жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
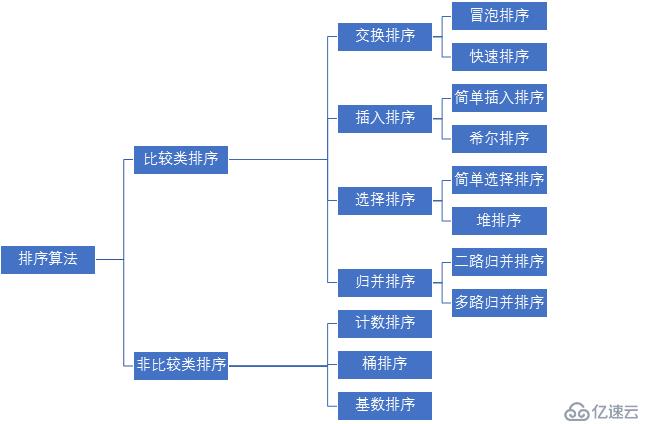
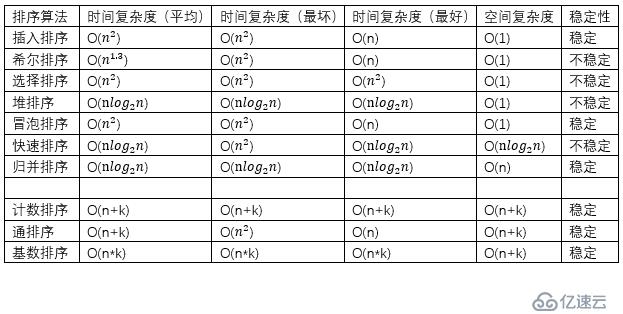
иҝҷйҮҢиҜҰз»Ҷи®Іи§ЈдәҶеҚҒеӨ§з»Ҹе…ёз®—жі•зҡ„еҲҶзұ»пјҢдҫӢеҰӮдәӨжҚўжҺ’еәҸгҖҒжҸ’е…ҘжҺ’еәҸгҖҒйҖүжӢ©жҺ’еәҸзӯүжҜ”иҫғзұ»жҺ’еәҸпјҢд»ҘеҸҠи®Ўж•°жҺ’еәҸгҖҒжЎ¶жҺ’еәҸе’Ңеҹәж•°жҺ’еәҸзҡ„йқһжҜ”иҫғзұ»жҺ’еәҸпјҢеҲҶжһҗдәҶеҗ„з§ҚжҺ’еәҸз®—жі•зҡ„еӨҚжқӮеәҰе’ҢзЁіе®ҡжҖ§пјҢиҝҳжңүJAVAд»Јз Ғзҡ„иҜҰз»Ҷе®һзҺ°гҖӮеҜ№еҶ’жіЎжҺ’еәҸгҖҒжҸ’е…ҘжҺ’еәҸгҖҒйҖүжӢ©жҺ’еәҸе’Ңе ҶжҺ’еәҸзӯүеҚҒз§Қз®—жі•иҝӣиЎҢдәҶиҜҰз»Ҷзҡ„жҖқжғіжҖ»з»“гҖӮ
еҚҒз§Қеёёи§ҒжҺ’еәҸз®—жі•еҸҜд»ҘеҲҶдёәдёӨеӨ§зұ»пјҡ
пјҲ1пјүжҜ”иҫғзұ»жҺ’еәҸпјҡйҖҡиҝҮжҜ”иҫғжқҘеҶіе®ҡе…ғзҙ й—ҙзҡ„зӣёеҜ№ж¬ЎеәҸпјҢз”ұдәҺе…¶ж—¶й—ҙеӨҚжқӮеәҰдёҚиғҪзӘҒз ҙO(nlogn)еӣ жӯӨд№ҹз§°дёәйқһзәҝжҖ§ж—¶й—ҙжҜ”иҫғзұ»жҺ’еәҸгҖӮ
пјҲ2пјүйқһжҜ”иҫғзұ»жҺ’еәҸпјҡдёҚйҖҡиҝҮжҜ”иҫғе…ғзҙ й—ҙзҡ„зӣёеҜ№ж¬ЎеәҸпјҢе®ғеҸҜд»ҘзӘҒз ҙеҹәдәҺжҜ”иҫғжҺ’еәҸзҡ„ж—¶й—ҙдёӢз•ҢпјҢд»ҘзәҝжҖ§ж—¶й—ҙиҝҗиЎҢпјҢеӣ жӯӨд№ҹз§°дёәзәҝжҖ§ж—¶й—ҙйқһжҜ”иҫғзұ»жҺ’еәҸгҖӮ
еҰӮжһңaеҺҹжң¬еңЁbеүҚйқўпјҢиҖҢa=bпјҢжҺ’еәҸд№ӢеҗҺaд»Қ然еңЁbзҡ„еүҚйқўгҖӮ
еҰӮжһңaеҺҹжң¬еңЁbзҡ„еүҚйқўпјҢиҖҢa=bпјҢжҺ’еәҸд№ӢеҗҺ a еҸҜиғҪдјҡеҮәзҺ°еңЁ b зҡ„еҗҺйқўгҖӮ
еҜ№жҺ’еәҸж•°жҚ®зҡ„жҖ»зҡ„ж“ҚдҪңж¬Ўж•°гҖӮеҸҚжҳ еҪ“nеҸҳеҢ–ж—¶пјҢж“ҚдҪңж¬Ўж•°е‘ҲзҺ°д»Җд№Ҳ规еҫӢгҖӮ
жҳҜжҢҮз®—жі•еңЁи®Ўз®—жңәеҶ…жү§иЎҢж—¶жүҖйңҖеӯҳеӮЁз©әй—ҙзҡ„еәҰйҮҸпјҢе®ғд№ҹжҳҜж•°жҚ®и§„жЁЎnзҡ„еҮҪж•°гҖӮ
еҶ’жіЎжҺ’еәҸжҳҜдёҖз§Қз®ҖеҚ•зҡ„жҺ’еәҸз®—жі•гҖӮе®ғйҮҚеӨҚең°иө°и®ҝиҝҮиҰҒжҺ’еәҸзҡ„ж•°еҲ—пјҢдёҖж¬ЎжҜ”иҫғдёӨдёӘе…ғзҙ пјҢеҰӮжһңе®ғ们зҡ„йЎәеәҸй”ҷиҜҜе°ұжҠҠе®ғ们дәӨжҚўиҝҮжқҘгҖӮиө°и®ҝж•°еҲ—зҡ„е·ҘдҪңжҳҜйҮҚеӨҚең°иҝӣиЎҢзӣҙеҲ°жІЎжңүеҶҚйңҖиҰҒдәӨжҚўпјҢд№ҹе°ұжҳҜиҜҙиҜҘж•°еҲ—е·Із»ҸжҺ’еәҸе®ҢжҲҗгҖӮиҝҷдёӘз®—жі•зҡ„еҗҚеӯ—з”ұжқҘжҳҜеӣ дёәи¶Ҡе°Ҹзҡ„е…ғзҙ дјҡз»Ҹз”ұдәӨжҚўж…ўж…ўвҖңжө®вҖқеҲ°ж•°еҲ—зҡ„йЎ¶з«ҜгҖӮ
пјҲ1пјүжҜ”иҫғзӣёйӮ»зҡ„е…ғзҙ гҖӮеҰӮжһң第дёҖдёӘжҜ”第дәҢдёӘеӨ§пјҢе°ұдәӨжҚўе®ғ们дёӨдёӘпјӣ
пјҲ2пјүеҜ№жҜҸдёҖеҜ№зӣёйӮ»е…ғзҙ дҪңеҗҢж ·зҡ„е·ҘдҪңпјҢд»ҺејҖе§Ӣ第дёҖеҜ№еҲ°з»“е°ҫзҡ„жңҖеҗҺдёҖеҜ№пјҢиҝҷж ·еңЁжңҖеҗҺзҡ„е…ғзҙ еә”иҜҘдјҡжҳҜжңҖеӨ§зҡ„ж•°пјӣ
пјҲ3пјүй’ҲеҜ№жүҖжңүзҡ„е…ғзҙ йҮҚеӨҚд»ҘдёҠзҡ„жӯҘйӘӨпјҢйҷӨдәҶжңҖеҗҺдёҖдёӘпјӣ
пјҲ4пјүйҮҚеӨҚжӯҘйӘӨ1~3пјҢзӣҙеҲ°жҺ’еәҸе®ҢжҲҗгҖӮ
// дёҖиҲ¬зҡ„еҶ’жіЎжҺ’еәҸ
public static void BubbleSort(int[] arr){
int temp; //дёҙж—¶еҸҳйҮҸ
for (int i = arr.length-1;i > 0 ; i--){ // иЎЁзӨәи¶ҹж•°пјҢдёҖе…ұarr.length-1ж¬Ў
for (int j = 0;j < i; j++){ // иЎЁзӨәжҜ”иҫғж¬Ўж•°,д»ҺеҗҺеҫҖеүҚпјҢжҜҸи¶ҹжҜ”иҫғжҠҠжңҖеӨ§зҡ„еҶ’еҲ°жңҖеҗҺйқў
System.out.println("第"+(arr.length-i)+"и¶ҹ"+ "第"+(j+1)+"ж¬ЎжҜ”иҫғ"+Arrays.toString(arr));
if(arr[j] > arr[j+1]){
temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
}
}й’ҲеҜ№й—®йўҳпјҡж•°жҚ®зҡ„йЎәеәҸжҺ’еҘҪд№ӢеҗҺпјҢеҶ’жіЎз®—жі•д»Қ然дјҡ继з»ӯиҝӣиЎҢдёӢдёҖиҪ®зҡ„жҜ”иҫғпјҢзӣҙеҲ°arr.length-1ж¬ЎпјҢеҗҺйқўзҡ„жҜ”иҫғжІЎжңүж„Ҹд№үзҡ„гҖӮ
