жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮж–Үз« з»ҷеӨ§е®¶еҲҶдә«зҡ„жҳҜжңүе…іејҖеҸ‘дёӯйӮЈдәӣеёёз”Ёзҡ„MySQLдјҳеҢ–жңүе“ӘдәӣпјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еӯҰд№ пјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·пјҢиҜқдёҚеӨҡиҜҙпјҢи·ҹзқҖе°Ҹзј–дёҖиө·жқҘзңӢзңӢеҗ§гҖӮ
1гҖҒеӨ§жү№йҮҸжҸ’е…Ҙж•°жҚ®дјҳеҢ–
пјҲ1пјүеҜ№дәҺMyISAMеӯҳеӮЁеј•ж“Һзҡ„иЎЁпјҢеҸҜд»ҘдҪҝз”ЁпјҡDISABLE KEYS е’Ң ENABLE KEYS з”ЁжқҘжү“ејҖжҲ–иҖ…е…ій—ӯ MyISAM иЎЁйқһе”ҜдёҖзҙўеј•зҡ„жӣҙж–°гҖӮ
ALTER TABLE tbl_name DISABLE KEYS; loading the data ALTER TABLE tbl_name ENABLE KEYS;
пјҲ2пјүеҜ№дәҺInnoDBеј•ж“ҺпјҢжңүд»ҘдёӢеҮ з§ҚдјҳеҢ–жҺӘж–Ҫпјҡ
в‘ еҜје…Ҙзҡ„ж•°жҚ®жҢүз…§дё»й”®зҡ„йЎәеәҸдҝқеӯҳпјҡиҝҷжҳҜеӣ дёәInnoDBеј•ж“ҺиЎЁзӨәжҢүз…§дё»й”®йЎәеәҸдҝқеӯҳзҡ„пјҢеҰӮжһңиғҪе°ҶжҸ’е…Ҙзҡ„ж•°жҚ®жҸҗеүҚжҢүз…§жҺ’еәҸеҘҪиҮӘ然иғҪзңҒеҺ»еҫҲеӨҡж—¶й—ҙгҖӮ
жҜ”еҰӮbulk_insert.txtж–Ү件жҳҜд»ҘиЎЁuserдё»й”®зҡ„йЎәеәҸеӯҳеӮЁзҡ„пјҢеҜје…Ҙзҡ„ж—¶й—ҙдёә15.23з§’
mysql> load data infile 'mysql/bulk_insert.txt' into table user; Query OK, 126732 rows affected (15.23 sec) Records: 126732 Deleted: 0 Skipped: 0 Warnings: 0
жІЎжңүжҢүз…§дё»й”®жҺ’еәҸзҡ„иҜқпјҢж—¶й—ҙдёәпјҡ26.54з§’
mysql> load data infile 'mysql/bulk_insert.txt' into table user; Query OK, 126732 rows affected (26.54 sec) Records: 126732 Deleted: 0 Skipped: 0 Warnings: 0
в‘Ў еҜје…Ҙж•°жҚ®еүҚжү§иЎҢSET UNIQUE_CHECKS=0пјҢе…ій—ӯе”ҜдёҖжҖ§ж ЎйӘҢпјҢеёҰеҜје…Ҙд№ӢеҗҺеҶҚжү“ејҖи®ҫзҪ®дёә1пјҡж ЎйӘҢдјҡж¶ҲиҖ—ж—¶й—ҙпјҢеңЁж•°жҚ®йҮҸеӨ§зҡ„жғ…еҶөдёӢйңҖиҰҒиҖғиҷ‘гҖӮ
в‘ў еҜје…ҘеүҚи®ҫзҪ®SET AUTOCOMMIT=0пјҢе…ій—ӯиҮӘеҠЁжҸҗдәӨпјҢеҜје…ҘеҗҺз»“жқҹеҶҚи®ҫзҪ®дёә1пјҡиҝҷжҳҜеӣ дёәиҮӘеҠЁжҸҗдәӨдјҡж¶ҲиҖ—йғЁеҲҶж—¶й—ҙдёҺиө„жәҗпјҢиҷҪ然ж¶ҲиҖ—дёҚжҳҜеҫҲеӨ§пјҢдҪҶжҳҜеңЁж•°жҚ®йҮҸеӨ§зҡ„жғ…еҶөдёӢиҝҳжҳҜеҫ—иҖғиҷ‘гҖӮ
2гҖҒINSERTзҡ„дјҳеҢ–
пјҲ1пјүе°ҪйҮҸдҪҝз”ЁеӨҡдёӘеҖјиЎЁзҡ„ INSERT иҜӯеҸҘпјҢиҝҷз§Қж–№ејҸе°ҶеӨ§еӨ§зј©еҮҸе®ўжҲ·з«ҜдёҺж•°жҚ®еә“д№Ӣй—ҙзҡ„иҝһжҺҘгҖҒе…ій—ӯзӯүж¶ҲиҖ—гҖӮпјҲеҗҢдёҖе®ўжҲ·зҡ„жғ…еҶөдёӢпјүпјҢеҚіпјҡ
INSERT INTO tablename values(1,2),(1,3),(1,4)
е®һйӘҢпјҡжҸ’е…Ҙ8жқЎж•°жҚ®еҲ°userиЎЁдёӯпјҲдҪҝз”Ёnavicatе®ўжҲ·з«Ҝе·Ҙе…·пјү
