您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容主要讲解“MapReduce的输出格式是怎样的”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“MapReduce的输出格式是怎样的”吧!
Hadoop 都有相应的输出格式。默认情况下只有一个 Reduce,输出只有一个文件,默认文件名为 part-r-00000,输出文件的个数与 Reduce 的个数一致。 如果有两个Reduce,输出结果就有两个文件,第一个为part-r-00000,第二个为part-r-00001,依次类推。
OutputFormat主要用于描述输出数据的格式,它能够将用户提供的key/value对写入特定格式的文件中。 通过OutputFormat 接口,实现具体的输出格式,过程有些复杂也没有这个必要。Hadoop 自带了很多 OutputFormat 的实现,它们与InputFormat实现相对应,足够满足我们业务的需要。 OutputFormat 类的层次结构如下图所示。
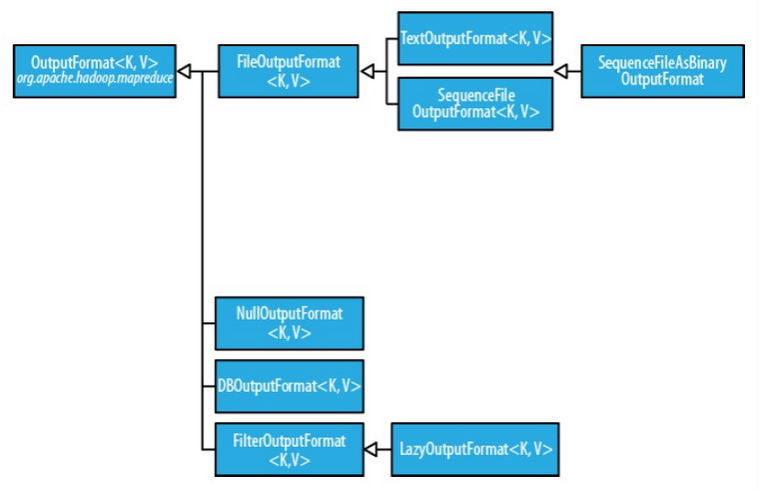
OutputFormat 是 MapReduce 输出的基类,所有实现 MapReduce 输出都实现了 OutputFormat 接口。 我们可以把这些实现接口类分为以下几种类型,分别一一介绍。
默认的输出格式是 TextOutputFormat,它把每条记录写为文本行。它的键和值可以是任意类型,因为 TextOutputFormat 调用 toString() 方法把它们转换为字符串。 每个键/值对由制表符进行分割,当然也可以设定 mapreduce.output.textoutputformat.separator 属性(旧版本 API 中的 mapred.textoutputformat.separator)改变默认的分隔符。 与 TextOutputFormat 对应的输入格式是 KeyValueTextInputFormat,它通过可配置的分隔符将键/值对文本分割。
可以使用 NullWritable 来省略输出的键或值(或两者都省略,相当于 NullOutputFormat 输出格式,后者什么也不输出)。 这也会导致无分隔符输出,以使输出适合用 TextInputFormat 读取。
1、关于SequenceFileOutputFormat
顾名思义,SequenceFileOutputFormat 将它的输出写为一个顺序文件。如果输出需要作为后续 MapReduce 任务的输入,这便是一种好的输出格式, 因为它的格式紧凑,很容易被压缩。
2、关于SequenceFileAsBinaryOutputFormat
SequenceFileAsBinaryOutputFormat 把键/值对作为二进制格式写到一个 SequenceFile 容器中。
3、关于MapFileOutputFormat
MapFileOutputFormat 把 MapFile 作为输出。MapFile 中的键必须顺序添加,所以必须确保 reducer 输出的键已经排好序。
上面我们提到,默认情况下只有一个 Reduce,输出只有一个文件。有时可能需要对输出的文件名进行控制或让每个 reducer 输出多个文件。 我们有两种方式实现reducer输出多个文件。
1、Partitioner
我们考虑这样一个需求:按学生的年龄段,将数据输出到不同的文件路径下。这里我们分为三个年龄段:小于等于20岁、大于20岁小于等于50岁和大于50岁。
我们采用的方法是每个年龄段对应一个 reducer。为此,我们需要通过以下两步实现。
第一步:把作业的 reducer 数设为年龄段数即为3。
job.setPartitionerClass(PCPartitioner.class);//设置Partitioner类 job.setNumReduceTasks(3);// reduce个数设置为3
第二步:写一个 Partitioner,把同一个年龄段的数据放到同一个分区。
public static class PCPartitioner extends Partitioner< Text, Text> {
@Override
public int getPartition(Text key, Text value, int numReduceTasks) {
// TODO Auto-generated method stub
String[] nameAgeScore = value.toString().split("\t");
String age = nameAgeScore[1];//学生年龄
int ageInt = Integer.parseInt(age);//按年龄段分区
// 默认指定分区 0
if (numReduceTasks == 0)
return 0;
//年龄小于等于20,指定分区0
if (ageInt <= 20) { return 0;
}
// 年龄大于20,小于等于50,指定分区1
if (ageInt > 20 && ageInt <= 50) { return 1 % numReduceTasks;
}
// 剩余年龄,指定分区2
else
return 2 % numReduceTasks;
}
}这种方法实现多文件输出,也只能满足此种需求。很多情况下是无法实现的,因为这样做存在两个缺点。
第一,需要在作业运行之前需要知道分区数和年龄段的个数,如果分区数很大或者未知,就无法操作。
第二,一般来说,让应用程序来严格限定分区数并不好,因为可能导致分区数少或分区不均。
2、MultipleOutputs 类
MultipleOutputs 类可以将数据写到多个文件,这些文件的名称源于输出的键和值或者任意字符串。这允许每个 reducer(或者只有 map 作业的 mapper)创建多个文件。 采用name-m-nnnnn 形式的文件名用于 map 输出,name-r-nnnnn 形式的文件名用于 reduce 输出,其中 name 是由程序设定的任意名字, nnnnn 是一个指明块号的整数(从 0 开始)。块号保证从不同块(mapper 或 reducer)写的输出在相同名字情况下不会冲突。
假如这里有一份邮箱数据文件,我们期望统计邮箱出现次数并按照邮箱的类别,将这些邮箱分别输出到不同文件路径下。数据集示例如下所示。