ж”№иҝӣж–№жЎҲпјҡи®ҫзҪ®ж Үеҝ—дҪҚflagпјҢеҰӮжһңеҸ‘з”ҹдәҶдәӨжҚўflagи®ҫзҪ®дёәtrueпјӣеҰӮжһңжІЎжңүдәӨжҚўе°ұи®ҫзҪ®дёәfalseгҖӮиҝҷж ·еҪ“дёҖиҪ®жҜ”иҫғз»“жқҹеҗҺеҰӮжһңflagд»ҚдёәfalseпјҢеҚіпјҡиҝҷдёҖиҪ®жІЎжңүеҸ‘з”ҹдәӨжҚўпјҢиҜҙжҳҺж•°жҚ®зҡ„йЎәеәҸе·Із»ҸжҺ’еҘҪпјҢжІЎжңүеҝ…иҰҒ继з»ӯиҝӣиЎҢдёӢеҺ»гҖӮ
public static void BubbleSort(int[] arr){
int temp; //дёҙж—¶еҸҳйҮҸ
boolean flag; //жҳҜеҗҰдәӨжҚўзҡ„ж Үи®°
for (int i = arr.length-1;i > 0 ; i--){ // иЎЁзӨәи¶ҹж•°пјҢдёҖе…ұarr.length-1ж¬Ў
flag = false; //и®ҫзҪ®иө·е§Ӣж Үеҝ—дҪҚдёәfalse
for (int j = 0;j < i; j++){ // иЎЁзӨәжҜ”иҫғж¬Ўж•°,д»ҺеҗҺеҫҖеүҚпјҢжҜҸи¶ҹжҜ”иҫғжҠҠжңҖеӨ§зҡ„еҶ’еҲ°жңҖеҗҺйқў
System.out.println("第"+(arr.length-i)+"и¶ҹ"+ "第"+(j+1)+"ж¬ЎжҜ”иҫғ"+Arrays.toString(arr));
if(arr[j] > arr[j+1]){
temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
flag = true;
}
}
if (!flag) break;
}
}ж”№иҝӣзҡ„еҶ’жіЎжҺ’еәҸпјҢйёЎе°ҫй…’еҶ’жіЎжҺ’еәҸпјҢд№ҹеҸ«е®ҡеҗ‘еҶ’жіЎжҺ’еәҸпјҢе®ғзҡ„ж”№иҝӣеңЁдәҺеҗҢж—¶зҡ„еҶ’жіЎдёӨиҫ№пјҢд»ҺдҪҺеҲ°й«ҳпјҢ然еҗҺд»Һй«ҳеҲ°дҪҺпјҢзӣёеҪ“дәҺйЎәдҫҝжҠҠжңҖе°Ҹзҡ„ж•°д№ҹеҶ’жіЎеҲ°жңҖеүҚйқўгҖӮ
public static void cocktailSort(int[] arr){
int left = 0,right = arr.length -1,temp;
while (left < right){
for (int i = left;i < right;i++){ //е°ҶжңҖеӨ§еҖјеҶ’еҲ°ж•°з»„жң«е°ҫ
if (arr[i] > arr[i+1]){
temp = arr[i];
arr[i] = arr[i+1];
arr[i+1] = temp;
}
}
right--;
for (int i = right;i > left;i--){ //е°Ҷиҫғе°ҸеҖјеҶ’еҲ°ж•°з»„еүҚйқў
if (arr[i] < arr[i-1]){
temp = arr[i];
arr[i] = arr[i-1];
arr[i-1] = temp;
}
}
left++;
}
}йҖүжӢ©жҺ’еәҸ(Selection-sort)жҳҜдёҖз§Қз®ҖеҚ•зӣҙи§Ӯзҡ„жҺ’еәҸз®—жі•гҖӮе®ғзҡ„е·ҘдҪңеҺҹзҗҶпјҡйҰ–е…ҲеңЁжңӘжҺ’еәҸеәҸеҲ—дёӯжүҫеҲ°жңҖе°ҸпјҲеӨ§пјүе…ғзҙ пјҢеӯҳж”ҫеҲ°жҺ’еәҸеәҸеҲ—зҡ„иө·е§ӢдҪҚзҪ®пјҢ然еҗҺпјҢеҶҚд»Һеү©дҪҷжңӘжҺ’еәҸе…ғзҙ дёӯ继з»ӯеҜ»жүҫжңҖе°ҸпјҲеӨ§пјүе…ғзҙ пјҢ然еҗҺж”ҫеҲ°е·ІжҺ’еәҸеәҸеҲ—зҡ„жң«е°ҫгҖӮд»ҘжӯӨзұ»жҺЁпјҢзӣҙеҲ°жүҖжңүе…ғзҙ еқҮжҺ’еәҸе®ҢжҜ•гҖӮ
nдёӘи®°еҪ•зҡ„зӣҙжҺҘйҖүжӢ©жҺ’еәҸеҸҜз»ҸиҝҮn-1и¶ҹзӣҙжҺҘйҖүжӢ©жҺ’еәҸеҫ—еҲ°жңүеәҸз»“жһңгҖӮе…·дҪ“з®—жі•жҸҸиҝ°еҰӮдёӢпјҡ
пјҲ1пјүеҲқе§ӢзҠ¶жҖҒпјҡж— еәҸеҢәдёәR[1..n]пјҢжңүеәҸеҢәдёәз©әпјӣ
пјҲ2пјү第iи¶ҹжҺ’еәҸ(i=1,2,3вҖҰn-1)ејҖе§Ӣж—¶пјҢеҪ“еүҚжңүеәҸеҢәе’Ңж— еәҸеҢәеҲҶеҲ«дёәR[1..i-1]е’ҢR(i..nпјүгҖӮиҜҘи¶ҹжҺ’еәҸд»ҺеҪ“еүҚж— еәҸеҢәдёӯ-йҖүеҮәе…ій”®еӯ—жңҖе°Ҹзҡ„и®°еҪ• R[k]пјҢе°Ҷе®ғдёҺж— еәҸеҢәзҡ„第1дёӘи®°еҪ•RдәӨжҚўпјҢдҪҝR[1..i]е’ҢR[i+1..n)еҲҶеҲ«еҸҳдёәи®°еҪ•дёӘж•°еўһеҠ 1дёӘзҡ„ж–°жңүеәҸеҢәе’Ңи®°еҪ•дёӘж•°еҮҸе°‘1дёӘзҡ„ж–°ж— еәҸеҢәпјӣ
пјҲ3пјүn-1и¶ҹз»“жқҹпјҢж•°з»„жңүеәҸеҢ–дәҶгҖӮ
public static void selectSort(int[] arr){
//д»Һж— еәҸзҡ„ж•°з»„дёӯйҖүеҮәжңҖе°ҸеҖјпјҢжӣҝжҚўеҲ°ж•°з»„жңҖеүҚйқў
for(int i = 0;i < arr.length - 1;i++){
int minIndex = i;
for(int j = i + 1;j < arr.length;j++){
