жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
ж‘ҳиҰҒ
еңЁеӨ§ж•°жҚ®з®—жі•дёӯпјҢиҒҡзұ»з®—жі•дёҖиҲ¬йғҪжҳҜдҪңдёәе…¶д»–з®—жі•еҲҶжһҗзҡ„еҹәзЎҖпјҢеҜ№ж•°жҚ®иҝӣиЎҢиҒҡзұ»еҸҜд»Ҙд»Һж•ҙдҪ“дёҠеҲҶжһҗж•°жҚ®зҡ„дёҖдәӣзү№жҖ§гҖӮиҒҡзұ»жңүеҫҲеӨҡзҡ„з®—жі•пјҢk-meansжҳҜжңҖз®ҖеҚ•жңҖе®һз”Ёзҡ„дёҖз§Қз®—жі•гҖӮеңЁиҝҷйҮҢеҜ№k-meansз®—жі•зҡ„еҺҹзҗҶд»ҘеҸҠе…¶иғҢеҗҺзҡ„ж•°еӯҰжҺЁеҜјеҒҡдёҖ
дәӣиҜҰз»Ҷзҡ„д»Ӣз»ҚпјҢ并讨и®әеңЁе®һйҷ…еә”з”ЁдёӯиҰҒйҒҝе…Қзҡ„дёҖдәӣеқ‘гҖӮ
k-meansз®—жі•еҫҲз®ҖеҚ•пјҢдҪҶжҳҜеҪ“жҲ‘们жӯЈзңҹжҠҠиҝҷдёӘз®—жі•з”ЁеңЁз”ҹдә§дёӯж—¶иҝҳжҳҜеӯҳеңЁеҫҲеӨҡзҡ„з»ҶиҠӮйңҖиҰҒиҖғиҷ‘зҡ„пјҢиҝҷдәӣз»ҶиҠӮе°ҶиҰҒеңЁеҗҺйқўиҝӣиЎҢи®Ёи®әгҖӮйҰ–е…Ҳз»ҷеҮәk-meansз®—жі•зҡ„жӯҘйӘӨпјҡ
1гҖҒз»ҷеҮәkдёӘеҲқе§ӢиҒҡзұ»дёӯеҝғ
2гҖҒrepeatпјҡ
жҠҠжҜҸдёҖдёӘж•°жҚ®еҜ№иұЎйҮҚж–°еҲҶй…ҚеҲ°kдёӘиҒҡзұ»дёӯеҝғеӨ„пјҢеҪўжҲҗkдёӘз°Ү
йҮҚж–°и®Ўз®—жҜҸдёҖдёӘз°Үзҡ„иҒҡзұ»дёӯеҝғ
3гҖҒuntil иҒҡзұ»дёӯеҝғдёҚеңЁеҸ‘з”ҹеҸҳеҢ–
еҪ“жҲ‘们жӢҝеҲ°дёҖжү№ж•°жҚ®ж—¶пјҢеӨ§еӨҡж•°жғ…еҶөдёӢжҲ‘们жҳҜдёҚзҹҘйҒ“з°Үзҡ„дёӘж•°зҡ„гҖӮ
