您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
一、摘要
随着互联网的高速发展,数据量爆发式增长的同时,数据的存储形式也开始呈现出多样性,有结构化存储,如 Mysql, Oracle, SQLServer 等,半结构化甚至非结构化存储,如HBase,OSS 等。那么从事数据分析的人员就面临着从多种多样的数据存储形式中提取数据而后进行多维分析,这将是一件非常具有挑战的事情。而Quick BI 作为新一代智能BI服务平台,恰好解决了这一难题,不仅支持多种结构化数据源的多维分析,也支持本地文件上传后的查询分析,同时还支持部分非结构化数据源的OLAP分析,甚至支持混合异构数据源的关联分析。
Quick BI 目前支持的数据源既可以来自阿里云数据库,也可以来自自建数据库,如下所示:



二、结构化数据源多维分析
对于一般的数据源,用户在做多维分析之前需要先在Quick BI 数据源界面添加自己的数据源,比如MySQL数据源,如下:

数据源添加完成后,可以选择一张或多张要进行分析的数据表创建一个数据集,如下:
数据集创建完成后用户就可以在仪表板里拖拽维度和度量进行多维分析了,比如: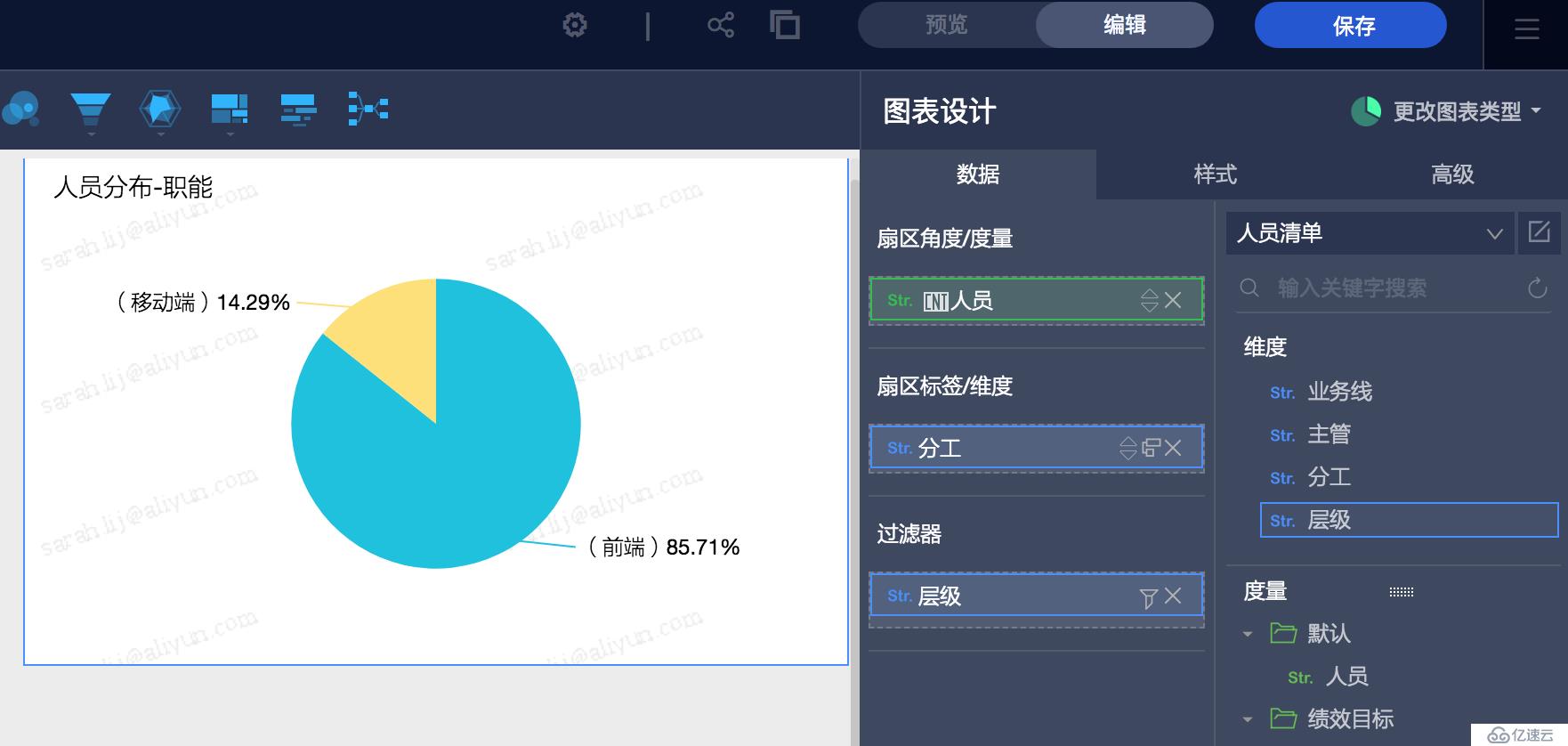
结构化数据源的多维分析相对比较简单,大致过程就是针对每次多维分析查询,根据用户选择的维度,度量及过滤条件等查询因子,生成相应结构化数据源的方言SQL,然后通过执行机下发到用户自己的数据库去执行该SQL,最后Quick BI接收返回的查询结果进行可视化展现。下图展示了多维分析的流程图: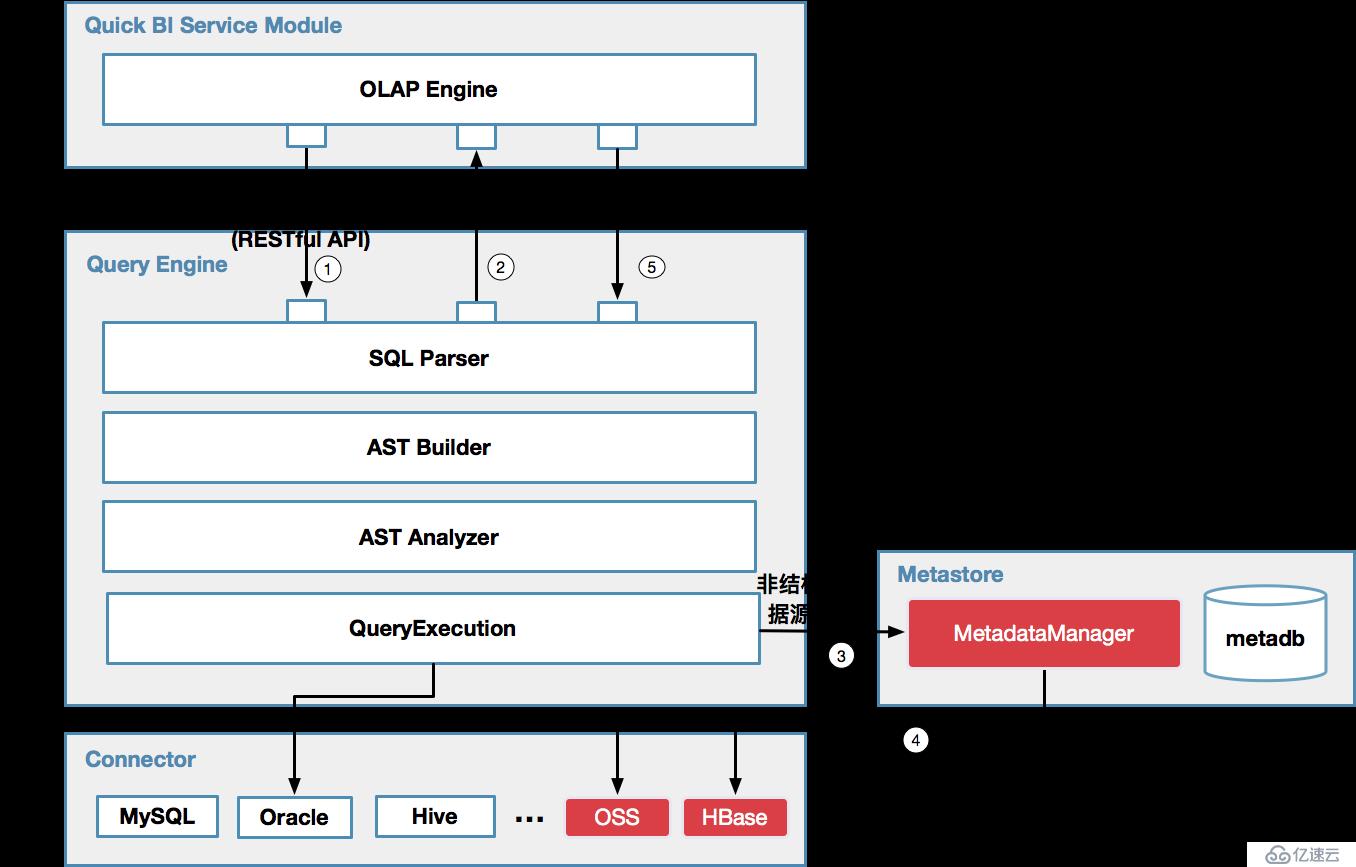