if (arr[minIndex] > arr[j]){
minIndex = j;
}
}
int temp = arr[i];
arr[i] = arr[minIndex];
arr[minIndex] = temp;
System.out.println("第"+(i+1)+"ж¬ЎйҖүжӢ©"+Arrays.toString(arr));
}
}иЎЁзҺ°жңҖзЁіе®ҡзҡ„жҺ’еәҸз®—жі•д№ӢдёҖпјҢеӣ дёәж— и®әд»Җд№Ҳж•°жҚ®иҝӣеҺ»йғҪжҳҜO(n2)зҡ„ж—¶й—ҙеӨҚжқӮеәҰпјҢжүҖд»Ҙз”ЁеҲ°е®ғзҡ„ж—¶еҖҷпјҢж•°жҚ®и§„жЁЎи¶Ҡе°Ҹи¶ҠеҘҪгҖӮе”ҜдёҖзҡ„еҘҪеӨ„еҸҜиғҪе°ұжҳҜдёҚеҚ з”ЁйўқеӨ–зҡ„еҶ…еӯҳз©әй—ҙдәҶеҗ§гҖӮзҗҶи®әдёҠи®ІпјҢйҖүжӢ©жҺ’еәҸеҸҜиғҪд№ҹжҳҜе№іж—¶жҺ’еәҸдёҖиҲ¬дәәжғіеҲ°зҡ„жңҖеӨҡзҡ„жҺ’еәҸж–№жі•дәҶеҗ§гҖӮ
жҸ’е…ҘжҺ’еәҸпјҲInsertion-Sortпјүзҡ„з®—жі•жҸҸиҝ°жҳҜдёҖз§Қз®ҖеҚ•зӣҙи§Ӯзҡ„жҺ’еәҸз®—жі•гҖӮе®ғзҡ„е·ҘдҪңеҺҹзҗҶжҳҜйҖҡиҝҮжһ„е»әжңүеәҸеәҸеҲ—пјҢеҜ№дәҺжңӘжҺ’еәҸж•°жҚ®пјҢеңЁе·ІжҺ’еәҸеәҸеҲ—дёӯд»ҺеҗҺеҗ‘еүҚжү«жҸҸпјҢжүҫеҲ°зӣёеә”дҪҚзҪ®е№¶жҸ’е…ҘгҖӮ
дёҖиҲ¬жқҘиҜҙпјҢжҸ’е…ҘжҺ’еәҸйғҪйҮҮз”Ёin-placeеңЁж•°з»„дёҠе®һзҺ°гҖӮе…·дҪ“з®—жі•жҸҸиҝ°еҰӮдёӢпјҡ
пјҲ1пјүд»Һ第дёҖдёӘе…ғзҙ ејҖе§ӢпјҢиҜҘе…ғзҙ еҸҜд»Ҙи®Өдёәе·Із»Ҹиў«жҺ’еәҸпјӣ
пјҲ2пјүеҸ–еҮәдёӢдёҖдёӘе…ғзҙ пјҢеңЁе·Із»ҸжҺ’еәҸзҡ„е…ғзҙ еәҸеҲ—дёӯд»ҺеҗҺеҗ‘еүҚжү«жҸҸпјӣ
пјҲ3пјүеҰӮжһңиҜҘе…ғзҙ пјҲе·ІжҺ’еәҸпјүеӨ§дәҺж–°е…ғзҙ пјҢе°ҶиҜҘе…ғзҙ 移еҲ°дёӢдёҖдҪҚзҪ®пјӣ
пјҲ4пјүйҮҚеӨҚжӯҘйӘӨ3пјҢзӣҙеҲ°жүҫеҲ°е·ІжҺ’еәҸзҡ„е…ғзҙ е°ҸдәҺжҲ–иҖ…зӯүдәҺж–°е…ғзҙ зҡ„дҪҚзҪ®пјӣ
пјҲ5пјүе°Ҷж–°е…ғзҙ жҸ’е…ҘеҲ°иҜҘдҪҚзҪ®еҗҺпјӣ
пјҲ6пјүйҮҚеӨҚжӯҘйӘӨ2~5гҖӮ
public static void insetSort(int[] arr){
for (int i = 0;i < arr.length;i++){
for (int j = i;j > 0;j--){
//й…ҚеҗҲдәӨжҚўзҡ„е®һзҺ°
if (arr[j] < arr[j-1]){
int temp = arr[j];
arr[j] = arr[j-1];
arr[j-1] = temp;
}else {
break;
}
}
System.out.println("第"+(i+1)+"ж¬ЎжҸ’е…Ҙ"+Arrays.toString(arr));
}
}
жҸ’е…ҘжҺ’еәҸеңЁе®һзҺ°дёҠпјҢйҖҡеёёйҮҮз”Ёin-placeжҺ’еәҸпјҲеҚіеҸӘйңҖз”ЁеҲ°O(1)зҡ„йўқеӨ–з©әй—ҙзҡ„жҺ’еәҸпјүпјҢеӣ иҖҢеңЁд»ҺеҗҺеҗ‘еүҚжү«жҸҸиҝҮзЁӢдёӯпјҢйңҖиҰҒеҸҚеӨҚжҠҠе·ІжҺ’еәҸе…ғзҙ йҖҗжӯҘеҗ‘еҗҺжҢӘдҪҚпјҢдёәжңҖж–°е…ғзҙ жҸҗдҫӣжҸ’е…Ҙз©әй—ҙгҖӮ
第дёҖдёӘзӘҒз ҙO(n2)зҡ„жҺ’еәҸз®—жі•пјҢжҳҜз®ҖеҚ•жҸ’е…ҘжҺ’еәҸзҡ„ж”№иҝӣзүҲгҖӮе®ғдёҺжҸ’е…ҘжҺ’еәҸзҡ„дёҚеҗҢд№ӢеӨ„еңЁдәҺпјҢе®ғдјҡдјҳе…ҲжҜ”иҫғи·қзҰ»иҫғиҝңзҡ„е…ғзҙ гҖӮеёҢе°”жҺ’еәҸеҸҲеҸ«зј©е°ҸеўһйҮҸжҺ’еәҸгҖӮ
е…Ҳе°Ҷж•ҙдёӘеҫ…жҺ’еәҸзҡ„и®°еҪ•еәҸеҲ—еҲҶеүІжҲҗдёәиӢҘе№ІеӯҗеәҸеҲ—еҲҶеҲ«иҝӣиЎҢзӣҙжҺҘжҸ’е…ҘжҺ’еәҸпјҢе…·дҪ“з®—жі•жҸҸиҝ°пјҡ
пјҲ1пјүйҖүжӢ©дёҖдёӘеўһйҮҸеәҸеҲ—t1пјҢt2пјҢвҖҰпјҢtkпјҢе…¶дёӯti>tjпјҢtk=1пјӣ
пјҲ2пјүжҢүеўһйҮҸеәҸеҲ—дёӘж•°kпјҢеҜ№еәҸеҲ—иҝӣиЎҢk и¶ҹжҺ’еәҸпјӣ
пјҲ3пјүжҜҸи¶ҹжҺ’еәҸпјҢж №жҚ®еҜ№еә”зҡ„еўһйҮҸtiпјҢе°Ҷеҫ…жҺ’еәҸеҲ—еҲҶеүІжҲҗиӢҘе№Ій•ҝеәҰдёәm зҡ„еӯҗеәҸеҲ—пјҢеҲҶеҲ«еҜ№еҗ„еӯҗиЎЁиҝӣиЎҢзӣҙжҺҘжҸ’е…ҘжҺ’еәҸгҖӮд»…еўһйҮҸеӣ еӯҗдёә1 ж—¶пјҢж•ҙдёӘеәҸеҲ—дҪңдёәдёҖдёӘиЎЁжқҘеӨ„зҗҶпјҢиЎЁй•ҝеәҰеҚідёәж•ҙдёӘеәҸеҲ—зҡ„й•ҝеәҰгҖӮ
public static void ShellSort(int[] arr){
//е®ҡд№үеўһйҮҸеәҸеҲ—пјҢж•°з»„й•ҝеәҰзҡ„жҜҸж¬ЎжҠҳеҚҠ