insert into user values(1,'test',replace(uuid(),'-','')); insert into user values(2,'test',replace(uuid(),'-','')); insert into user values(3,'test',replace(uuid(),'-','')); insert into user values(4,'test',replace(uuid(),'-','')); insert into user values(5,'test',replace(uuid(),'-','')); insert into user values(6,'test',replace(uuid(),'-','')); insert into user values(7,'test',replace(uuid(),'-','')); insert into user values(8,'test',replace(uuid(),'-',''));
еҫ—еҲ°еҸҚйҰҲпјҡ
[SQL] insert into user values(1,'test',replace(uuid(),'-','')); еҸ—еҪұе“Қзҡ„иЎҢ: 1 ж—¶й—ҙ: 0.033s [SQL] insert into user values(2,'test',replace(uuid(),'-','')); еҸ—еҪұе“Қзҡ„иЎҢ: 1 ж—¶й—ҙ: 0.034s [SQL] insert into user values(3,'test',replace(uuid(),'-','')); еҸ—еҪұе“Қзҡ„иЎҢ: 1 ж—¶й—ҙ: 0.056s [SQL] insert into user values(4,'test',replace(uuid(),'-','')); еҸ—еҪұе“Қзҡ„иЎҢ: 1 ж—¶й—ҙ: 0.008s [SQL] insert into user values(5,'test',replace(uuid(),'-','')); еҸ—еҪұе“Қзҡ„иЎҢ: 1 ж—¶й—ҙ: 0.008s [SQL] insert into user values(6,'test',replace(uuid(),'-','')); еҸ—еҪұе“Қзҡ„иЎҢ: 1 ж—¶й—ҙ: 0.024s [SQL] insert into user values(7,'test',replace(uuid(),'-','')); еҸ—еҪұе“Қзҡ„иЎҢ: 1 ж—¶й—ҙ: 0.004s [SQL] insert into user values(8,'test',replace(uuid(),'-','')); еҸ—еҪұе“Қзҡ„иЎҢ: 1 ж—¶й—ҙ: 0.004s
жҖ»е…ұзҡ„ж—¶й—ҙдёә0.171з§’пјҢжҺҘдёӢжқҘдҪҝз”ЁеӨҡеҖјиЎЁеҪўејҸпјҡ
insert into user values (9,'test',replace(uuid(),'-','')), (10,'test',replace(uuid(),'-','')), (11,'test',replace(uuid(),'-','')), (12,'test',replace(uuid(),'-','')), (13,'test',replace(uuid(),'-','')), (14,'test',replace(uuid(),'-','')), (15,'test',replace(uuid(),'-','')), (16,'test',replace(uuid(),'-',''));
еҫ—еҲ°еҸҚйҰҲпјҡ
[SQL] insert into user values (9,'test',replace(uuid(),'-','')), (10,'test',replace(uuid(),'-','')), (11,'test',replace(uuid(),'-','')), (12,'test',replace(uuid(),'-','')), (13,'test',replace(uuid(),'-','')), (14,'test',replace(uuid(),'-','')), (15,'test',replace(uuid(),'-','')), (16,'test',replace(uuid(),'-','')); еҸ—еҪұе“Қзҡ„иЎҢ: 8 ж—¶й—ҙ: 0.038s
еҫ—еҲ°ж—¶й—ҙдёә0.038пјҢиҝҷж ·дёҖжқҘеҸҜд»ҘеҫҲжҳҺжҳҫиҠӮзәҰж—¶й—ҙдјҳеҢ–SQL
