жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚдәҶSparkеҰӮдҪ•е®үиЈ…еҸҠзҺҜеўғй…ҚзҪ®пјҢе…·жңүдёҖе®ҡеҖҹйүҙд»·еҖјпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢеҸҜд»ҘеҸӮиҖғдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« д№ӢеҗҺеӨ§жңү收иҺ·пјҢдёӢйқўи®©е°Ҹзј–еёҰзқҖеӨ§е®¶дёҖиө·дәҶи§ЈдёҖдёӢгҖӮ
1гҖҒApache sparkдёӢиҪҪ
еңЁжөҸи§ҲеҷЁиҫ“е…ҘзҪ‘еқҖ
https://spark.apache.org/downloads.htmlиҝӣе…Ҙsparkзҡ„дёӢиҪҪйЎөйқўпјҢеҰӮдёӢеӣҫжүҖзӨәпјҡ
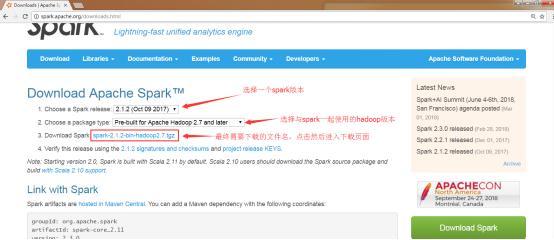
дёӢиҪҪж—¶йңҖиҰҒжіЁж„Ҹзҡ„жҳҜеңЁз¬¬1жӯҘйҖүжӢ©е®ҢsparkзүҲжң¬д№ӢеҗҺзҡ„第2жӯҘвҖңchoose a package type вҖқж—¶пјҢsparkдёҺhadoopзүҲжң¬еҝ…йЎ»й…ҚеҗҲдҪҝз”ЁгҖӮеӣ дёәsparkдјҡиҜ»еҸ–hdfsж–Ү件еҶ…е®№иҖҢдё”sparkзЁӢеәҸиҝҳдјҡиҝҗиЎҢеңЁHadoopYARNдёҠгҖӮжүҖд»Ҙеҝ…йЎ»жҢүз…§жҲ‘们зӣ®еүҚе®үиЈ…зҡ„hadoopзүҲжң¬жқҘйҖүжӢ©package typeгҖӮжҲ‘们зӣ®еүҚдҪҝз”Ёзҡ„hadoopзүҲжң¬дёәhadoop2.7.5,жүҖд»ҘйҖүжӢ©Pre-built for Apache Hadoop 2.7 and laterгҖӮ
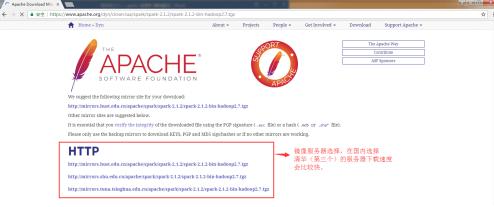
зӮ№еҮ»з¬¬3жӯҘDownload SparkеҗҺзҡ„иҝһжҺҘ
spark-2.1.2-bin-hadoop2.7.tgzиҝӣе…ҘдёӢеӣҫжүҖзӨәзҡ„йЎөйқўгҖӮеңЁеӣҪеҶ…жҲ‘们дёҖиҲ¬йҖүжӢ©жё…еҚҺзҡ„жңҚеҠЎеҷЁдёӢиҪҪпјҢиҝҷдёӢиҪҪйҖҹеәҰжҜ”иҫғеҝ«пјҢиҝһжҺҘең°еқҖ
2гҖҒе®үиЈ…spark
йҖҡиҝҮWinSCPе°Ҷ
spark-2.1.2-bin-hadoop2.7.tgzдёҠдј еҲ°masterиҷҡжӢҹжңәзҡ„Downloadsзӣ®еҪ•дёӢпјҢ然еҗҺи§ЈеҺӢеҲ°з”ЁжҲ·дё»зӣ®еҪ•дёӢ并жӣҙж”№и§ЈеҺӢеҗҺзҡ„ж–Ү件еҗҚ(ж”№ж–Ү件еҗҚзӣ®зҡ„жҳҜеҗҚеӯ—еҸҳзҹӯпјҢе®№жҳ“ж“ҚдҪң)гҖӮи§ЈеҺӢиҝҮзЁӢйңҖиҰҒдёҖзӮ№ж—¶й—ҙпјҢиҖҗеҝғзӯүеҫ…е“ҲгҖӮ
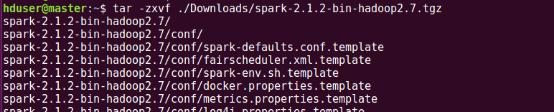
и§ЈеҺӢе®ҢжҲҗеҗҺйҖҡиҝҮlsе‘Ҫд»ӨжҹҘзңӢеҪ“еүҚз”ЁжҲ·дё»зӣ®еҪ•пјҢеҰӮдёӢеӣҫжүҖзӨәеўһеҠ дәҶspark-2.1.2-bin-hadoop2.7ж–Ү件зӣ®еҪ•

