您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
数据格式:
每一行都是字符串并且以空格分开。
代码实现:
object SparkSqlTest {
def main(args: Array[String]): Unit = {
//屏蔽多余的日志
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.project-spark").setLevel(Level.WARN)
//构建编程入口
val conf: SparkConf = new SparkConf()
conf.setAppName("SparkSqlTest")
.setMaster("local[2]")
val spark: SparkSession = SparkSession.builder().config(conf)
.enableHiveSupport()
.getOrCreate()
//创建sqlcontext对象
val sqlContext: SQLContext = spark.sqlContext
val wordDF: DataFrame = sqlContext.read.text("C:\\z_data\\test_data\\ip.txt").toDF("line")
wordDF.createTempView("lines")
val sql=
"""
|select t1.word,count(1) counts
|from (
|select explode(split(line,'\\s+')) word
|from lines) t1
|group by t1.word
|order by counts
""".stripMargin
spark.sql(sql).show()
}
}结果: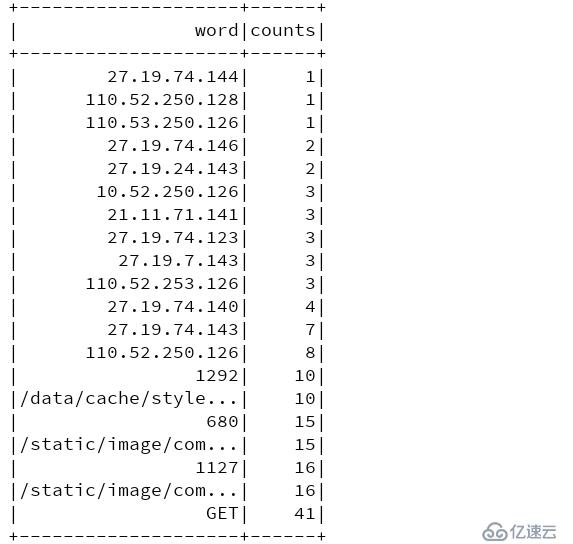
数据格式:
取每门课程中成绩最好的前三
代码实现:
object SparkSqlTest {
def main(args: Array[String]): Unit = {
//屏蔽多余的日志
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.project-spark").setLevel(Level.WARN)
//构建编程入口
val conf: SparkConf = new SparkConf()
conf.setAppName("SparkSqlTest")
.setMaster("local[2]")
val spark: SparkSession = SparkSession.builder().config(conf)
.enableHiveSupport()
.getOrCreate()
//创建sqlcontext对象
val sqlContext: SQLContext = spark.sqlContext
val topnDF: DataFrame = sqlContext.read.json("C:\\z_data\\test_data\\score.json")
topnDF.createTempView("student")
val sql=
"""select
|t1.course course,
|t1.name name,
|t1.score score
|from (
|select
|course,
|name,
|score,
|row_number() over(partition by course order by score desc ) top
|from student) t1 where t1.top<=3
""".stripMargin
spark.sql(sql).show()
}
}结果: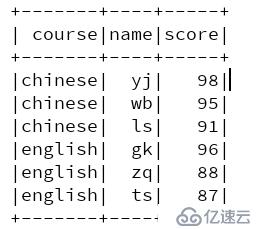
思路: (使用两阶段的聚合)
- 找到发生数据倾斜的key
- 对发生倾斜的数据的key进行拆分
- 做局部聚合
- 去后缀
- 全局聚合
以上面的wordcount为例,找出相应的数据量比较大的单词
代码实现:
object SparkSqlTest {
def main(args: Array[String]): Unit = {
//屏蔽多余的日志
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.project-spark").setLevel(Level.WARN)
//构建编程入口
val conf: SparkConf = new SparkConf()
conf.setAppName("SparkSqlTest")
.setMaster("local[2]")
val spark: SparkSession = SparkSession.builder().config(conf)
.enableHiveSupport()
.getOrCreate()
//创建sqlcontext对象
val sqlContext: SQLContext = spark.sqlContext
//注册UDF
sqlContext.udf.register[String,String,Integer]("add_prefix",add_prefix)
sqlContext.udf.register[String,String]("remove_prefix",remove_prefix)
//创建sparkContext对象
val sc: SparkContext = spark.sparkContext
val lineRDD: RDD[String] = sc.textFile("C:\\z_data\\test_data\\ip.txt")
//找出数据倾斜的单词
val wordsRDD: RDD[String] = lineRDD.flatMap(line => {
line.split("\\s+")
})
val sampleRDD: RDD[String] = wordsRDD.sample(false,0.2)
val sortRDD: RDD[(String, Int)] = sampleRDD.map(word=>(word,1)).reduceByKey(_+_).sortBy(kv=>kv._2,false)
val hot_word = sortRDD.take(1)(0)._1
val bs: Broadcast[String] = sc.broadcast(hot_word)
import spark.implicits._
//将数据倾斜的key打标签
val lineDF: DataFrame = sqlContext.read.text("C:\\z_data\\test_data\\ip.txt")
val wordDF: Dataset[String] = lineDF.flatMap(row => {
row.getAs[String](0).split("\\s+")
})
//有数据倾斜的word
val hotDS: Dataset[String] = wordDF.filter(row => {
val hot_word = bs.value
row.equals(hot_word)
})
val hotDF: DataFrame = hotDS.toDF("word")
hotDF.createTempView("hot_table")
//没有数据倾斜的word
val norDS: Dataset[String] = wordDF.filter(row => {
val hot_word = bs.value
!row.equals(hot_word)
})
val norDF: DataFrame = norDS.toDF("word")
norDF.createTempView("nor_table")
var sql=
"""
|(select
|t3.word,
|sum(t3.counts) counts
|from (select
|remove_prefix(t2.newword) word,
|t2.counts
|from (select
|t1.newword newword,
|count(1) counts
|from
|(select
|add_prefix(word,3) newword
|from hot_table) t1
|group by t1.newword) t2) t3
|group by t3.word)
|union
|(select
| word,
| count(1) counts
|from nor_table
|group by word)
""".stripMargin
spark.sql(sql).show()
}
//自定义UDF加前缀
def add_prefix(word:String,range:Integer): String ={
val random=new Random()
random.nextInt(range)+"_"+word
}
//自定义UDF去除后缀
def remove_prefix(word:String): String ={
word.substring(word.indexOf("_")+1)
}
}结果:
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。