пјҲ2пјүеҰӮжһңеңЁдёҚеҗҢе®ўжҲ·з«ҜжҸ’е…ҘеҫҲеӨҡиЎҢпјҢеҸҜдҪҝз”ЁINSERT DELAYEDиҜӯеҸҘеҫ—еҲ°жӣҙй«ҳзҡ„йҖҹеәҰпјҢDELLAYEDеҗ«д№үжҳҜи®©INSERTиҜӯеҸҘ马дёҠжү§иЎҢпјҢе…¶е®һж•°жҚ®йғҪиў«ж”ҫеңЁеҶ…еӯҳзҡ„йҳҹеҲ—дёӯгҖӮ并没жңүзңҹжӯЈеҶҷе…ҘзЈҒзӣҳгҖӮLOW_PRIORITYеҲҡеҘҪзӣёеҸҚгҖӮ
пјҲ3пјүе°Ҷзҙўеј•ж–Ү件е’Ңж•°жҚ®ж–Ү件еҲҶеңЁдёҚеҗҢзҡ„зЈҒзӣҳдёҠеӯҳж”ҫпјҲInnoDBеј•ж“ҺжҳҜеңЁеҗҢдёҖдёӘиЎЁз©әй—ҙзҡ„пјүгҖӮ
пјҲ4пјүеҰӮжһңжү№йҮҸжҸ’е…ҘпјҢеҲҷеҸҜд»ҘеўһеҠ bluk_insert_buffer_sizeеҸҳйҮҸеҖјжҸҗдҫӣйҖҹеәҰпјҲеҸӘеҜ№MyISAMжңүз”Ёпјү
пјҲ5пјүеҪ“д»ҺдёҖдёӘж–Үжң¬ж–Ү件装иҪҪдёҖдёӘиЎЁж—¶пјҢдҪҝз”ЁLOAD DATA INFILEпјҢйҖҡеёёжҜ”INSERTиҜӯеҸҘеҝ«20еҖҚгҖӮ
3гҖҒGROUP BYзҡ„дјҳеҢ–
еңЁй»ҳи®Өжғ…еҶөдёӢпјҢMySQLдёӯзҡ„GROUP BYиҜӯеҸҘдјҡеҜ№е…¶еҗҺеҮәзҺ°зҡ„еӯ—ж®өиҝӣиЎҢй»ҳи®ӨжҺ’еәҸпјҲйқһдё»й”®жғ…еҶөпјүпјҢе°ұеҘҪжҜ”жҲ‘们дҪҝз”ЁORDER BY col1,col2,col3…жүҖд»ҘжҲ‘们еңЁеҗҺйқўи·ҹдёҠе…·жңүзӣёеҗҢеҲ—пјҲдёҺGROUP BYеҗҺеҮәзҺ°зҡ„col1,col2,col3…зӣёеҗҢпјүORDER BYеӯҗеҸҘ并没жңүеҪұе“ҚиҜҘSQLзҡ„е®һйҷ…жү§иЎҢжҖ§иғҪгҖӮ
йӮЈд№Ҳе°ұдјҡжңүиҝҷж ·зҡ„жғ…еҶөеҮәзҺ°пјҢжҲ‘们еҜ№жҹҘиҜўеҲ°зҡ„з»“жһңжҳҜеҗҰе·Із»ҸжҺ’еәҸдёҚеңЁд№Һж—¶пјҢеҸҜд»ҘдҪҝз”ЁORDER BY NULLзҰҒжӯўжҺ’еәҸиҫҫеҲ°дјҳеҢ–зӣ®зҡ„гҖӮдёӢйқўдҪҝз”ЁEXPLAINе‘Ҫд»ӨеҲҶжһҗSQLгҖӮJavaзҹҘйҹіе…¬дј—еҸ·еҶ…еӣһеӨҚвҖңйқўиҜ•йўҳиҒҡеҗҲвҖқпјҢйҖҒдҪ дёҖд»ҪйқўиҜ•йўҳе®қе…ё
еңЁuser_1дёӯжү§иЎҢselect id, sum(money) form user_1 group by nameж—¶пјҢдјҡй»ҳи®ӨжҺ’еәҸпјҲжіЁж„Ҹgroup byеҗҺзҡ„columnжҳҜйқһindexжүҚдјҡдҪ“зҺ°group byзҡ„жҺ’еәҸпјҢеҰӮжһңжҳҜprimary keyпјҢйӮЈд№ӢеүҚиҜҙиҝҮдәҶInnoDBй»ҳи®ӨжҳҜжҢүз…§дё»й”®indexжҺ’еҘҪеәҸзҡ„пјү
mysql> select*from user_1; +----+----------+-------+ | id | name | money | +----+----------+-------+ | 1 | Zhangsan | 32 | | 2 | Lisi | 65 | | 3 | Wangwu | 44 | | 4 | Lijian | 100 | +----+----------+-------+ 4 rows in set
дёҚзҰҒжӯўжҺ’еәҸпјҢеҚідёҚдҪҝз”ЁORDER BY NULLж—¶пјҡжңүжҳҺжҳҫзҡ„Using filesortгҖӮ
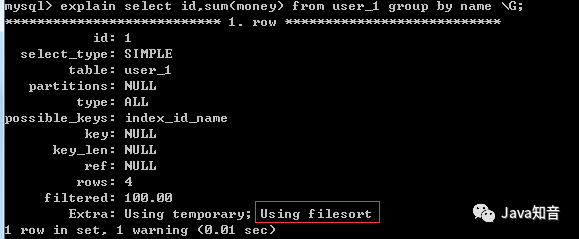
еҪ“дҪҝз”ЁORDER BY NULLзҰҒжӯўжҺ’еәҸеҗҺпјҢUsing filesortдёҚеӯҳеңЁ
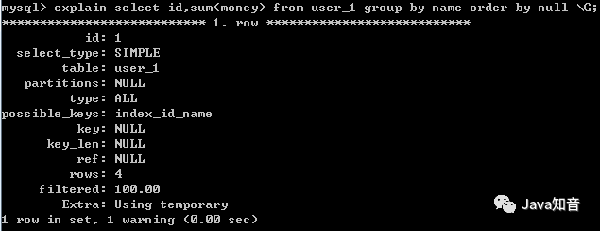
4гҖҒORDER BY зҡ„дјҳеҢ–
MySQLеҸҜд»ҘдҪҝз”ЁдёҖдёӘзҙўеј•жқҘж»Ўи¶іORDER BY еӯҗеҸҘзҡ„жҺ’еәҸпјҢиҖҢдёҚйңҖиҰҒйўқеӨ–зҡ„жҺ’еәҸпјҢдҪҶжҳҜйңҖиҰҒж»Ўи¶ід»ҘдёӢеҮ дёӘжқЎд»¶пјҡ
