您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容介绍了“MapReduce执行流程是怎样的”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
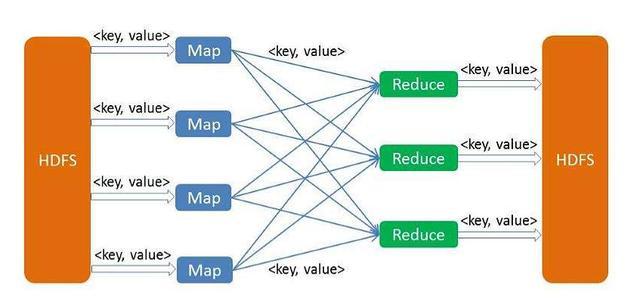
MapReduce执行流程图
概述
MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题。
MapReduce是分布式运行的,由两个阶段组成:Map和Reduce,Map阶段是一个独立的程序,有很多个节点同时运行,每个节点处理一部分数据。
Reduce阶段是一个独立的程序,有很多个节点同时运行,每个节点处理一部分数据。
使用
MapReduce框架都有默认实现,用户只需要覆盖map()和reduce()两个函数,即可实现分布式计算,非常简单。
这两个函数的形参和返回值都是,使用的时候一定要注意构造。
一个文本(在HDFS上面保存,两个block)中每一个单词的出现的次数: hello you hello marry hello me really ----->block-1 hello kate ready xiao wang hello tomcat ----->block-2
1.获取每一个block块中的文本,遍历所有,回去其中的一行str
因为要统计的是每一个单词i的次数,所以还需要直到文本中有哪些单词,可以根据字符串的特点,使用split()进行切割。
String[] words=str.split("");根据要求,需将每一个单词i转换为的形式,k为单词本身,v为单词出现的次数。
2.因为mr的计算是分布式的 ,每一个map(称之为一个mapper task)计算其中的一个block块数据。
map阶段: 输入<K1,V1> k1,偏移量,v1,当前行文本内容 map()函数操作 输出<K2,V2> k2,具体单词,v2,单词对应的统计项,比如次数 输出<K2,V2>
shuffle阶段 研究后发现,如果按照<key,1>这种方式向reduce输出数据的时候,会有 大量的冗余数据。 比如map阶段之后有5个hello,则输出<hello,1>,<hello,1>,<hello,1>, <hello,1>,<hello,1>5次,实际上会对网络造成一定的压力,能不能对 这5个<hello,1>进行一个进入reduce之前的本地组合?比如成为 <hello,5>或者<hello,[1,1,1,1,1]>. 这个过程成为shuffle,洗牌重组阶段,达到上述的结果,称之为规约。 >>>shuffle阶段,也就是对map的输出进行重新洗牌: 分区、分组、排序 <K2,V2>...===><K2,V2s>
reduce阶段 接收map的输出结果<key,values> 对这个结果进行汇总统计,针对values,进行简单的累加,计算得出key 对应的次数 reduce针对一个key调用一次reduce()函数 =====>reduce 阶段 输入<K2,V2> K2,就是map的输出的K2,V2s是map经过shuffle之后的结果集 reduce()函数操作 转化为<K3,V3>
经过上述操作之后,系统会将计算结果输出给用户,一般会先存储(落地)到hdfs,然后反馈给用户。
“MapReduce执行流程是怎样的”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。