您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章将为大家详细讲解有关TKE容器网络中的ARP Overflow问题探究及其解决方法是什么,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
最近,某内部客户的 TKE VPC-CNI 模式的独立网卡集群上出现了 pod 间访问不通的情况,问题 pod ping 不通任何其他 pod 和节点。
查看 dmesg 内核日志,有如下报错信息:neighbour: arp_cache: neighbor table overflow!(下图为后续复现的日志截图)
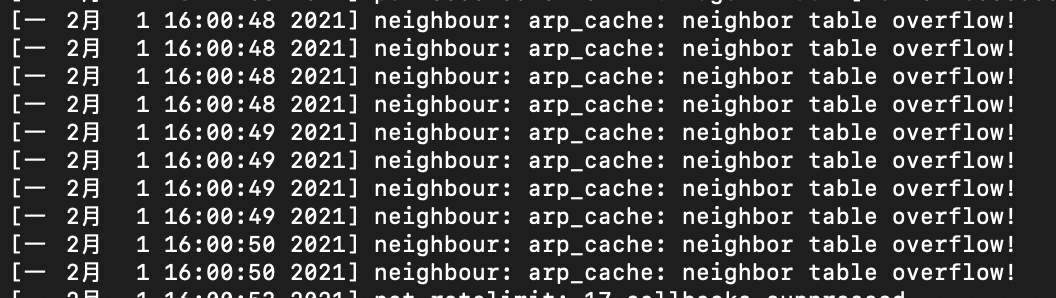
并且,这个集群规模较大,约有 1000 个节点,30000 个 pod,基本可以怀疑是由于集群规模较大,导致 ARP 表项过多,从而引起 ARP Overflow 的问题。
| 名词 | 说明 |
|---|---|
| TKE | 全称 Tencent Kubernetes Engine, 腾讯云容器服务,是基于原生 kubernetes 提供以容器为核心的、高度可扩展的高性能容器管理服务 |
| VPC-CNI 模式 | 是容器服务 TKE 基于 CNI 和 VPC 弹性网卡实现的容器网络能力 |
| Pod | Pod 是 kubernetes 的基本资源管理单位,拥有独立的网络命名空间,1个 Pod 可包含多个容器 |
从如上报错信息可知,这个问题的基本原因在于 ARP 缓存表打满了。这里涉及到内核的 ARP 缓存垃圾回收机制。当 ARP 表项太多且又没有可回收的表项的时候,新表项就会无法插入。
这就导致网络包发送时无法找到对应的硬件地址(MAC)。使得网络包不能发送。
那么具体什么情况会导致新表项无法插入呢?回答这个问题,我们需要先深入了解一下 ARP 缓存老化及垃圾回收机制。
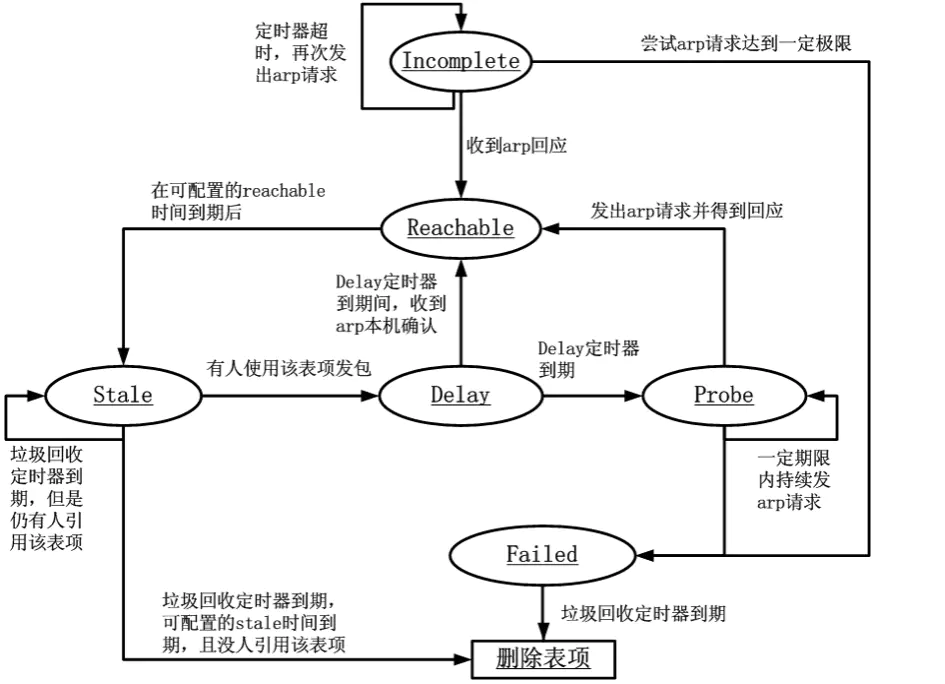
如上图,是整个 ARP 表项的生命周期及其状态机。
