жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№дё»иҰҒи®Іи§ЈвҖңGoи°ғеәҰеҷЁжҳҜеҰӮдҪ•еӨ„зҗҶзәҝзЁӢйҳ»еЎһзҡ„вҖқпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢдёҚеҰЁжқҘзңӢзңӢгҖӮжң¬ж–Үд»Ӣз»Қзҡ„ж–№жі•ж“ҚдҪңз®ҖеҚ•еҝ«жҚ·пјҢе®һз”ЁжҖ§ејәгҖӮдёӢйқўе°ұи®©е°Ҹзј–жқҘеёҰеӨ§е®¶еӯҰд№ вҖңGoи°ғеәҰеҷЁжҳҜеҰӮдҪ•еӨ„зҗҶзәҝзЁӢйҳ»еЎһзҡ„вҖқеҗ§!
жҖҺд№Ҳи®©жҲ‘们зҡ„зі»з»ҹжӣҙеҝ«
йҡҸзқҖдҝЎжҒҜжҠҖжңҜзҡ„иҝ…йҖҹеҸ‘еұ•пјҢеҚ•еҸ°жңҚеҠЎеҷЁеӨ„зҗҶиғҪеҠӣи¶ҠжқҘи¶ҠејәпјҢиҝ«дҪҝзј–зЁӢжЁЎејҸз”ұд»ҺеүҚзҡ„дёІиЎҢжЁЎејҸеҚҮзә§еҲ°е№¶еҸ‘жЁЎеһӢгҖӮ
并еҸ‘жЁЎеһӢеҢ…еҗ« IO еӨҡи·ҜеӨҚз”ЁгҖҒеӨҡиҝӣзЁӢд»ҘеҸҠеӨҡзәҝзЁӢпјҢиҝҷеҮ з§ҚжЁЎеһӢйғҪеҗ„жңүдјҳеҠЈпјҢзҺ°д»ЈеӨҚжқӮзҡ„й«ҳ并еҸ‘жһ¶жһ„еӨ§еӨҡжҳҜеҮ з§ҚжЁЎеһӢеҚҸеҗҢдҪҝз”ЁпјҢдёҚеҗҢеңәжҷҜеә”з”ЁдёҚеҗҢжЁЎеһӢпјҢжү¬й•ҝйҒҝзҹӯпјҢеҸ‘жҢҘжңҚеҠЎеҷЁзҡ„жңҖеӨ§жҖ§иғҪгҖӮ
иҖҢеӨҡзәҝзЁӢпјҢеӣ дёәе…¶иҪ»йҮҸе’Ңжҳ“з”ЁпјҢжҲҗдёә并еҸ‘зј–зЁӢдёӯдҪҝз”Ёйў‘зҺҮжңҖй«ҳзҡ„并еҸ‘жЁЎеһӢпјҢеҢ…жӢ¬еҗҺиЎҚз”ҹзҡ„еҚҸзЁӢзӯүе…¶д»–еӯҗдә§е“ҒпјҢд№ҹйғҪеҹәдәҺе®ғгҖӮ
并еҸ‘ ≠ 并иЎҢ
并еҸ‘ (concurrency) е’Ң 并иЎҢ ( parallelism) жҳҜдёҚеҗҢзҡ„гҖӮ
еңЁеҚ•дёӘ CPU ж ёдёҠпјҢзәҝзЁӢйҖҡиҝҮж—¶й—ҙзүҮжҲ–иҖ…и®©еҮәжҺ§еҲ¶жқғжқҘе®һзҺ°д»»еҠЎеҲҮжҚўпјҢиҫҫеҲ° "еҗҢж—¶" иҝҗиЎҢеӨҡдёӘд»»еҠЎзҡ„зӣ®зҡ„пјҢиҝҷе°ұжҳҜжүҖи°“зҡ„并еҸ‘гҖӮдҪҶе®һйҷ…дёҠд»»дҪ•ж—¶еҲ»йғҪеҸӘжңүдёҖдёӘд»»еҠЎиў«жү§иЎҢпјҢе…¶д»–д»»еҠЎйҖҡиҝҮжҹҗз§Қз®—жі•жқҘжҺ’йҳҹгҖӮ
еӨҡж ё CPU еҸҜд»Ҙи®©еҗҢдёҖиҝӣзЁӢеҶ…зҡ„ "еӨҡдёӘзәҝзЁӢ" еҒҡеҲ°зңҹжӯЈж„Ҹд№үдёҠзҡ„еҗҢж—¶иҝҗиЎҢпјҢиҝҷжүҚжҳҜ并иЎҢгҖӮ
иҝӣзЁӢгҖҒзәҝзЁӢгҖҒеҚҸзЁӢ
иҝӣзЁӢпјҡиҝӣзЁӢжҳҜзі»з»ҹиҝӣиЎҢиө„жәҗеҲҶй…Қзҡ„еҹәжң¬еҚ•дҪҚпјҢжңүзӢ¬з«Ӣзҡ„еҶ…еӯҳз©әй—ҙгҖӮ
зәҝзЁӢпјҡзәҝзЁӢжҳҜ CPU и°ғеәҰе’ҢеҲҶжҙҫзҡ„еҹәжң¬еҚ•дҪҚпјҢзәҝзЁӢдҫқйҷ„дәҺиҝӣзЁӢеӯҳеңЁпјҢжҜҸдёӘзәҝзЁӢдјҡе…ұдә«зҲ¶иҝӣзЁӢзҡ„иө„жәҗгҖӮ
