жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңClassificationз®—жі•жҢҮж ҮжҳҜд»Җд№ҲвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
еёёи§Ғзҡ„еҲҶзұ»пјҲClassificationпјүз®—жі•жҢҮж Үдё»иҰҒжңүзІҫеәҰпјҲAccuracyпјүгҖҒеҮҶзЎ®зҺҮе’ҢеҸ¬еӣһзҺҮгҖҒROCжӣІзәҝе’ҢAUCз©әй—ҙиҝҷеҮ з§ҚгҖӮ
еҲҶзұ»жҳҜжңәеҷЁеӯҰд№ дёӯзҡ„дёҖзұ»йҮҚиҰҒй—®йўҳпјҢеҫҲеӨҡйҮҚиҰҒзҡ„з®—жі•йғҪеңЁи§ЈеҶіеҲҶзұ»й—®йўҳпјҢдҫӢеҰӮеҶізӯ–ж ‘пјҢж”ҜжҢҒеҗ‘йҮҸжңәзӯүпјҢе…¶дёӯдәҢеҲҶзұ»й—®йўҳжҳҜеҲҶзұ»й—®йўҳдёӯзҡ„дёҖдёӘйҮҚиҰҒзҡ„иҜҫйўҳгҖӮ
еёёи§Ғзҡ„еҲҶзұ»жЁЎеһӢеҢ…жӢ¬пјҡйҖ»иҫ‘еӣһеҪ’гҖҒеҶізӯ–ж ‘гҖҒжңҙзҙ иҙқеҸ¶ж–ҜгҖҒSVMгҖҒзҘһз»ҸзҪ‘з»ңзӯүпјҢжЁЎеһӢиҜ„дј°жҢҮж ҮеҢ…жӢ¬д»ҘдёӢеҮ з§Қпјҡ
д»Җд№ҲжҳҜж··ж·Ҷзҹ©йҳөпјҲConfusionmatrixпјүгҖӮиҝҷдёӘеҗҚеӯ—иө·еҫ—жҳҜзңҹзҡ„еҘҪпјҢеҲқеӯҰиҖ…еҫҲе®№жҳ“иў«иҝҷдёӘзҹ©йҳөжҗһеҫ—жҷ•еӨҙиҪ¬еҗ‘гҖӮдёӢеӣҫaе°ұжҳҜжңүеҗҚзҡ„ж··ж·Ҷзҹ©йҳөпјҢиҖҢдёӢеӣҫbеҲҷжҳҜз”ұж··ж·Ҷзҹ©йҳөжҺЁеҮәзҡ„дёҖдәӣжңүеҗҚзҡ„иҜ„дј°жҢҮж ҮгҖӮ
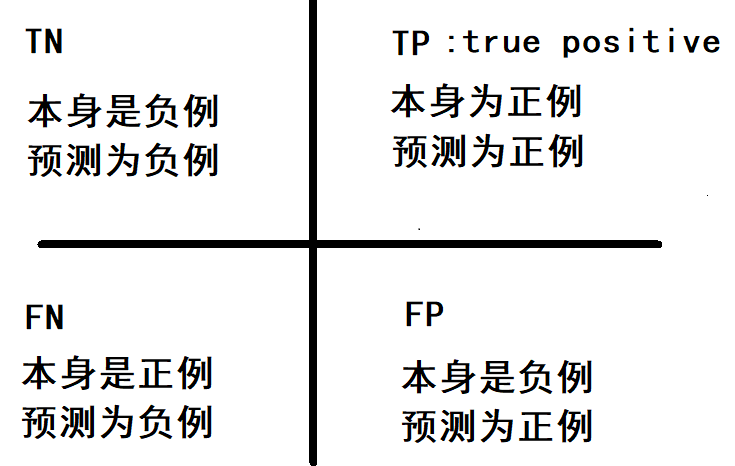
еңЁдәҢеҲҶзұ»й—®йўҳдёӯпјҢеҚіе°Ҷе®һдҫӢеҲҶжҲҗжӯЈзұ»пјҲpositiveпјүжҲ–иҙҹзұ»пјҲnegativeпјүгҖӮеҜ№дёҖдёӘдәҢеҲҶй—®йўҳжқҘиҜҙпјҢдјҡеҮәзҺ°еӣӣз§Қжғ…еҶөгҖӮеҰӮжһңдёҖдёӘе®һдҫӢжҳҜжӯЈзұ»е№¶дё”д№ҹиў« йў„жөӢжҲҗжӯЈзұ»пјҢеҚідёәзңҹжӯЈзұ»пјҲTrue positiveпјү,еҰӮжһңе®һдҫӢжҳҜиҙҹзұ»иў«йў„жөӢжҲҗжӯЈзұ»пјҢз§°д№ӢдёәеҒҮжӯЈзұ»пјҲFalse positiveпјүгҖӮзӣёеә”ең°пјҢеҰӮжһңе®һдҫӢжҳҜиҙҹзұ»иў«йў„жөӢжҲҗиҙҹзұ»пјҢз§°д№Ӣдёәзңҹиҙҹзұ»пјҲTrue negativeпјү,жӯЈзұ»иў«йў„жөӢжҲҗиҙҹзұ»еҲҷдёәеҒҮиҙҹзұ»пјҲfalse negativeпјүгҖӮ
True Positive пјҲзңҹжӯЈ, TPпјү иў«жЁЎеһӢйў„жөӢдёәжӯЈзҡ„жӯЈж ·жң¬пјӣеҸҜд»Ҙз§°дҪңеҲӨж–ӯдёәзңҹзҡ„жӯЈзЎ®зҺҮ
True Negative пјҲзңҹиҙҹ , TNпјү иў«жЁЎеһӢйў„жөӢдёәиҙҹзҡ„иҙҹж ·жң¬ пјӣеҸҜд»Ҙз§°дҪңеҲӨж–ӯдёәеҒҮзҡ„жӯЈзЎ®зҺҮ
False Positive пјҲеҒҮжӯЈ, FPпјү иў«жЁЎеһӢйў„жөӢдёәжӯЈзҡ„иҙҹж ·жң¬пјӣеҸҜд»Ҙз§°дҪңиҜҜжҠҘзҺҮ
False NegativeпјҲеҒҮиҙҹ , FNпјү иў«жЁЎеһӢйў„жөӢдёәиҙҹзҡ„жӯЈж ·жң¬пјӣеҸҜд»Ҙз§°дҪңжјҸжҠҘзҺҮ
True Positive RateпјҲзңҹжӯЈзҺҮ , TPRпјүжҲ–зҒөж•ҸеәҰпјҲsensitivityпјү
