您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
朴素贝叶斯分类器是基于贝叶斯理论中属性独立假设而创造的一种算法。算法思路简单:只要是哪个类的后验概率大待测样本即为该类别。所谓后验概率就是在给定条件发生的情况下,该样本被判定为某个类别的概率。后验概率P(Y|X)表示在属性集合X(X1,X2,...,Xn)发生的条件下Y类别发生的概率,所以只要计算这个概率就行了,问题的关键在于这个概率该怎么求?
下面贝叶斯告诉了我们一种方法来求这个概率:
P(Y|X) = P(X|Y)P(Y)/P(X),我们称P(X|Y)为类条件概率密度,P(Y)为先验概率。假设待测分类问题是个二分问题两个类别分别为Y1、Y2。所以我们要做的就是求出P(Y1|X)和P(Y2|X)的大小,如果P(Y1|X)>P(Y2|X)则样本被判为类别Y1,反之亦然。从上面的分析中我们知道P(Y|X)可以利用贝叶斯公式进行转化,而且对于不同的类分母P(X)都是相同的,即只需要比较P(X|Y)P(Y)大小就可以了。
现在我们需要求两个值:1、P(X|Y) 2、P(Y)
P(X|Y)的求解依赖一个假设,即假设属性之间条件独立。用公式表示为:P(X|Y1) =∏P(Xi|Y=Y1) (i = 1,2,...,n)。
P(Y),可以用数据表中的数据直接得到。
举个列子:

有了上面这些表格我们就可以很方便的计算某个待测样本的后验概率了,比如给定一个样本X = (有房=否,婚姻状况=已婚,年收入=120),判定该样本属于哪个类?
有上面的分析我们只需计算两个概率P(No|X)和P(Yes|X):
P(No|X)= P(有房=No) * P(婚姻=已婚|No)* P(年收入=120) = 4/7 * 4/7 * 0.0072 = 0.0024
P (Yes|X) = P(有房=Yes) * P(婚姻=已婚|Yes)* P(年收入=120) = 1 * 0 * 1.2*10e(-9) = 0
因为P(No|X) > P (Yes|X),所以判定样本属于类No。
但是上述计算过程中有两个问题:
1、对于零次出现的属性它的概率怎么处理,因为如果这个属性集合如(婚姻=已婚|Yes)没有出现所以导致任何出现包含该集合的属性集的后验概率一律为零,显然这是不合理的。
2、对于属性集中的连续属性如何求它的概率(如上面的年收入)?
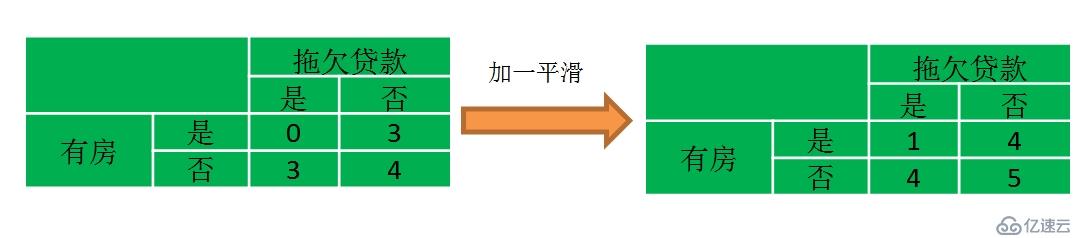
对第一个问题我们采用拉普拉斯平滑(也称加一平滑)方法,也即对每个属性组合的频数都加一之后再求他的概率,如下所示
对第二个问题我们可以用分布估计的方法来处理,如上对于年收入属性我们可以假设它符合高斯分布,我么可以用如下的公式估计参数:
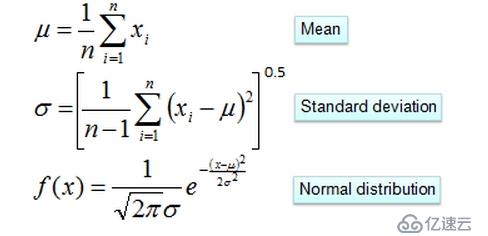
得到最后一个公式之后就可以计算相应给定样本的概率了。
朴素贝叶斯分类器的特点:
1、抗干扰能力强,对鼓励的噪声点健壮,因为它在求概率的过程中将噪声平均化;
2、面对无关属性,分类器健壮,因为类条件概率不会对后验概率计算产生影响;
3、相关属性会降低分类器性能,因为条件独立假设此时不成
需要总结的大概就是这么多,欢迎批评指正!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。