我们知道,对于 TCP/IP 网络包发送时,网络栈需要对端的 MAC 地址才能让网络包转换成二层的数据结构——帧,从而在网络中传输。而对于不同广播域的 IP 地址,其对端 MAC 地址为网关,发送端会将网络包发给网关让其转发,而对于同广播域中的 IP 地址,其对端 MAC 地址即与 IP 地址对应。
而通过 IP 地址找到 MAC 地址就是 ARP 协议的主要工作内容。ARP 协议的工作过程此处不再赘述,而通过 ARP 协议找到 IP 地址对应的 MAC 地址后,会将该对应关系存储在本机上一段时间,以减少 ARP 协议的通信频率,加快网络包的发送。该对应关系,即 ARP 缓存表项,其状态机或整个生命周期可描述如下:
初始时,对于任何网络包发送时,内核协议栈需要找到目的 IP 地址对应的对端 MAC 地址,如果这时 ARP 缓存中没有命中,则会新插入一条状态为 Incomplete 的表项。Incomplete 状态会尝试发送 ARP 包,请求某 IP 地址对应的 MAC 地址。
若收到 ARP 回应的,表项状态就变为 Reachable。
若尝试了一定次数后没收到响应,表项即变为 Failed。
Reachable 表项在到达超时时间后,会变成 Stale 状态,Stale 状态的表项已不可再使用。
Stale 的表项若有被引用来发包,则表项会变为 Delay 状态。
Delay 状态的表项也不可使用来发包,但在 Delay 状态到期前,收到 ARP 的本机确认,则重新转为 Reachable 状态。
Delay 状态到期,表项变为 Probe 状态,该状态与 Incomplete 状态类似。
Stale 状态到期后,会被启动的垃圾回收起回收删除。
通过以下命令可查看当前网络命名空间(network namespace) 中 arp 表项及其状态:
ip neigh
如:
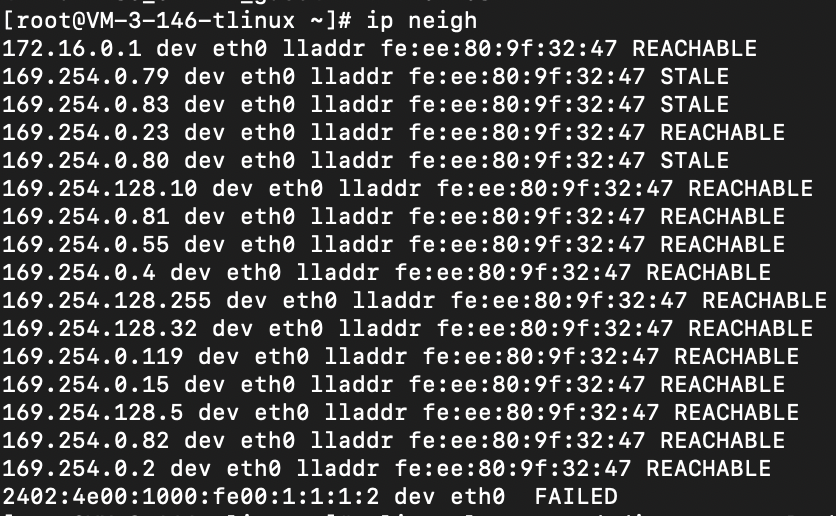
本机确认:这是代指本机收到了一个源 mac 地址匹配的网络包,这个网络包表示此次网络通信的“上一跳”即是该 mac 地址的机器,能收到这个网络包即说明该 mac 地址可达。因此即可把该表项转为 Reachable 状态。通过这一机制,内核可减少 ARP 的通信需求。