TPR = TP /пјҲTP + FNпјү
жӯЈж ·жң¬йў„жөӢз»“жһңж•° / жӯЈж ·жң¬е®һйҷ…ж•°
True Negative RateпјҲзңҹиҙҹзҺҮ , TNRпјүжҲ–зү№жҢҮеәҰпјҲspecificityпјү
TNR = TN /пјҲTN + FPпјү
иҙҹж ·жң¬йў„жөӢз»“жһңж•° / иҙҹж ·жң¬е®һйҷ…ж•°
False Positive Rate пјҲеҒҮжӯЈзҺҮ, FPRпјү
FPR = FP /пјҲFP + TNпјү
иў«йў„жөӢдёәжӯЈзҡ„иҙҹж ·жң¬з»“жһңж•° /иҙҹж ·жң¬е®һйҷ…ж•°
False Negative RateпјҲеҒҮиҙҹзҺҮ , FNRпјү
FNR = FN /пјҲTP + FNпјү
иў«йў„жөӢдёәиҙҹзҡ„жӯЈж ·жң¬з»“жһңж•° / жӯЈж ·жң¬е®һйҷ…ж•°
зІҫзЎ®еәҰпјҲPrecisionпјүпјҡ
P = TP/(TP+FP) ; еҸҚжҳ дәҶиў«еҲҶзұ»еҷЁеҲӨе®ҡзҡ„жӯЈдҫӢдёӯзңҹжӯЈзҡ„жӯЈдҫӢж ·жң¬зҡ„жҜ”йҮҚ
еҮҶзЎ®зҺҮпјҲAccuracyпјү
A = (TP + TN)/(P+N) = (TP + TN)/(TP + FN + FP + TN);
еҸҚжҳ дәҶеҲҶзұ»еҷЁз»ҹеҜ№ж•ҙдёӘж ·жң¬зҡ„еҲӨе®ҡиғҪеҠӣвҖ”вҖ”иғҪе°ҶжӯЈзҡ„еҲӨе®ҡдёәжӯЈпјҢиҙҹзҡ„еҲӨе®ҡдёәиҙҹ
еҸ¬еӣһзҺҮ(Recall)пјҢд№ҹз§°дёә True Positive Rate:
R = TP/(TP+FN) = 1 - FN/T; еҸҚжҳ дәҶиў«жӯЈзЎ®еҲӨе®ҡзҡ„жӯЈдҫӢеҚ жҖ»зҡ„жӯЈдҫӢзҡ„жҜ”йҮҚ
from sklearn.metrics import confusion_matrix # y_predжҳҜйў„жөӢж Үзӯҫ y_pred, y_true =[1,0,1,0], [0,0,1,0] confusion_matrix(y_true=y_true, y_pred=y_pred)
зІҫзЎ®зҺҮпјҲжӯЈзЎ®зҺҮпјүе’ҢеҸ¬еӣһзҺҮжҳҜе№ҝжіӣз”ЁдәҺдҝЎжҒҜжЈҖзҙўе’Ңз»ҹи®ЎеӯҰеҲҶзұ»йўҶеҹҹзҡ„дёӨдёӘеәҰйҮҸеҖјпјҢз”ЁжқҘиҜ„д»·з»“жһңзҡ„иҙЁйҮҸгҖӮе…¶дёӯзІҫеәҰжҳҜжЈҖзҙўеҮәзӣёе…іж–ҮжЎЈж•°дёҺжЈҖзҙўеҮәзҡ„ж–ҮжЎЈжҖ»ж•°зҡ„жҜ”зҺҮпјҢиЎЎйҮҸзҡ„жҳҜжЈҖзҙўзі»з»ҹзҡ„жҹҘеҮҶзҺҮпјӣеҸ¬еӣһзҺҮжҳҜжҢҮжЈҖзҙўеҮәзҡ„зӣёе…іж–ҮжЎЈж•°е’Ңж–ҮжЎЈеә“дёӯжүҖжңүзҡ„зӣёе…іж–ҮжЎЈж•°зҡ„жҜ”зҺҮпјҢиЎЎйҮҸзҡ„жҳҜжЈҖзҙўзі»з»ҹзҡ„жҹҘе…ЁзҺҮгҖӮ
гҖҖгҖҖдёҖиҲ¬жқҘиҜҙпјҢPrecisionе°ұжҳҜжЈҖзҙўеҮәжқҘзҡ„жқЎзӣ®пјҲжҜ”еҰӮпјҡж–ҮжЎЈгҖҒзҪ‘йЎөзӯүпјүжңүеӨҡе°‘жҳҜеҮҶзЎ®зҡ„пјҢRecallе°ұжҳҜжүҖжңүеҮҶзЎ®зҡ„жқЎзӣ®жңүеӨҡе°‘иў«жЈҖзҙўеҮәжқҘдәҶпјҢдёӨиҖ…зҡ„е®ҡд№үеҲҶеҲ«еҰӮдёӢпјҡ
Precision = жҸҗеҸ–еҮәзҡ„жӯЈзЎ®дҝЎжҒҜжқЎж•° / жҸҗеҸ–еҮәзҡ„дҝЎжҒҜжқЎж•°
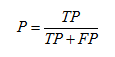
Recall = жҸҗеҸ–еҮәзҡ„жӯЈзЎ®дҝЎжҒҜжқЎж•° / ж ·жң¬дёӯзҡ„дҝЎжҒҜжқЎж•°
