жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
Kafka дҪңдёәдёҖдёӘжөҒејҸж•°жҚ®е№іеҸ°пјҢеҜ№ејҖеҸ‘иҖ…жҸҗдҫӣдәҶдёүз§Қе®ўжҲ·з«Ҝпјҡз”ҹдә§иҖ… / ж¶Ҳиҙ№иҖ…гҖҒиҝһжҺҘеҷЁгҖҒжөҒеӨ„зҗҶгҖӮжң¬ж–ҮзқҖйҮҚеҲҶжһҗиҝҷдёүз§Қе®ўжҲ·з«Ҝзҡ„зәҝзЁӢжЁЎеһӢгҖӮзңӢеҲ°жңҖеҗҺзҡ„йҖҡеёёйғҪжңүжғҠе–ңгҖӮ
ж¶Ҳиҙ№иҖ…зҡ„зәҝзЁӢжЁЎеһӢ
0.8 зүҲжң¬д»ҘеүҚзҡ„ж¶Ҳиҙ№иҖ…е®ўжҲ·з«ҜдјҡеҲӣе»әдёҖдёӘеҹәдәҺ ZK зҡ„ж¶Ҳиҙ№иҖ…иҝһжҺҘеҷЁпјҢдёҖдёӘж¶Ҳиҙ№иҖ…е®ўжҲ·з«ҜжҳҜдёҖдёӘ Java иҝӣзЁӢпјҢж¶Ҳиҙ№иҖ…еҸҜд»Ҙи®ўйҳ…еӨҡдёӘдё»йўҳпјҢжҜҸдёӘдё»йўҳд№ҹеҸҜд»ҘеӨҡдёӘзәҝзЁӢгҖӮдёәдәҶи®©ж¶ҲжҒҜеңЁеӨҡдёӘиҠӮзӮ№иў«еҲҶеёғејҸең°ж¶Ҳиҙ№пјҢжҸҗй«ҳж¶ҲжҒҜеӨ„зҗҶзҡ„еҗһеҗҗйҮҸпјҢKafka е…Ғи®ёеӨҡдёӘж¶Ҳиҙ№иҖ…и®ўйҳ…еҗҢдёҖдёӘдё»йўҳпјҢиҝҷдәӣж¶Ҳиҙ№иҖ…йңҖиҰҒж»Ўи¶івҖңдёҖдёӘеҲҶеҢәеҸӘиғҪиў«дёҖдёӘж¶Ҳиҙ№иҖ…дёӯзҡ„дёҖдёӘзәҝзЁӢеӨ„зҗҶвҖқзҡ„йҷҗеҲ¶жқЎд»¶гҖӮйҖҡеёёпјҢжҲ‘们дјҡе°ҶеҗҢдёҖд»ҪзӣёеҗҢдёҡеҠЎеӨ„зҗҶйҖ»иҫ‘зҡ„еә”з”ЁзЁӢеәҸйғЁзҪІеңЁдёҚеҗҢжңәеҷЁдёҠпјҢ并且жҢҮе®ҡдёҖдёӘж¶Ҳиҙ№з»„зј–еҸ·гҖӮеҪ“дёҚеҗҢжңәеҷЁдёҠзҡ„ж¶Ҳиҙ№иҖ…иҝӣзЁӢеҗҜеҠЁеҗҺпјҢжүҖжңүиҝҷдәӣж¶Ҳиҙ№иҖ…иҝӣзЁӢе°ұз»„жҲҗдәҶдёҖдёӘйҖ»иҫ‘ж„Ҹд№үдёҠзҡ„ж¶Ҳиҙ№з»„гҖӮ