еҚҸзЁӢпјҡеҚҸзЁӢжҳҜдёҖз§Қз”ЁжҲ·жҖҒзҡ„иҪ»йҮҸзә§зәҝзЁӢпјҢеҚҸзЁӢзҡ„и°ғеәҰе®Ңе…Ёз”ұз”ЁжҲ·жҺ§еҲ¶пјҢеҚҸзЁӢй—ҙеҲҮжҚўеҸӘйңҖиҰҒдҝқеӯҳд»»еҠЎзҡ„дёҠдёӢж–ҮпјҢжІЎжңүеҶ…ж ёзҡ„ејҖй”ҖгҖӮ
зәҝзЁӢдёҠдёӢж–ҮеҲҮжҚў
з”ұдәҺдёӯж–ӯеӨ„зҗҶпјҢеӨҡд»»еҠЎеӨ„зҗҶпјҢз”ЁжҲ·жҖҒеҲҮжҚўзӯүеҺҹеӣ дјҡеҜјиҮҙ CPU д»ҺдёҖдёӘзәҝзЁӢеҲҮжҚўеҲ°еҸҰдёҖдёӘзәҝзЁӢпјҢеҲҮжҚўиҝҮзЁӢйңҖиҰҒдҝқеӯҳеҪ“еүҚиҝӣзЁӢзҡ„зҠ¶жҖҒ并жҒўеӨҚеҸҰдёҖдёӘиҝӣзЁӢзҡ„зҠ¶жҖҒгҖӮ
дёҠдёӢж–ҮеҲҮжҚўзҡ„д»Јд»·жҳҜй«ҳжҳӮзҡ„пјҢеӣ дёәеңЁж ёеҝғдёҠдәӨжҚўзәҝзЁӢдјҡиҠұиҙ№еҫҲеӨҡж—¶й—ҙгҖӮдёҠдёӢж–ҮеҲҮжҚўзҡ„延иҝҹеҸ–еҶідәҺдёҚеҗҢзҡ„еӣ зҙ пјҢеӨ§жҰӮеңЁеңЁ 50 еҲ° 100 зәіз§’д№Ӣй—ҙгҖӮиҖғиҷ‘еҲ°зЎ¬д»¶е№іеқҮеңЁжҜҸдёӘж ёеҝғдёҠжҜҸзәіз§’жү§иЎҢ 12 жқЎжҢҮд»ӨпјҢйӮЈд№ҲдёҖж¬ЎдёҠдёӢж–ҮеҲҮжҚўеҸҜиғҪдјҡиҠұиҙ№ 600 еҲ° 1200 жқЎжҢҮд»Өзҡ„延иҝҹж—¶й—ҙгҖӮе®һйҷ…дёҠпјҢдёҠдёӢж–ҮеҲҮжҚўеҚ з”ЁдәҶеӨ§йҮҸзЁӢеәҸжү§иЎҢжҢҮд»Өзҡ„ж—¶й—ҙгҖӮ
еҰӮжһңеӯҳеңЁи·Ёж ёдёҠдёӢж–ҮеҲҮжҚў(Cross-Core Context Switch)пјҢеҸҜиғҪдјҡеҜјиҮҙ CPU зј“еӯҳеӨұж•Ҳ(CPU д»Һзј“еӯҳи®ҝй—®ж•°жҚ®зҡ„жҲҗжң¬еӨ§зәҰ 3 еҲ° 40 дёӘж—¶й’ҹе‘ЁжңҹпјҢд»Һдё»еӯҳи®ҝй—®ж•°жҚ®зҡ„жҲҗжң¬еӨ§зәҰ 100 еҲ° 300 дёӘж—¶й’ҹе‘Ёжңҹ)пјҢиҝҷз§ҚеңәжҷҜзҡ„еҲҮжҚўжҲҗжң¬дјҡжӣҙеҠ жҳӮиҙөгҖӮ
Golang дёә并еҸ‘иҖҢз”ҹ
Golang д»Һ 2009 е№ҙжӯЈејҸеҸ‘еёғд»ҘжқҘпјҢдҫқйқ е…¶жһҒй«ҳиҝҗиЎҢйҖҹеәҰе’Ңй«ҳж•Ҳзҡ„ејҖеҸ‘ж•ҲзҺҮпјҢиҝ…йҖҹеҚ жҚ®еёӮеңәд»ҪйўқгҖӮGolang д»ҺиҜӯиЁҖзә§еҲ«ж”ҜжҢҒ并еҸ‘пјҢйҖҡиҝҮиҪ»йҮҸзә§еҚҸзЁӢ Goroutine жқҘе®һзҺ°зЁӢеәҸ并еҸ‘иҝҗиЎҢгҖӮ
Goroutine йқһеёёиҪ»йҮҸпјҢдё»иҰҒдҪ“зҺ°еңЁд»ҘдёӢдёӨдёӘж–№йқўпјҡ
дёҠдёӢж–ҮеҲҮжҚўд»Јд»·е°Ҹпјҡ Goroutine дёҠдёӢж–ҮеҲҮжҚўеҸӘж¶үеҸҠеҲ°дёүдёӘеҜ„еӯҳеҷЁ(PC / SP / DX)зҡ„еҖјдҝ®ж”№;иҖҢеҜ№жҜ”зәҝзЁӢзҡ„дёҠдёӢж–ҮеҲҮжҚўеҲҷйңҖиҰҒж¶үеҸҠжЁЎејҸеҲҮжҚў(д»Һз”ЁжҲ·жҖҒеҲҮжҚўеҲ°еҶ…ж ёжҖҒ)гҖҒд»ҘеҸҠ 16 дёӘеҜ„еӯҳеҷЁгҖҒPCгҖҒSP…зӯүеҜ„еӯҳеҷЁзҡ„еҲ·ж–°;