顺便介绍一下,本地文件上传支持csv 和Excel 两种文件类型。上传后的文件会落地到Quick BI提供的一种官方数据源:探索空间。探索空间底层依赖了一种阿里云自研的MPP SQL引擎,提供存储+计算服务。
接下来的篇幅将着重介绍非结构化查询分析及混合异构数据源关联分析的原理。
三、非结构化数据源查询分析
3.1 背景
近年来部分大型企业更倾向于采用诸如半结构化存储(HBase),对象存储(OSS)等能容纳较大数据规模的数据库。如何有效地帮助企业对此类数据源进行多维数据分析是目前业界BI产品的一项挑战。
在开源的数据库产品当中,存在着一些潜在的解决方案。例如,针对HDFS数据的查询,Hive设计了metastore组件,专门用于存储元数据,解决了从结构化查询到非结构化数据之间的映射关系,用户通过使用创建外部表SQL的语法,可以更灵活地自定义映射的方式。另外,Apache Phoenix也采取了类似的方式让用户能够使用SQL语句对HBase中的数据进行查询。经过充分调研后,针对Quick BI产品自身的业务场景,结合开源计算引擎二次开发了一套用于非结构化查询的分析引擎。
3.2 技术原理
对非结构化数据源进行OLAP查询,其关键在于支持SQL语法形式的数据查询。Quick BI在OLAP引擎内部采用创建外部表的SQL语法,给用户提供了一种自定义的,从非结构化数据到结构化存储的映射方式。对于诸如MySQL、Oracle等结构化的数据源而言,无须额外的元数据信息,而对于非结构化的数据源,需要提供额外的元数据信息。Metastore维护了所有非结构化数据源的元数据信息,元数据信息中反映了非结构化数据到结构化之间的映射方式。Metadb中包含了3张表,用于定义可以被SQL查询所需要的元数据信息,如下图所示:
Schems、Tables和Columns分别定义了外部表的结构,通过SQL创建外部表时,在其中加入相应的记录。查询非结构化数据源时,再读取相应的记录,对数据进行解析。
下面以一个场景作为例子,进一步地说明非结构化查询的过程,假设用户以CSV文件的形式将业务数据存储在OSS上,文件的名称为iris.csv,其内容如下所示: 
针对这个文件,用户期望利用Quick BI对其进行OLAP查询,根据用户在Quick BI数据源页面中的配置,OLAP内部生成一条创建外部表的SQL语句:
SQL Parser对SQL进行解析,AST Builder生成对应的AST,如下图所示: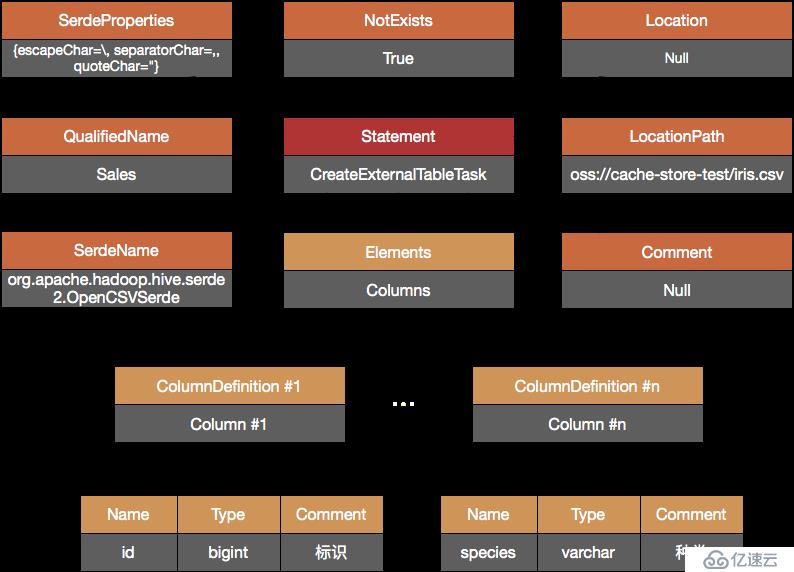
注意到该AST包含了外部表所需的全部信息,包括如何解析csv文件并映射成结构化的数据,使得数据能够与SQL中的schema、column和table对应。Query Execution调用Metastore将信息存储至Meatadb。此时,存储再OSS上的CSV文件在逻辑上已经映射成了一张表,如下图所示:

下一步便可以直接使用SQL对其进行查询,例如,使用下面的SQL筛选出种类(species)为setosa的数据记录;
同理,对于HBase数据源,同样采用外部表的方式定义映射规则: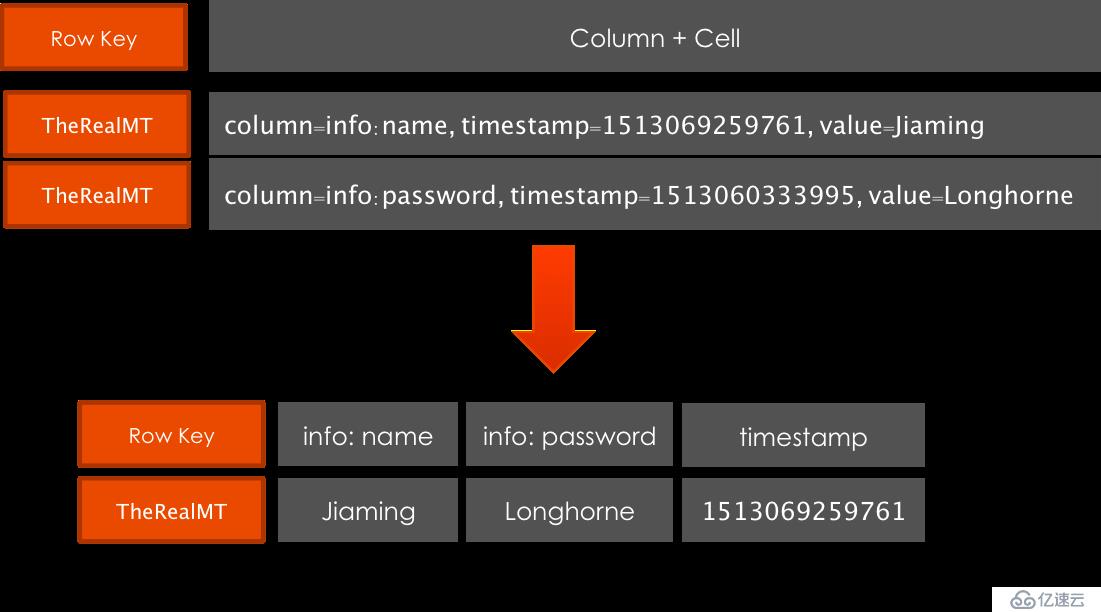
3.3 小结