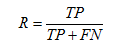
Precisionе’ҢRecallжҢҮж Үжңүж—¶еҖҷдјҡеҮәзҺ°зҡ„зҹӣзӣҫзҡ„жғ…еҶөпјҢиҝҷж ·е°ұйңҖиҰҒз»јеҗҲиҖғиҷ‘他们пјҢжңҖеёёи§Ғзҡ„ж–№жі•е°ұжҳҜеңЁPrecisionе’ҢRecallзҡ„еҹәзЎҖдёҠжҸҗеҮәдәҶF1еҖјзҡ„жҰӮеҝөпјҢжқҘеҜ№Precisionе’ҢRecallиҝӣиЎҢж•ҙдҪ“иҜ„д»·гҖӮF1зҡ„е®ҡд№үеҰӮдёӢпјҡ
F1еҖј = жӯЈзЎ®зҺҮ * еҸ¬еӣһзҺҮ * 2 / (жӯЈзЎ®зҺҮ + еҸ¬еӣһзҺҮ)
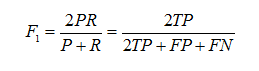
гҖҖгҖҖF-MeasureжҳҜPrecisionе’ҢRecallеҠ жқғи°ғе’Ңе№іеқҮпјҡ
гҖҖгҖҖеҪ“еҸӮж•°Оұ=1ж—¶пјҢе°ұжҳҜжңҖеёёи§Ғзҡ„F1гҖӮеӣ жӯӨпјҢF1з»јеҗҲдәҶPе’ҢRзҡ„з»“жһңпјҢеҪ“F1иҫғй«ҳж—¶еҲҷиғҪиҜҙжҳҺиҜ•йӘҢж–№жі•жҜ”иҫғжңүж•ҲгҖӮ

гҖҖгҖҖеҮҶзЎ®зҺҮе’ҢеҸ¬еӣһзҺҮжҳҜдә’зӣёеҪұе“Қзҡ„пјҢзҗҶжғіжғ…еҶөдёӢиӮҜе®ҡжҳҜеҒҡеҲ°дёӨиҖ…йғҪй«ҳпјҢдҪҶжҳҜдёҖиҲ¬жғ…еҶөдёӢеҮҶзЎ®зҺҮй«ҳгҖҒеҸ¬еӣһзҺҮе°ұдҪҺпјҢеҸ¬еӣһзҺҮдҪҺгҖҒеҮҶзЎ®зҺҮй«ҳпјҢеҪ“然еҰӮжһңдёӨиҖ…йғҪдҪҺпјҢйӮЈжҳҜд»Җд№Ҳең°ж–№еҮәй—®йўҳдәҶгҖӮеҪ“зІҫзЎ®зҺҮе’ҢеҸ¬еӣһзҺҮйғҪй«ҳж—¶пјҢF1зҡ„еҖјд№ҹдјҡй«ҳгҖӮеңЁдёӨиҖ…йғҪиҰҒжұӮй«ҳзҡ„жғ…еҶөдёӢпјҢеҸҜд»Ҙз”ЁF1жқҘиЎЎйҮҸ
ең°йңҮзҡ„йў„жөӢ
еҜ№дәҺең°йңҮзҡ„йў„жөӢпјҢжҲ‘们еёҢжңӣзҡ„жҳҜRECALLйқһеёёй«ҳпјҢд№ҹе°ұжҳҜиҜҙжҜҸж¬Ўең°йңҮжҲ‘们йғҪеёҢжңӣйў„жөӢеҮәжқҘгҖӮиҝҷдёӘж—¶еҖҷжҲ‘们еҸҜд»ҘзүәзүІPRECISIONгҖӮжғ…ж„ҝеҸ‘еҮә1000ж¬ЎиӯҰжҠҘпјҢжҠҠ10ж¬Ўең°йңҮйғҪйў„жөӢжӯЈзЎ®дәҶпјӣд№ҹдёҚиҰҒйў„жөӢ100ж¬ЎеҜ№дәҶ8ж¬ЎжјҸдәҶдёӨж¬ЎгҖӮ
е«Ңз–‘дәәе®ҡзҪӘ
еҹәдәҺдёҚй”ҷжҖӘдёҖдёӘеҘҪдәәзҡ„еҺҹеҲҷпјҢеҜ№дәҺе«Ңз–‘дәәзҡ„е®ҡзҪӘжҲ‘们еёҢжңӣжҳҜйқһеёёеҮҶзЎ®зҡ„гҖӮеҸҠж—¶жңүж—¶еҖҷж”ҫиҝҮдәҶдёҖдәӣзҪӘзҠҜпјҲrecallдҪҺпјүпјҢдҪҶд№ҹжҳҜеҖјеҫ—зҡ„гҖӮ
гҖҖгҖҖдёҚеҰЁдёҫиҝҷж ·дёҖдёӘдҫӢеӯҗпјҡ
гҖҖгҖҖжҹҗжұ еЎҳжңү1400жқЎйІӨйұјпјҢ300еҸӘиҷҫпјҢ300еҸӘйі–гҖӮзҺ°еңЁд»ҘжҚ•йІӨйұјдёәзӣ®зҡ„гҖӮж’’дёҖеӨ§зҪ‘пјҢйҖ®зқҖдәҶ700жқЎйІӨйұјпјҢ200еҸӘиҷҫпјҢ100еҸӘйі–гҖӮйӮЈд№ҲпјҢиҝҷдәӣжҢҮж ҮеҲҶеҲ«еҰӮдёӢпјҡ
гҖҖгҖҖжӯЈзЎ®зҺҮ = 700 / (700 + 200 + 100) = 70%
гҖҖгҖҖеҸ¬еӣһзҺҮ = 700 / 1400 = 50%
гҖҖгҖҖF1еҖј = 70% * 50% * 2 / (70% + 50%) = 58.3%
гҖҖгҖҖдёҚеҰЁзңӢзңӢеҰӮжһңжҠҠжұ еӯҗйҮҢзҡ„жүҖжңүзҡ„йІӨйұјгҖҒиҷҫе’Ңйі–йғҪдёҖзҪ‘жү“е°ҪпјҢиҝҷдәӣжҢҮж ҮеҸҲжңүдҪ•еҸҳеҢ–пјҡ