еҶ…еӯҳеҚ з”Ёе°‘пјҡзәҝзЁӢж Ҳз©әй—ҙйҖҡеёёжҳҜ 2MпјҢGoroutine ж Ҳз©әй—ҙжңҖе°Ҹ 2K;
Golang зЁӢеәҸдёӯеҸҜд»ҘиҪ»жқҫж”ҜжҢҒ10w зә§еҲ«зҡ„ Goroutine иҝҗиЎҢпјҢиҖҢзәҝзЁӢж•°йҮҸиҫҫеҲ° 1k ж—¶пјҢеҶ…еӯҳеҚ з”Ёе°ұе·Із»ҸиҫҫеҲ° 2GгҖӮ
Go и°ғеәҰеҷЁе®һзҺ°жңәеҲ¶пјҡ
Go зЁӢеәҸйҖҡиҝҮи°ғеәҰеҷЁжқҘи°ғеәҰGoroutine еңЁеҶ…ж ёзәҝзЁӢдёҠжү§иЎҢпјҢдҪҶжҳҜ Goroutine 并дёҚзӣҙжҺҘз»‘е®ҡ OS зәҝзЁӢ M - MachineиҝҗиЎҢпјҢиҖҢжҳҜз”ұ Goroutine Scheduler дёӯзҡ„ P - Processor (йҖ»иҫ‘еӨ„зҗҶеҷЁ)жқҘдҪңиҺ·еҸ–еҶ…ж ёзәҝзЁӢиө„жәҗзҡ„гҖҺдёӯд»ӢгҖҸгҖӮ
Go и°ғеәҰеҷЁжЁЎеһӢжҲ‘们йҖҡеёёеҸ«еҒҡG-P-M жЁЎеһӢпјҢд»–еҢ…жӢ¬ 4 дёӘйҮҚиҰҒз»“жһ„пјҢеҲҶеҲ«жҳҜGгҖҒPгҖҒMгҖҒSchedпјҡ
G:GoroutineпјҢжҜҸдёӘ Goroutine еҜ№еә”дёҖдёӘ G з»“жһ„дҪ“пјҢG еӯҳеӮЁ Goroutine зҡ„иҝҗиЎҢе Ҷж ҲгҖҒзҠ¶жҖҒд»ҘеҸҠд»»еҠЎеҮҪж•°пјҢеҸҜйҮҚз”ЁгҖӮ
G 并йқһжү§иЎҢдҪ“пјҢжҜҸдёӘ G йңҖиҰҒз»‘е®ҡеҲ° P жүҚиғҪиў«и°ғеәҰжү§иЎҢгҖӮ
P: ProcessorпјҢиЎЁзӨәйҖ»иҫ‘еӨ„зҗҶеҷЁпјҢеҜ№ G жқҘиҜҙпјҢP зӣёеҪ“дәҺ CPU ж ёпјҢG еҸӘжңүз»‘е®ҡеҲ° P жүҚиғҪиў«и°ғеәҰгҖӮеҜ№ M жқҘиҜҙпјҢP жҸҗдҫӣдәҶзӣёе…ізҡ„жү§иЎҢзҺҜеўғ(Context)пјҢеҰӮеҶ…еӯҳеҲҶй…ҚзҠ¶жҖҒ(mcache)пјҢд»»еҠЎйҳҹеҲ—(G)зӯүгҖӮ
P зҡ„ж•°йҮҸеҶіе®ҡдәҶзі»з»ҹеҶ…жңҖеӨ§еҸҜ并иЎҢзҡ„ G зҡ„ж•°йҮҸ(еүҚжҸҗпјҡзү©зҗҶ CPU ж ёж•° >= P зҡ„ж•°йҮҸ)гҖӮ
P зҡ„ж•°йҮҸз”ұз”ЁжҲ·и®ҫзҪ®зҡ„ GoMAXPROCS еҶіе®ҡпјҢдҪҶжҳҜдёҚи®ә GoMAXPROCS и®ҫзҪ®дёәеӨҡеӨ§пјҢP зҡ„ж•°йҮҸжңҖеӨ§дёә 256гҖӮ
M: MachineпјҢOS еҶ…ж ёзәҝзЁӢжҠҪиұЎпјҢд»ЈиЎЁзқҖзңҹжӯЈжү§иЎҢи®Ўз®—зҡ„иө„жәҗпјҢеңЁз»‘е®ҡжңүж•Ҳзҡ„ P еҗҺпјҢиҝӣе…Ҙ schedule еҫӘзҺҜ;иҖҢ schedule еҫӘзҺҜзҡ„жңәеҲ¶еӨ§иҮҙжҳҜд»Һ Global йҳҹеҲ—гҖҒP зҡ„ Local йҳҹеҲ—д»ҘеҸҠ wait йҳҹеҲ—дёӯиҺ·еҸ–гҖӮ
M зҡ„ж•°йҮҸжҳҜдёҚе®ҡзҡ„пјҢз”ұ Go Runtime и°ғж•ҙпјҢдёәдәҶйҳІжӯўеҲӣе»әиҝҮеӨҡ OS зәҝзЁӢеҜјиҮҙзі»з»ҹи°ғеәҰдёҚиҝҮжқҘпјҢзӣ®еүҚй»ҳи®ӨжңҖеӨ§йҷҗеҲ¶дёә 10000 дёӘгҖӮ