ж¶Ҳиҙ№з»„дёӯзҡ„ж¶Ҳиҙ№иҖ…ж•°йҮҸжҳҜеҠЁжҖҒеҸҳеҢ–зҡ„пјҢеҪ“жңүж–°ж¶Ҳиҙ№иҖ…еҠ е…Ҙж¶Ҳиҙ№з»„пјҢжҲ–иҖ…ж—§ж¶Ҳиҙ№иҖ…зҰ»ејҖж¶Ҳиҙ№з»„пјҢйғҪдјҡи§ҰеҸ‘еҹәдәҺ ZK зҡ„ж¶Ҳиҙ№з»„вҖңеҶҚе№іиЎЎвҖқж“ҚдҪңгҖӮеҪ“вҖңеҶҚе№іиЎЎвҖқж“ҚдҪңеҸ‘з”ҹж—¶пјҢжҜҸдёӘж¶Ҳиҙ№иҖ…йғҪдјҡеңЁе®ўжҲ·з«Ҝжү§иЎҢеҲҶеҢәеҲҶй…Қз®—жі•пјҢ然еҗҺд»Һе…ЁеұҖзҡ„еҲҶй…Қз»“жһңдёӯиҺ·еҸ–еұһдәҺиҮӘе·ұзҡ„еҲҶеҢәгҖӮе®ғзҡ„зјәзӮ№жҳҜж¶Ҳиҙ№иҖ…дјҡе’Ң ZK дә§з”ҹйў‘з№Ғзҡ„дәӨдә’пјҢйҖ жҲҗ ZK йӣҶзҫӨзҡ„еҺӢеҠӣиҝҮеӨ§пјҢ并且容жҳ“дә§з”ҹзҫҠзҫӨж•Ҳеә”е’Ңи„‘иЈӮзӯүй—®йўҳгҖӮ
еңЁ 0.8 зүҲжң¬д»ҘеҗҺпјҢKafka йҮҚж–°и®ҫи®ЎдәҶе®ўжҲ·з«ҜпјҢ并且引е…ҘдәҶвҖңеҚҸи°ғиҖ…вҖқе’ҢвҖңж¶Ҳиҙ№з»„з®ЎзҗҶеҚҸи®®вҖқгҖӮж–°зҡ„ж¶Ҳиҙ№иҖ…е°ҶвҖңж¶Ҳиҙ№з»„з®ЎзҗҶеҚҸи®®вҖқе’ҢвҖңеҲҶеҢәеҲҶй…Қзӯ–з•ҘвҖқиҝӣиЎҢдәҶеҲҶзҰ»гҖӮеҚҸи°ғиҖ…иҙҹиҙЈж¶Ҳиҙ№з»„зҡ„з®ЎзҗҶпјҢиҖҢеҲҶеҢәеҲҶй…ҚеҲҷдјҡеңЁж¶Ҳиҙ№з»„зҡ„дёҖдёӘдё»ж¶Ҳиҙ№иҖ…дёӯе®ҢжҲҗгҖӮйҮҮз”Ёиҝҷз§Қж–№ејҸпјҢжҜҸдёӘж¶Ҳиҙ№иҖ…йғҪйңҖиҰҒеҸ‘йҖҒдёӢйқўдёӨз§ҚиҜ·жұӮз»ҷеҚҸи°ғиҖ…гҖӮ
