您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
为什么需要sequenceId?
HBase数据在写入的时候首先追加写入HLog,再写入Memstore,也就是说一份数据会以两种不同的形式存在于两个地方。那两个地方的同一份数据需不需要一种机制将两者关联起来?有的朋友要问为什么需要关联这两者,那笔者这里提出三个相关问题:
Memstore中的数据flush到HDFS文件中后HLog对应的数据是不是就可以被删除了?不然HLog会无限增长!那问题来了,Memstore中被flush到HDFS的数据,如何映射到HLog中的相关日志数据?
HBase中单个HLog都有固定大小,日志文件最大个数也是固定设置的,默认最大HLog文件数量为8。如果日志数量超过这个数量,就必须删除最老的HLog日志。那问题来了,如何知道待删除HLog日志对应的所有数据都已经落盘了?(如果知道哪些数据没有落盘,就可以强制对其执行flush,之后就可以将HLog删除)
这三个问题从本质上来讲是一个问题,都需要一种介质来表示Memstore中数据Flush的那个点对应HLog哪个位置,这个介质就是本文要介绍的重点-sequenceId
HLog日志核心结构
要理解sequenceId,需要简单了解HBase中HLog文件的基本结构,如下图所示,关注点主要有两点:
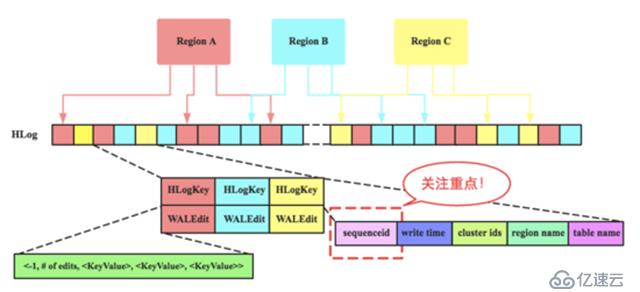
每个RegionServer拥有一个或多个HLog(默认只有1个,1.x版本可以开启 MultiWAL 功能,允许多个HLog)。 每个HLog是多个Region共享的 ,如图所示,Region A、Region B和Region C共享一个HLog文件。
什么是sequenceid?
sequenceid是region级别一次行级事务的自增序号。这个定义是我琢磨出来的,需要关注的地方有三个:
sequenceid是自增序号。很好理解,就是随着时间推移不断自增,不会减小。
sequenceid是一次行级事务的自增序号。行级事务是什么?简单点说,就是更新一行中的多个列族、多个列,行级事务能够保证这次更新的原子性、一致性、持久性以及设置的隔离性,HBase会为一次行级事务分配一个自增序号。
在这样的定义条件下,HLog就会如下图所示:
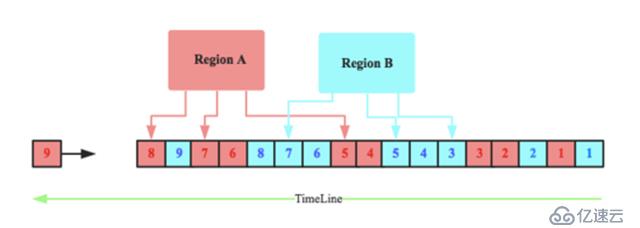
HLog中有两个Region的日志记录,方框中的数字表示sequenceid,随着时间的推移,每个region的sequenceid都独立自增。
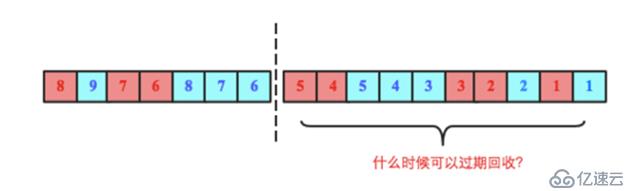
问题一:HLog在什么时候可以过期回收?
下图中虚线右侧部分为超过单个HLog大小阈值后切分形成的一个HLog文件,问题是这个文件什么时候可以被系统回收删除。理论上来说只需要这个文件上所有Region对应的最大sequenceid已经落盘就可以删除,比如下图中如果RegionA对应的最大sequenceid(5)已经落盘,同时RegionB对应的最大sequenceid(5)也落盘,那该HLog就可以被删除。那怎么实现的呢?