гҖҖгҖҖжӯЈзЎ®зҺҮ = 1400 / (1400 + 300 + 300) = 70%
гҖҖгҖҖеҸ¬еӣһзҺҮ = 1400 / 1400 = 100%
гҖҖгҖҖF1еҖј = 70% * 100% * 2 / (70% + 100%) = 82.35%
гҖҖгҖҖз”ұжӯӨеҸҜи§ҒпјҢжӯЈзЎ®зҺҮжҳҜиҜ„дј°жҚ•иҺ·зҡ„жҲҗжһңдёӯзӣ®ж ҮжҲҗжһңжүҖеҚ еҫ—жҜ”дҫӢпјӣеҸ¬еӣһзҺҮпјҢйЎҫеҗҚжҖқд№үпјҢе°ұжҳҜд»Һе…іжіЁйўҶеҹҹдёӯпјҢеҸ¬еӣһзӣ®ж Үзұ»еҲ«зҡ„жҜ”дҫӢпјӣиҖҢFеҖјпјҢеҲҷжҳҜз»јеҗҲиҝҷдәҢиҖ…жҢҮж Үзҡ„иҜ„дј°жҢҮж ҮпјҢз”ЁдәҺз»јеҗҲеҸҚжҳ ж•ҙдҪ“зҡ„жҢҮж ҮгҖӮ
гҖҖгҖҖеҪ“然еёҢжңӣжЈҖзҙўз»“жһңPrecisionи¶Ҡй«ҳи¶ҠеҘҪпјҢеҗҢж—¶Recallд№ҹи¶Ҡй«ҳи¶ҠеҘҪпјҢдҪҶдәӢе®һдёҠиҝҷдёӨиҖ…еңЁжҹҗдәӣжғ…еҶөдёӢжңүзҹӣзӣҫзҡ„гҖӮжҜ”еҰӮжһҒз«Ҝжғ…еҶөдёӢпјҢжҲ‘们еҸӘжҗңзҙўеҮәдәҶдёҖдёӘз»“жһңпјҢдё”жҳҜеҮҶзЎ®зҡ„пјҢйӮЈд№ҲPrecisionе°ұжҳҜ100%пјҢдҪҶжҳҜRecallе°ұеҫҲдҪҺпјӣиҖҢеҰӮжһңжҲ‘们жҠҠжүҖжңүз»“жһңйғҪиҝ”еӣһпјҢйӮЈд№ҲжҜ”еҰӮRecallжҳҜ100%пјҢдҪҶжҳҜPrecisionе°ұдјҡеҫҲдҪҺгҖӮеӣ жӯӨеңЁдёҚеҗҢзҡ„еңәеҗҲдёӯйңҖиҰҒиҮӘе·ұеҲӨж–ӯеёҢжңӣPrecisionжҜ”иҫғй«ҳжҲ–жҳҜRecallжҜ”иҫғй«ҳгҖӮеҰӮжһңжҳҜеҒҡе®һйӘҢз ”з©¶пјҢеҸҜд»Ҙз»ҳеҲ¶Precision-RecallжӣІзәҝжқҘеё®еҠ©еҲҶжһҗгҖӮ
гҖҖгҖҖд»Јз ҒиЎҘе……пјҡ
from sklearn.metrics import precision_score, recall_score, f1_score
# жӯЈзЎ®зҺҮ пјҲжҸҗеҸ–еҮәзҡ„жӯЈзЎ®дҝЎжҒҜжқЎж•° / жҸҗеҸ–еҮәзҡ„дҝЎжҒҜжқЎж•°пјү
print('Precision: %.3f' % precision_score(y_true=y_test, y_pred=y_pred))
# еҸ¬еӣһзҺҮ пјҲжҸҗеҮәеҮәзҡ„жӯЈзЎ®дҝЎжҒҜжқЎж•° / ж ·жң¬дёӯзҡ„дҝЎжҒҜжқЎж•°пјү
print('Recall: %.3f' % recall_score(y_true=y_test, y_pred=y_pred))
# F1-score пјҲжӯЈзЎ®зҺҮ*еҸ¬еӣһзҺҮ*2 /пјҲжӯЈзЎ®зҺҮ+еҸ¬еӣһзҺҮпјүпјү
print('F1: %.3f' % f1_score(y_true=y_test, y_pred=y_pred))гҖҖгҖҖAUCжҳҜдёҖз§ҚжЁЎеһӢеҲҶзұ»жҢҮж ҮпјҢдё”д»…д»…жҳҜдәҢеҲҶзұ»жЁЎеһӢзҡ„иҜ„д»·жҢҮж ҮгҖӮAUCжҳҜArea Under Curveзҡ„з®Җз§°пјҢйӮЈд№ҲCurveе°ұжҳҜROCпјҲReceiver Operating CharacteristicпјүпјҢзҝ»иҜ‘дёә"жҺҘеҸ—иҖ…ж“ҚдҪңзү№жҖ§жӣІзәҝ"гҖӮд№ҹе°ұжҳҜиҜҙROCжҳҜдёҖжқЎжӣІзәҝпјҢAUCжҳҜдёҖдёӘйқўз§ҜеҖјгҖӮ
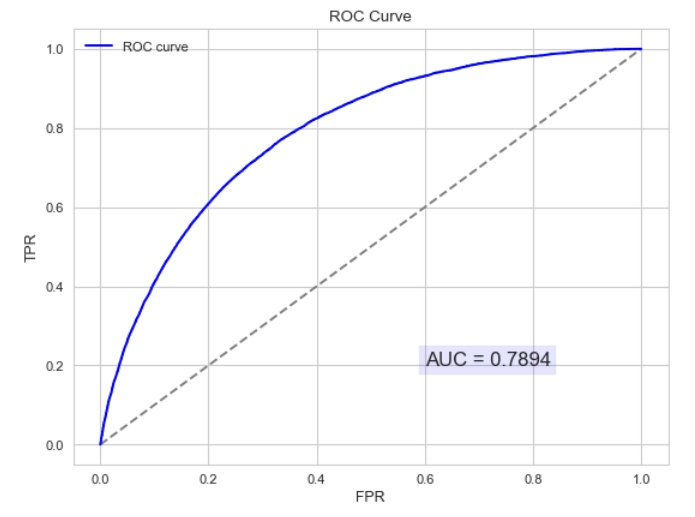
гҖҖгҖҖROCжӣІзәҝеә”иҜҘе°ҪйҮҸеҒҸзҰ»еҸӮиҖғзәҝпјҢи¶Ҡйқ иҝ‘е·ҰдёҠи¶ҠеҘҪ