еҠ е…Ҙз»„иҜ·жұӮпјҡеҚҸи°ғиҖ…收йӣҶж¶Ҳиҙ№з»„зҡ„жүҖжңүж¶Ҳиҙ№иҖ…пјҢ并йҖүдёҫдёҖдёӘдё»ж¶Ҳиҙ№иҖ…жү§иЎҢеҲҶеҢәеҲҶй…Қе·ҘдҪңгҖӮ
еҗҢжӯҘз»„иҜ·жұӮпјҡдё»ж¶Ҳиҙ№иҖ…е®ҢжҲҗеҲҶеҢәеҲҶй…ҚпјҢз”ұеҚҸи°ғиҖ…е°ҶеҲҶеҢәзҡ„еҲҶй…Қз»“жһңдј ж’ӯз»ҷжҜҸдёӘж¶Ҳиҙ№иҖ…гҖӮ
ж–°зүҲжң¬зҡ„ж¶Ҳиҙ№иҖ…е®ўжҲ·з«Ҝеј•е…ҘдәҶдёҖдёӘе®ўжҲ·з«ҜеҚҸи°ғиҖ…зҡ„жҠҪиұЎзұ»пјҢе®ғзҡ„е®һзҺ°йҷӨдәҶж¶Ҳиҙ№иҖ…зҡ„еҚҸи°ғиҖ…пјҢиҝҳжңүдёҖдёӘиҝһжҺҘеҷЁзҡ„е®һзҺ°гҖӮ
иҝһжҺҘеҷЁзҡ„зәҝзЁӢжЁЎеһӢ
Kafka иҝһжҺҘеҷЁзҡ„еҮәзҺ°ж ҮеҮҶеҢ–дәҶ Kafka дёҺеҗ„з§ҚеӨ–йғЁеӯҳеӮЁзі»з»ҹзҡ„ж•°жҚ®еҗҢжӯҘгҖӮз”ЁжҲ·ејҖеҸ‘е’ҢдҪҝз”ЁиҝһжҺҘеҷЁе°ұеҸҳеҫ—йқһеёёз®ҖеҚ•пјҢеҸӘйңҖиҰҒеңЁй…ҚзҪ®ж–Ү件дёӯе®ҡд№үиҝһжҺҘеҷЁпјҢе°ұеҸҜд»Ҙе°ҶеӨ–йғЁзі»з»ҹзҡ„ж•°жҚ®еҜје…Ҙ Kafka жҲ–е°Ҷ Kafka ж•°жҚ®еҜјеҮәеҲ°еӨ–йғЁзі»з»ҹгҖӮеҰӮеӣҫ 1 жүҖзӨәпјҢдёӯй—ҙйғЁеҲҶйғҪжҳҜ Kafka иҝһжҺҘеҷЁзҡ„еҶ…йғЁз»„件пјҢеҢ…жӢ¬жәҗиҝһжҺҘеҷЁпјҲSource Connectorпјүе’Ңзӣ®ж ҮиҝһжҺҘеҷЁпјҲSink ConnectorпјүгҖӮ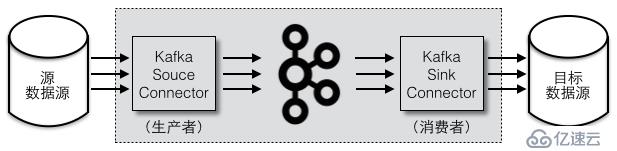
еӣҫ 1 Kafka иҝһжҺҘеҷЁзҡ„жәҗиҝһжҺҘеҷЁдёҺзӣ®ж ҮиҝһжҺҘеҷЁ
