您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
Hadoop的MapReduce shuffle过程,非常重要。只有熟悉整个过程才能对业务了如指掌。
MapReduce执行流程
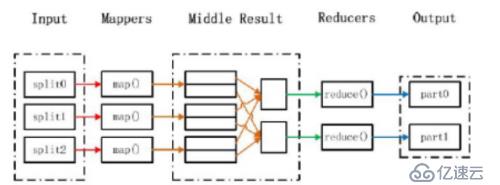
输入和拆分:
不属于map和reduce的主要过程,但属于整个计算框架消耗时间的一部分,该部分会为正式的map准备数据。
分片(split)操作:
split只是将源文件的内容分片形成一系列的 InputSplit,每个 InputSpilt 中存储着对 应分片的数据信息(例如,文件块信息、起始位置、数据长度、所在节点列表…),并不是将源文件分割成多个小文件,每个InputSplit 都由一个 mapper 进行后续处理。
每个分片大小参数是很重要的,splitSize 是组成分片规则很重要的一个参数,该参数由三个值来确定:
minSize:splitSize 的最小值,由 mapred-site.xml 配置文件中 mapred.min.split.size 参数确定。
maxSize:splitSize 的最大值,由 mapred-site.xml 配置文件中mapreduce.jobtracker.split.metainfo.maxsize 参数确定。
blockSize:HDFS 中文件存储的快大小,由 hdfs-site.xml 配置文件中 dfs.block.size 参数确定。
splitSize的确定规则:splitSize=max{minSize,min{maxSize,blockSize}}
数据格式化(Format)操作:
将划分好的 InputSplit 格式化成键值对形式的数据。其中 key 为偏移量,value 是每一行的内容。
值得注意的是,在map任务执行过程中,会不停的执行数据格式化操作,每生成一个键值对就会将其传入 map,进行处理。所以map和数据格式化操作并不存在前后时间差,而是同时进行的。

2)Map 映射:
是 Hadoop 并行性质发挥的地方。根据用户指定的map过程,MapReduce 尝试在数据所在机器上执行该 map 程序。在 HDFS中,文件数据是被复制多份的,所以计算将会选择拥有此数据的最空闲的节点。
在这一部分,map内部具体实现过程,可以由用户自定义。
3)Shuffle 派发:
Shuffle 过程是指Mapper 产生的直接输出结果,经过一系列的处理,成为最终的 Reducer 直接输入数据为止的整个过程。这是mapreduce的核心过程。该过程可以分为两个阶段:
Mapper 端的Shuffle:由 Mapper 产生的结果并不会直接写入到磁盘中,而是先存储在内存中,当内存中的数据量达到设定的阀值时,一次性写入到本地磁盘中。并同时进行 sort(排序)、combine(合并)、partition(分片)等操作。其中,sort 是把 Mapper 产 生的结果按照 key 值进行排序;combine 是把key值相同的记录进行合并;partition 是把 数据均衡的分配给 Reducer。
Reducer 端的 Shuffle:由于Mapper和Reducer往往不在同一个节点上运行,所以 Reducer 需要从多个节点上下载Mapper的结果数据,并对这些数据进行处理,然后才能被 Reducer处理。
4)Reduce 缩减:
Reducer 接收形式的数据流,形成形式的输出,具体的过程可以由用户自定义,最终结果直接写入hdfs。每个reduce进程会对应一个输出文件,名称以part-开头。
欢迎补充。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。