M 并дёҚдҝқз•ҷ G зҠ¶жҖҒпјҢиҝҷжҳҜ G еҸҜд»Ҙи·Ё M и°ғеәҰзҡ„еҹәзЎҖгҖӮ
SchedпјҡGo и°ғеәҰеҷЁпјҢе®ғз»ҙжҠӨжңүеӯҳеӮЁ M е’Ң G зҡ„йҳҹеҲ—д»ҘеҸҠи°ғеәҰеҷЁзҡ„дёҖдәӣзҠ¶жҖҒдҝЎжҒҜзӯүгҖӮ
и°ғеәҰеҷЁеҫӘзҺҜзҡ„жңәеҲ¶еӨ§иҮҙжҳҜд»Һеҗ„з§ҚйҳҹеҲ—гҖҒP зҡ„жң¬ең°йҳҹеҲ—дёӯиҺ·еҸ– GпјҢеҲҮжҚўеҲ° G зҡ„жү§иЎҢж ҲдёҠ并жү§иЎҢ G зҡ„еҮҪж•°пјҢи°ғз”Ё Goexit еҒҡжё…зҗҶе·ҘдҪң并еӣһеҲ° MпјҢеҰӮжӯӨеҸҚеӨҚгҖӮ
зҗҶи§Ј MгҖҒPгҖҒG дёүиҖ…зҡ„е…ізі»пјҢеҸҜд»ҘйҖҡиҝҮз»Ҹе…ёзҡ„ең°йј жҺЁиҪҰжҗ¬з –зҡ„жЁЎеһӢжқҘиҜҙжҳҺе…¶дёүиҖ…е…ізі»пјҡ
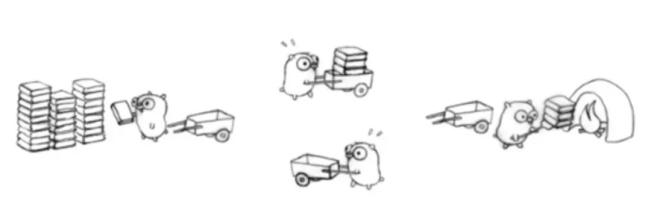
ең°йј (Gopher)зҡ„е·ҘдҪңд»»еҠЎжҳҜпјҡе·Ҙең°дёҠжңүиӢҘе№Із –еӨҙпјҢең°йј еҖҹеҠ©е°ҸиҪҰжҠҠз –еӨҙиҝҗйҖҒеҲ°зҒ«з§ҚдёҠеҺ»зғ§еҲ¶гҖӮM е°ұеҸҜд»ҘзңӢдҪңеӣҫдёӯзҡ„ең°йј пјҢP е°ұжҳҜе°ҸиҪҰпјҢG е°ұжҳҜе°ҸиҪҰйҮҢиЈ…зҡ„з –гҖӮ
еј„жё…жҘҡдәҶе®ғ们дёүиҖ…зҡ„е…ізі»пјҢдёӢйқўжҲ‘们е°ұејҖе§ӢйҮҚзӮ№иҒҠең°йј жҳҜеҰӮдҪ•еңЁжҗ¬иҝҗз –еқ—зҡ„гҖӮ
Processor(P)пјҡ
ж №жҚ®з”ЁжҲ·и®ҫзҪ®зҡ„ GoMAXPROCS еҖјжқҘеҲӣе»әдёҖжү№е°ҸиҪҰ(P)гҖӮ
Goroutine(G)пјҡ
йҖҡиҝҮ Go е…ій”®еӯ—е°ұжҳҜз”ЁжқҘеҲӣе»әдёҖдёӘ GoroutineпјҢд№ҹе°ұзӣёеҪ“дәҺеҲ¶йҖ дёҖеқ—з –(G)пјҢ然еҗҺе°Ҷиҝҷеқ—з –(G)ж”ҫе…ҘеҪ“еүҚиҝҷиҫҶе°ҸиҪҰ(P)дёӯгҖӮ
Machine (M)пјҡ
ең°йј (M)дёҚиғҪйҖҡиҝҮеӨ–йғЁеҲӣе»әеҮәжқҘпјҢеҸӘиғҪз –(G)еӨӘеӨҡдәҶпјҢең°йј (M)еҸҲеӨӘе°‘дәҶпјҢе®һеңЁеҝҷдёҚиҝҮжқҘпјҢеҲҡеҘҪиҝҳжңүз©әй—Ізҡ„е°ҸиҪҰ(P)жІЎжңүдҪҝз”ЁпјҢйӮЈе°ұд»ҺеҲ«еӨ„еҶҚеҖҹдәӣең°йј (M)иҝҮжқҘзӣҙеҲ°жҠҠе°ҸиҪҰ(P)з”Ёе®ҢдёәжӯўгҖӮ
иҝҷйҮҢжңүдёҖдёӘең°йј (M)дёҚеӨҹз”ЁпјҢд»ҺеҲ«еӨ„еҖҹең°йј (M)зҡ„иҝҮзЁӢпјҢиҝҷдёӘиҝҮзЁӢе°ұжҳҜеҲӣе»әдёҖдёӘеҶ…ж ёзәҝзЁӢ(M)гҖӮ
йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҡең°йј (M) еҰӮжһңжІЎжңүе°ҸиҪҰ(P)жҳҜжІЎеҠһжі•иҝҗз –зҡ„пјҢе°ҸиҪҰ(P)зҡ„ж•°йҮҸеҶіе®ҡдәҶиғҪеӨҹе№Іжҙ»зҡ„ең°йј (M)ж•°йҮҸпјҢеңЁ Go зЁӢеәҸйҮҢйқўеҜ№еә”зҡ„жҳҜжҙ»еҠЁзәҝзЁӢж•°;