Kafka иҝһжҺҘеҷЁзҡ„еҚ•жңәжЁЎејҸдјҡеңЁдёҖдёӘиҝӣзЁӢеҶ…еҗҜеҠЁдёҖдёӘ Worker д»ҘеҸҠжүҖжңүзҡ„иҝһжҺҘеҷЁе’Ңд»»еҠЎгҖӮеҲҶеёғејҸжЁЎејҸзҡ„жҜҸдёӘиҝӣзЁӢйғҪжңүдёҖдёӘ WorkerпјҢиҖҢиҝһжҺҘеҷЁе’Ңд»»еҠЎеҲҷеҲҶеҲ«иҝҗиЎҢеңЁеҗ„дёӘиҠӮзӮ№дёҠгҖӮеӣҫ 2 еҲ—дёҫдәҶиҝһжҺҘеҷЁе’Ңд»»еҠЎеңЁдёҚеҗҢ Worker дёҠзҡ„еӣӣз§ҚеҲҶеёғж–№ејҸпјҡ
дёҖдёӘ WorkerпјҢдёҖдёӘжәҗд»»еҠЎгҖҒдёҖдёӘзӣ®ж Үд»»еҠЎ
дёҖдёӘ WorkerпјҢдёӨдёӘжәҗд»»еҠЎгҖҒдёӨдёӘзӣ®ж Үд»»еҠЎ
дёӨдёӘ WorkerпјҢдёӨдёӘжәҗд»»еҠЎгҖҒдёӨдёӘзӣ®ж Үд»»еҠЎ
дёүдёӘ WorkerпјҢдёӨдёӘжәҗд»»еҠЎгҖҒдёӨдёӘзӣ®ж Үд»»еҠЎ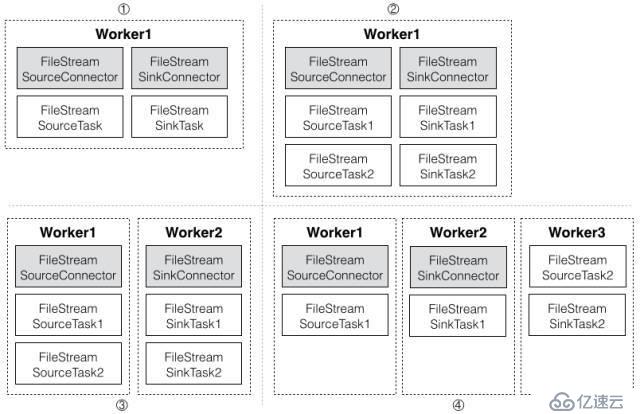
еӣҫ 2 еҲҶеёғејҸжЁЎејҸзҡ„ Kafka иҝһжҺҘеҷЁйӣҶзҫӨ
еҲҶеёғејҸжЁЎејҸдёӢпјҢдёҚеҗҢ Worker иҝӣзЁӢд№Ӣй—ҙзҡ„еҚҸи°ғе·ҘдҪңзұ»дјјдәҺж¶Ҳиҙ№иҖ…зҡ„еҚҸи°ғгҖӮж¶Ҳиҙ№иҖ…йҖҡиҝҮеҚҸи°ғиҖ…иҺ·еҸ–еҲҶй…Қзҡ„еҲҶеҢәпјҢWorker д№ҹдјҡйҖҡиҝҮеҚҸи°ғиҖ…иҺ·еҸ–еҲҶй…Қзҡ„иҝһжҺҘеҷЁдёҺд»»еҠЎгҖӮеҰӮеӣҫ 3 жүҖзӨәпјҢж¶Ҳиҙ№иҖ…е®ўжҲ·з«Ҝе’Ң Worker е®ўжҲ·з«ҜдёәдәҶеҠ е…ҘеҲ°з»„з®ЎзҗҶдёӯпјҢеҲҶеҲ«йҖҡиҝҮе®ўжҲ·з«Ҝзҡ„еҚҸи°ғиҖ…еҜ№иұЎжқҘе’ҢжңҚеҠЎз«Ҝзҡ„ж¶Ҳиҙ№з»„еҚҸи°ғпјҲGroupCoordinatorпјүйҖҡдҝЎгҖӮ
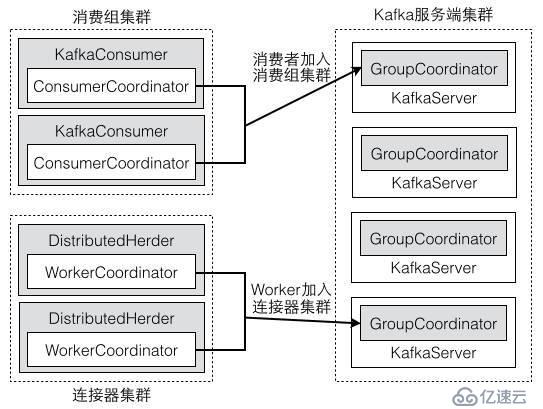