гҖҖгҖҖAUCпјҡROCжӣІзәҝдёӢйқўз§ҜпјҢеҸӮиҖғзәҝйқўз§Ҝдёә0.5пјҢAUCеә”еӨ§дәҺ0.5пјҢдё”еҒҸзҰ»и¶ҠеӨҡи¶ҠеҘҪ
гҖҖгҖҖMotivation1пјҡеңЁдёҖдёӘдәҢеҲҶзұ»жЁЎеһӢдёӯпјҢеҜ№дәҺжүҖеҫ—еҲ°зҡ„иҝһз»ӯз»“жһңпјҢеҒҮи®ҫе·ІзЎ®е®ҡдёҖдёӘйҳҖеҖјпјҢжҜ”еҰӮиҜҙ 0.6пјҢеӨ§дәҺиҝҷдёӘеҖјзҡ„е®һдҫӢеҲ’еҪ’дёәжӯЈзұ»пјҢе°ҸдәҺиҝҷдёӘеҖјеҲҷеҲ’еҲ°иҙҹзұ»дёӯгҖӮеҰӮжһңеҮҸе°ҸйҳҖеҖјпјҢеҮҸеҲ°0.5пјҢеӣә然иғҪиҜҶеҲ«еҮәжӣҙеӨҡзҡ„жӯЈзұ»пјҢд№ҹе°ұжҳҜжҸҗй«ҳдәҶиҜҶеҲ«еҮәзҡ„жӯЈдҫӢеҚ жүҖжңүжӯЈдҫӢ зҡ„жҜ”зұ»пјҢеҚіTPR,дҪҶеҗҢж—¶д№ҹе°ҶжӣҙеӨҡзҡ„иҙҹе®һдҫӢеҪ“дҪңдәҶжӯЈе®һдҫӢпјҢеҚіжҸҗй«ҳдәҶFPRгҖӮдёәдәҶеҪўиұЎеҢ–иҝҷдёҖеҸҳеҢ–пјҢеј•е…ҘROCпјҢROCжӣІзәҝеҸҜд»Ҙз”ЁдәҺиҜ„д»·дёҖдёӘеҲҶзұ»еҷЁгҖӮ
гҖҖгҖҖMotivation2пјҡеңЁзұ»дёҚе№іиЎЎзҡ„жғ…еҶөдёӢ,еҰӮжӯЈж ·жң¬90дёӘ,иҙҹж ·жң¬10дёӘ,зӣҙжҺҘжҠҠжүҖжңүж ·жң¬еҲҶзұ»дёәжӯЈж ·жң¬,еҫ—еҲ°иҜҶеҲ«зҺҮдёә90%гҖӮдҪҶиҝҷжҳҫ然жҳҜжІЎжңүж„Ҹд№үзҡ„гҖӮеҚ•зәҜж №жҚ®Precisionе’ҢRecallжқҘиЎЎйҮҸз®—жі•зҡ„дјҳеҠЈе·Із»ҸдёҚиғҪиЎЁеҫҒиҝҷз§Қз—…жҖҒй—®йўҳгҖӮ
гҖҖгҖҖз»ҳеҲ¶ROCжӣІзәҝ
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc
# y_testпјҡе®һйҷ…зҡ„ж Үзӯҫ, dataset_predпјҡйў„жөӢзҡ„жҰӮзҺҮеҖјгҖӮ
fpr, tpr, thresholds = roc_curve(y_test, dataset_pred)
roc_auc = auc(fpr, tpr)
#з”»еӣҫпјҢеҸӘйңҖиҰҒplt.plot(fpr,tpr),еҸҳйҮҸroc_aucеҸӘжҳҜи®°еҪ•aucзҡ„еҖјпјҢйҖҡиҝҮauc()еҮҪж•°иғҪи®Ўз®—еҮәжқҘ
plt.plot(fpr, tpr, lw=1, label='ROC(area = %0.2f)' % (roc_auc))
plt.xlabel("FPR (False Positive Rate)")
plt.ylabel("TPR (True Positive Rate)")
plt.title("Receiver Operating Characteristic, ROC(AUC = %0.2f)"% (roc_auc))
plt.show()гҖҖгҖҖROCпјҲReceiver Operating Characteristicпјүзҝ»иҜ‘дёә"жҺҘеҸ—иҖ…ж“ҚдҪңзү№жҖ§жӣІзәҝ"гҖӮжӣІзәҝз”ұдёӨдёӘеҸҳйҮҸ1-specificity е’Ң Sensitivityз»ҳеҲ¶. 1-specificity=FPRпјҢеҚіиҙҹжӯЈзұ»зҺҮгҖӮSensitivityеҚіжҳҜзңҹжӯЈзұ»зҺҮпјҢTPR(True positive rate),еҸҚжҳ дәҶжӯЈзұ»иҰҶзӣ–зЁӢеәҰгҖӮиҝҷдёӘз»„еҗҲд»Ҙ1-specificityеҜ№sensitivity,еҚіжҳҜд»Ҙд»Јд»·(costs)еҜ№ж”¶зӣҠ(benefits)гҖӮжҳҫ然收зӣҠи¶Ҡй«ҳпјҢд»Јд»·и¶ҠдҪҺпјҢжЁЎеһӢзҡ„жҖ§иғҪе°ұи¶ҠеҘҪгҖӮ