以下列出了该机制中主要涉及的内核参数:
| 参数 | 含义 | 默认值 |
|---|---|---|
| /proc/sys/net/ipv4/neigh/default/base_reachable_time | Reachable 状态基础过期时间,每个表项过期时间是在[1/2base_reachable_time,3/2base_reachable_time]之间 | 30秒 |
| /proc/sys/net/ipv4/neigh/default/base_reachable_time_ms | Reachable 状态基础过期时间,毫秒表示 | 30秒 |
| /proc/sys/net/ipv4/neigh/default/gc_stale_time | Stale 状态过期时间 | 60秒 |
| /proc/sys/net/ipv4/neigh/default/delay_first_probe_time | delay 状态过期到 Probe 的时间 | 5秒 |
| /proc/sys/net/ipv4/neigh/default/gc_interval | gc 启动的周期时间 | 30秒 |
| /proc/sys/net/ipv4/neigh/default/gc_thresh2 | 少于这个值,gc 不会启动 | 2048 |
| /proc/sys/net/ipv4/neigh/default/gc_thresh3 | ARP表的最多纪录的软限制,允许超过该数字5秒 | 4096 |
| /proc/sys/net/ipv4/neigh/default/gc_thresh4 | ARP表的最多纪录的硬限制,大于该数目,gc立即启动,并强制回收 | 8192 |
其中,gc 相关的内核参数是对**所有网卡(interface)**生效的。但是各种到期时间的设置是仅对单独网卡(interface)生效的,default 值仅对新增接口设备生效。
由其缓存表项的状态机我们知道,不是所有的表项都会被回收,只有 Stale 状态过期后,Failed 的表项可能会被回收。另外,ARP 缓存表项的垃圾回收是触发式的,需要回收的表项不一定立刻会被回收,ARP 缓存表项的垃圾回收有四种启动逻辑:
arp 表项数量 < gc_thresh2,不启动。
gc_thresh2 =< arp 表项数量 <= gc_thresh3,按照 gc_interval 定期启动
gc_thresh3 < arp 表项数量 <= gc_thresh4,5秒后启动
arp 表项数量 > gc_thresh4,立即启动
对于不可回收的表项,垃圾回收即便启动了也不会对其进行回收。因此当不可回收的表项数量大于 gc_thresh4 的时候,垃圾回收也无能为力了。
我们知道,每个独立的网络命名空间是有完整的网络协议栈的。那么,ARP 缓存的垃圾回收也是每个命名空间单独处理的吗?
从涉及的内核参数可以看出,gc 相关的内核参数是对所有接口设备生效的,因此,这里可以推测垃圾回收的阈值也是子机级别生效的,而不是按网络命名空间。
这里做了一个简单的实验来验证:
在节点 default ns 上的 gc_thresh2, gc_thresh3 和 gc_thresh4 设置成60 。
在节点上创建了 19 个独立网卡模式的 Pod
任意选择一个 pod ping 其他的 pod,以此产生 arp 缓存
用 shell 脚本扫描节点上的所有 pod,计算 arp 表项的和,可以得到:
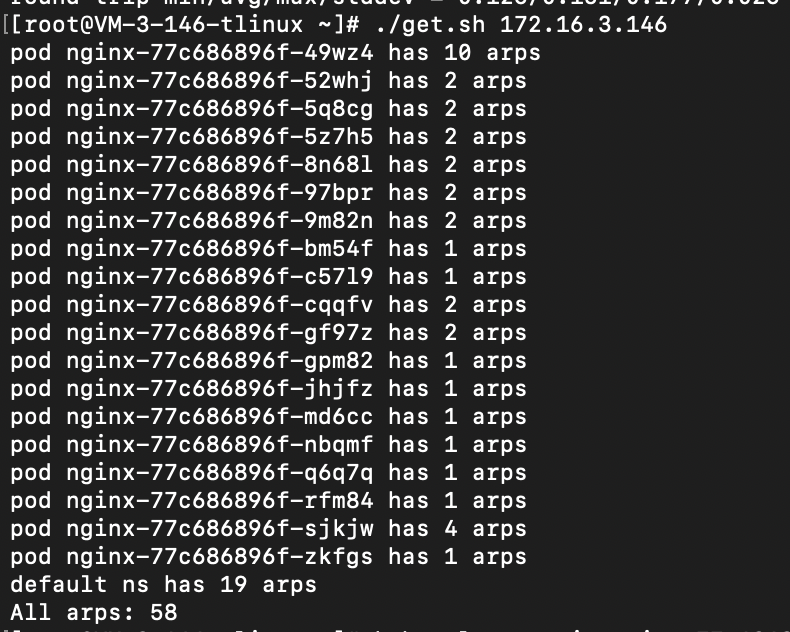
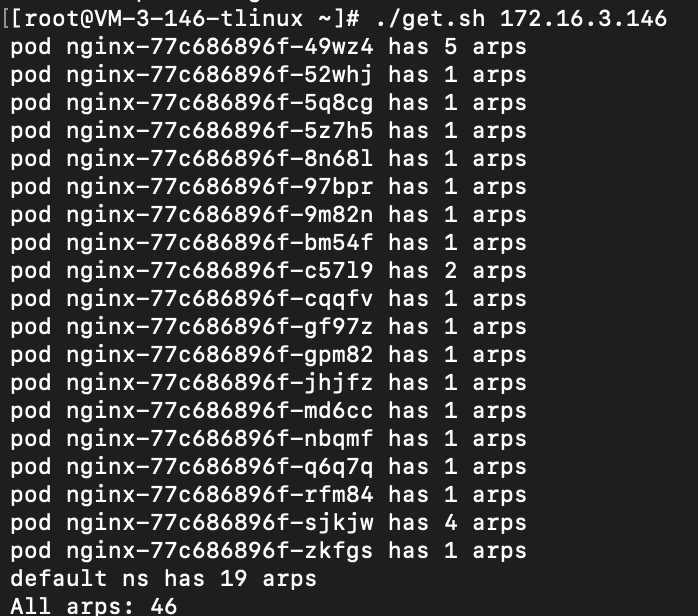
可以发现, 各命名空间的累计 arp 表项的数目在每次达到 60 之后就会快速下降,也就是达到 60 之后就产生了垃圾回收。重复几次都是类似的结果,因此,这说明了垃圾回收在计算 ARP 表项是否触发阈值时,是计算各命名空间的累计值,也就是按子机级别生效,而非命名空间级别。
由前面的介绍我们知道,垃圾回收机制并非回收任意 ARP 缓存,因此,当所有可达状态的 ARP 表项打满 ARP 缓存表时,也即达到 gc_thresh4 时,会发生什么行为?可以推测,此时旧的无法回收,新的 ARP 表项也无法插入,新的网络包会无法发送,也即发生了本次文章所描述的问题。