еӣҫ 3 ж¶Ҳиҙ№иҖ…е’Ң Worker зҡ„е·ҘдҪңйғҪжҳҜйҖҡиҝҮеҚҸи°ғиҖ…еҲҶй…Қзҡ„
жөҒеӨ„зҗҶзҡ„зәҝзЁӢжЁЎеһӢ
Kafka жөҒеӨ„зҗҶзҡ„е·ҘдҪңжөҒзЁӢз®ҖеҚ•жқҘзңӢеҲҶжҲҗдёүдёӘжӯҘйӘӨпјҡж¶Ҳиҙ№иҖ…иҜ»еҸ–иҫ“е…ҘеҲҶеҢәзҡ„ж•°жҚ®гҖҒжөҒејҸең°еӨ„зҗҶжҜҸжқЎж•°жҚ®гҖҒз”ҹдә§иҖ…е°ҶеӨ„зҗҶз»“жһңеҶҷе…Ҙиҫ“еҮәеҲҶеҢәпјҢиҝҷйҮҢйқўжӯҘйӘӨ 1 д№ҹе……еҲҶеҲ©з”ЁдәҶвҖңж¶Ҳиҙ№з»„з®ЎзҗҶеҚҸи®®вҖқгҖӮKafka жөҒеӨ„зҗҶзҡ„иҫ“е…Ҙж•°жҚ®жәҗеҹәдәҺе…·жңүеҲҶеёғејҸеҲҶеҢәжЁЎеһӢзҡ„ Kafka дё»йўҳпјҢе®ғзҡ„зәҝзЁӢжЁЎеһӢдё»иҰҒз”ұдёӢйқўдёүдёӘзұ»з»„жҲҗпјҡ
жөҒе®һдҫӢпјҲKafkaStreamsпјүпјҡйҖҡеёёдёҖдёӘиҠӮзӮ№пјҲдёҖеҸ°жңәеҷЁпјүеҸӘиҝҗиЎҢдёҖдёӘжөҒе®һдҫӢгҖӮ
жөҒзәҝзЁӢпјҲStreamThreadпјүпјҡдёҖдёӘжөҒе®һдҫӢеҸҜд»Ҙй…ҚзҪ®еӨҡдёӘжөҒзәҝзЁӢгҖӮ
жөҒд»»еҠЎпјҲStreamTaskпјүпјҡдёҖдёӘжөҒзәҝзЁӢеҸҜд»ҘиҝҗиЎҢеӨҡдёӘжөҒд»»еҠЎпјҢж №жҚ®иҫ“е…Ҙдё»йўҳзҡ„еҲҶеҢәж•°зЎ®е®ҡд»»еҠЎж•°гҖӮ
еҰӮеӣҫ 4 жүҖзӨәпјҢиҫ“е…Ҙдё»йўҳжңүе…ӯдёӘеҲҶеҢәпјҢKafka жөҒеӨ„зҗҶжҖ»е…ұе°ұдјҡдә§з”ҹе…ӯдёӘжөҒд»»еҠЎгҖӮжөҒе®һдҫӢеҸҜд»ҘеҠЁжҖҒжү©еұ•пјҢжөҒзәҝзЁӢзҡ„дёӘж•°д№ҹеҸҜд»ҘеҠЁжҖҒй…ҚзҪ®гҖӮеӣҫдёӯдёҖе…ұжңүдёүдёӘжөҒзәҝзЁӢпјҢеҲҷжҜҸдёӘжөҒзәҝзЁӢдјҡжңүдёӨдёӘжөҒд»»еҠЎпјҢжҜҸдёӘжөҒд»»еҠЎйғҪеҜ№еә”иҫ“е…Ҙдё»йўҳзҡ„дёҖдёӘеҲҶеҢәгҖӮ