aгҖҒеңЁдёҖдәӣжғ…еҶөдёӢпјҢжҲ‘们йҖҡиҝҮеҜ№дёҡеҠЎдәҶи§Јзҡ„еҠ ж·ұпјҢжҳҜеҸҜд»ҘжүҫеҲ°ж•°жҚ®зҡ„з°Үзҡ„пјҢжҜ”еҰӮжҲ‘们жүӢйҮҢжңүдёҖжү№з”ЁжҲ·иҙӯд№°е•Ҷе“Ғзҡ„и®°еҪ•ж•°жҚ®пјҢе·Із»Ҹз»ҹи®ЎеҮәз”ЁжҲ·е·ҘдҪңж—Ҙе’Ңе‘Ёжң«иҙӯд№°зү©е“Ғзҡ„ж•°йҮҸпјҢеңЁдәҢз»ҙеҒҡеқҗж ҮдёӯеҲҶеҲ«дёәпјҡе·ҘдҪңж—Ҙиҙӯд№°зҡ„зү©е“Ғж•°е’Ңе‘Ёжң«иҙӯд№°зҡ„зү©е“Ғж•°пјҢд»ҺиҝҷжҲ‘们еҸҜд»ҘеҸ‘зҺ°пјҢжҲ‘们дәәдёәе·Із»ҸжҠҠж•°жҚ®еҲҶдёәдёүдёӘз°Үпјҡе‘Ёжң«иҙӯд№°гҖҒе·ҘдҪңж—Ҙиҙӯд№°е’Ңе‘Ёжң«е’Ңе·ҘдҪңж—ҘйғҪиҙӯд№°зҡ„дәәж•°
bгҖҒеҪ“жҲ‘们зңҹзҡ„зЎ®е®ҡдёҚдәҶж•°жҚ®зҡ„з°Үж—¶пјҢжҲ‘们еҸҜд»ҘйҖҡиҝҮзӣёе…ізҡ„з®—жі•жқҘеӨ§жҰӮзЎ®е®ҡж•°жҚ®зҡ„з°ҮгҖӮеҜ№kиҝӣиЎҢеӨҡж¬ЎеҸ–еҖјпјҢйҖҡиҝҮдёҖдёӘзӣ®ж ҮеҮҪж•°fиҝӣиЎҢеәҰйҮҸпјҢйҖүеҸ–дҪҝиҝҷдёӘfеҖјжңҖе°Ҹзҡ„kдҪңдёәиҒҡзұ»дёӯеҝғпјҲзӣ®ж ҮеҮҪж•°fеҗҺйқўдјҡи®ІеҲ°),иҝӣиЎҢеӨҡж¬ЎйҖүжӢ©kеҖјж—¶пјҢж—¶й—ҙе’Ңз©әй—ҙеӨҚжқӮеәҰйғҪдјҡеўһеҠ гҖӮиҝҳдёҖз§Қзӯ–з•ҘжҳҜйҖҡиҝҮдёҖдёӘз®—жі•canopyз®—жі•еҲқе§ӢйҖүеҸ–еҮәиҒҡзұ»зҡ„дёӘж•°kе’ҢеҲқе§Ӣзҡ„иҒҡдёӯеҝғдҪңдёәk-meansз®—жі•зҡ„иҫ“е…ҘпјҢиҖҢcanopyз®—жі•дёҚйңҖиҰҒиҫ“е…Ҙkе’ҢеҲқе§ӢиҒҡзұ»дёӯеҝғпјҢе®ғеҸҜд»ҘдҪңдёәk-meansз®—жі•йў„еӨ„зҗҶз®—жі•з”ЁжқҘйҖүеҸ–k-meansз®—жі•гҖӮжүҖйңҖиҰҒзҡ„kеҖје’ҢиҒҡзұ»дёӯеҝғ
йҖүеҸ–еҲқе§ӢиҒҡзұ»дёӯеҝғжҳҜжңҖи®©дәәеӨҙз–јзҡ„дёҖ件дәӢпјҢеҰӮжһңйҖүжӢ©зҡ„дёҚеҘҪе°ұе®№жҳ“жүҫеҲ°еұҖйғЁжңҖдјҳиҒҡзұ»дёӯеҝғиҖҢдёҚжҳҜе…ЁеұҖжңҖдјҳзҡ„иҒҡзұ»дёӯеҝғгҖӮ