жӯӨеӨ–пјҢROCжӣІзәҝиҝҳеҸҜд»Ҙз”ЁжқҘи®Ўз®—вҖңеқҮеҖје№іеқҮзІҫеәҰвҖқпјҲmean average precisionпјүпјҢиҝҷжҳҜеҪ“дҪ йҖҡиҝҮж”№еҸҳйҳҲеҖјжқҘйҖүжӢ©жңҖеҘҪзҡ„з»“жһңж—¶жүҖеҫ—еҲ°зҡ„е№іеқҮзІҫеәҰпјҲPPVпјүгҖӮ
x иҪҙдёәеҒҮйҳіжҖ§зҺҮпјҲFPRпјүпјҡеңЁжүҖжңүзҡ„иҙҹж ·жң¬дёӯпјҢеҲҶзұ»еҷЁйў„жөӢй”ҷиҜҜзҡ„жҜ”дҫӢ

дёәдәҶжӣҙеҘҪең°зҗҶи§ЈROCжӣІзәҝпјҢжҲ‘们дҪҝз”Ёе…·дҪ“зҡ„е®һдҫӢжқҘиҜҙжҳҺпјҡ
гҖҖгҖҖеҰӮеңЁеҢ»еӯҰиҜҠж–ӯдёӯ,еҲӨж–ӯжңүз—…зҡ„ж ·жң¬гҖӮйӮЈд№Ҳе°ҪйҮҸжҠҠжңүз—…зҡ„жҸӘеҮәжқҘжҳҜдё»иҰҒд»»еҠЎ,д№ҹе°ұжҳҜ第дёҖдёӘжҢҮж ҮTPR,иҰҒи¶Ҡй«ҳи¶ҠеҘҪгҖӮиҖҢжҠҠжІЎз—…зҡ„ж ·жң¬иҜҜиҜҠдёәжңүз—…зҡ„,д№ҹе°ұжҳҜ第дәҢдёӘжҢҮж ҮFPR,иҰҒи¶ҠдҪҺи¶ҠеҘҪгҖӮ
гҖҖгҖҖдёҚйҡҫеҸ‘зҺ°,иҝҷдёӨдёӘжҢҮж Үд№Ӣй—ҙжҳҜзӣёдә’еҲ¶зәҰзҡ„гҖӮеҰӮжһңжҹҗдёӘеҢ»з”ҹеҜ№дәҺжңүз—…зҡ„з—ҮзҠ¶жҜ”иҫғж•Ҹж„ҹ,зЁҚеҫ®зҡ„е°Ҹз—ҮзҠ¶йғҪеҲӨж–ӯдёәжңүз—…,йӮЈд№Ҳд»–зҡ„第дёҖдёӘжҢҮж Үеә”иҜҘдјҡеҫҲй«ҳ,дҪҶжҳҜ第дәҢдёӘжҢҮж Үд№ҹе°ұзӣёеә”ең°еҸҳй«ҳгҖӮжңҖжһҒз«Ҝзҡ„жғ…еҶөдёӢ,д»–жҠҠжүҖжңүзҡ„ж ·жң¬йғҪзңӢеҒҡжңүз—…,йӮЈд№Ҳ第дёҖдёӘжҢҮж ҮиҫҫеҲ°1,第дәҢдёӘжҢҮж Үд№ҹдёә1гҖӮ
гҖҖгҖҖжҲ‘们д»ҘFPRдёәжЁӘиҪҙ,TPRдёәзәөиҪҙ,еҫ—еҲ°еҰӮдёӢROCз©әй—ҙгҖӮ
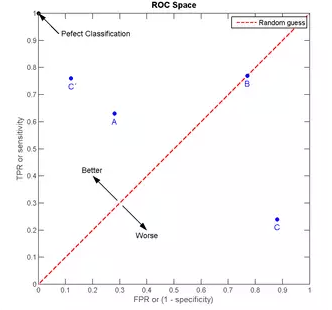
гҖҖ жҲ‘们еҸҜд»ҘзңӢеҮә,е·ҰдёҠи§’зҡ„зӮ№(TPR=1,FPR=0),дёәе®ҢзҫҺеҲҶзұ»,д№ҹе°ұжҳҜиҝҷдёӘеҢ»з”ҹеҢ»жңҜй«ҳжҳҺ,иҜҠж–ӯе…ЁеҜ№гҖӮзӮ№A(TPR>FPR),еҢ»з”ҹAзҡ„еҲӨж–ӯеӨ§дҪ“жҳҜжӯЈзЎ®зҡ„гҖӮдёӯзәҝдёҠзҡ„зӮ№B(TPR=FPR),д№ҹе°ұжҳҜеҢ»з”ҹBе…ЁйғҪжҳҜи’ҷзҡ„,и’ҷеҜ№дёҖеҚҠ,и’ҷй”ҷдёҖеҚҠ;дёӢеҚҠе№ійқўзҡ„зӮ№C(TPR<FPR),иҝҷдёӘеҢ»з”ҹиҜҙдҪ жңүз—…,йӮЈд№ҲдҪ еҫҲеҸҜиғҪжІЎжңүз—…,еҢ»з”ҹCзҡ„иҜқжҲ‘们иҰҒеҸҚзқҖеҗ¬,дёәзңҹеәёеҢ»гҖӮдёҠеӣҫдёӯдёҖдёӘйҳҲеҖј,еҫ—еҲ°дёҖдёӘзӮ№гҖӮзҺ°еңЁжҲ‘们йңҖиҰҒдёҖдёӘзӢ¬з«ӢдәҺйҳҲеҖјзҡ„иҜ„д»·жҢҮж ҮжқҘиЎЎйҮҸиҝҷдёӘеҢ»з”ҹзҡ„еҢ»жңҜеҰӮдҪ•,д№ҹе°ұжҳҜйҒҚеҺҶжүҖжңүзҡ„йҳҲеҖј,еҫ—еҲ°ROCжӣІзәҝгҖӮ
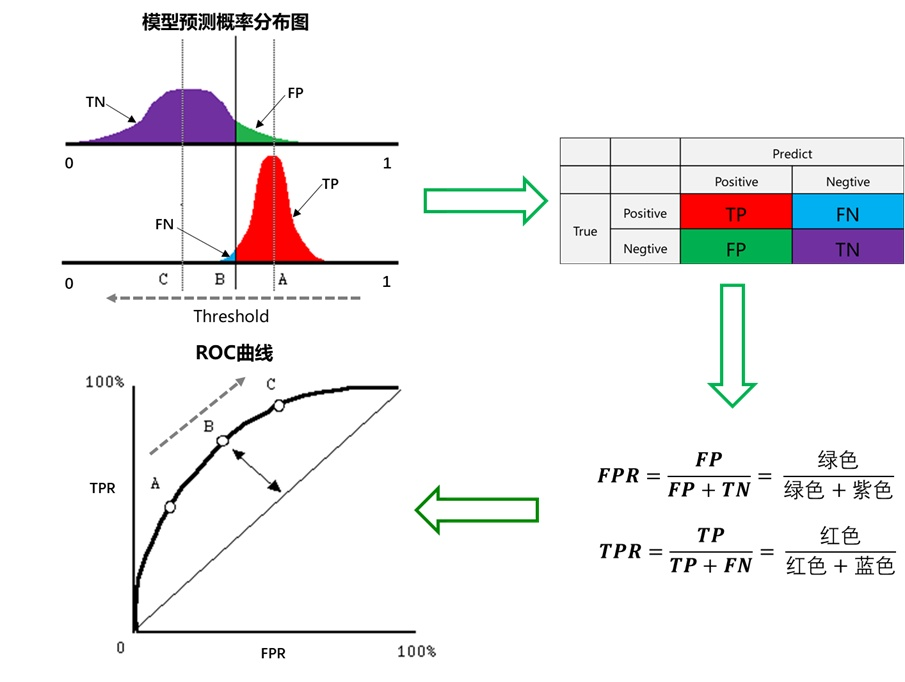
гҖҖгҖҖеҒҮи®ҫдёӢеӣҫжҳҜжҹҗеҢ»з”ҹзҡ„иҜҠж–ӯз»ҹи®ЎеӣҫпјҢдёәжңӘеҫ—з—…дәәзҫӨпјҲдёҠеӣҫпјүе’Ңеҫ—з—…дәәзҫӨпјҲдёӢеӣҫпјүзҡ„жЁЎеһӢиҫ“еҮәжҰӮзҺҮеҲҶеёғеӣҫпјҲжЁӘеқҗж ҮиЎЁзӨәжЁЎеһӢиҫ“еҮәжҰӮзҺҮпјҢзәөеқҗж ҮиЎЁзӨәжҰӮзҺҮеҜ№еә”зҡ„дәәзҫӨзҡ„ж•°йҮҸпјүпјҢжҳҫ然жңӘеҫ—з—…дәәзҫӨзҡ„жҰӮзҺҮеҖјжҷ®йҒҚдҪҺдәҺеҫ—з—…дәәзҫӨзҡ„иҫ“еҮәжҰӮзҺҮеҖјпјҲеҚіжӯЈеёёдәәиҜҠж–ӯеҮәз–ҫз—…зҡ„жҰӮзҺҮе°ҸдәҺеҫ—з—…дәәзҫӨиҜҠж–ӯеҮәз–ҫз—…зҡ„жҰӮзҺҮпјүгҖӮ
гҖҖгҖҖз«–зәҝд»ЈиЎЁйҳҲеҖјгҖӮжҳҫ然пјҢеӣҫдёӯз»ҷеҮәдәҶжҹҗдёӘйҳҲеҖјеҜ№еә”зҡ„ж··ж·Ҷзҹ©йҳөпјҢйҖҡиҝҮж”№еҸҳдёҚеҗҢзҡ„йҳҲеҖј 

иҝҳжҳҜдёҖејҖе§Ӣзҡ„йӮЈе№…еӣҫ,еҒҮи®ҫеҰӮдёӢе°ұжҳҜжҹҗдёӘеҢ»з”ҹзҡ„иҜҠж–ӯз»ҹи®Ўеӣҫ,зӣҙзәҝд»ЈиЎЁйҳҲеҖјгҖӮжҲ‘们йҒҚеҺҶжүҖжңүзҡ„йҳҲеҖј,иғҪеӨҹеңЁROCе№ійқўдёҠеҫ—еҲ°еҰӮдёӢзҡ„ROCжӣІзәҝгҖӮ
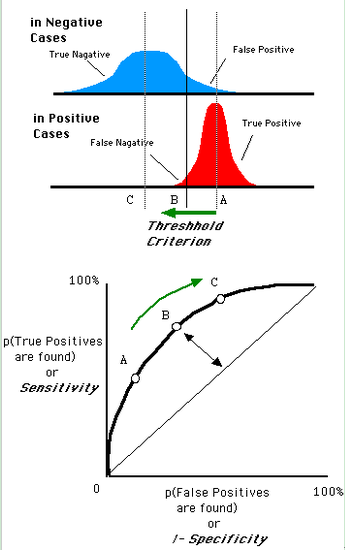
гҖҖгҖҖжӣІзәҝи·қзҰ»е·ҰдёҠи§’и¶Ҡиҝ‘,иҜҒжҳҺеҲҶзұ»еҷЁж•Ҳжһңи¶ҠеҘҪгҖӮ
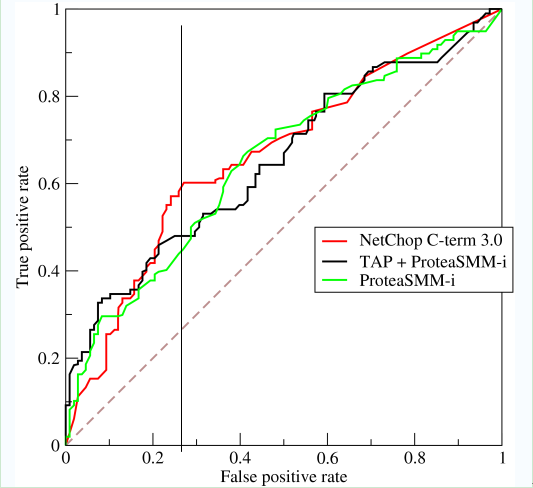
гҖҖгҖҖеҰӮдёҠ,жҳҜдёүжқЎROCжӣІзәҝ,еңЁ0.23еӨ„еҸ–дёҖжқЎзӣҙзәҝгҖӮйӮЈд№Ҳ,еңЁеҗҢж ·зҡ„дҪҺFPR=0.23зҡ„жғ…еҶөдёӢ,зәўиүІеҲҶзұ»еҷЁеҫ—еҲ°жӣҙй«ҳзҡ„PTRгҖӮд№ҹе°ұиЎЁжҳҺ,ROCи¶ҠеҫҖдёҠ,еҲҶзұ»еҷЁж•Ҳжһңи¶ҠеҘҪгҖӮжҲ‘们用дёҖдёӘж ҮйҮҸеҖјAUCжқҘйҮҸеҢ–е®ғгҖӮ
гҖҖгҖҖAUCеҖјдёәROCжӣІзәҝжүҖиҰҶзӣ–зҡ„еҢәеҹҹйқўз§Ҝ,жҳҫ然,AUCи¶ҠеӨ§,еҲҶзұ»еҷЁеҲҶзұ»ж•Ҳжһңи¶ҠеҘҪгҖӮ
гҖҖгҖҖAUC = 1пјҢжҳҜе®ҢзҫҺеҲҶзұ»еҷЁпјҢйҮҮз”ЁиҝҷдёӘйў„жөӢжЁЎеһӢж—¶пјҢдёҚз®Ўи®ҫе®ҡд»Җд№ҲйҳҲеҖјйғҪиғҪеҫ—еҮәе®ҢзҫҺйў„жөӢгҖӮз»қеӨ§еӨҡж•°йў„жөӢзҡ„еңәеҗҲпјҢдёҚеӯҳеңЁе®ҢзҫҺеҲҶзұ»еҷЁгҖӮ
гҖҖгҖҖ0.5 < AUC < 1пјҢдјҳдәҺйҡҸжңәзҢңжөӢгҖӮиҝҷдёӘеҲҶзұ»еҷЁпјҲжЁЎеһӢпјүеҰҘе–„и®ҫе®ҡйҳҲеҖјзҡ„иҜқпјҢиғҪжңүйў„жөӢд»·еҖјгҖӮ
гҖҖгҖҖAUC = 0.5пјҢи·ҹйҡҸжңәзҢңжөӢдёҖж ·пјҲдҫӢпјҡдёўй“ңжқҝпјүпјҢжЁЎеһӢжІЎжңүйў„жөӢд»·еҖјгҖӮ
гҖҖгҖҖAUC < 0.5пјҢжҜ”йҡҸжңәзҢңжөӢиҝҳе·®пјӣдҪҶеҸӘиҰҒжҖ»жҳҜеҸҚйў„жөӢиҖҢиЎҢпјҢе°ұдјҳдәҺйҡҸжңәзҢңжөӢгҖӮ
гҖҖгҖҖд»ҘдёӢдёәROCжӣІзәҝе’ҢAUCеҖјеҫ—е®һдҫӢпјҡ
гҖҖгҖҖAUCзҡ„зү©зҗҶж„Ҹд№үпјҡеҒҮи®ҫеҲҶзұ»еҷЁзҡ„иҫ“еҮәжҳҜж ·жң¬еұһдәҺжӯЈзұ»зҡ„socreпјҲзҪ®дҝЎеәҰпјүпјҢеҲҷAUCзҡ„зү©зҗҶж„Ҹд№үдёәпјҢд»»еҸ–дёҖеҜ№пјҲжӯЈгҖҒиҙҹпјүж ·жң¬пјҢжӯЈж ·жң¬зҡ„scoreеӨ§дәҺиҙҹж ·жң¬зҡ„scoreзҡ„жҰӮзҺҮгҖӮ
гҖҖгҖҖAUCзҡ„зү©зҗҶж„Ҹд№үжӯЈж ·жң¬зҡ„йў„жөӢз»“жһңеӨ§дәҺиҙҹж ·жң¬зҡ„йў„жөӢз»“жһңзҡ„жҰӮзҺҮгҖӮжүҖд»ҘAUCеҸҚеә”зҡ„жҳҜеҲҶзұ»еҷЁеҜ№ж ·жң¬зҡ„жҺ’еәҸиғҪеҠӣгҖӮ
