您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
今天小编给大家分享一下Python数据分析之Pandas Dataframe如何自定义的相关知识点,内容详细,逻辑清晰,相信大部分人都还太了解这方面的知识,所以分享这篇文章给大家参考一下,希望大家阅读完这篇文章后有所收获,下面我们一起来了解一下吧。
apply()函数是一个自定义函数作用于某一行或几行,或者某一列或多列上的每一个元素, 使用格式如下:
df.apply(func, axis=0, *args, **kwargs)
参数如下:
func:指定函数
axis:指定作用于行还是列,默认为0,表示作用于列,设置为1表示作用于行
*args&**kwargs:接收任意数量、类型的参数,这些参数被传递到函数func
例如,对下面Dataframe执行进行操作:
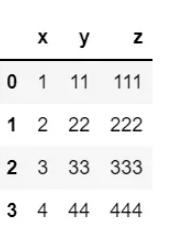
自定义"返回最大值"的函数并作用于该Dataframe:
def func(x): return x.max() df.apply(func)
结果输出如下:

可见,结果返回了每列最大的值,如果想返回每行最大的值,设置axis=1即可。
当然apply()也支持传递lambda匿名函数。
applymap()函数可以作用于DataFrame中的每一个元素,例如,转换DataFrame中数据的格式:
df.applymap(lambda x: '%.2f' % x)

注意:Pandas还提供了一个map()方法,作用于Series对象,此类方法和Python原生的map()方法都很类似。
以上就是“Python数据分析之Pandas Dataframe如何自定义”这篇文章的所有内容,感谢各位的阅读!相信大家阅读完这篇文章都有很大的收获,小编每天都会为大家更新不同的知识,如果还想学习更多的知识,请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。