aгҖҒзҹҘйҒ“дәҶkеҗҺпјҢеҶҚйҖүеҸ–еҲқе§Ӣзҡ„иҒҡзұ»дёӯеҝғгҖӮдёҖз§Қзӯ–з•ҘжҳҜиҝӣиЎҢеӨҡж¬ЎйҡҸжңәзҡ„йҖүжӢ©kдёӘзӮ№дҪңдёәеҲқе§ӢиҒҡзұ»дёӯеҝғпјҢжҜ”иҫғзӣ®ж ҮеҮҪж•°fпјҢйҖүеҸ–зӣ®ж ҮеҮҪж•°fжңҖе°Ҹзҡ„жңҖдёәеҲқе§Ӣзҡ„иҒҡзұ»дёӯеҝғпјҢиҝҷз§ҚйҡҸжңәйҖүжӢ©жңүеҫҲеӨҡзҡ„дёҚи¶іпјҡ1гҖҒж— еҪўдёӯе°ұеўһеҠ дәҶж—¶й—ҙејҖй”Җе’Ңз©әй—ҙејҖй”Җ 2гҖҒжүҫеҲ°зҡ„иҒҡзұ»дёӯеҝғеҸҜиғҪжҳҜеұҖйғЁжңҖдјҳзҡ„иҖҢдёҚжҳҜе…ЁеұҖжңҖдјҳзҡ„пјҢеӣ дёәеҪ“йҡҸжңәйҖүжӢ©зҡ„дёӨдёӘиҒҡзұ»дёӯеҝғдҪҚдәҺдёҖдёӘз°ҮдёӯпјҢж— и®әжҖҺд№ҲйҮҚж–°и®Ўз®—иҒҡзұ»дёӯеҝғпјҢеҫ—еҲ°зҡ„з»“жһңйғҪдёҚжҳҜе…ЁеұҖжңҖдјҳзҡ„пјҢеҲҶзұ»зҡ„з»“жһңд№ҹдёҚжҳҜжҲ‘们жғіиҰҒзҡ„гҖӮиҷҪ然иҝҷз§Қзӯ–з•ҘжңүеҫҲеӨҡзҡ„дёҚи¶іпјҢдёҚд»ЈиЎЁжҲ‘们дёҚеҸҜд»ҘдҪҝз”ЁпјҢеңЁе®һйҷ…еә”з”ЁдёӯжҲ‘们иҝҳжҳҜеҸҜд»ҘйҖүжӢ©иҝҷдёӯзӯ–з•ҘиҝӣиЎҢз”ҹдә§зҡ„гҖӮ
bгҖҒеҪ“зҹҘйҒ“дәҶkеҗҺпјҢиҝҳжңүдёҖз§ҚйҖүеҸ–иҒҡзұ»дёӯеҝғзҡ„зӯ–з•Ҙ:йҰ–е…ҲжҲ‘们жҠҠж•°жҚ®еҲҶдёәдёӨдёӘйғЁеҲҶпјҡиҒҡзұ»дёӯеҝғйӣҶеҗҲе’ҢеҺҹе§Ӣж•°жҚ®йӣҶеҗҲпјҢйҰ–е…ҲжҲ‘们д»ҺеҺҹе§Ӣж•°жҚ®йӣҶеҗҲдёӯйҡҸжңәзҡ„йҖүжӢ©дёҖдёӘж•°жҚ®жңҖдёәеҲқе§ӢиҒҡзұ»дёӯеҝғзҡ„дёҖдёӘз°Үдёӯеҝғж”ҫе…ҘиҒҡзұ»дёӯеҝғйӣҶеҗҲдёӯпјҢ然еҗҺжҲ‘们еҶҚд»ҺеҺҹе§Ӣж•°жҚ®йӣҶдёӯйҖүжӢ©дёҖдёӘиҒҡзұ»иҒҡзұ»дёӯеҝғйӣҶеҗҲдёӯжүҖжңүзҡ„и®°еҪ•йғҪжңҖиҝңзҡ„дёҖдёӘзӮ№дҪңдёәдёӢдёҖдёӘеҲқе§Ӣзҡ„иҒҡзұ»дёӯеҝғгҖӮиҝҷз§ҚйҖүжӢ©еңЁе®һйҷ…еә”з”ЁдёӯиҜҒжҳҺдәҶд№ҹжҳҜжҜ”иҫғеҘҪзҡ„дёҖз§Қзӯ–з•ҘпјҢеҫ—еҲ°зҡ„ж•ҲжһңиҰҒжҜ”aзӯ–з•Ҙеҫ—еҲ°зҡ„еҘҪдёҖдәӣпјҢдҪҶжҳҜиҝҷз§Қзӯ–з•ҘиҰҒеҸ—еҲ°зҰ»зҫӨзӮ№зҡ„жү°еҠЁжҜ”иҫғзҡ„еӨ§пјҢеҗҢж—¶йҖүжӢ©еҲқе§ӢиҒҡзұ»дёӯеҝғзҡ„и®Ўз®—йҮҸд№ҹжҳҜйқһеёёеӨ§зҡ„пјҢз©әй—ҙж¶ҲиҖ—д№ҹйқһеёёзҡ„еӨ§гҖӮ
cгҖҒеҪ“kдёҚзҹҘйҒ“зҡ„жғ…еҶөдёӢпјҢжңҖеёёз”Ёзҡ„дёҖз§Қзӯ–з•Ҙе°ұжҳҜдҪҝз”Ёcanopyз®—жі•жқҘеҜ»жүҫkе’ҢиҒҡзұ»дёӯеҝғгҖӮ
еңЁk-meansз®—жі•дёӯпјҢжҲ‘们йңҖиҰҒжҠҠж•°жҚ®йӣҶеҲҶеҲ°и·қзҰ»иҒҡзұ»дёӯеҝғжңҖиҝ‘зҡ„йӮЈдёӘз°ҮдёӯпјҢиҝҷж ·е°ұйңҖиҰҒжңҖиҝ‘йӮ»зҡ„еәҰйҮҸзӯ–з•ҘгҖӮжҲ‘们йңҖиҰҒз”Ёд»Җд№ҲжқҘиЎЎйҮҸжңҖиҝ‘пјҢжҖҺд№ҲиЎЎйҮҸпјҹk-meansз®—жі•йңҖиҰҒи®Ўз®—и·қзҰ»пјҢи®Ўз®—и·қзҰ»е°ұйңҖиҰҒж•°еҖјпјҢеӣ жӯӨk-meansз®—жі•д№ҹжҳҜеҜ№ж•°еҖјеһӢж•°жҚ®жҜ”иҫғе®һз”ЁгҖӮk-meansз®—жі•дёӯжңҖеёёз”Ёзҡ„еәҰйҮҸе…¬ејҸпјҡеңЁж¬§ејҸз©әй—ҙдёӯйҮҮз”Ёзҡ„жҳҜ欧ејҸи·қзҰ»пјҢеңЁеӨ„зҗҶж–ҮжЎЈдёӯйҮҮз”Ёзҡ„жҳҜдҪҷејҰзӣёдјјеәҰеҮҪж•°пјҢжңүж—¶еҖҷд№ҹйҮҮз”Ёжӣје“ҲйЎҝи·қзҰ»дҪңдёәеәҰйҮҸпјҢдёҚеҗҢзҡ„жғ…еҶөе®һз”Ёзҡ„еәҰйҮҸе…¬ејҸжҳҜдёҚдёҖж ·зҡ„гҖӮ
欧ејҸи·қзҰ»
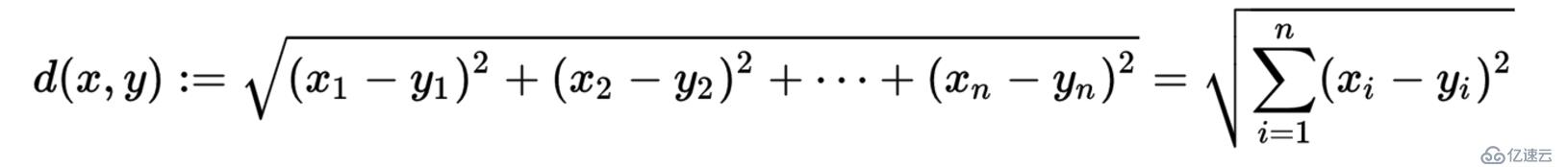
