您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
首先打开这个链接https://www.dingtalk.com/qiye/1.html,可以网页列出了很多企业,点击企业,就看到了企业的信息。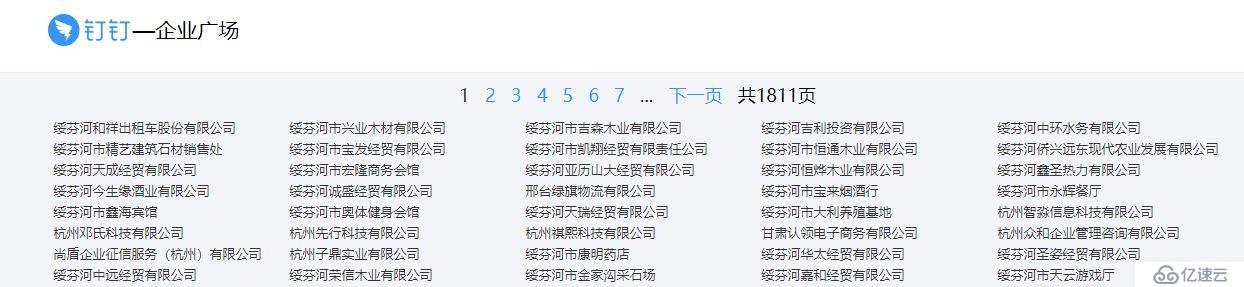
所以,我们的思路就很明确了,通过https://www.dingtalk.com/qiye/1.html这个入口链接获取企业的URL,然后通过访问企业的URL获取企业的信息。在jupyter notebook中试一下。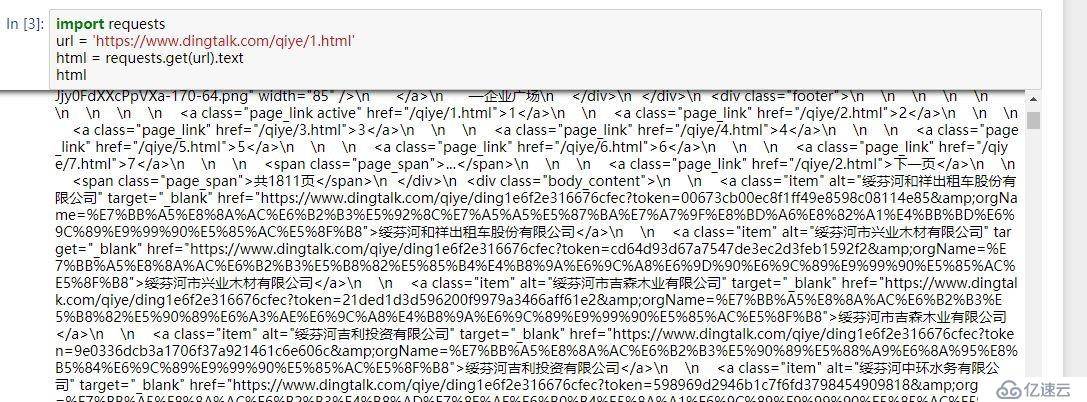
企业的URL已经获取到了,然后再访问企业的URL,看看能否获取到企业的信息。
没有。
写请求头,请求头包含两项,一个是cookie,一个user-agent。加上请求头再试试看,有了。
发现企业信息在js代码里,写正则表达式
patterns = r'"businessInfoData":{"enterpriseName":"(.*?)","frName":"(.*?)","enterpriseType":"(.*?)","enterpriseStatus":"(.*?)","regCap":"(.*?)","regCapCur":"(.*?)","esDate":"(.*?)","regOrg":"(.*?)","operateScope":"(.*?)","address":"(.*?)","regNo":"(.*?)","creditCode":"(.*?)","region":"(.*?)"}'
results = re.findall(patterns, html)ok,成功匹配出来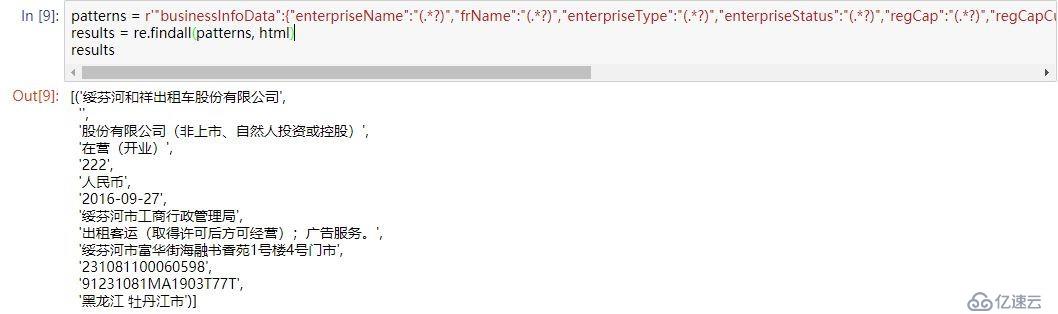
到此,发现很简单了,立马就把代码给写了出来,但发现一些问题,只有一部分企业的信息爬取了出来,大部分企业信息都获取失败了。这是咋回事呢,原来啊,有的企业URL源码里有企业信息,而有的没有。

然后,我查看完整企业信息,发现这个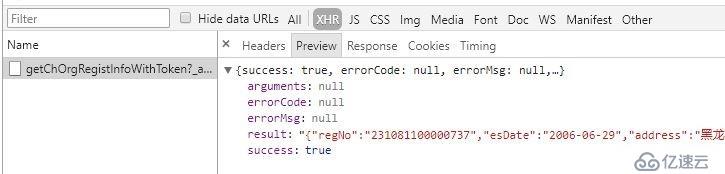
但是,我无法构造这个链接,忧伤。
所以,整个爬虫到此为止。写代码的时候,原本想用入口链接不断下一页获取所有企业URL,但一想,算了吧,直接简单粗暴一点。然后呢,爬取的时候,爬取速度好慢。
最后,附上垃圾的源码github。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。