еңЁ Go зЁӢеәҸйҮҢжҲ‘们йҖҡиҝҮдёӢйқўзҡ„еӣҫзӨәжқҘеұ•зӨә G-P-M жЁЎеһӢпјҡ
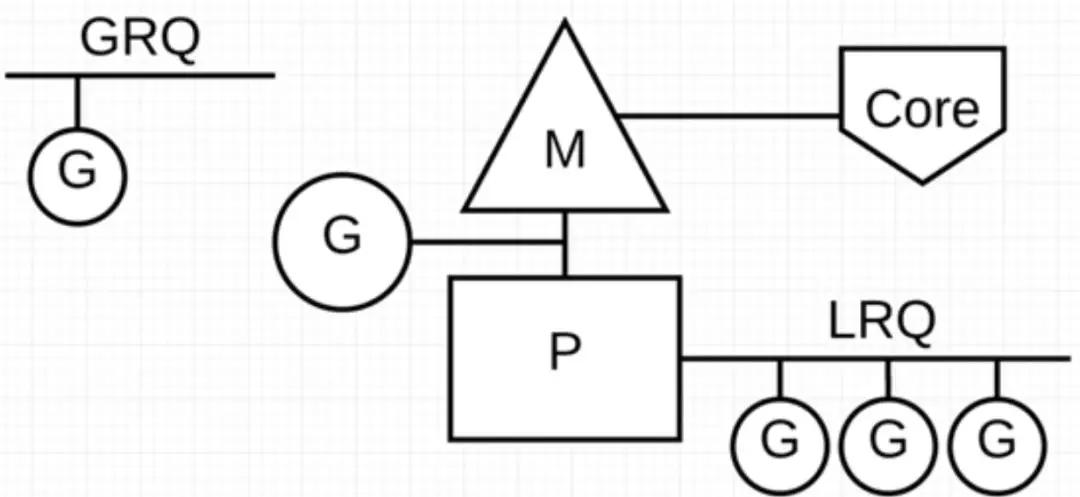
P д»ЈиЎЁеҸҜд»ҘвҖң并иЎҢвҖқиҝҗиЎҢзҡ„йҖ»иҫ‘еӨ„зҗҶеҷЁпјҢжҜҸдёӘ P йғҪиў«еҲҶй…ҚеҲ°дёҖдёӘзі»з»ҹзәҝзЁӢ MпјҢG д»ЈиЎЁ Go еҚҸзЁӢгҖӮ
Go и°ғеәҰеҷЁдёӯжңүдёӨдёӘдёҚеҗҢзҡ„иҝҗиЎҢйҳҹеҲ—пјҡе…ЁеұҖиҝҗиЎҢйҳҹеҲ—(GRQ)е’Ңжң¬ең°иҝҗиЎҢйҳҹеҲ—(LRQ)гҖӮ
жҜҸдёӘ P йғҪжңүдёҖдёӘ LRQпјҢз”ЁдәҺз®ЎзҗҶеҲҶй…Қз»ҷеңЁ P зҡ„дёҠдёӢж–Үдёӯжү§иЎҢзҡ„ GoroutinesпјҢиҝҷдәӣ Goroutine иҪ®жөҒиў«е’Ң P з»‘е®ҡзҡ„ M иҝӣиЎҢдёҠдёӢж–ҮеҲҮжҚўгҖӮGRQ йҖӮз”ЁдәҺе°ҡжңӘеҲҶй…Қз»ҷ P зҡ„ GoroutinesгҖӮ
д»ҺдёҠеӣҫеҸҜд»ҘзңӢеҮәпјҢG зҡ„ж•°йҮҸеҸҜд»ҘиҝңиҝңеӨ§дәҺ M зҡ„ж•°йҮҸпјҢжҚўеҸҘиҜқиҜҙпјҢGo зЁӢеәҸеҸҜд»ҘеҲ©з”Ёе°‘йҮҸзҡ„еҶ…ж ёзә§зәҝзЁӢжқҘж”Ҝж’‘еӨ§йҮҸ Goroutine зҡ„并еҸ‘гҖӮеӨҡдёӘ Goroutine йҖҡиҝҮз”ЁжҲ·зә§еҲ«зҡ„дёҠдёӢж–ҮеҲҮжҚўжқҘе…ұдә«еҶ…ж ёзәҝзЁӢ M зҡ„и®Ўз®—иө„жәҗпјҢдҪҶеҜ№дәҺж“ҚдҪңзі»з»ҹжқҘиҜҙ并没жңүзәҝзЁӢдёҠдёӢж–ҮеҲҮжҚўдә§з”ҹзҡ„жҖ§иғҪжҚҹиҖ—гҖӮ
дёәдәҶжӣҙеҠ е……еҲҶеҲ©з”ЁзәҝзЁӢзҡ„и®Ўз®—иө„жәҗпјҢGo и°ғеәҰеҷЁйҮҮеҸ–дәҶд»ҘдёӢеҮ з§Қи°ғеәҰзӯ–з•Ҙпјҡ
д»»еҠЎзӘғеҸ–(work-stealing)
жҲ‘们зҹҘйҒ“пјҢзҺ°е®һжғ…еҶөжңүзҡ„ Goroutine иҝҗиЎҢзҡ„еҝ«пјҢжңүзҡ„ж…ўпјҢйӮЈд№ҲеҠҝеҝ…иӮҜе®ҡдјҡеёҰжқҘзҡ„й—®йўҳе°ұжҳҜпјҢеҝҷзҡ„еҝҷжӯ»пјҢй—Ізҡ„й—Іжӯ»пјҢGo иӮҜе®ҡдёҚе…Ғи®ёж‘ёйұјзҡ„ P еӯҳеңЁпјҢеҠҝеҝ…иҰҒе……еҲҶеҲ©з”ЁеҘҪи®Ўз®—иө„жәҗгҖӮ
дёәдәҶжҸҗй«ҳ Go 并иЎҢеӨ„зҗҶиғҪеҠӣпјҢи°ғй«ҳж•ҙдҪ“еӨ„зҗҶж•ҲзҺҮпјҢеҪ“жҜҸдёӘ P д№Ӣй—ҙзҡ„ G д»»еҠЎдёҚеқҮиЎЎж—¶пјҢи°ғеәҰеҷЁе…Ғи®ёд»Һ GRQпјҢжҲ–иҖ…е…¶д»– P зҡ„ LRQ дёӯиҺ·еҸ– G жү§иЎҢгҖӮ
еҮҸе°‘йҳ»еЎһ
еҰӮжһңжӯЈеңЁжү§иЎҢзҡ„ Goroutine йҳ»еЎһдәҶзәҝзЁӢ M жҖҺд№ҲеҠһ?P дёҠ LRQ дёӯзҡ„ Goroutine дјҡиҺ·еҸ–дёҚеҲ°и°ғеәҰд№Ҳ?