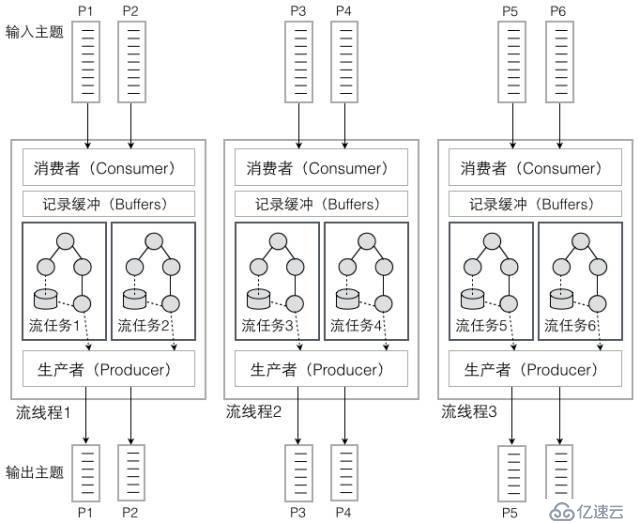
еӣҫ 4 Kafka жөҒеӨ„зҗҶзҡ„зәҝзЁӢжЁЎеһӢ
Kafka зҡ„жөҒеӨ„зҗҶжЎҶжһ¶дҪҝ用并иЎҢзҡ„зәҝзЁӢжЁЎеһӢеӨ„зҗҶиҫ“е…Ҙдё»йўҳзҡ„ж•°жҚ®йӣҶпјҢиҝҷз§Қи®ҫи®ЎжҖқи·Ҝе’Ң Kafka зҡ„ж¶Ҳиҙ№иҖ…зәҝзЁӢжЁЎеһӢйқһеёёзұ»дјјгҖӮж¶Ҳиҙ№иҖ…еҲҶй…ҚеҲ°и®ўйҳ…дё»йўҳзҡ„дёҚеҗҢеҲҶеҢәпјҢжөҒеӨ„зҗҶжЎҶжһ¶зҡ„жөҒд»»еҠЎд№ҹеҲҶй…ҚеҲ°иҫ“е…Ҙдё»йўҳзҡ„дёҚеҗҢеҲҶеҢәгҖӮеҰӮеӣҫ 5 жүҖзӨәпјҢиҫ“е…Ҙдё»йўҳ 1 зҡ„еҲҶеҢә P1 е’Ңиҫ“е…Ҙдё»йўҳ 2 зҡ„еҲҶеҢә P1 еҲҶй…Қз»ҷжөҒзәҝзЁӢ 1 зҡ„жөҒд»»еҠЎпјҢиҫ“е…Ҙдё»йўҳ 1 зҡ„еҲҶеҢә P2 е’Ңиҫ“е…Ҙдё»йўҳ 2 зҡ„еҲҶеҢә P2 еҲҶй…Қз»ҷжөҒзәҝзЁӢ 2 зҡ„жөҒд»»еҠЎгҖӮжөҒеӨ„зҗҶзӣёжҜ”ж¶Ҳиҙ№иҖ…пјҢиҝҳдјҡе°ҶжӢ“жү‘зҡ„и®Ўз®—з»“жһңеҶҷеҲ°иҫ“еҮәдё»йўҳгҖӮ
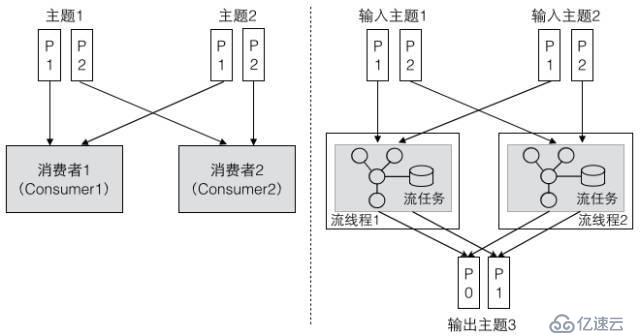
еӣҫ 5 ж¶Ҳиҙ№иҖ…жЁЎеһӢдёҺжөҒеӨ„зҗҶзҡ„зәҝзЁӢжЁЎеһӢ