пјҲ1пјүWHERE жқЎд»¶е’ҢOREDR BY дҪҝз”ЁзӣёеҗҢзҡ„зҙўеј•пјҡеҚіkey_part1дёҺkey_part2жҳҜеӨҚеҗҲзҙўеј•пјҢwhereдёӯдҪҝз”ЁеӨҚеҗҲзҙўеј•дёӯзҡ„key_part1
SELECT*FROM user WHERE key_part1=1 ORDER BY key_part1 DESC, key_part2 DESC;
пјҲ2пјүиҖҢдё”ORDER BYйЎәеәҸе’Ңзҙўеј•йЎәеәҸзӣёеҗҢпјҡ
SELECT*FROM user ORDER BY key_part1, key_part2;
пјҲ3пјү并且иҰҒд№ҲйғҪжҳҜеҚҮеәҸиҰҒд№ҲйғҪжҳҜйҷҚеәҸпјҡ
SELECT*FROM user ORDER BY key_part1 DESC, key_part2 DESC;
дҪҶд»ҘдёӢеҮ з§Қжғ…еҶөеҲҷдёҚдҪҝз”Ёзҙўеј•пјҡ
пјҲ1пјүORDER BYдёӯж··еҗҲASCе’ҢDESCпјҡ
SELECT*FROM user ORDER BY key_part1 DESC, key_part2 ASC;
пјҲ2пјүжҹҘиҜўиЎҢзҡ„е…ій”®еӯ—дёҺORDER BYжүҖдҪҝз”Ёзҡ„дёҚзӣёеҗҢпјҢеҚіWHERE еҗҺзҡ„еӯ—ж®өдёҺORDER BY еҗҺзҡ„еӯ—ж®өжҳҜдёҚдёҖж ·зҡ„
SELECT*FROM user WHERE key2 = ‘xxx’ ORDER BY key1;
пјҲ3пјүORDER BYеҜ№дёҚеҗҢзҡ„е…ій”®еӯ—дҪҝз”ЁпјҢеҚіORDER BYеҗҺзҡ„е…ій”®еӯ—дёҚзӣёеҗҢ
SELECT*FROM user ORDER BY key1, key2;
5гҖҒORзҡ„дјҳеҢ–
еҪ“MySQLдҪҝз”ЁORжҹҘиҜўж—¶пјҢеҰӮжһңиҰҒеҲ©з”Ёзҙўеј•зҡ„иҜқпјҢеҝ…йЎ»жҜҸдёӘжқЎд»¶еҲ—йғҪдҪҝзӢ¬з«Ӣзҙўеј•пјҢиҖҢдёҚжҳҜеӨҚеҗҲзҙўеј•пјҲеӨҡеҲ—зҙўеј•пјүпјҢжүҚиғҪдҝқиҜҒдҪҝз”ЁеҲ°жҹҘиҜўзҡ„ж—¶еҖҷдҪҝз”ЁеҲ°зҙўеј•гҖӮ
жҜ”еҰӮжҲ‘们新е»әдёҖеј з”ЁжҲ·дҝЎжҒҜиЎЁuser_info
mysql> select*from user_info; +---------+--------+----------+-----------+ | user_id | idcard | name | address | +---------+--------+----------+-----------+ | 1 | 111111 | Zhangsan | Kunming | | 2 | 222222 | Lisi | Beijing | | 3 | 333333 | Wangwu | Shanghai | | 4 | 444444 | Lijian | Guangzhou | +---------+--------+----------+-----------+ 4 rows in set
д№ӢеҗҺеҲӣе»әind_name_id(user_id, name)еӨҚеҗҲзҙўеј•гҖҒid_index(id_index)зӢ¬з«Ӣзҙўеј•пјҢidcardдё»й”®зҙўеј•дёүдёӘзҙўеј•гҖӮ
mysql> show index from user_info; +-----------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +-----------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | user_info | 0 | PRIMARY | 1 | idcard | A | 4 | NULL | NULL | | BTREE | | | | user_info | 1 | ind_name_id | 1 | user_id | A | 4 | NULL | NULL | | BTREE | | | | user_info | 1 | ind_name_id | 2 | name | A | 4 | NULL | NULL | YES | BTREE | | | | user_info | 1 | id_index | 1 | user_id | A | 4 | NULL | NULL | | BTREE | | | +-----------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ 4 rows in set