еңЁ Go йҮҢйқўйҳ»еЎһдё»иҰҒеҲҶдёәдёҖдёӢ 4 з§ҚеңәжҷҜпјҡ
еңәжҷҜ 1пјҡз”ұдәҺеҺҹеӯҗгҖҒдә’ж–ҘйҮҸжҲ–йҖҡйҒ“ж“ҚдҪңи°ғз”ЁеҜјиҮҙ Goroutine йҳ»еЎһпјҢи°ғеәҰеҷЁе°ҶжҠҠеҪ“еүҚйҳ»еЎһзҡ„ Goroutine еҲҮжҚўеҮәеҺ»пјҢйҮҚж–°и°ғеәҰ LRQ дёҠзҡ„е…¶д»– Goroutine;
еңәжҷҜ 2пјҡз”ұдәҺзҪ‘з»ңиҜ·жұӮе’Ң IO ж“ҚдҪңеҜјиҮҙ Goroutine йҳ»еЎһпјҢиҝҷз§Қйҳ»еЎһзҡ„жғ…еҶөдёӢпјҢжҲ‘们зҡ„ G е’Ң M еҸҲдјҡжҖҺд№ҲеҒҡе‘ў?
Go зЁӢеәҸжҸҗдҫӣдәҶзҪ‘з»ңиҪ®иҜўеҷЁ(NetPoller)жқҘеӨ„зҗҶзҪ‘з»ңиҜ·жұӮе’Ң IO ж“ҚдҪңзҡ„й—®йўҳпјҢе…¶еҗҺеҸ°йҖҡиҝҮ kqueue(MacOS)пјҢepoll(Linux)жҲ– iocp(Windows)жқҘе®һзҺ° IO еӨҡи·ҜеӨҚз”ЁгҖӮ
йҖҡиҝҮдҪҝз”Ё NetPoller иҝӣиЎҢзҪ‘з»ңзі»з»ҹи°ғз”ЁпјҢи°ғеәҰеҷЁеҸҜд»ҘйҳІжӯў Goroutine еңЁиҝӣиЎҢиҝҷдәӣзі»з»ҹи°ғз”Ёж—¶йҳ»еЎһ MгҖӮиҝҷеҸҜд»Ҙи®© M жү§иЎҢ P зҡ„ LRQ дёӯе…¶д»–зҡ„ GoroutinesпјҢиҖҢдёҚйңҖиҰҒеҲӣе»әж–°зҡ„ MгҖӮжңүеҠ©дәҺеҮҸе°‘ж“ҚдҪңзі»з»ҹдёҠзҡ„и°ғеәҰиҙҹиҪҪгҖӮ
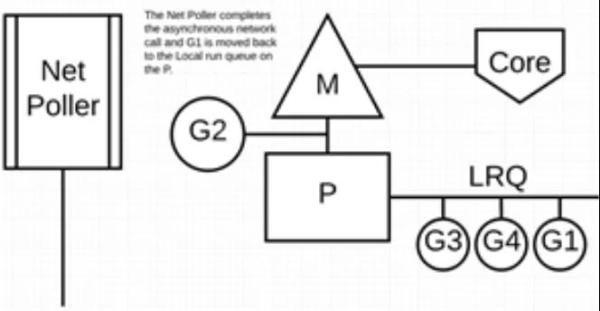
дёӢеӣҫеұ•зӨәе®ғзҡ„е·ҘдҪңеҺҹзҗҶпјҡG1 жӯЈеңЁ M дёҠжү§иЎҢпјҢиҝҳжңү 3 дёӘ Goroutine еңЁ LRQ дёҠзӯүеҫ…жү§иЎҢгҖӮзҪ‘з»ңиҪ®иҜўеҷЁз©әй—ІзқҖпјҢд»Җд№ҲйғҪжІЎе№ІгҖӮ
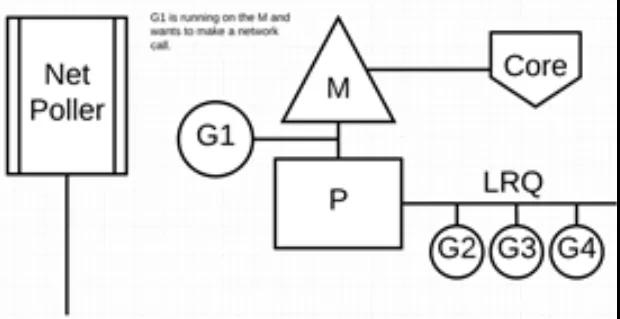
жҺҘдёӢжқҘпјҢG1 жғіиҰҒиҝӣиЎҢзҪ‘з»ңзі»з»ҹи°ғз”ЁпјҢеӣ жӯӨе®ғ被移еҠЁеҲ°зҪ‘з»ңиҪ®иҜўеҷЁе№¶дё”еӨ„зҗҶејӮжӯҘзҪ‘з»ңзі»з»ҹи°ғз”ЁгҖӮ然еҗҺпјҢM еҸҜд»Ҙд»Һ LRQ жү§иЎҢеҸҰеӨ–зҡ„ GoroutineгҖӮжӯӨж—¶пјҢG2 е°ұиў«дёҠдёӢж–ҮеҲҮжҚўеҲ° M дёҠдәҶгҖӮ
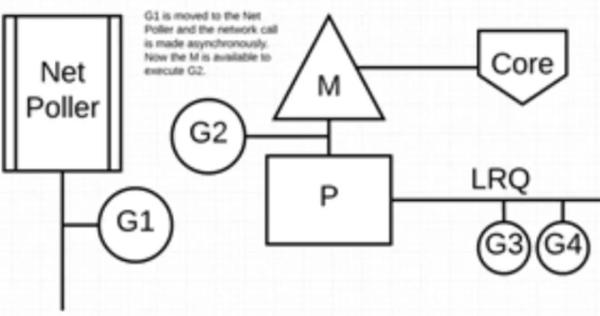