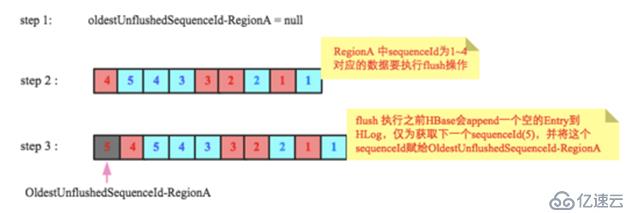
RegionServer会为每个Region维护了一个变量oldestUnflushedSequenceId(实际上是为每个Store,为了方便讲解,此处暂且认为是Region,不影响原理),表示这个Region最早的还未落盘的seqid ,即这个seqid之前的所有数据都已经落盘。接下来看看这个值在flush的时候是怎么维护的,以及如何用这个值实现HLog的过期回收判断。
下图是flush过程中oldestUnflushedSequenceId变量变化的示意图,初始时为null,假设在某一时刻阶段二RegionA(红色方框)要执行flush,中间HLog中sequenceId为1~4对应的数据将会落盘,在执行flush之前,HBase会append一个空的Entry到HLog,仅为获取下一个sequenceId(5),并将这个sequenceId赋给OldestUnflushedSequenceId-RegionA。如图中第三阶段OldestUnflushedSequenceId-RegionA指向sequenceId为5的Entry。
可见,每次flush之后这个变量就会往前移动一段距离。这个变量至关重要,是解决文初提到的三个问题的关键。基于上述对这个变量的理解,来看看下面两种场景下右侧HLog是否可以删除:
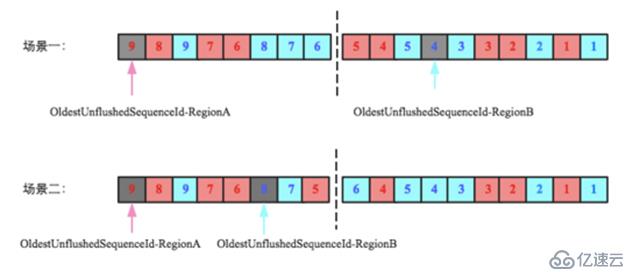
很显然,场景一中右侧HLog还有未落盘的数据(sequenceid=5还未落盘),因此不能删除;而场景二中右侧HLog的所有数据都已经落盘,所以这个HLog理论上就已经可以被删除回收。
问题二:HLog数量超过阈值(maxlogs)之后删除最早HLog,应该强制刷新哪些Region?
假设当前系统设置了HLog的最大数量为32,即hbase.regionserver.maxlogs=32,上图中最左侧HLog是第33个,此时系统会获取到最老的日志(最右侧HLog),并检查所有的Entry对应的数据是否都已经落盘,如图所示RegionC还有部分数据没有落地,为了安全删除这个HLog就必须强制对该Region执行flush操作,将所有数据落盘。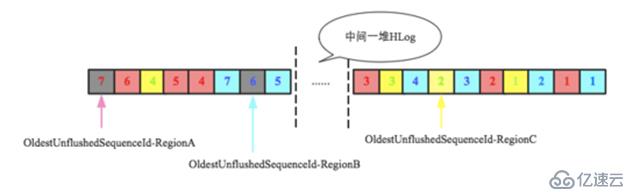
问题三:RegionServer宕机恢复replay日志时哪些WALEntry需要被回放,哪些会被skip?
理论上来说只需要回放Memstore中没有落地的数据对应的WALEntry,已经落地数据对应的WALEntry可以skip。可问题是RegionServer已经宕机了, 对应信息肯定没有了,如何是好?想办法持久化呗,上文分析oldestUnflushedSequenceId变量是flush时产生的一个变量,这个变量 完全 可以以flush的时候以元数据的形式写到HFile中 (代码见下图):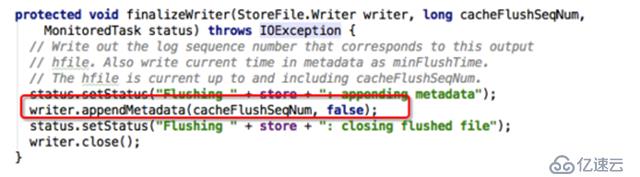
这样Region在宕机迁移重新打开之后加载HFile元数据就可以恢复出这个核心变量oldestUnflushedSequenceId(本次flush所生成的所有HFlie中都存储同一个sequenceId),这个sequenceId在恢复出来之后就可以用来在回放WALEntry的时候过滤哪些Entry需要被回放,哪些会被skip。
这里提一个问题:有没有可能一次flush所生成的所有HFile中存储的sequenceId出现不一致,比如:region中所有store(store1、store2)都执行flush,其中store1执行flush成功,此时oldestUnflushedSequenceId变量成功追加到对应的HFile中;但在store2执行flush之前RegionServer发生宕机异常,store2对应的oldestUnflushedSequenceId变量还是上个文件对应的sequenceId,这种情况下回放数据会不会有影响?如果有,为什么?如果没有,是什么机制保证的?