йҖҡиҝҮmvе‘Ҫд»Өжӣҙж”№spark-2.1.2-bin-hadoop2.7еҗҚдёәspark

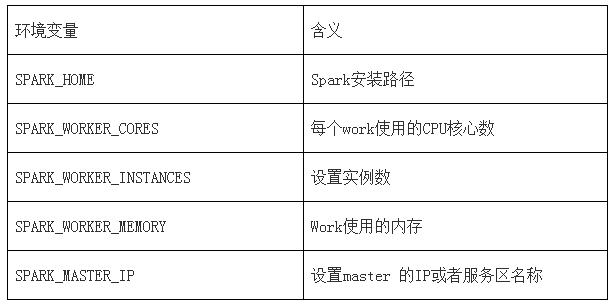
3гҖҒй…ҚзҪ®sparkзҺҜеўғеҸҳйҮҸ
йҖҡиҝҮе‘Ҫд»Өvim .bashrcзј–иҫ‘зҺҜеўғеҸҳйҮҸ

еңЁж–Ү件жң«е°ҫеўһеҠ еҰӮдёӢеҶ…е®№пјҢ然еҗҺдҝқеӯҳ并йҖҖеҮә

йҮҚж–°еҠ иҪҪзҺҜеўғеҸҳйҮҸй…ҚзҪ®ж–Ү件пјҢдҪҝж–°зҡ„й…ҚзҪ®з”ҹж•Ҳ(д»…йҷҗеҪ“еүҚз»Ҳз«ҜпјҢеҰӮжһңйҖҖеҮәз»Ҳз«Ҝж–°зҡ„зҺҜеўғеҸҳйҮҸиҝҳжҳҜдёҚиғҪз”ҹж•ҲпјҢйҮҚеҗҜиҷҡжӢҹжңәзі»з»ҹеҗҺеҸҳеҸҜж°ёд№…з”ҹж•Ҳ)

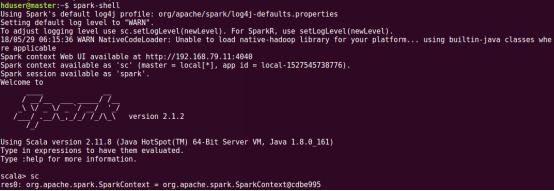
йҖҡиҝҮspark-shellеұ•зӨәsparkжҳҜеҗҰжӯЈзЎ®е®үиЈ…пјҢSpark-shellжҳҜж·»еҠ дәҶдёҖдәӣsparkеҠҹиғҪзҡ„scala REPLдәӨдә’ејҸи§ЈйҮҠеҷЁпјҢеҗҜеҠЁж–№ејҸеҰӮдёӢеӣҫжүҖзӨәгҖӮеҗҜеҠЁиҝҮзЁӢдёӯдјҡжү“еҚ°sparkзӣёе…ідҝЎжҒҜеҰӮзүҲжң¬гҖӮ
йҖҖеҮәspark-shellдҪҝз”Ёе‘Ҫд»Өпјҡquit