жөӢиҜ•дёҖпјҡORиҝһжҺҘдёӨдёӘжңүеҚ•зӢ¬зҙўеј•зҡ„еӯ—ж®өпјҢж•ҙдёӘSQLжҹҘиҜўжүҚдјҡз”ЁеҲ°зҙўеј•(index_merge)пјҢ并且жҲ‘们зҹҘйҒ“ORе®һйҷ…дёҠжҳҜжҠҠжҜҸдёӘз»“жһңжңҖеҗҺUNIONдёҖиө·зҡ„гҖӮ
mysql> explain select*from user_info where user_id=1 or idcard='222222'; +----+-------------+-----------+------------+-------------+------------------------------+---------------------+---------+------+------+----------+----------------------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+-------------+------------------------------+---------------------+---------+------+------+----------+----------------------------------------------------+ | 1 | SIMPLE | user_info | NULL | index_merge | PRIMARY,ind_name_id,id_index | ind_name_id,PRIMARY | 4,62 | NULL | 2 | 100 | Using sort_union(ind_name_id,PRIMARY); Using where | +----+-------------+-----------+------------+-------------+------------------------------+---------------------+---------+------+------+----------+----------------------------------------------------+ 1 row in set
жөӢиҜ•дәҢпјҡORдҪҝз”ЁеӨҚеҗҲзҙўеј•зҡ„еӯ—ж®өnameпјҢдёҺжІЎжңүзҙўеј•зҡ„addressпјҢж•ҙдёӘSQLйғҪжҳҜALLе…ЁиЎЁжү«жҸҸзҡ„
mysql> explain select*from user_info where name='Zhangsan' or address='Beijing'; +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | user_info | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 43.75 | Using where | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ 1 row in set
дәӨжҚўORдҪҚзҪ®е№¶дё”дҪҝз”ЁеҸҰеӨ–зҡ„еӨҚеҗҲзҙўеј•зҡ„еҲ—пјҢд№ҹжҳҜALLе…ЁиЎЁжү«жҸҸпјҡ
mysql> explain select*from user_info where address='Beijing' or user_id=1; +----+-------------+-----------+------------+------+----------------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+----------------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | user_info | NULL | ALL | ind_name_id,id_index | NULL | NULL | NULL | 4 | 43.75 | Using where | +----+-------------+-----------+------------+------+----------------------+------+---------+------+------+----------+-------------+ 1 row in set
