您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
1.简单介绍和安装:
(1)Spark使用scala编写,运行在JVM(java虚拟机)上。所以,安装Spark需要先安装JDK。安装好java后,到官网下载安装包(压缩文件):http://spark.apache.org/downloads.html ,当前使用的版本是:spark-1.6.1-bin-hadoop2.4.tgz。
(2)解压,查看目录内容:
tar -zxvf spark-1.6.1-bin-hadoop2.4.tgz cd spark-1.6.1-bin-hadoop2.4
这样我们可以在单机模式下运行Spark了,Spark也可以运行在Mesos、YARN等上。
2.Spark交互式shell:
(1) Spark只支持Scala和Python两种Shell。为了对Spark Shell有个感性的认识,我们可以follow官网的quick-start教程:http://spark.apache.org/docs/latest/quick-start.html
首先启动Spark shell,Scala和Python有2种不同启动方式(下面,我们以Scala为例介绍):
Scala:
./bin/spark-shell
scala启动shell参数:
./bin/spark-shell --name "axx" --conf spark.cores.max=5 --conf spark.ui.port=4041
Python:
./bin/pyspark
启动后有如下界面:
如果需要修改显示的日志级别,修改$SPARK_HOME/conf/log4j.properties文件。
(2)Spark中第一个重要名词:RDD(Resilient Distributed Dataset),弹性分布式数据集。
在Spark中,使用RDD来进行分布式计算。RDD是Spark对于分布数据和分布计算的基本抽象。
RDD包括两类操作,actions 和 transformations;
行动操作(actions):会产生新的值。会对RDD计算出一个结果,并把结果返回到驱动器程序中(例如shell命令行中,我们输入一个计算指令,spark为我们返回的结果值),或把结果存储到外部存储系统(如HDFS)中(我们在后边还会看到rdd.saveAsTextFile())。
转化操作(transformations):会产生一个新的RDD。
val lines = sc.textFile("file:///spark/spark/README.md")通过读取文件的方式来定义一个RDD。默认地,textFile会读取HDFS上的文件,加上file://指定读取本地路径的文件。
lines.count() lines.first()
上边是2个actions操作,分别返回RDD的行数和第一行数据。
val linesWithSpark = lines.filter(line=>lines.contains("spark"))上边是一个transformations操作,生成一个新的RDD,该RDD是lines的一个子集,只返回包含spark的行。
3.Spark核心概念:
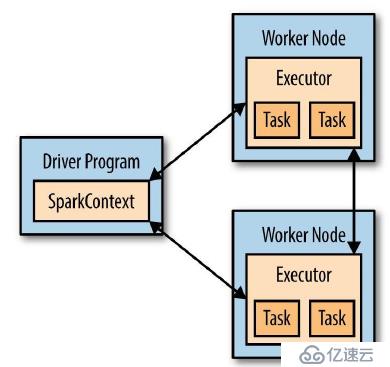
每个Spark应用都包含一个驱动程序,该驱动程序在集群中执行并行计算。在前面的事例中,驱动程序就是spark shell本身。驱动程序通过SparkContext对象(对计算集群的一个连接)来访问Spark。
为了运行RDD操作,驱动程序会管理一些叫做执行器的节点。当在分布式系统中运行时,架构图如下:
4.独立应用:
除了在shell中运行,还可以运行独立应用。与Spark Shell主要区别是,当开发独立应用时,你需要自己初始化SparkContext。
4.1 初始化SparkContext
首先,需要创建SparkConf对象来配置应用,然后通过SparkConf来创建SparkContext。初始化SparkContext对象:
SparkConf conf = new SparkConf().setAppName("wc_ms");
JavaSparkContext sc = new JavaSparkContext(conf);setAppName可以设置这个独立应用的名称,后期我们可以在WebUI上监控这个应用。
4.2 开发WordCount程序:
通过Maven构建Spark程序,pom只需要引入一个依赖(根据具体的Spark版本而定):
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core_2.10 --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>1.6.1</version> </dependency>
WordCount.java
package com.vip.SparkTest;
import java.util.Arrays;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
public class WordCount {
public static void main(String[] args) {
String inputfile = args[0];
String outputfile = args[1];
//得到SparkContext
SparkConf conf = new SparkConf().setAppName("wc_ms");
JavaSparkContext sc = new JavaSparkContext(conf);
//加载文件到RDD
JavaRDD<String> input = sc.textFile(inputfile);
//flatMap方法,来自接口JavaRDDLike,JavaRDD继承接口JavaRDDLike。
//将文件拆分成一个个单词(通过空格分开);transformation操作,生成一个新的RDD。
JavaRDD<String> words = input.flatMap(
new FlatMapFunction<String,String>()
{
@Override
public Iterable<String> call(String content) throws Exception {
// TODO Auto-generated method stub
return Arrays.asList(content.split(" "));
}
}
);
//先转换成元组(key-value),word - 1 word2 - 1;
//再Reduce汇总计算
JavaPairRDD<String,Integer> counts = words.mapToPair(
new PairFunction<String,String,Integer>(){
@Override
public Tuple2<String, Integer> call(String arg0) throws Exception {
// TODO Auto-generated method stub
return new Tuple2<String, Integer>(arg0,1);
}
}
).reduceByKey(
new Function2<Integer,Integer,Integer>(){
@Override
public Integer call(Integer x, Integer y) throws Exception {
// TODO Auto-generated method stub
return x+y;
}
}
)
;
counts.saveAsTextFile(outputfile);
sc.close();
}
}上边对应的步骤做了注释。
4.3 发布应用到Spark(单机或者集群):
(1)首先,要将开发好的程序打包:
mvn package
得到jar包:SparkTest-0.0.1-SNAPSHOT.jar
(2)将相关文件上传到服务器上:
将要做count的文本文件、jar文件上传服务器。
(3)使用spark-submit启动应用:
$SPARK_HOME/bin/spark-submit \ --class "com.vip.SparkTest.WordCount" \ --master local \ ./SparkTest-0.0.1-SNAPSHOT.jar "输入目录" "输出目录"
说明: --class 指定程序的主类;
--master 指定Spark的URL,因为是在本机,所以指定了local
输入目录:包含所有输入的文本文件(可能是一个或多个文件)。
输出目录:这块要特别注意,首先这是一个目录,不能是文件;再次这个目录不能事先创建,否则报错。
(4) 运行结果:
最后执行成功后,生成了2个文件:
part-00000 _SUCCESS
part-00000文件内容:
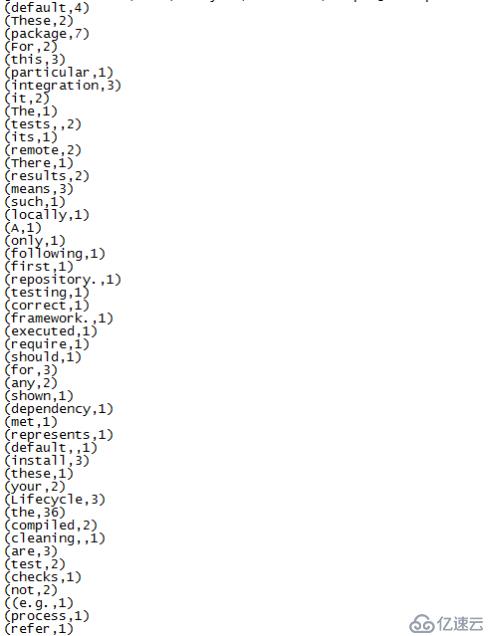
至此,我们的wordcount程序结束。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。