4гҖҒеңЁе…¶д»–иҠӮзӮ№е®үиЈ…spark
еңЁmasterиҠӮзӮ№е®үиЈ…е®ҢжҲҗеҗҺеҸӘйңҖеӨҚеҲ¶sparkж–Ү件зӣ®еҪ•еҸҠ.bashrcж–Ү件еҲ°е…¶д»–иҠӮзӮ№еҚіеҸҜпјҢе…·дҪ“ж“ҚдҪңе‘Ҫд»ӨеҸҜжҢүдёӢеӣҫж“ҚдҪң



жңҖеҗҺйҮҚеҗҜslave1гҖҒslave2еҚіеҸҜдҪҝй…ҚзҪ®ж–Ү件з”ҹж•ҲгҖӮеҲ°иҝҷйҮҢsparkе®үиЈ…е®ҢжҲҗпјҢжҺҘдёӢжқҘе°ұжҳҜж №жҚ®sparkиҝҗиЎҢжЁЎејҸжқҘй…ҚзҪ®sparkзӣёе…ій…ҚзҪ®ж–Ү件дҪҝйӣҶзҫӨжӯЈеёёе·ҘдҪңгҖӮ
5гҖҒй…ҚзҪ®sparkзӣёе…іж–Ү件
第дёҖжӯҘпјҡspark-env.shж–Ү件
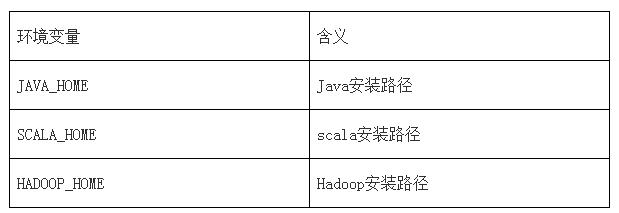
йҖҡиҝҮзҺҜеўғеҸҳйҮҸй…ҚзҪ®зЎ®е®ҡзҡ„Sparkи®ҫзҪ®гҖӮзҺҜеўғеҸҳйҮҸд»ҺSparkе®үиЈ…зӣ®еҪ•дёӢзҡ„conf/spark-env.shи„ҡжң¬иҜ»еҸ–гҖӮ
еҸҜд»ҘеңЁspark-env.shдёӯи®ҫзҪ®еҰӮдёӢеҸҳйҮҸпјҡ
Sparkзӣёе…ій…ҚзҪ®
йҰ–е…ҲејҖеҗҜдёүдёӘиҷҡжӢҹжңәmaster гҖҒslave1гҖҒslave2пјҢжҺҘдёӢжқҘеңЁmasterдё»жңәдёҠй…ҚзҪ®пјҢй…ҚзҪ®е®ҢжҲҗд№ӢеҗҺе°Ҷspark/confеҸ‘йҖҒеҲ°е…¶д»–иҠӮзӮ№еҚіеҸҜгҖӮ
жҲ‘们е…Ҳи·іиҪ¬еҲ°spark/confзӣ®еҪ•дёӢзңӢзңӢжҲ‘们йңҖиҰҒй…ҚзҪ®е“Әдәӣж–Ү件гҖӮеҰӮдёӢеӣҫжүҖзӨәйҖҡиҝҮlsе‘Ҫд»ӨжҹҘзңӢж–Ү件еҲ—иЎЁпјҢжҲ‘们д»ҠеӨ©дё»иҰҒз”ЁеҲ°зҡ„жңүspark-env.sh.templateгҖҒslaves.templateпјҢжҲ‘们иҝҳеҸҜд»Ҙз”Ёlog4j.properties.templateжқҘдҝ®ж”№иҫ“еҮәдҝЎжҒҜгҖӮ