6гҖҒдјҳеҢ–еөҢеҘ—жҹҘиҜў
дҪҝз”ЁеөҢеҘ—жҹҘиҜўжңүж—¶еҖҷеҸҜд»ҘдҪҝз”Ёжӣҙжңүж•Ҳзҡ„JOINиҝһжҺҘд»ЈжӣҝпјҢиҝҷжҳҜеӣ дёәMySQLдёӯдёҚйңҖиҰҒеңЁеҶ…еӯҳдёӯеҲӣе»әдёҙж—¶иЎЁе®ҢжҲҗSELECTеӯҗжҹҘиҜўдёҺдё»жҹҘиҜўдёӨйғЁеҲҶжҹҘиҜўе·ҘдҪңгҖӮдҪҶжҳҜ并дёҚжҳҜжүҖжңүзҡ„ж—¶еҖҷйғҪжҲҗз«ӢпјҢжңҖеҘҪжҳҜеңЁonе…ій”®еӯ—еҗҺйқўзҡ„еҲ—жңүзҙўеј•зҡ„иҜқпјҢж•ҲжһңдјҡжӣҙеҘҪпјҒ
жҜ”еҰӮеңЁиЎЁmajorдёӯmajor_idжҳҜжңүзҙўеј•зҡ„пјҡ
select * from student u left join major m on u.major_id=m.major_id where m.major_id is null;
иҖҢйҖҡиҝҮеөҢеҘ—жҹҘиҜўж—¶пјҢеңЁеҶ…еӯҳдёӯеҲӣе»әдёҙж—¶иЎЁе®ҢжҲҗSELECTеӯҗжҹҘиҜўдёҺдё»жҹҘиҜўдёӨйғЁеҲҶжҹҘиҜўе·ҘдҪңпјҢдјҡжңүдёҖе®ҡзҡ„ж¶ҲиҖ—
select * from student u where major_id not in (select major_id from major);
7гҖҒдҪҝз”ЁSQLжҸҗзӨә
SQLжҸҗзӨәпјҲSQL HINTпјүжҳҜдјҳеҢ–ж•°жҚ®еә“зҡ„дёҖдёӘйҮҚиҰҒжүӢж®өпјҢе°ұжҳҜеҫҖSQLиҜӯеҸҘдёӯеҠ е…ҘдёҖдәӣдәәдёәзҡ„жҸҗзӨәжқҘиҫҫеҲ°дјҳеҢ–зӣ®зҡ„гҖӮдёӢйқўжҳҜдёҖдәӣеёёз”Ёзҡ„SQLжҸҗзӨәпјҡ
пјҲ1пјүUSE INDEXпјҡдҪҝз”ЁUSE INDEXжҳҜеёҢжңӣMySQLеҺ»еҸӮиҖғзҙўеј•еҲ—иЎЁпјҢе°ұеҸҜд»Ҙи®©MySQLдёҚйңҖиҰҒиҖғиҷ‘е…¶д»–еҸҜз”Ёзҙўеј•пјҢе…¶е®һд№ҹе°ұжҳҜpossible_keysеұһжҖ§дёӢеҸӮиҖғзҡ„зҙўеј•еҖј
mysql> explain select* from user_info use index(id_index,ind_name_id) where user_id>0; +----+-------------+-----------+------------+------+----------------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+----------------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | user_info | NULL | ALL | ind_name_id,id_index | NULL | NULL | NULL | 4 | 100 | Using where | +----+-------------+-----------+------------+------+----------------------+------+---------+------+------+----------+-------------+ 1 row in set mysql> explain select* from user_info use index(id_index) where user_id>0; +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | user_info | NULL | ALL | id_index | NULL | NULL | NULL | 4 | 100 | Using where | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ 1 row in set
пјҲ2пјүIGNORE INDEXеҝҪз•Ҙзҙўеј•
жҲ‘们дҪҝз”Ёuser_idеҲӨж–ӯпјҢз”ЁдёҚеҲ°е…¶д»–зҙўеј•ж—¶пјҢеҸҜд»ҘеҝҪз•Ҙзҙўеј•гҖӮеҚідёҺUSE INDEXзӣёеҸҚпјҢд»Һpossible_keysдёӯеҮҸеҺ»дёҚйңҖиҰҒзҡ„зҙўеј•пјҢдҪҶжҳҜе®һйҷ…зҺҜеўғдёӯеҫҲе°‘дҪҝз”ЁгҖӮ