ж¶Ҳиҙ№иҖ…е’ҢжөҒеӨ„зҗҶзҡ„ж•…йҡңе®№й”ҷжңәеҲ¶д№ҹжҳҜзұ»дјјзҡ„гҖӮеҰӮеӣҫ 6 жүҖзӨәпјҢеҒҮи®ҫж¶Ҳиҙ№иҖ… 2 иҝӣзЁӢжҢӮжҺүпјҢе®ғжүҖжҢҒжңүзҡ„еҲҶеҢәдјҡиў«еҲҶй…Қз»ҷеҗҢдёҖдёӘж¶Ҳиҙ№з»„дёӯзҡ„ж¶Ҳиҙ№иҖ… 1пјҢиҝҷж ·ж¶Ҳиҙ№иҖ… 1 дјҡеҲҶй…ҚеҲ°и®ўйҳ…дё»йўҳзҡ„жүҖжңүеҲҶеҢәгҖӮеҜ№дәҺжөҒеӨ„зҗҶиҖҢиЁҖпјҢеҰӮжһңжөҒзәҝзЁӢ 2 жҢӮжҺүдәҶпјҢжөҒзәҝзЁӢ 2 дёӯзҡ„жөҒд»»еҠЎдјҡеҲҶй…Қз»ҷжөҒзәҝзЁӢ 1гҖӮеҚіжөҒзәҝзЁӢ 1 дјҡиҝҗиЎҢдёӨдёӘжөҒд»»еҠЎпјҢжҜҸдёӘжөҒд»»еҠЎеҲҶй…Қзҡ„еҲҶеҢәд»Қ然дҝқжҢҒдёҚеҸҳгҖӮ
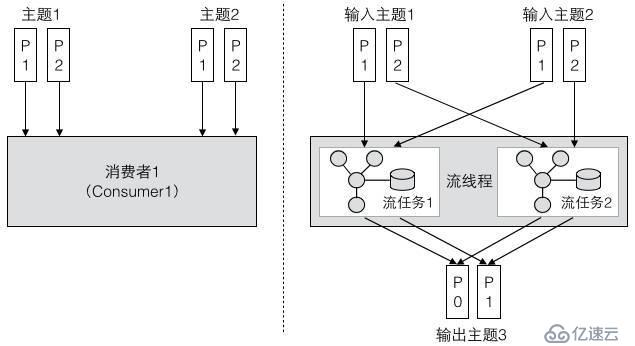
еӣҫ 6 ж¶Ҳиҙ№иҖ…дёҺжөҒеӨ„зҗҶзҡ„ж•…йҡңе®№й”ҷжңәеҲ¶
е°Ҹ з»“
Kafka е®ўжҲ·з«ҜжҠҪиұЎеҮәжқҘзҡ„зҡ„вҖңз»„з®ЎзҗҶеҚҸи®®вҖқе……еҲҶиҝҗз”ЁеңЁж¶Ҳиҙ№иҖ…гҖҒиҝһжҺҘеҷЁгҖҒжөҒеӨ„зҗҶдёүдёӘдҪҝз”ЁеңәжҷҜдёӯгҖӮе®ўжҲ·з«Ҝдёӯзҡ„ж¶Ҳиҙ№иҖ…гҖҒиҝһжҺҘеҷЁдёӯзҡ„е·ҘдҪңиҖ…гҖҒжөҒеӨ„зҗҶдёӯзҡ„жөҒиҝӣзЁӢйғҪеҸҜд»ҘзңӢеҒҡвҖңз»„вҖқзҡ„дёҖдёӘжҲҗе‘ҳгҖӮеҪ“еўһеҠ жҲ–еҮҸе°‘з»„жҲҗе‘ҳж—¶пјҢеңЁиҝҷдёӘеҚҸи®®зҡ„зәҰжқҹдёӢпјҢжҜҸдёӘз»„жҲҗе‘ҳйғҪеҸҜд»ҘиҺ·еҸ–еҲ°жңҖж–°зҡ„д»»еҠЎпјҢд»ҺиҖҢеҒҡеҲ°ж— зјқзҡ„д»»еҠЎиҝҒ移гҖӮдёҖж—ҰзҗҶи§ЈдәҶвҖңз»„з®ЎзҗҶеҚҸи®®вҖқпјҢеҜ№дәҺзҗҶи§Ј Kafka зҡ„жһ¶жһ„и®ҫи®ЎжҳҜеҫҲжңүеё®еҠ©зҡ„гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