жіЁж„ҸпјҢеҪ“Sparkе®үиЈ…ж—¶пјҢconf/spark-env.shй»ҳи®ӨжҳҜдёҚеӯҳеңЁзҡ„гҖӮдҪ еҸҜд»ҘеӨҚеҲ¶
conf/spark-env.sh.templateеҲӣе»әе®ғгҖӮ

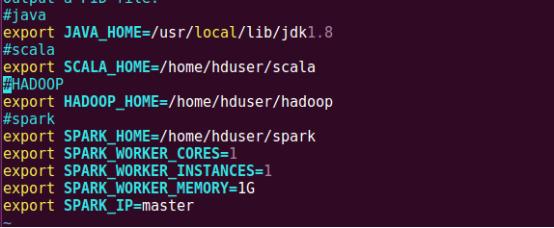
йҖҡиҝҮvimзј–иҫ‘еҷЁзј–иҫ‘spark-env.shпјҢеңЁз»Ҳз«ҜдёӯжҲ‘们еҸҜд»ҘеҸӘиҫ“е…ҘеүҚеҮ дёӘеӯ—жҜҚ然еҗҺжҢүtabй”®жқҘз»ҷжҲ‘们иҮӘеҠЁиЎҘе…ЁгҖӮ

еңЁж–Ү件жң«е°ҫж·»еҠ еҰӮдёӢеҶ…е®№пјҢдҝқеӯҳ并йҖҖеҮә
第дәҢжӯҘпјҡlog4j.properties
sparkеңЁеҗҜеҠЁиҝҮзЁӢдёӯдјҡжңүеӨ§йҮҸж—Ҙеҝ—дҝЎжҒҜжү“еҚ°еҮәжқҘпјҢеҰӮжһңжҲ‘们еҸӘжғізңӢиӯҰе‘ҠжҲ–иҖ…й”ҷиҜҜпјҢиҖҢдёҚжҳҜдёҖиҲ¬дҝЎжҒҜеҸҜд»ҘеңЁlog4j.propertiesдёӯи®ҫзҪ®пјҢеҗҢж ·зҡ„sparkдёәжҲ‘们жҸҗдҫӣдәҶдёҖдёӘжЁЎжқҝж–Ү件пјҢйңҖиҰҒйҖҡиҝҮжЁЎжқҝеӨҚеҲ¶еҮәlog4j.properties

и®ҫзҪ®ж–№жі•дёәе°Ҷж–Ү件第дәҢиЎҢINFOж”№дёәWARN

жӣҙж”№е®ҢжҲҗеҗҺж–Ү件еҶ…е®№еҰӮдёӢеӣҫжүҖзӨәпјҢи®°еҫ—дҝқеӯҳ并йҖҖеҮәгҖӮ

第дёүжӯҘпјҡslavesж–Ү件
slavesж–Ү件主иҰҒдҪңз”ЁжҳҜе‘ҠиҜүsparkйӣҶзҫӨе“ӘдәӣиҠӮзӮ№жҳҜе·ҘдҪңиҠӮзӮ№workerпјҢиҝҷйҮҢslavesж–Ү件д№ҹйңҖиҰҒз”ұжЁЎжқҝж–Ү件еӨҚеҲ¶иҝҮжқҘпјҢж“ҚдҪңеҰӮдёӢеӣҫжүҖзӨә