到目前为止,上面所有分析都基于一个事实:hbase中flush操作是region级别操作,即每次执行flush都需要整个region中的所有store全都执行flush。接下来作为延伸阅读内容,对Per-CF Flush比较感兴趣的可以继续阅读,Per-CF Flush允许系统对某个或某些列组单独执行flush。实现原理与上文所分析内容基本相似。不同的是上文中 oldestUnflushedSequenceId是与region一一对应的,Per-CF Flush中这个参数需要细化到store,与store一一对应。
延伸阅读:Per-CF Flush
region级别flush确实存在不少问题,在多个列族的情况下其中一个store大小超过了阈值(128M),不论其他store多大多小都会强制落盘,有些很小的列族(几兆)落盘后形成很多特别小的文件,对hbase的读并不是一件好事。
per-cf flush允许单个store执行flush,该feature在1.0.0以上版本已经存在,在1.2.0版本设置为默认策略。 实现这个功能有两个必要的工作,其一是提出一种新的flush策略能够在多个列族中选择一个或者多个单独进行进行flush,目前新策略称为FlushLargerStoresPolicy,即选择当前最大的一个store进行flush。其二是必须将oldestUnflushedSequenceId的粒度从region细化到store,即从map改为map>,上文所述三个问题的判断逻辑也需要修改为store级别判断逻辑。这里使用store级别判断逻辑简单对问题一和问题三进行复盘。
Per-CF Flush策略下,HLog在什么时候可以过期回收?
region级别的判断逻辑主要依赖于map,详见上文。store级别的数据结构改为了map>,其实很容易经过简单的转化又变回region级别,map找到最小的oldestUnflushedSequenceId称为minSeqNum,这样region级别的数据结构就变出来了 – map,其他逻辑都不用变。
Per-CF Flush策略下,RegionServer宕机恢复replay日志时哪些数据需要被回放,哪些会被skip?
这个问题稍微复杂一点,第一个关注的问题是回放粒度的问题。需要回过头来看看HLog中Entry的组成,如图可以知道一个Entry由WALKey和WAKEdit两部分构成,WALKey包含一些基本信息,本文重点关注sequenceId这个变量; WALEdit包含插入\更新的KeyValue集合,这里需要重点注意, 这些KeyValue可能包含一行中多个列族(列),因此可以说WALEdit会包含多个store更新的KeyValue 。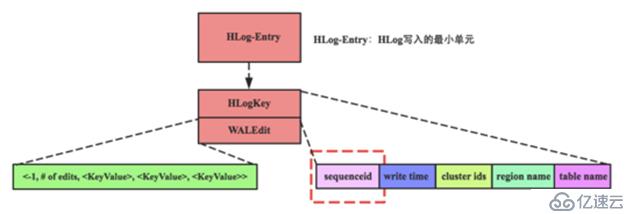
在All-CF Flush策略下,我们以HLog-Entry为粒度进行数据回放没有任何问题,但是在Per-CF Flush策略下就不再行得通。因为一个HLog-Entry中多个CF的KeyValue是混在一起的,可能部分KV已经落盘,其他部分还没有。因此需要将回放粒度减小到KeyValue级别,一个一个KeyValue分别进行检查回放。
回放粒度问题摸清了,再来关注哪些KeyValue需要被回放,哪些会被skip。上文说过,每次flush的时候对应的oldestUnflushedSequenceId会被持久化到HFile的元数据中。在All-CF Flush策略下,一次flush操作中整个region所有store所持久化的oldestUnflushedSequenceId都相同,因此回放的时候HLog-Entry的sequenceId只需要与这一个oldestUnflushedSequenceId比较就可以,大的话就需要回放,小的话就skip。但在Per-CF的场景下又不再行得通,一个region中不同store都有自己独立的oldestUnflushedSequenceId,因此回放的时候需要根据KeyValue找到对应store,在与该store中的oldestUnflushedSequenceId比较,大的话需要回放,小的话skip。
总结起来就是:skip hlog cells per store when replaying,注意这里蕴含两个点: hlog cells 以及 per store。
全文总结
本文从hbase中非常重要的一个变量(sequenceId)入手,将其所涉及到的WAL模块、Flush模块分别进行了说明。文中只讲了一个大概,很多细节知识并没有深究,有兴趣的同学可以根据文中所讲内容深入源码,相信会比较容易。接下来笔者将会继续根据sequenceId这个话题分析HBase中MVCC机制,敬请期待!
为了帮助大家让学习变得轻松、高效,给大家免费分享一大批资料,帮助大家在成为大数据工程师,乃至架构师的路上披荆斩棘。在这里给大家推荐一个大数据学习交流圈:658558542 欢迎大家进×××流讨论,学习交流,共同进步。
当真正开始学习的时候难免不知道从哪入手,导致效率低下影响继续学习的信心。
但最重要的是不知道哪些技术需要重点掌握,学习时频繁踩坑,最终浪费大量时间,所以有有效资源还是很有必要的。
最后祝福所有遇到瓶疾且不知道怎么办的大数据程序员们,祝福大家在往后的工作与面试中一切顺利
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。