标值
到此,相信大家对“Redis中的BloomFilter简介及使用方法”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。