为了验证这一点,继续在以上环境中实验:
将任意两个 Pod 的基础老化时间 base_reachable_time 调长到 1800秒,以此产生不可回收的 ARP 表项。
设置 gc_thresh4 为 40,以此更容易触发问题
选择调整了老化时间的 pod ping 其他的 pod,以此产生 arp 缓存。
可以发现,当到达阈值的时候,ping 会产生丢包或不通:
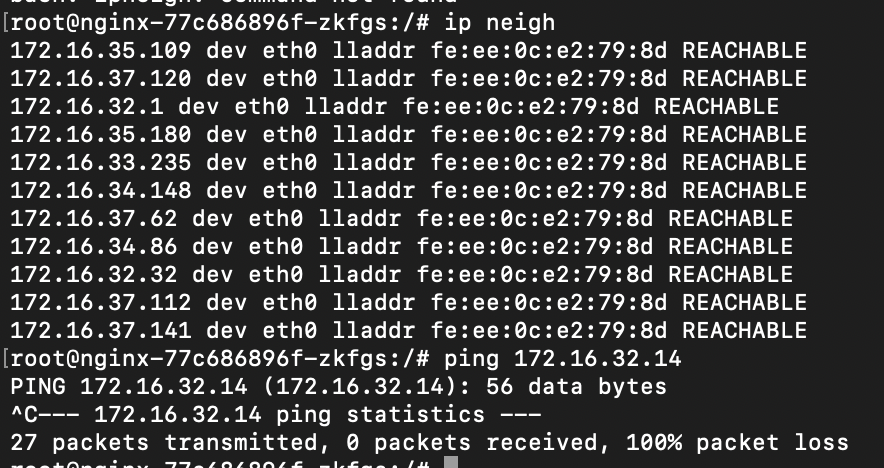
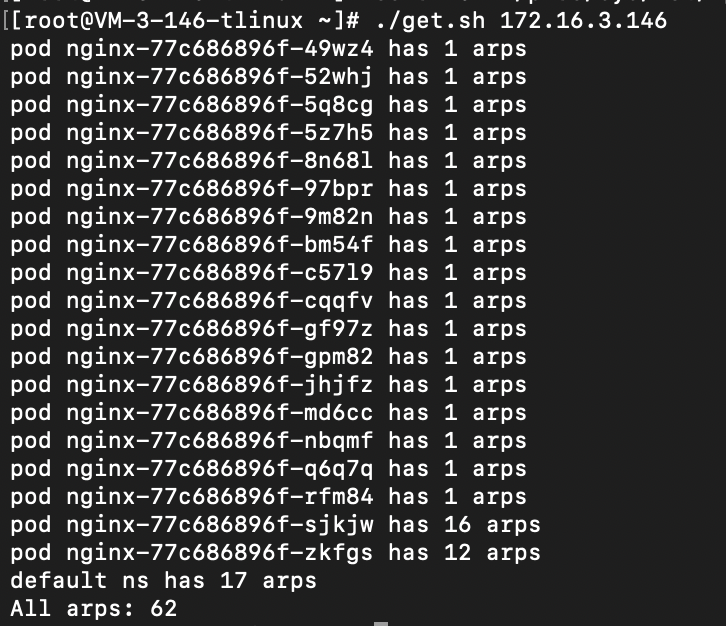
查看内核日志 dmesg -T,可以看到文章开头描述的信息:neighbour: arp_cache: neighbor table overflow!
以上实验说明了,不可回收的 ARP 表项打满 ARP 表会让新的表项无法插入,从而网络不通。
要回答这个问题,我们先简单看一下 TKE 各网络模式的原理介绍
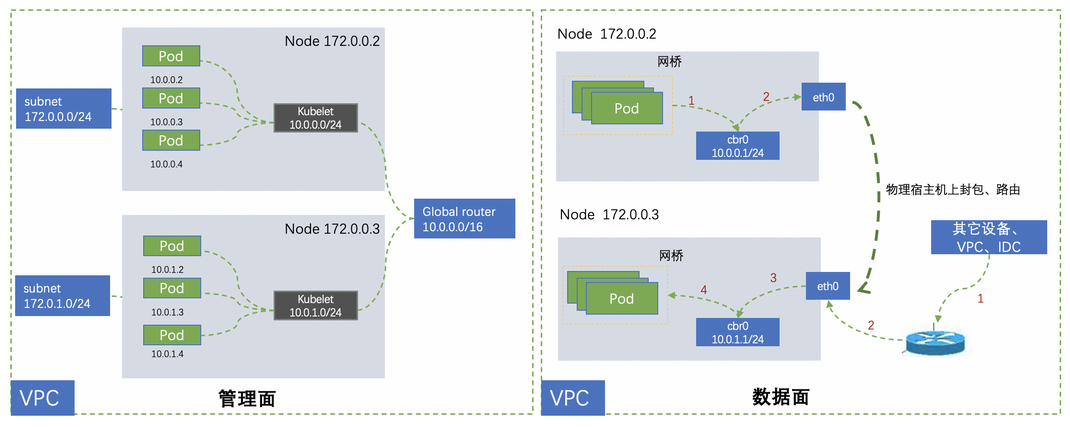
该网络模式下,每个节点上的容器 IP 是预先分配到节点上的,这些 IP 同属一个子网,且每个节点就是一个小子网。我们知道,ARP 协议是为二层通信服务的,因此,该网络方案中,每个 Pod 的网络命名空间内的 ARP 表最大可能保存了节点上所有其他 Pod 的 ARP 表项,最后节点的 ARP 表项的数量最大即为 节点子网 IP 数的平方,如节点的子网大小是128,则其 ARP 表项最大可能为 127 的平方,约 16000。
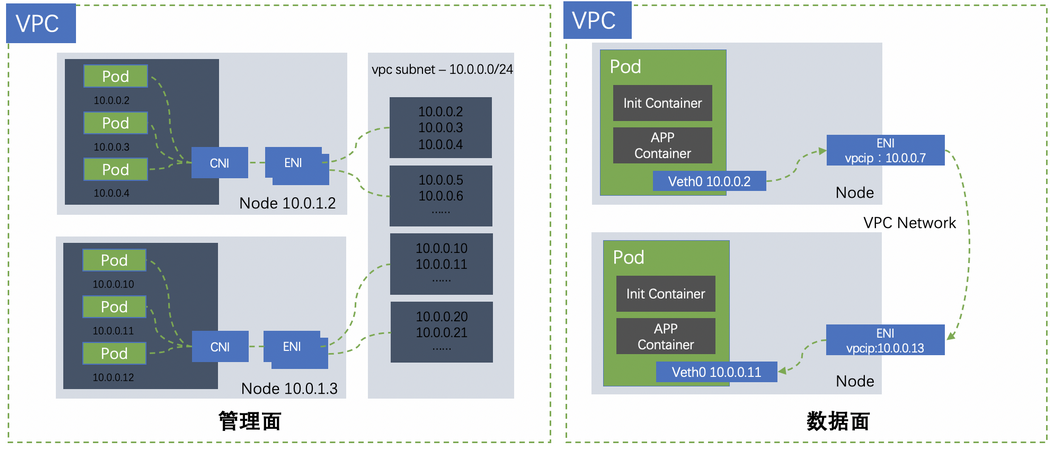
该网络模式下,每个节点会绑定辅助弹性网卡,节点上的 Pod 共享使用该辅助网卡,每个 Pod 内不会做网络包的路由,只会有一条 ARP 表项,实际的路由控制在节点的 default 命名空间内完成。因此,该网络模式下,ARP 缓存表几乎是共享的,又因为网卡只能属于 1 个子网,因此每个节点的 Pod ARP 缓存表只能存储一个子网的 IP-MAC 映射关系,至多数量为各网卡所在子网内 IP 的数量和,如子网是 /22,即含有约 1000 个 ip, 那么 arp 表项也大概有 1000,由于节点网卡配额一般不超过 10,因此该节点的最大 ARP 表项一般不超过 10000。