жңҖеҗҺпјҢејӮжӯҘзҪ‘з»ңзі»з»ҹи°ғз”Ёз”ұзҪ‘з»ңиҪ®иҜўеҷЁе®ҢжҲҗпјҢG1 被移еӣһеҲ° P зҡ„ LRQ дёӯгҖӮдёҖж—Ұ G1 еҸҜд»ҘеңЁ M дёҠиҝӣиЎҢдёҠдёӢж–ҮеҲҮжҚўпјҢе®ғиҙҹиҙЈзҡ„ Go зӣёе…ід»Јз Ғе°ұеҸҜд»ҘеҶҚж¬Ўжү§иЎҢгҖӮиҝҷйҮҢзҡ„жңҖеӨ§дјҳеҠҝжҳҜпјҢжү§иЎҢзҪ‘з»ңзі»з»ҹи°ғз”ЁдёҚйңҖиҰҒйўқеӨ–зҡ„ MгҖӮзҪ‘з»ңиҪ®иҜўеҷЁдҪҝз”Ёзі»з»ҹзәҝзЁӢпјҢе®ғж—¶еҲ»еӨ„зҗҶдёҖдёӘжңүж•Ҳзҡ„дәӢ件еҫӘзҺҜгҖӮ
иҝҷз§Қи°ғз”Ёж–№ејҸзңӢиө·жқҘеҫҲеӨҚжқӮпјҢеҖјеҫ—еәҶе№ёзҡ„жҳҜпјҢGo иҜӯиЁҖе°ҶиҜҘвҖңеӨҚжқӮжҖ§вҖқйҡҗи—ҸеңЁ Runtime дёӯпјҡGo ејҖеҸ‘иҖ…ж— йңҖе…іжіЁ socket жҳҜеҗҰжҳҜ non-block зҡ„пјҢд№ҹж— йңҖдәІиҮӘжіЁеҶҢж–Ү件жҸҸиҝ°з¬Ұзҡ„еӣһи°ғпјҢеҸӘйңҖеңЁжҜҸдёӘиҝһжҺҘеҜ№еә”зҡ„ Goroutine дёӯд»ҘвҖңblock I/OвҖқзҡ„ж–№ејҸеҜ№еҫ… socket еӨ„зҗҶеҚіеҸҜпјҢе®һзҺ°дәҶ goroutine-per-connection з®ҖеҚ•зҡ„зҪ‘з»ңзј–зЁӢжЁЎејҸ(дҪҶжҳҜеӨ§йҮҸзҡ„ Goroutine д№ҹдјҡеёҰжқҘйўқеӨ–зҡ„й—®йўҳпјҢжҜ”еҰӮж ҲеҶ…еӯҳеўһеҠ е’Ңи°ғеәҰеҷЁиҙҹжӢ…еҠ йҮҚ)гҖӮ
з”ЁжҲ·еұӮзңјдёӯзңӢеҲ°зҡ„ Goroutine дёӯзҡ„вҖңblock socketвҖқпјҢе®һйҷ…дёҠжҳҜйҖҡиҝҮ Go runtime дёӯзҡ„ netpoller йҖҡиҝҮ Non-block socket + I/O еӨҡи·ҜеӨҚз”ЁжңәеҲ¶вҖңжЁЎжӢҹвҖқеҮәжқҘзҡ„гҖӮGo дёӯзҡ„ net еә“жӯЈжҳҜжҢүз…§иҝҷж–№ејҸе®һзҺ°зҡ„гҖӮ
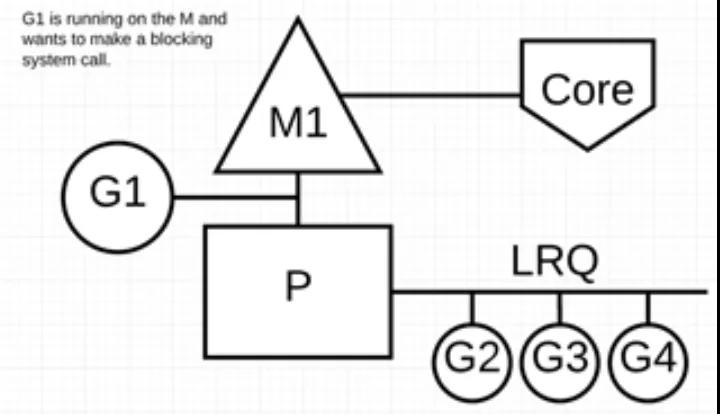
еңәжҷҜ 3пјҡеҪ“и°ғз”ЁдёҖдәӣзі»з»ҹж–№жі•зҡ„ж—¶еҖҷпјҢеҰӮжһңзі»з»ҹж–№жі•и°ғз”Ёзҡ„ж—¶еҖҷеҸ‘з”ҹйҳ»еЎһпјҢиҝҷз§Қжғ…еҶөдёӢпјҢзҪ‘з»ңиҪ®иҜўеҷЁ(NetPoller)ж— жі•дҪҝз”ЁпјҢиҖҢиҝӣиЎҢзі»з»ҹи°ғз”Ёзҡ„ Goroutine е°Ҷйҳ»еЎһеҪ“еүҚ MгҖӮ