гҖҖгҖҖеҸҰеӨ–еҖјеҫ—жіЁж„Ҹзҡ„жҳҜпјҢAUCеҜ№ж ·жң¬зұ»еҲ«жҳҜеҗҰеқҮ衡并дёҚж•Ҹж„ҹпјҢиҝҷд№ҹжҳҜдёҚеқҮиЎЎж ·жң¬йҖҡеёёз”ЁAUCиҜ„д»·еҲҶзұ»еҷЁжҖ§иғҪзҡ„дёҖдёӘеҺҹеӣ гҖӮ
гҖҖгҖҖдёӢйқўд»ҺдёҖдёӘе°ҸдҫӢеӯҗи§ЈйҮҠAUCзҡ„еҗ«д№үпјҡе°ҸжҳҺдёҖ家еӣӣеҸЈпјҢе°ҸжҳҺ5еІҒпјҢе§җе§җ10еІҒпјҢзҲёзҲё35еІҒпјҢеҰҲеҰҲ33еІҒе»әз«ӢдёҖдёӘйҖ»иҫ‘еӣһеҪ’еҲҶзұ»еҷЁпјҢжқҘйў„жөӢе°ҸжҳҺ家дәәдёәжҲҗе№ҙдәәжҰӮзҺҮпјҢеҒҮи®ҫеҲҶзұ»еҷЁе·Із»ҸеҜ№е°ҸжҳҺзҡ„家дәәеҒҡиҝҮйў„жөӢпјҢеҫ—еҲ°жҜҸдёӘдәәдёәжҲҗдәәзҡ„жҰӮзҺҮгҖӮ
AUCжӣҙеӨҡзҡ„жҳҜе…іжіЁеҜ№и®Ўз®—жҰӮзҺҮзҡ„жҺ’еәҸпјҢе…іжіЁзҡ„жҳҜжҰӮзҺҮеҖјзҡ„зӣёеҜ№еӨ§е°ҸпјҢдёҺйҳҲеҖје’ҢжҰӮзҺҮеҖјзҡ„з»қеҜ№еӨ§е°ҸжІЎжңүе…ізі»
гҖҖгҖҖдҫӢеӯҗдёӯ并дёҚе…іжіЁе°ҸжҳҺжҳҜдёҚжҳҜжҲҗдәәпјҢиҖҢе…іжіЁзҡ„жҳҜпјҢйў„жөӢдёәжҲҗдәәзҡ„жҰӮзҺҮзҡ„жҺ’еәҸгҖӮ
гҖҖгҖҖ第дёҖз§Қж–№жі•:AUCдёәROCжӣІзәҝдёӢзҡ„йқўз§Ҝ,йӮЈжҲ‘们зӣҙжҺҘи®Ўз®—йқўз§ҜеҸҜеҫ—гҖӮйқўз§ҜдёәдёҖдёӘдёӘе°Ҹзҡ„жўҜеҪўйқўз§Ҝд№Ӣе’ҢгҖӮи®Ўз®—зҡ„зІҫеәҰдёҺйҳҲеҖјзҡ„зІҫеәҰжңүе…ігҖӮ
гҖҖгҖҖ第дәҢз§Қж–№жі•:ж №жҚ®AUCзҡ„зү©зҗҶж„Ҹд№ү,жҲ‘们计算жӯЈж ·жң¬scoreеӨ§дәҺиҙҹж ·жң¬зҡ„scoreзҡ„жҰӮзҺҮгҖӮеҸ–N*M(NдёәжӯЈж ·жң¬ж•°,Mдёәиҙҹж ·жң¬ж•°)дёӘдәҢе…ғз»„,жҜ”иҫғscore,жңҖеҗҺеҫ—еҲ°AUCгҖӮж—¶й—ҙеӨҚжқӮеәҰдёәO(N*M)гҖӮ
гҖҖгҖҖ第дёүз§Қж–№жі•:дёҺ第дәҢз§Қж–№жі•зӣёдјј,зӣҙжҺҘи®Ўз®—жӯЈж ·жң¬scoreеӨ§дәҺиҙҹж ·жң¬зҡ„жҰӮзҺҮгҖӮжҲ‘们йҰ–е…ҲжҠҠжүҖжңүж ·жң¬жҢүз…§scoreжҺ’еәҸ,дҫқж¬Ўз”ЁrankиЎЁзӨә他们,еҰӮжңҖеӨ§scoreзҡ„ж ·жң¬,rank=n(n=N+M),е…¶ж¬Ўдёәn-1гҖӮйӮЈд№ҲеҜ№дәҺжӯЈж ·жң¬дёӯrankжңҖеӨ§зҡ„ж ·жң¬,rank_max,жңүM-1дёӘе…¶д»–жӯЈж ·жң¬жҜ”д»–scoreе°Ҹ,йӮЈд№Ҳе°ұжңү(rank_max-1)-(M-1)дёӘиҙҹж ·жң¬жҜ”д»–scoreе°ҸгҖӮе…¶ж¬Ўдёә(rank_second-1)-(M-2)гҖӮжңҖеҗҺжҲ‘们еҫ—еҲ°жӯЈж ·жң¬еӨ§дәҺиҙҹж ·жң¬зҡ„жҰӮзҺҮдёә

ж—¶й—ҙеӨҚжқӮеәҰдёәO(N+M)гҖӮ
from sklearn.metrics import roc_auc_score # y_testпјҡе®һйҷ…зҡ„ж Үзӯҫ, dataset_predпјҡйў„жөӢзҡ„жҰӮзҺҮеҖјгҖӮ roc_auc_score(y_test, dataset_pred)
вҖңClassificationз®—жі•жҢҮж ҮжҳҜд»Җд№ҲвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