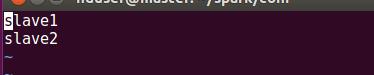
дҪҝз”Ёvimзј–иҫ‘еҷЁзј–иҫ‘slaves

ж–Ү件дёӯиҫ“е…ҘеҰӮдёӢеҶ…е®№пјҢиЎЁзӨәе·ҘдҪңиҠӮзӮ№дёәslave1е’Ңslave2,дҝқеӯҳ并йҖҖеҮәгҖӮ
жңҖеҗҺе°Ҷspark/confзӣ®еҪ•з§»еҠЁеҲ°slave1 slave2иҠӮзӮ№sparkзӣ®еҪ•дёӢ,ж“ҚдҪңеҰӮдёӢеӣҫжүҖзӨә
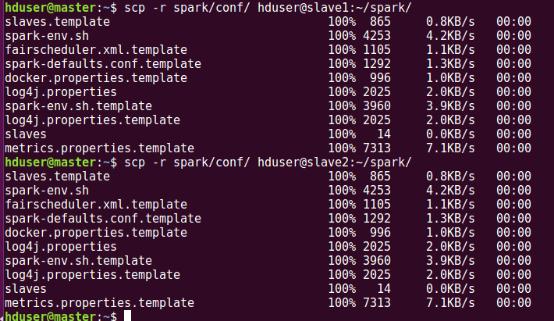
зҺ°еңЁе°ұеҸҜд»ҘеҗҜеҠЁйӣҶзҫӨдәҶпјҢе…ҲеҗҜеҠЁhadoopйӣҶзҫӨ(д№ҹеҸҜд»ҘдёҚз”ЁhadoopпјҢдҪҶжҳҜеңЁе®һйҷ…еә”з”ЁдёӯеӨ§йғЁеҲҶsparkиҝҳжҳҜдјҡз”ЁеҲ°hadoopзҡ„иө„жәҗз®ЎзҗҶYARN)еҶҚеҗҜеҠЁsparkйӣҶзҫӨпјҢж“ҚдҪңеҰӮдёӢжүҖзӨәгҖӮ
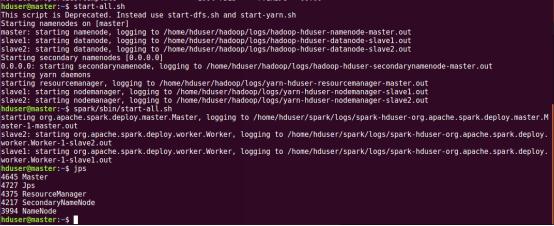
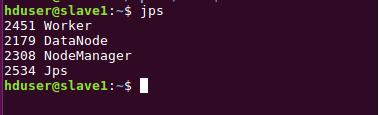
йҖҡиҝҮjpsжҹҘзңӢеҗҜеҠЁзҡ„иҝӣзЁӢпјҢеңЁmasterиҠӮзӮ№дёҠsparkзҡ„иҝӣзЁӢжҳҜMasterпјҢеңЁslaveиҠӮзӮ№дёҠsparkзӣёе…іиҝӣзЁӢжҳҜWorkerгҖӮ
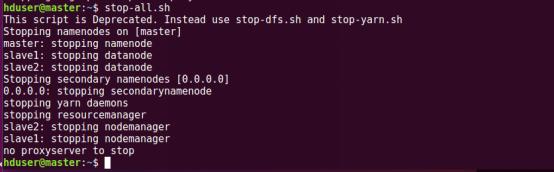
еҒңжӯўйӣҶзҫӨж—¶иҰҒе…ҲеҒңжӯўsparkйӣҶзҫӨ

еҶҚеҒңжӯўhadoopйӣҶзҫӨ
ж„ҹи°ўдҪ иғҪеӨҹи®Өзңҹйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« пјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„вҖңSparkеҰӮдҪ•е®үиЈ…еҸҠзҺҜеўғй…ҚзҪ®вҖқиҝҷзҜҮж–Үз« еҜ№еӨ§е®¶жңүеё®еҠ©пјҢеҗҢж—¶д№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘пјҢе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢжӣҙеӨҡзӣёе…ізҹҘиҜҶзӯүзқҖдҪ жқҘеӯҰд№ !
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