и®©жҲ‘们жқҘзңӢзңӢеҗҢжӯҘзі»з»ҹи°ғз”Ё(еҰӮж–Ү件 I/O)дјҡеҜјиҮҙ M йҳ»еЎһзҡ„жғ…еҶөпјҡG1 е°ҶиҝӣиЎҢеҗҢжӯҘзі»з»ҹи°ғз”Ёд»Ҙйҳ»еЎһ M1гҖӮ
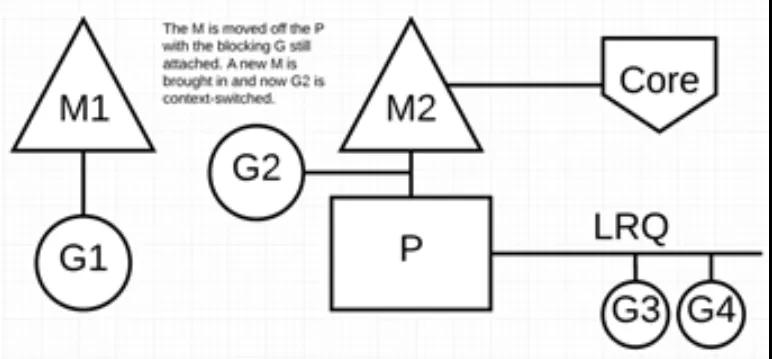
и°ғеәҰеҷЁд»Ӣе…ҘеҗҺпјҡиҜҶеҲ«еҮә G1 е·ІеҜјиҮҙ M1 йҳ»еЎһпјҢжӯӨж—¶пјҢи°ғеәҰеҷЁе°Ҷ M1 дёҺ P еҲҶзҰ»пјҢеҗҢж—¶д№ҹе°Ҷ G1 еёҰиө°гҖӮ然еҗҺи°ғеәҰеҷЁеј•е…Ҙж–°зҡ„ M2 жқҘжңҚеҠЎ PгҖӮжӯӨж—¶пјҢеҸҜд»Ҙд»Һ LRQ дёӯйҖүжӢ© G2 并еңЁ M2 дёҠиҝӣиЎҢдёҠдёӢж–ҮеҲҮжҚўгҖӮ
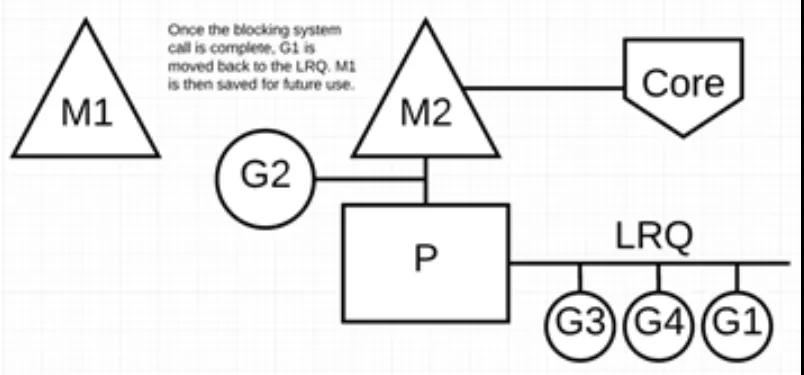
йҳ»еЎһзҡ„зі»з»ҹи°ғз”Ёе®ҢжҲҗеҗҺпјҡG1 еҸҜд»Ҙ移еӣһ LRQ 并еҶҚж¬Ўз”ұ P жү§иЎҢгҖӮеҰӮжһңиҝҷз§Қжғ…еҶөеҶҚж¬ЎеҸ‘з”ҹпјҢM1 е°Ҷиў«ж”ҫеңЁж—Ғиҫ№д»ҘеӨҮе°ҶжқҘйҮҚеӨҚдҪҝз”ЁгҖӮ
еңәжҷҜ 4пјҡеҰӮжһңеңЁ Goroutine еҺ»жү§иЎҢдёҖдёӘ sleep ж“ҚдҪңпјҢеҜјиҮҙ M иў«йҳ»еЎһдәҶгҖӮ
Go зЁӢеәҸеҗҺеҸ°жңүдёҖдёӘзӣ‘жҺ§зәҝзЁӢ sysmonпјҢе®ғзӣ‘жҺ§йӮЈдәӣй•ҝж—¶й—ҙиҝҗиЎҢзҡ„ G д»»еҠЎз„¶еҗҺи®ҫзҪ®еҸҜд»ҘејәеҚ зҡ„ж ҮиҜҶз¬ҰпјҢеҲ«зҡ„ Goroutine е°ұеҸҜд»ҘжҠўе…ҲиҝӣжқҘжү§иЎҢгҖӮ
еҸӘиҰҒдёӢж¬ЎиҝҷдёӘ Goroutine иҝӣиЎҢеҮҪж•°и°ғз”ЁпјҢйӮЈд№Ҳе°ұдјҡиў«ејәеҚ пјҢеҗҢж—¶д№ҹдјҡдҝқжҠӨзҺ°еңәпјҢ然еҗҺйҮҚж–°ж”ҫе…Ҙ P зҡ„жң¬ең°йҳҹеҲ—йҮҢйқўзӯүеҫ…дёӢж¬Ўжү§иЎҢгҖӮ
еҲ°жӯӨпјҢзӣёдҝЎеӨ§е®¶еҜ№вҖңGoи°ғеәҰеҷЁжҳҜеҰӮдҪ•еӨ„зҗҶзәҝзЁӢйҳ»еЎһзҡ„вҖқжңүдәҶжӣҙж·ұзҡ„дәҶи§ЈпјҢдёҚеҰЁжқҘе®һйҷ…ж“ҚдҪңдёҖз•Әеҗ§пјҒиҝҷйҮҢжҳҜдәҝйҖҹдә‘зҪ‘з«ҷпјҢжӣҙеӨҡзӣёе…іеҶ…е®№еҸҜд»Ҙиҝӣе…Ҙзӣёе…ійў‘йҒ“иҝӣиЎҢжҹҘиҜўпјҢе…іжіЁжҲ‘们пјҢ继з»ӯеӯҰд№ пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