mysql> explain select* from user_info ignore index(primary,ind_name_id,id_index) where user_id>0; +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | user_info | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 33.33 | Using where | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ 1 row in set
пјҲ3пјүFORCE INDEXејәеҲ¶зҙўеј•
жҜ”еҰӮwhere user_id > 0пјҢдҪҶжҳҜuser_idеңЁиЎЁдёӯйғҪжҳҜеӨ§дәҺ0зҡ„пјҢиҮӘ然е°ұдјҡиҝӣиЎҢALLе…ЁиЎЁжҗңзҙўпјҢдҪҶжҳҜдҪҝз”ЁFORCE INDEXиҷҪ然жү§иЎҢж•ҲзҺҮдёҚжҳҜжңҖй«ҳпјҲwhere user_id > 0жқЎд»¶еҶіе®ҡзҡ„пјүдҪҶMySQLиҝҳжҳҜдҪҝз”Ёзҙўеј•гҖӮ
mysql> explain select* from user_info where user_id>0; +----+-------------+-----------+------------+------+----------------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+----------------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | user_info | NULL | ALL | ind_name_id,id_index | NULL | NULL | NULL | 4 | 100 | Using where | +----+-------------+-----------+------------+------+----------------------+------+---------+------+------+----------+-------------+ 1 row in set
д№ӢеҗҺејәеҲ¶дҪҝз”ЁзӢ¬з«Ӣзҙўеј•id_index(user_id)пјҡ
mysql> explain select* from user_info force index(id_index) where user_id>0; +----+-------------+-----------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+ | 1 | SIMPLE | user_info | NULL | range | id_index | id_index | 4 | NULL | 4 | 100 | Using index condition | +----+-------------+-----------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+ 1 row in set
еҫҲеӨҡж—¶еҖҷж•°жҚ®еә“зҡ„жҖ§иғҪжҳҜз”ұдәҺдёҚеҗҲйҖӮпјҲжҳҜжҢҮж•ҲзҺҮдёҚй«ҳпјҢеҸҜиғҪдјҡеҜјиҮҙй”ҒиЎЁзӯүпјүзҡ„SQLиҜӯеҸҘйҖ жҲҗпјҢе…¶дёӯжңүдәӣдјҳеҢ–еңЁзңҹжӯЈејҖеҸ‘дёӯжҳҜз”ЁдёҚеҲ°зҡ„пјҢдҪҶжҳҜдёҖж—ҰеҮәй—®йўҳжҖ§иғҪдёӢйҷҚзҡ„ж—¶еҖҷйңҖиҰҒеҺ»дёҖдёҖеҲҶжһҗгҖӮ
д»ҘдёҠе°ұжҳҜејҖеҸ‘дёӯйӮЈдәӣеёёз”Ёзҡ„MySQLдјҳеҢ–жңүе“ӘдәӣпјҢе°Ҹзј–зӣёдҝЎжңүйғЁеҲҶзҹҘиҜҶзӮ№еҸҜиғҪжҳҜжҲ‘们ж—Ҙеёёе·ҘдҪңдјҡи§ҒеҲ°жҲ–з”ЁеҲ°зҡ„гҖӮеёҢжңӣдҪ иғҪйҖҡиҝҮиҝҷзҜҮж–Үз« еӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮжӣҙеӨҡиҜҰжғ…敬иҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