您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容介绍了“python数据分析之DataFrame内存优化的方法”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
?先说明一下情况,pandas处理几百兆的dataframe是没有问题的,但是我们在处理几个G甚至更大的数据时,就会特别占用内存,对内存小的用户特别不好,所以对数据进行压缩是很有必要的。
给大家看一下这么查看自己的内存大小(user_log是dataframe的名字)
#方法1 就是使用查看dataframe信息的命令
user_log.info()
#方法2 使用memory_usage()或者getsizeof(user_log)
import time
import sys
print("all_data占据内存约: {:.2f} GB".format(user_log.memory_usage().sum()/ (1024**3)))
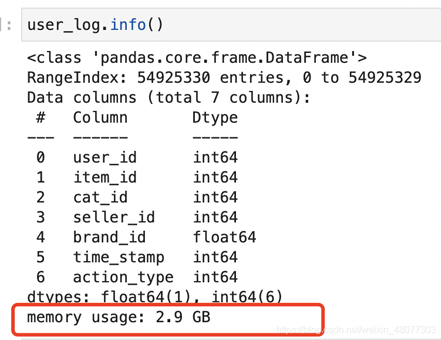
print("all_data占据内存约: {:.2f} GB".format(sys.getsizeof(user_log)/(1024**3)))我这里有个dataframe文件叫做user_log,原始大小为1.91G,然后pandas读取出来,内存使用了2.9G。
看一下原始数据大小:1.91G
pandas读取后的内存消耗:2.9G
数值类型的列进行降级处理(‘int16", ‘int32", ‘int64", ‘float16", ‘float32", ‘float64")
字符串类型的列转化为类别类型(category)
字符串类型的列的类别数超过总行数的一半时,建议使用object类型
我们这里主要采用对数值型类型的数据进行降级,说一下降级是什么意思意思呢,可以比喻为一个一个抽屉,你有一个大抽屉,但是你只装了钥匙,这就会有很多空间浪费掉,如果我们将钥匙放到一个小抽屉里,就可以节省很多空间,就像字符的类型int32 比int8占用空间大很多,但是我们的数据使用int8类型就够了,这就导致数据占用了很多空间,我们要做的就是进行数据类型转换,节省内存空间。
压缩数值的这段代码是从天池大赛的某个项目中看见的,查阅资料后发现,大家压缩内存都是基本固定的函数形式
def reduce_mem_usage(df):
starttime = time.time()
numerics = ["int16", "int32", "int64", "float16", "float32", "float64"]
start_mem = df.memory_usage().sum() / 1024**2
for col in df.columns:
col_type = df[col].dtypes
if col_type in numerics:
c_min = df[col].min()
c_max = df[col].max()
if pd.isnull(c_min) or pd.isnull(c_max):
continue
if str(col_type)[:3] == "int":
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
end_mem = df.memory_usage().sum() / 1024**2
print("-- Mem. usage decreased to {:5.2f} Mb ({:.1f}% reduction),time spend:{:2.2f} min".format(end_mem,
100*(start_mem-end_mem)/start_mem,
(time.time()-starttime)/60))
return df用压缩的方式将数据导入user_log2中
#首先读取到csv中如何传入函数生称新的csv user_log2=reduce_mem_usage(pd.read_csv(r"/Users/liucong/MainFiles/ML/tianchi/tianmiao/user_log_format1.csv"))
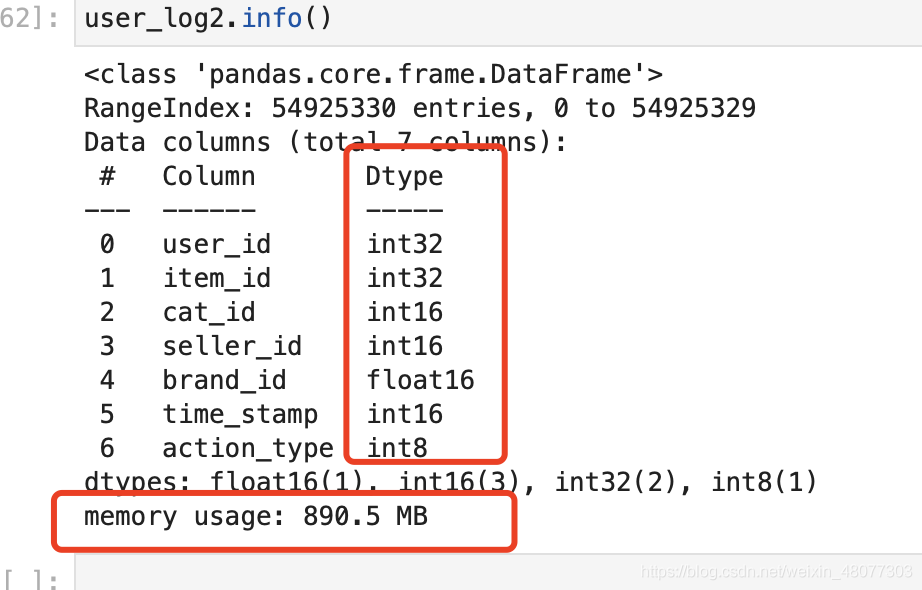
读取成功:内训大小为890.48m 减少了69.6%,效果显著

查看压缩后的数据集信息:类型发生了变化,数量变小了
“python数据分析之DataFrame内存优化的方法”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。