дҪҷејҰзӣёдјјеәҰи®Ўз®—е…¬ејҸ
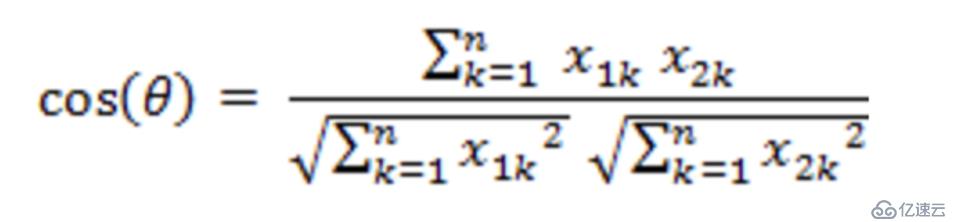
еҗ‘йҮҸиЎЁзӨәжі•
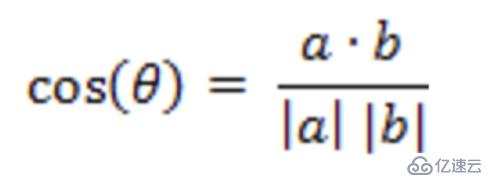
жӣје“ҲйЎҝи·қзҰ»:
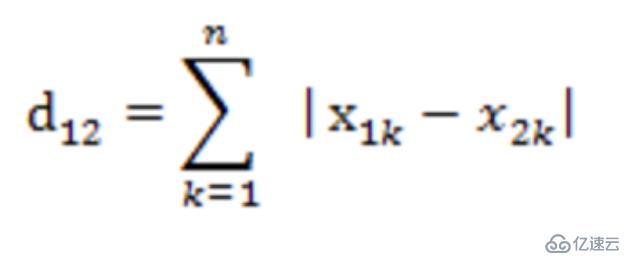
k-meansз®—жі•иҰҒи§ЈеҶізҡ„й—®йўҳжҳҜжҲ‘们жҠҠж•°жҚ®з»ҷеҲҶжҲҗдёҚеҗҢзҡ„з°ҮпјҢйӮЈжҲ‘们иҰҒиҫҫеҲ°зҡ„зӣ®ж ҮжҳҜд»Җд№Ҳе‘ўпјҹжҳҜдҪҝеҫ—еҗҢдёҖдёӘз°Үзҡ„е·®ејӮеҫҲе°ҸпјҢдёҚеҗҢз°Үд№Ӣй—ҙзҡ„ж•°жҚ®е·®ејӮжңҖеӨ§еҢ–пјҢиҝҷжҳҜж–Үеӯ—жҸҸиҝ°зҡ„пјҢдёҚиғҪз”ЁжқҘж ҮеҮҶеҢ–з ”з©¶жҲ–иҖ…ж•°еӯҰжҺЁеҜјпјҢжҲ‘们жғіиҰҒеҲҡжүҚзҡ„дёҖеҸҘиҜқз”ЁдёҖдёӘж•°жҚ®е…¬ејҸжҲ–иҖ…ж•°еӯҰжЁЎеһӢжқҘиҝӣиЎҢиЎЎйҮҸпјҢе»әз«ӢжҖҺд№Ҳж ·зҡ„ж•°еӯҰе…¬ејҸжүҚиғҪз”ЁжқҘиЎЎйҮҸдёҠйқўзҡ„жҸҸиҝ°пјҹдёҖиҲ¬жғ…еҶөдёӢйҮҮз”Ёзҡ„жҳҜиҜҜе·®е№іж–№е’ҢдҪңдёәиЎЎйҮҸзҡ„зӣ®ж ҮеҮҪж•°SSEпјҢдёҠйқўжҸҗеҲ°зҡ„зӣ®ж ҮеҮҪж•°fе°ұжҳҜSSEд№ҹжҳҜиҜҜе·®е№іж–№е’ҢгҖӮе…ҲдёҠе…¬ејҸ:
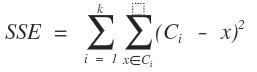
е…ғзҙ и§ЈйҮҠ:CиЎЁзӨәзҡ„иҒҡзұ»дёӯеҝғзҡ„еҖјпјҢxжҳҜеұһдәҺиҝҷдёӘз°Үзҡ„ж•°жҚ®зӮ№пјҢdдёә欧ејҸи·қзҰ»
дёәдәҶе®һзҺ°еҗҢдёҖдёӘз°Үзҡ„е·®ејӮеҫҲе°ҸпјҢдёҚеҗҢз°Үд№Ӣй—ҙзҡ„е…ғзҙ ж•°жҚ®е·®ејӮжңҖеӨ§еҢ–(жҲ‘们й»ҳи®Өзҡ„ж•°жҚ®йғҪжҳҜеңЁж¬§ејҸз©әй—ҙдёӯпјҢж•°жҚ®зҡ„е·®ејӮйҮҮз”Ёзҡ„жҳҜ欧ејҸи·қзҰ»жқҘиҝӣиЎҢиЎЎйҮҸ)гҖӮдёәдәҶе®һзҺ°иҝҷдёӘзӣ®ж