int incre = arr.length;
int n = 0;
while (true){
n += 1;
incre = incre / 2;
System.out.println("第"+n+"йҒҚжҺ’еәҸпјҢеўһйҮҸеәҸеҲ—дёәпјҡ"+incre+Arrays.toString(arr));
// ж №жҚ®еўһйҮҸжӢҶеҲҶжҲҗдёҚеҗҢзҡ„ж•°з»„еәҸеҲ—пјҢжӢҶеҲҶдёәincreз»„
for (int k = 0;k < incre; k++){ //еҜ№жӢҶеҲҶзҡ„еәҸеҲ—з”ЁжҸ’е…ҘжҺ’еәҸ
for (int i = k;i < arr.length;i += incre){
for (int j = i;j>k;j-=incre){
if (arr[j] < arr[j-incre]){
int temp = arr[j];
arr[j] = arr[j-incre];
arr[j-incre] = temp;
}else {
break;
}
}
}
}
if (incre == 1){
break;
}
}
}еёҢе°”жҺ’еәҸзҡ„ж ёеҝғеңЁдәҺй—ҙйҡ”еәҸеҲ—зҡ„и®ҫе®ҡгҖӮж—ўеҸҜд»ҘжҸҗеүҚи®ҫе®ҡеҘҪй—ҙйҡ”еәҸеҲ—пјҢд№ҹеҸҜд»ҘеҠЁжҖҒзҡ„е®ҡд№үй—ҙйҡ”еәҸеҲ—гҖӮеҠЁжҖҒе®ҡд№үй—ҙйҡ”еәҸеҲ—зҡ„з®—жі•жҳҜгҖҠз®—жі•пјҲ第4зүҲпјүгҖӢзҡ„еҗҲи‘—иҖ…Robert SedgewickжҸҗеҮәзҡ„гҖӮ
еҪ’并жҺ’еәҸжҳҜе»әз«ӢеңЁеҪ’并ж“ҚдҪңдёҠзҡ„дёҖз§Қжңүж•Ҳзҡ„жҺ’еәҸз®—жі•гҖӮиҜҘз®—жі•жҳҜйҮҮз”ЁеҲҶжІ»жі•пјҲDivide and Conquerпјүзҡ„дёҖдёӘйқһеёёе…ёеһӢзҡ„еә”з”ЁгҖӮе°Ҷе·ІжңүеәҸзҡ„еӯҗеәҸеҲ—еҗҲ并пјҢеҫ—еҲ°е®Ңе…ЁжңүеәҸзҡ„еәҸеҲ—пјӣеҚіе…ҲдҪҝжҜҸдёӘеӯҗеәҸеҲ—жңүеәҸпјҢеҶҚдҪҝеӯҗеәҸеҲ—ж®өй—ҙжңүеәҸгҖӮиӢҘе°ҶдёӨдёӘжңүеәҸиЎЁеҗҲ并жҲҗдёҖдёӘжңүеәҸиЎЁпјҢз§°дёә2-и·ҜеҪ’并гҖӮ
пјҲ1пјүжҠҠй•ҝеәҰдёәnзҡ„иҫ“е…ҘеәҸеҲ—еҲҶжҲҗдёӨдёӘй•ҝеәҰдёәn/2зҡ„еӯҗеәҸеҲ—пјӣ
пјҲ2пјүеҜ№иҝҷдёӨдёӘеӯҗеәҸеҲ—еҲҶеҲ«йҮҮз”ЁеҪ’并жҺ’еәҸпјӣ
пјҲ3пјүе°ҶдёӨдёӘжҺ’еәҸеҘҪзҡ„еӯҗеәҸеҲ—еҗҲ并жҲҗдёҖдёӘжңҖз»Ҳзҡ„жҺ’еәҸеәҸеҲ—гҖӮ
public static int[] MergeSort(int[] arr){
if (arr.length < 2) return arr;
int mid = arr.length / 2;
int[] left = Arrays.copyOfRange(arr,0,mid);
int[] right = Arrays.copyOfRange(arr,mid,arr.length);
return merge_sort(MergeSort(left),MergeSort(right));
}
public static int[] merge_sort(int[] left,int[] right){
int[] newarr = new int[left.length + right.length];
for (int index = 0,i = 0,j = 0;index < newarr.length;index++){
if (i >= left.length){
newarr[index] = right[j++];
}else if (j >= right.length){
newarr[index] = left[i++];
}else if (left[i] > right[j]){
newarr[index] = right[j++];
}else {
newarr[index] = left[i++];
}
}
return newarr;
}еҪ’并жҺ’еәҸжҳҜдёҖз§ҚзЁіе®ҡзҡ„жҺ’еәҸж–№жі•гҖӮе’ҢйҖүжӢ©жҺ’еәҸдёҖж ·пјҢеҪ’并жҺ’еәҸзҡ„жҖ§иғҪдёҚеҸ—иҫ“е…Ҙж•°жҚ®зҡ„еҪұе“ҚпјҢдҪҶиЎЁзҺ°жҜ”йҖүжӢ©жҺ’еәҸеҘҪзҡ„еӨҡпјҢеӣ дёәе§Ӣз»ҲйғҪжҳҜO(nlognпјүзҡ„ж—¶й—ҙеӨҚжқӮеәҰгҖӮд»Јд»·жҳҜйңҖиҰҒйўқеӨ–зҡ„еҶ…еӯҳз©әй—ҙгҖӮ
еҝ«йҖҹжҺ’еәҸзҡ„еҹәжң¬жҖқжғіпјҡйҖҡиҝҮдёҖи¶ҹжҺ’еәҸе°Ҷеҫ…жҺ’и®°еҪ•еҲҶйҡ”жҲҗзӢ¬з«Ӣзҡ„дёӨйғЁеҲҶпјҢе…¶дёӯдёҖйғЁеҲҶи®°еҪ•зҡ„е…ій”®еӯ—еқҮжҜ”еҸҰдёҖйғЁеҲҶзҡ„е…ій”®еӯ—е°ҸпјҢеҲҷеҸҜеҲҶеҲ«еҜ№иҝҷдёӨйғЁеҲҶи®°еҪ•з»§з»ӯиҝӣиЎҢжҺ’еәҸпјҢд»ҘиҫҫеҲ°ж•ҙдёӘеәҸеҲ—жңүеәҸгҖӮ
еҝ«йҖҹжҺ’еәҸдҪҝз”ЁеҲҶжІ»жі•жқҘжҠҠдёҖдёӘдёІпјҲlistпјүеҲҶдёәдёӨдёӘеӯҗдёІпјҲsub-listsпјүгҖӮе…·дҪ“з®—жі•жҸҸиҝ°еҰӮдёӢпјҡ