独立网卡模式是 TKE 团队推出的下一代“零损耗”容器网络方案,其基本原理如下图所示:
即母机虚拟出的弹性网卡,直接置于容器中,使容器获得与 CVM 子机一样的网络通信能力和网络管理能力,大大提升了容器网络的数据面能力,真正做到“零损耗”。
目前,独立网卡网络方案已在 TKE 产品中开放白名单测试,欢迎内外部客户体验试用。
以上网络方案中,每个 Pod 都会独占一个网卡,也会拥有独立的命名空间和独立的 ARP 缓存表。而每个网卡都可以属于不同的子网。因此,在独立网卡模式里,ARP 缓存表项数量至多为同可用区的子网 IP 数量之和。这一数量量级是可以很轻易上万的,很容易就突破了默认的 ARP 缓存设置。也就触发了这个问题。
从以上的分析可以看出,这个问题,调大垃圾回收的阈值,可以比较好的解决问题。因此,临时的解决方案,就是调大 ARP 缓存表的垃圾回收阈值:
echo 8192 > /proc/sys/net/ipv4/neigh/default/gc_thresh2echo 16384 > /proc/sys/net/ipv4/neigh/default/gc_thresh3echo 32768 > /proc/sys/net/ipv4/neigh/default/gc_thresh4
ARP 缓存打满之后,Pod 就会网络不通。初看起来很简单,但是其背后的 ARP 缓存老化和垃圾回收机制也是比较复杂的。查询了很多资料,但是都对“垃圾回收阈值是对各命名空间的 ARP 表项累积值生效还是单独生效”,“垃圾回收会回收哪些表项”,“表项打满后的具体行为如何”等问题说不清、道不明。因此,笔者尝试通过几个小实验验证了具体的行为模式。相比直接阅读晦涩的内核源码,实验法也许也是一个研究问题和理解机制的捷径了。希望能够帮助到各位读者。
关于TKE容器网络中的ARP Overflow问题探究及其解决方法是什么就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。