wolys@21cn.com zss1984@126.com 294522652@qq.com simulateboy@163.com zhoushigang_123@163.com sirenxing424@126.com lixinyu23@qq.com chenlei1201@gmail.com 370433835@qq.com cxx0409@126.com viv093@sina.com q62148830@163.com 65993266@qq.com summeredison@sohu.com zhangbao-autumn@163.com diduo_007@yahoo.com.cn fxh852@163.com
下面我们编写 MapReduce 程序,实现上述业务需求。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class Email extends Configured implements Tool {
public static class MailMapper extends Mapper< LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(value, one);
}
}
public static class MailReducer extends Reducer< Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
private MultipleOutputs< Text, IntWritable> multipleOutputs;
@Override
protected void setup(Context context) throws IOException ,InterruptedException{
multipleOutputs = new MultipleOutputs< Text, IntWritable>(context);
}
protected void reduce(Text Key, Iterable< IntWritable> Values,Context context) throws IOException, InterruptedException {
int begin = Key.toString().indexOf("@");
int end = Key.toString().indexOf(".");
if(begin>=end){
return;
}
//获取邮箱类别,比如 qq
String name = Key.toString().substring(begin+1, end);
int sum = 0;
for (IntWritable value : Values) {
sum += value.get();
}
result.set(sum);
multipleOutputs.write(Key, result, name);
}
@Override
protected void cleanup(Context context) throws IOException ,InterruptedException{
multipleOutputs.close();
}
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();// 读取配置文件
Path mypath = new Path(args[1]);
FileSystem hdfs = mypath.getFileSystem(conf);//创建输出路径
if (hdfs.isDirectory(mypath)) {
hdfs.delete(mypath, true);
}
Job job = Job.getInstance();// 新建一个任务
job.setJarByClass(Email.class);// 主类
FileInputFormat.addInputPath(job, new Path(args[0]));// 输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));// 输出路径
job.setMapperClass(MailMapper.class);// Mapper
job.setReducerClass(MailReducer.class);// Reducer
job.setOutputKeyClass(Text.class);// key输出类型
job.setOutputValueClass(IntWritable.class);// value输出类型
job.waitForCompletion(true);
return 0;
}
public static void main(String[] args) throws Exception {
String[] args0 = {
"hdfs://single.hadoop.dajiangtai.com:9000/junior/mail.txt",
"hdfs://single.hadoop.dajiangtai.com:9000/junior/mail-out/" };
int ec = ToolRunner.run(new Configuration(), new Email(), args0);
System.exit(ec);
}
}在 reducer 中,在 setup() 方法中构造一个 MultipleOutputs 的实例并将它赋给一个实例变量。在 reduce() 方法中使用 MultipleOutputs 实例来写输出, 而不是 context 。write() 方法作用于键、值、和名字。
程序运行之后,输出文件的命名如下所示。
/mail-out/163-r-00000 /mail-out/126-r-00000 /mail-out/21cn-r-00000 /mail-out/gmail-r-00000 /mail-out/qq-r-00000 /mail-out/sina-r-00000 /mail-out/sohu-r-00000 /mail-out/yahoo-r-00000 /mail-out/part-r-00000
在 MultipleOutputs 的 write() 方法中指定的基本路径相当于输出路径进行解释,因为它可以包含文件路径分隔符(/), 创建任意深度的子目录是有可能的。
DBOutputFormat 适用于将作业输出数据(中等规模的数据)转存到Mysql、Oracle等数据库。
到此,相信大家对“MapReduce的输出格式是怎样的”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。