пјҲ1пјүд»Һж•°еҲ—дёӯжҢ‘еҮәдёҖдёӘе…ғзҙ пјҢз§°дёә вҖңеҹәеҮҶвҖқпјҲpivotпјүпјӣ
пјҲ2пјүйҮҚж–°жҺ’еәҸж•°еҲ—пјҢжүҖжңүе…ғзҙ жҜ”еҹәеҮҶеҖје°Ҹзҡ„ж‘Ҷж”ҫеңЁеҹәеҮҶеүҚйқўпјҢжүҖжңүе…ғзҙ жҜ”еҹәеҮҶеҖјеӨ§зҡ„ж‘ҶеңЁеҹәеҮҶзҡ„еҗҺйқўпјҲзӣёеҗҢзҡ„ж•°еҸҜд»ҘеҲ°д»»дёҖиҫ№пјүгҖӮеңЁиҝҷдёӘеҲҶеҢәйҖҖеҮәд№ӢеҗҺпјҢиҜҘеҹәеҮҶе°ұеӨ„дәҺж•°еҲ—зҡ„дёӯй—ҙдҪҚзҪ®гҖӮиҝҷдёӘз§°дёәеҲҶеҢәпјҲpartitionпјүж“ҚдҪңпјӣ
пјҲ3пјүйҖ’еҪ’ең°пјҲrecursiveпјүжҠҠе°ҸдәҺеҹәеҮҶеҖје…ғзҙ зҡ„еӯҗж•°еҲ—е’ҢеӨ§дәҺеҹәеҮҶеҖје…ғзҙ зҡ„еӯҗж•°еҲ—жҺ’еәҸгҖӮ
public static void QuickSort(int[] arr,int left,int right){
if (left >= right){
return;
}
//йҖүжӢ©з¬¬дёҖдёӘж•°дёәkey
int l = left,r = right;
int key = arr[left];
while (l < r){
//е…Ҳд»ҺеҸіиҫ№жүҫеҲ°з¬¬дёҖдёӘе°ҸдәҺkeyзҡ„ж•°
while (l < r && key <= arr[r]){
r--;
}
if (l < r){
arr[l] = arr[r];
l++;
}
//еҶҚд»Һе·Ұиҫ№иө·жүҫеҲ°з¬¬дёҖдёӘеӨ§дәҺkeyзҡ„еҖј
while (l < r && key > arr[l]){
l++;
}
if (l<r){
arr[r] = arr[l];
r--;
}
arr[l] = key;
QuickSort(arr,left,l-1);
QuickSort(arr,l+1,right);
}
}
public static void QuickSortFunc(int[] arr){
int left = 0;
int right = arr.length-1;
QuickSort(arr,left,right);
}е ҶжҺ’еәҸпјҲHeapsortпјүжҳҜжҢҮеҲ©з”Ёе Ҷиҝҷз§Қж•°жҚ®з»“жһ„жүҖи®ҫи®Ўзҡ„дёҖз§ҚжҺ’еәҸз®—жі•гҖӮе Ҷз§ҜжҳҜдёҖдёӘиҝ‘дјје®Ңе…ЁдәҢеҸүж ‘зҡ„з»“жһ„пјҢ并еҗҢж—¶ж»Ўи¶іе Ҷз§Ҝзҡ„жҖ§иҙЁпјҡеҚіеӯҗз»“зӮ№зҡ„й”®еҖјжҲ–зҙўеј•жҖ»жҳҜе°ҸдәҺпјҲжҲ–иҖ…еӨ§дәҺпјүе®ғзҡ„зҲ¶иҠӮзӮ№гҖӮ
пјҲ1пјүе°ҶеҲқе§Ӣеҫ…жҺ’еәҸе…ій”®еӯ—еәҸеҲ—(R1,R2вҖҰ.Rn)жһ„е»әжҲҗеӨ§йЎ¶е ҶпјҢжӯӨе ҶдёәеҲқе§Ӣзҡ„ж— еәҸеҢәпјӣ
пјҲ2пјүе°Ҷе ҶйЎ¶е…ғзҙ R[1]дёҺжңҖеҗҺдёҖдёӘе…ғзҙ R[n]дәӨжҚўпјҢжӯӨж—¶еҫ—еҲ°ж–°зҡ„ж— еәҸеҢә(R1,R2,вҖҰвҖҰRn-1)е’Ңж–°зҡ„жңүеәҸеҢә(Rn),дё”ж»Ўи¶іR[1,2вҖҰn-1]<=R[n]пјӣ
пјҲ3пјүз”ұдәҺдәӨжҚўеҗҺж–°зҡ„е ҶйЎ¶R[1]еҸҜиғҪиҝқеҸҚе Ҷзҡ„жҖ§иҙЁпјҢеӣ жӯӨйңҖиҰҒеҜ№еҪ“еүҚж— еәҸеҢә(R1,R2,вҖҰвҖҰRn-1)и°ғж•ҙдёәж–°е ҶпјҢ然еҗҺеҶҚж¬Ўе°ҶR[1]дёҺж— еәҸеҢәжңҖеҗҺдёҖдёӘе…ғзҙ дәӨжҚўпјҢеҫ—еҲ°ж–°зҡ„ж— еәҸеҢә(R1,R2вҖҰ.Rn-2)е’Ңж–°зҡ„жңүеәҸеҢә(Rn-1,Rn)гҖӮдёҚж–ӯйҮҚеӨҚжӯӨиҝҮзЁӢзӣҙеҲ°жңүеәҸеҢәзҡ„е…ғзҙ дёӘж•°дёәn-1пјҢеҲҷж•ҙдёӘжҺ’еәҸиҝҮзЁӢе®ҢжҲҗгҖӮ
public static void HeapSort(int[] arr){
//1гҖҒжһ„е»әеӨ§йЎ№е Ҷ
for (int i = arr.length/2 - 1;i>=0;i--){
//д»Һ第дёҖдёӘйқһеҸ¶еӯҗиҠӮзӮ№д»ҺдёӢиҮідёҠпјҢд»ҺеҸіиҮіе·Ұи°ғж•ҙз»“жһ„
adjustHeap(arr,i,arr.length);
}
//2гҖҒи°ғж•ҙе Ҷз»“жһ„+дәӨжҚўе ҶйЎ¶е…ғзҙ дёҺжң«е°ҫе…ғзҙ
for(int j = arr.length-1;j>0;j--){
int temp = arr[0];
arr[0] = arr[j];
arr[j] = temp; //е°Ҷе ҶйЎ¶е…ғзҙ дёҺжң«е°ҫе…ғзҙ иҝӣиЎҢдәӨжҚў
adjustHeap(arr,0,j); //йҮҚж–°иҝӣиЎҢе Ҷи°ғж•ҙ
}
}
//и°ғж•ҙе Ҷ
public static void adjustHeap(int[] arr,int i,int length){
//е…ҲеҸ–еҮәеҪ“еүҚе…ғзҙ i
int temp = arr[i];
//д»Һiз»“зӮ№зҡ„е·Ұеӯҗз»“зӮ№ејҖе§ӢпјҢд№ҹе°ұжҳҜ2i+1еӨ„ејҖе§Ӣ
for (int k = i*2 + 1;k<length;k=k*2+1){