ҮпјҢе®һйҷ…дёҠжҳҜдҪҝиҜҜе·®е№іж–№е’ҢSSEжңҖе°ҸпјҢеңЁдәҶk-meansз®—жі•дёӯпјҢжңүдёӨдёӘең°ж–№йҷҚдҪҺдәҶSSEж•°еҖјпјҡжҠҠж•°жҚ®зӮ№еҲҶеҲ°и·қзҰ»дёӯеҝғзӮ№жңҖиҝ‘зҡ„з°ҮдёӯпјҢиҝҷж ·и®Ўз®—еҮәжқҘзҡ„SSEе°ҶеҮҸе°‘гҖҒйҮҚж–°и®Ўз®—иҒҡзұ»дёӯеҝғзӮ№пјҢеҸҲиҝӣдёҖжӯҘзҡ„йҷҚдҪҺдәҶSSEпјҢдҪҶжҳҜиҝҷж ·зҡ„дјҳеҢ–зӯ–з•ҘеҸӘжҳҜдёәдәҶжүҫеҲ°еұҖйғЁжңҖдјҳи§ЈпјҢеҰӮжһңжғіиҰҒжүҫеҲ°е…ЁеұҖжңҖдјҳи§ЈйңҖиҰҒжүҫеҲ°еҗҲзҗҶзҡ„еҲқе§ӢиҒҡзұ»дёӯеҝғгҖӮ
иҝҳжңүдёҖдёӘй—®йўҳйңҖиҰҒжҲ‘们жқҘи®Ёи®әпјҢжҲ‘们дёәд»Җд№ҲйҖүеҸ–з°ҮйӣҶеҗҲзҡ„е№іеқҮеҖјдҪңдёәиҒҡзұ»дёӯеҝғе‘ўпјҢеӣ дёәиҝҷж ·жүҚиғҪжҳҜSSEиҫҫеҲ°жңҖе°ҸпјҢеңЁж•°еӯҰдёӯжұӮдёҖдёӘеҮҪж•°зҡ„жңҖе°ҸеҖјпјҢжҖҺд№ҲеҠһпјҹжҳҜдёҚжҳҜжұӮеҜјпјҢжҲ‘们еҸ‘зҺ°SSEжҳҜдёҖдёӘдәҢе…ғеҮҪж•°пјҢйӮЈе°ұжұӮеҒҸеҜјеҗ§пјҢеҰӮдёӢжҺЁеҜјгҖӮ
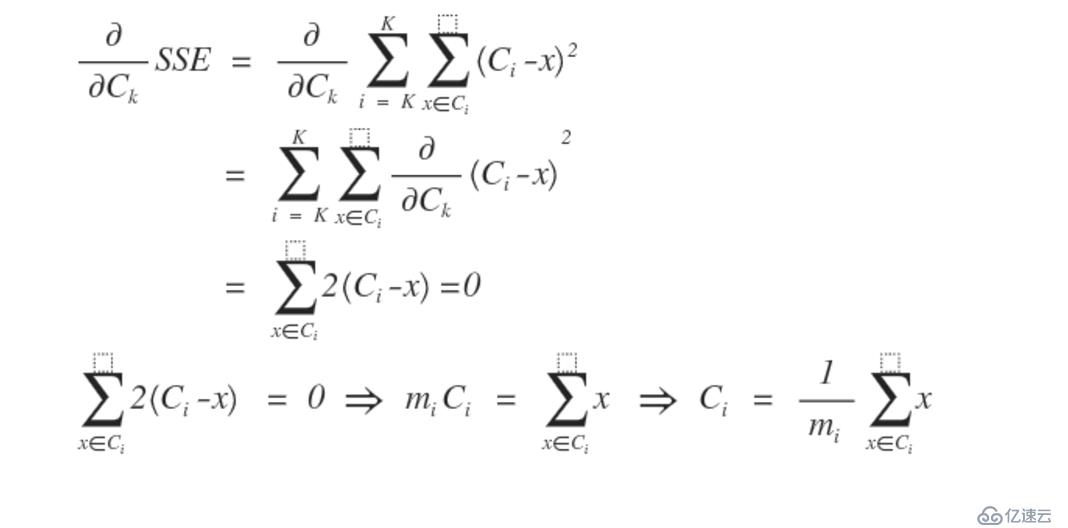
д»ҺдёҠйқўзҡ„жҺЁеҜјпјҢеҸҜд»ҘзңӢеҮәжҲ‘们дёәд»Җд№ҲйҖүжӢ©еқҮеҖјдҪңдёәиҒҡзұ»дёӯеҝғпјҢеҪ“иҒҡзұ»дёӯеҝғдёәз°Үдёӯзҡ„еқҮеҖјж—¶пјҢжүҚиғҪжҳҜSSEжңҖе°ҸпјҢеңЁжҺҘдёӢжқҘдјҡеҜ№sparkMLlibдёӯеҜ№дәҺk-meansзҡ„з®—жі•иҝӣиЎҢиҜҰз»Ҷзҡ„д»Ӣз»ҚпјҢеҶҚиЎҘеҗ§
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