//еҰӮжһңе·ҰеӯҗиҠӮзӮ№е°ҸдәҺеҸіеӯҗиҠӮзӮ№пјҢkжҢҮеҗ‘еҸіеӯҗиҠӮзӮ№
if(k+1<length && arr[k] < arr[k+1]){
k++;
}
if (arr[k] > temp){//еҰӮжһңеӯҗиҠӮзӮ№еӨ§дәҺзҲ¶иҠӮзӮ№пјҢе°ҶеӯҗиҠӮзӮ№еҖјд»ҳз»ҷзҲ¶иҠӮзӮ№пјҲдёҚз”ЁиҝӣиЎҢдәӨжҚўпјү
arr[i] = arr[k];
i = k;
}else {
break;
}
}
arr[i] = temp; //е°ҶtempеҖјж”ҫеҲ°жңҖз»Ҳзҡ„дҪҚзҪ®
}и®Ўж•°жҺ’еәҸдёҚжҳҜеҹәдәҺжҜ”иҫғзҡ„жҺ’еәҸз®—жі•пјҢе…¶ж ёеҝғеңЁдәҺе°Ҷиҫ“е…Ҙзҡ„ж•°жҚ®еҖјиҪ¬еҢ–дёәй”®еӯҳеӮЁеңЁйўқеӨ–ејҖиҫҹзҡ„ж•°з»„з©әй—ҙдёӯгҖӮ дҪңдёәдёҖз§ҚзәҝжҖ§ж—¶й—ҙеӨҚжқӮеәҰзҡ„жҺ’еәҸпјҢи®Ўж•°жҺ’еәҸиҰҒжұӮиҫ“е…Ҙзҡ„ж•°жҚ®еҝ…йЎ»жҳҜжңүзЎ®е®ҡиҢғеӣҙзҡ„ж•ҙж•°гҖӮ
е®ғзҡ„дјҳеҠҝеңЁдәҺеңЁеҜ№дәҺиҫғе°ҸиҢғеӣҙеҶ…зҡ„ж•ҙж•°жҺ’еәҸгҖӮе®ғзҡ„еӨҚжқӮеәҰдёәОҹ(n+k)пјҲе…¶дёӯkжҳҜеҫ…жҺ’еәҸж•°зҡ„иҢғеӣҙпјүпјҢеҝ«дәҺд»»дҪ•жҜ”иҫғжҺ’еәҸз®—жі•пјҢзјәзӮ№е°ұжҳҜйқһеёёж¶ҲиҖ—з©әй—ҙгҖӮеҫҲжҳҺжҳҫпјҢеҰӮжһңиҖҢдё”еҪ“O(k)>O(n*log(n))зҡ„ж—¶еҖҷе…¶ж•ҲзҺҮеҸҚиҖҢдёҚеҰӮеҹәдәҺжҜ”иҫғзҡ„жҺ’еәҸпјҢжҜ”еҰӮе ҶжҺ’еәҸе’ҢеҪ’并жҺ’еәҸе’Ңеҝ«йҖҹжҺ’еәҸгҖӮ
иҰҒжұӮпјҡеҫ…жҺ’еәҸж•°дёӯжңҖеӨ§ж•°еҖјдёҚиғҪеӨӘеӨ§гҖӮ
пјҲ1пјүжүҫеҮәеҫ…жҺ’еәҸзҡ„ж•°з»„дёӯжңҖеӨ§е’ҢжңҖе°Ҹзҡ„е…ғзҙ пјӣ
пјҲ2пјүз»ҹи®Ўж•°з»„дёӯжҜҸдёӘеҖјдёәiзҡ„е…ғзҙ еҮәзҺ°зҡ„ж¬Ўж•°пјҢеӯҳе…Ҙж•°з»„Cзҡ„第iйЎ№пјӣ
пјҲ3пјүеҜ№жүҖжңүзҡ„и®Ўж•°зҙҜеҠ пјҲд»ҺCдёӯзҡ„第дёҖдёӘе…ғзҙ ејҖе§ӢпјҢжҜҸдёҖйЎ№е’ҢеүҚдёҖйЎ№зӣёеҠ пјүпјӣ
пјҲ4пјүеҸҚеҗ‘еЎ«е……зӣ®ж Үж•°з»„пјҡе°ҶжҜҸдёӘе…ғзҙ iж”ҫеңЁж–°ж•°з»„зҡ„第C(i)йЎ№пјҢжҜҸж”ҫдёҖдёӘе…ғзҙ е°ұе°ҶC(i)еҮҸеҺ»1гҖӮ
public static int[] CountSort(int[] arr){
//1гҖҒжүҫеҮәж•°з»„arrдёӯзҡ„жңҖеӨ§еҖј
int k = arr[0];
for (int i = 1;i < arr.length;i++){
if (k < arr[i]){
k = arr[i];
}
}
//2гҖҒжһ„йҖ Cж•°з»„пјҢе°ҶAдёӯжҜҸдёӘе…ғзҙ еҜ№еә”Cдёӯзҡ„е…ғзҙ еӨ§е°Ҹ+1
int[] C = new int[k+1];
int sum = 0;
for (int i = 0;i < arr.length;i++){
C[arr[i]] +=1; //з»ҹи®ЎAдёӯеҗ„е…ғзҙ дёӘж•°пјҢеҜ№еә”еҲ°Cж•°з»„
}
//3гҖҒе°ҶCдёӯжҜҸдёӘiдҪҚзҪ®зҡ„е…ғзҙ еӨ§е°Ҹж”№жҲҗCж•°з»„еүҚiйЎ№е’Ң
for (int i=0;i<k+1; i++){
sum += C[i];
C[i] = sum;
}
//4гҖҒжһ„йҖ Bж•°з»„пјҢеҲқе§ӢеҢ–дёҖдёӘе’ҢAеҗҢж ·еӨ§е°Ҹзҡ„ж•°з»„Bз”ЁдәҺеӯҳеӮЁжҺ’еәҸеҗҺж•°з»„пјҢ然еҗҺеҖ’еәҸйҒҚеҺҶAдёӯе…ғзҙ пјҲеҗҺйқўдјҡжҸҗеҲ°дёәдҪ•иҰҒеҖ’еәҸйҒҚеҺҶпјүпјҢйҖҡиҝҮжҹҘжүҫCж•°з»„пјҢе°ҶиҜҘе…ғзҙ ж”ҫзҪ®еҲ°Bдёӯзӣёеә”зҡ„дҪҚзҪ®пјҢеҗҢж—¶е°ҶCдёӯеҜ№еә”зҡ„е…ғзҙ еӨ§е°Ҹ-1пјҲиЎЁжҳҺе·Із»Ҹж”ҫзҪ®дәҶдёҖдёӘиҝҷж ·еӨ§е°Ҹзҡ„е…ғзҙ пјҢдёӢж¬ЎеҶҚж”ҫеҗҢж ·еӨ§е°Ҹзҡ„е…ғзҙ пјҢе°ұиҰҒеҫҖеүҚжҢӨдёҖдёӘдҪҚзҪ®пјү
int[] B = new int[arr.length];
for (int i = arr.length-1;i>=0;i--){ //еҖ’еәҸйҒҚеҺҶAж•°з»„пјҢжһ„йҖ Bж•°з»„
B[C[arr[i]]-1] = arr[i]; //е°ҶAдёӯиҜҘе…ғзҙ ж”ҫеҲ°жҺ’еәҸеҗҺж•°з»„BдёӯжҢҮе®ҡзҡ„дҪҚзҪ®
C[arr[i]]--; //е°ҶCдёӯиҜҘе…ғзҙ -1пјҢж–№дҫҝеӯҳж”ҫдёӢдёҖдёӘеҗҢж ·еӨ§е°Ҹзҡ„е…ғзҙ
}
//5гҖҒе°ҶжҺ’еәҸеҘҪзҡ„ж•°з»„Bиҝ”еӣһпјҢе®ҢжҲҗжҺ’еәҸ
return B;
} и®Ўж•°жҺ’еәҸжҳҜдёҖдёӘзЁіе®ҡзҡ„жҺ’еәҸз®—жі•гҖӮеҪ“иҫ“е…Ҙзҡ„е…ғзҙ жҳҜ n дёӘ 0еҲ° k д№Ӣй—ҙзҡ„ж•ҙж•°ж—¶пјҢж—¶й—ҙеӨҚжқӮеәҰжҳҜO(n+k)пјҢз©әй—ҙеӨҚжқӮеәҰд№ҹжҳҜO(n+k)пјҢе…¶жҺ’еәҸйҖҹеәҰеҝ«дәҺд»»дҪ•жҜ”иҫғжҺ’еәҸз®—жі•гҖӮеҪ“kдёҚжҳҜеҫҲеӨ§е№¶дё”еәҸеҲ—жҜ”иҫғйӣҶдёӯж—¶пјҢи®Ўж•°жҺ’еәҸжҳҜдёҖдёӘеҫҲжңүж•Ҳзҡ„жҺ’еәҸз®—жі•гҖӮжЎ¶жҺ’еәҸжҳҜи®Ўж•°жҺ’еәҸзҡ„еҚҮзә§зүҲгҖӮе®ғеҲ©з”ЁдәҶеҮҪж•°зҡ„жҳ е°„е…ізі»пјҢй«ҳж•ҲдёҺеҗҰзҡ„е…ій”®е°ұеңЁдәҺиҝҷдёӘжҳ е°„еҮҪж•°зҡ„зЎ®е®ҡгҖӮжЎ¶жҺ’еәҸ (Bucket sort)зҡ„е·ҘдҪңзҡ„еҺҹзҗҶпјҡеҒҮи®ҫиҫ“е…Ҙж•°жҚ®жңҚд»ҺеқҮеҢҖеҲҶеёғпјҢе°Ҷж•°жҚ®еҲҶеҲ°жңүйҷҗж•°йҮҸзҡ„жЎ¶йҮҢпјҢжҜҸдёӘжЎ¶еҶҚеҲҶеҲ«жҺ’еәҸпјҲжңүеҸҜиғҪеҶҚдҪҝз”ЁеҲ«зҡ„жҺ’еәҸз®—жі•жҲ–жҳҜд»ҘйҖ’еҪ’ж–№ејҸ继з»ӯдҪҝз”ЁжЎ¶жҺ’еәҸиҝӣиЎҢжҺ’пјүгҖӮ
иҰҒжұӮпјҡеҫ…жҺ’еәҸж•°й•ҝеәҰдёҖиҮҙгҖӮ
пјҲ1пјүи®ҫзҪ®дёҖдёӘе®ҡйҮҸзҡ„ж•°з»„еҪ“дҪңз©әжЎ¶пјӣ
пјҲ2пјүйҒҚеҺҶиҫ“е…Ҙж•°жҚ®пјҢ并且жҠҠж•°жҚ®дёҖдёӘдёҖдёӘж”ҫеҲ°еҜ№еә”зҡ„жЎ¶йҮҢеҺ»пјӣ
пјҲ3пјүеҜ№жҜҸдёӘдёҚжҳҜз©әзҡ„жЎ¶иҝӣиЎҢжҺ’еәҸпјӣ
пјҲ4пјүд»ҺдёҚжҳҜз©әзҡ„жЎ¶йҮҢжҠҠжҺ’еҘҪеәҸзҡ„ж•°жҚ®жӢјжҺҘиө·жқҘгҖӮ
з®—жі•е®һзҺ°йҖ»иҫ‘
пјҲ1пјүжүҫеҮәеҫ…жҺ’еәҸж•°з»„дёӯзҡ„жңҖеӨ§еҖјmaxгҖҒжңҖе°ҸеҖјmin
пјҲ2пјүжҲ‘们дҪҝз”Ё еҠЁжҖҒж•°з»„ArrayList дҪңдёәжЎ¶пјҢжЎ¶йҮҢж”ҫзҡ„е…ғзҙ д№ҹз”Ё ArrayList еӯҳеӮЁгҖӮжЎ¶зҡ„ж•°йҮҸдёә(max-min)/arr.length+1
пјҲ3пјүйҒҚеҺҶж•°з»„ arrпјҢи®Ўз®—жҜҸдёӘе…ғзҙ arr[i] ж”ҫзҡ„жЎ¶
пјҲ4пјүжҜҸдёӘжЎ¶еҗ„иҮӘжҺ’еәҸ
пјҲ5пјүйҒҚеҺҶжЎ¶ж•°з»„пјҢжҠҠжҺ’еәҸеҘҪзҡ„е…ғзҙ ж”ҫиҝӣиҫ“еҮәж•°з»„
public static void BucketSort(int[] arr){
int max = Integer.MIN_VALUE;
int min = Integer.MAX_VALUE;
for (int i = 0;i < arr.length;i++){
max = Math.max(max,arr[i]);
min = Math.min(min,arr[i]);
}
//и®Ўз®—жЎ¶ж•°
int bucketNum = (max - min) / arr.length + 1;
ArrayList<ArrayList<Integer>> bunketArr = new ArrayList<>(bucketNum);
for (int i = 0;i < bucketNum;i++){
bunketArr.add(new ArrayList<Integer>());
}
for (int i = 0;i<arr.length;i++){
int num = (arr[i] - min) / (arr.length);
bunketArr.get(num).add(arr[i]);
}
//еҜ№жҜҸдёӘжЎ¶иҝӣиЎҢжҺ’еәҸ
for (int i = 0;i < bunketArr.size();i++){
Collections.sort(bunketArr.get(i));
}
//е°ҶжЎ¶дёӯжҺ’еҘҪеәҸзҡ„ж•°жҚ®дҫқж¬ЎеӨҚеҲ¶еӣһеҺҹж•°з»„
int index = 0;
for (int i = 0;i < bucketNum;i++){
for (int j = 0;j < bunketArr.get(i).size();j++){
arr[index++] = bunketArr.get(i).get(j);
}
}
}жЎ¶жҺ’еәҸжңҖеҘҪжғ…еҶөдёӢдҪҝз”ЁзәҝжҖ§ж—¶й—ҙO(n)пјҢжЎ¶жҺ’еәҸзҡ„ж—¶й—ҙеӨҚжқӮеәҰпјҢеҸ–еҶідёҺеҜ№еҗ„дёӘжЎ¶д№Ӣй—ҙж•°жҚ®иҝӣиЎҢжҺ’еәҸзҡ„ж—¶й—ҙеӨҚжқӮеәҰпјҢеӣ дёәе…¶е®ғйғЁеҲҶзҡ„ж—¶й—ҙеӨҚжқӮеәҰйғҪдёәO(n)гҖӮеҫҲжҳҫ然пјҢжЎ¶еҲ’еҲҶзҡ„и¶Ҡе°ҸпјҢеҗ„дёӘжЎ¶д№Ӣй—ҙзҡ„ж•°жҚ®и¶Ҡе°‘пјҢжҺ’еәҸжүҖз”Ёзҡ„ж—¶й—ҙд№ҹдјҡи¶Ҡе°‘гҖӮдҪҶзӣёеә”зҡ„з©әй—ҙж¶ҲиҖ—е°ұдјҡеўһеӨ§гҖӮ
еҹәж•°жҺ’еәҸжҳҜжҢүз…§дҪҺдҪҚе…ҲжҺ’еәҸпјҢ然еҗҺ收йӣҶпјӣеҶҚжҢүз…§й«ҳдҪҚжҺ’еәҸпјҢ然еҗҺеҶҚ收йӣҶпјӣдҫқж¬Ўзұ»жҺЁпјҢзӣҙеҲ°жңҖй«ҳдҪҚгҖӮжңүж—¶еҖҷжңүдәӣеұһжҖ§жҳҜжңүдјҳе…Ҳзә§йЎәеәҸзҡ„пјҢе…ҲжҢүдҪҺдјҳе…Ҳзә§жҺ’еәҸпјҢеҶҚжҢүй«ҳдјҳе…Ҳзә§жҺ’еәҸгҖӮжңҖеҗҺзҡ„ж¬ЎеәҸе°ұжҳҜй«ҳдјҳе…Ҳзә§й«ҳзҡ„еңЁеүҚпјҢй«ҳдјҳе…Ҳзә§зӣёеҗҢзҡ„дҪҺдјҳе…Ҳзә§й«ҳзҡ„еңЁеүҚгҖӮ
еҹәж•°жҺ’еәҸеұһдәҺвҖңеҲҶй…ҚејҸжҺ’еәҸвҖқпјҲdistribution sortпјүпјҢжҳҜйқһжҜ”иҫғзұ»зәҝжҖ§ж—¶й—ҙжҺ’еәҸзҡ„дёҖз§ҚпјҢеҸҲз§°вҖңжЎ¶еӯҗжі•вҖқпјҲbucket sortпјүпјҢйЎҫеҗҚжҖқд№үпјҢе®ғжҳҜйҖҸиҝҮй”®еҖјзҡ„йғЁеҲҶдҝЎжҒҜпјҢе°ҶиҰҒжҺ’еәҸзҡ„е…ғзҙ еҲҶй…ҚиҮіжҹҗдәӣвҖңжЎ¶вҖқдёӯпјҢи—үд»ҘиҫҫеҲ°жҺ’еәҸзҡ„дҪңз”ЁгҖӮ
еҹәж•°жҺ’еәҸпјҲд»ҘГ—Г—Г—дёәдҫӢпјүпјҢе°ҶГ—Г—Г—10иҝӣеҲ¶жҢүжҜҸдҪҚжӢҶеҲҶпјҢ然еҗҺд»ҺдҪҺдҪҚеҲ°й«ҳдҪҚдҫқж¬ЎжҜ”иҫғеҗ„дёӘдҪҚгҖӮдё»иҰҒеҲҶдёәдёӨдёӘиҝҮзЁӢпјҡ
пјҲ1пјүеҲҶй…ҚпјҢе…Ҳд»ҺдёӘдҪҚејҖе§ӢпјҢж №жҚ®дҪҚеҖј(0-9)еҲҶеҲ«ж”ҫеҲ°0~9еҸ·жЎ¶дёӯпјҲжҜ”еҰӮпј–4пјҢдёӘдҪҚдёәпј”пјҢеҲҷж”ҫе…Ҙпј”еҸ·жЎ¶дёӯпјүпјӣ
пјҲ2пјү收йӣҶпјҢеҶҚе°Ҷж”ҫзҪ®еңЁ0~9еҸ·жЎ¶дёӯзҡ„ж•°жҚ®жҢүйЎәеәҸж”ҫеҲ°ж•°з»„дёӯпјӣ
пјҲ3пјүйҮҚеӨҚпјҲ1пјүпјҲ2пјүиҝҮзЁӢпјҢд»ҺдёӘдҪҚеҲ°жңҖй«ҳдҪҚпјҲжҜ”еҰӮ32дҪҚж— з¬ҰеҸ·ж•ҙеһӢжңҖеӨ§ж•°4294967296пјҢжңҖй«ҳдҪҚдёә第10дҪҚпјүгҖӮеҹәж•°жҺ’еәҸзҡ„ж–№ејҸеҸҜд»ҘйҮҮз”ЁLSDпјҲLeast Significant DigitalпјүжҲ–MSDпјҲMost Significant DigitalпјүпјҢLSDзҡ„жҺ’еәҸж–№ејҸз”ұй”®еҖјзҡ„жңҖеҸіиҫ№ејҖе§ӢпјҢиҖҢMSDеҲҷзӣёеҸҚпјҢз”ұй”®еҖјзҡ„жңҖе·Ұиҫ№ејҖе§ӢгҖӮ
public static int[] RadixSort(int[] array) {
if (array == null || array.length < 2)
return array;
// 1.е…Ҳз®—еҮәжңҖеӨ§ж•°зҡ„дҪҚж•°пјӣ
int max = array[0];
for (int i = 1; i < array.length; i++) {
max = Math.max(max, array[i]);
}
int maxDigit = 0;
while (max != 0) {
max /= 10;
maxDigit++;
}
int mod = 10, div = 1;
ArrayList<ArrayList<Integer>> bucketList = new
ArrayList<ArrayList<Integer>>();
for (int i = 0; i < 10; i++)
bucketList.add(new ArrayList<Integer>());
for (int i = 0; i < maxDigit; i++, mod *= 10, div *= 10) {
for (int j = 0; j < array.length; j++) {
int num = (array[j] % mod) / div;
bucketList.get(num).add(array[j]);
}
int index = 0;
for (int j = 0; j < bucketList.size(); j++) {
for (int k = 0; k < bucketList.get(j).size(); k++)
array[index++] = bucketList.get(j).get(k);
bucketList.get(j).clear();
}
}
return array;
}еҹәж•°жҺ’еәҸеҹәдәҺеҲҶеҲ«жҺ’еәҸпјҢеҲҶеҲ«ж”¶йӣҶпјҢжүҖд»ҘжҳҜзЁіе®ҡзҡ„гҖӮдҪҶеҹәж•°жҺ’еәҸзҡ„жҖ§иғҪжҜ”жЎ¶жҺ’еәҸиҰҒз•Ҙе·®пјҢжҜҸдёҖж¬Ўе…ій”®еӯ—зҡ„жЎ¶еҲҶй…ҚйғҪйңҖиҰҒO(n)зҡ„ж—¶й—ҙеӨҚжқӮеәҰпјҢиҖҢдё”еҲҶй…Қд№ӢеҗҺеҫ—еҲ°ж–°зҡ„е…ій”®еӯ—еәҸеҲ—еҸҲйңҖиҰҒO(n)зҡ„ж—¶й—ҙеӨҚжқӮеәҰгҖӮеҒҮеҰӮеҫ…жҺ’ж•°жҚ®еҸҜд»ҘеҲҶдёәdдёӘе…ій”®еӯ—пјҢеҲҷеҹәж•°жҺ’еәҸзҡ„ж—¶й—ҙеӨҚжқӮеәҰе°ҶжҳҜO(d*2n) пјҢеҪ“然dиҰҒиҝңиҝңе°ҸдәҺnпјҢеӣ жӯӨеҹәжң¬дёҠиҝҳжҳҜзәҝжҖ§зә§еҲ«зҡ„гҖӮ
еҹәж•°жҺ’еәҸзҡ„з©әй—ҙеӨҚжқӮеәҰдёәO(n+k)пјҢе…¶дёӯkдёәжЎ¶зҡ„ж•°йҮҸгҖӮдёҖиҲ¬жқҘиҜҙn>>kпјҢеӣ жӯӨйўқеӨ–з©әй—ҙйңҖиҰҒеӨ§жҰӮnдёӘе·ҰеҸігҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