Quick BI 目前支持对OSS上的csv 文件进行查询分析,后续会增加支持OSS上更多文件类型的查询分析,及对HBase的多维分析。
四、混合异构数据源关联分析
4.1 背景
Quick BI用户对异构数据源的分析需求,如:维表在MySQL,事实表在MaxCompute时,需要进行不同类型数据源间或相同类型数据源不同库间表的关联分析。
4.2 技术原理
要能够支持异构数据源间的跨源关联分析,首先需要有一款具备数据源Connector 插件机制的计算引擎,这样就能够方便扩展支持多种数据源类型查询。我们从业界开源计算引擎中选择了一款具备这样特性的MPP内存计算引擎,经过二次开发,形成了一套适合Quick BI业务场景的跨源查询引擎。
跨源查询引擎在支持异构数据源查询时,只需在查询SQL中使用完整的catalogName.dbName.tableName表名(如:odps.quickbi_test.company_sales_record),
在Quick BI业务中用户自己配置的每个数据源在后台都会配一个唯一标识dsId, 所以刚好可以用来作为catalogName, 且涉及到的Catalog在跨源查询引擎中已经被加载即可。之后在查询时,跨源查询引擎会解析SQL,生成逻辑计划、物理计划,再通过Catalog的配置到指定数据源加载数据,在内存中进行计算并返回最终结果。
大部分多维分析都是单源查询,那么在什么情况下才会启用跨源查询引擎呢,这就需要实现异构数据源查询的智能路由,智能路由主要是根据查询模型中涵盖的数据源信息来判断是单源查询还是多源查询来决定路由到单源查询引擎还是跨源查询引擎。跨源查询流程如下图所示: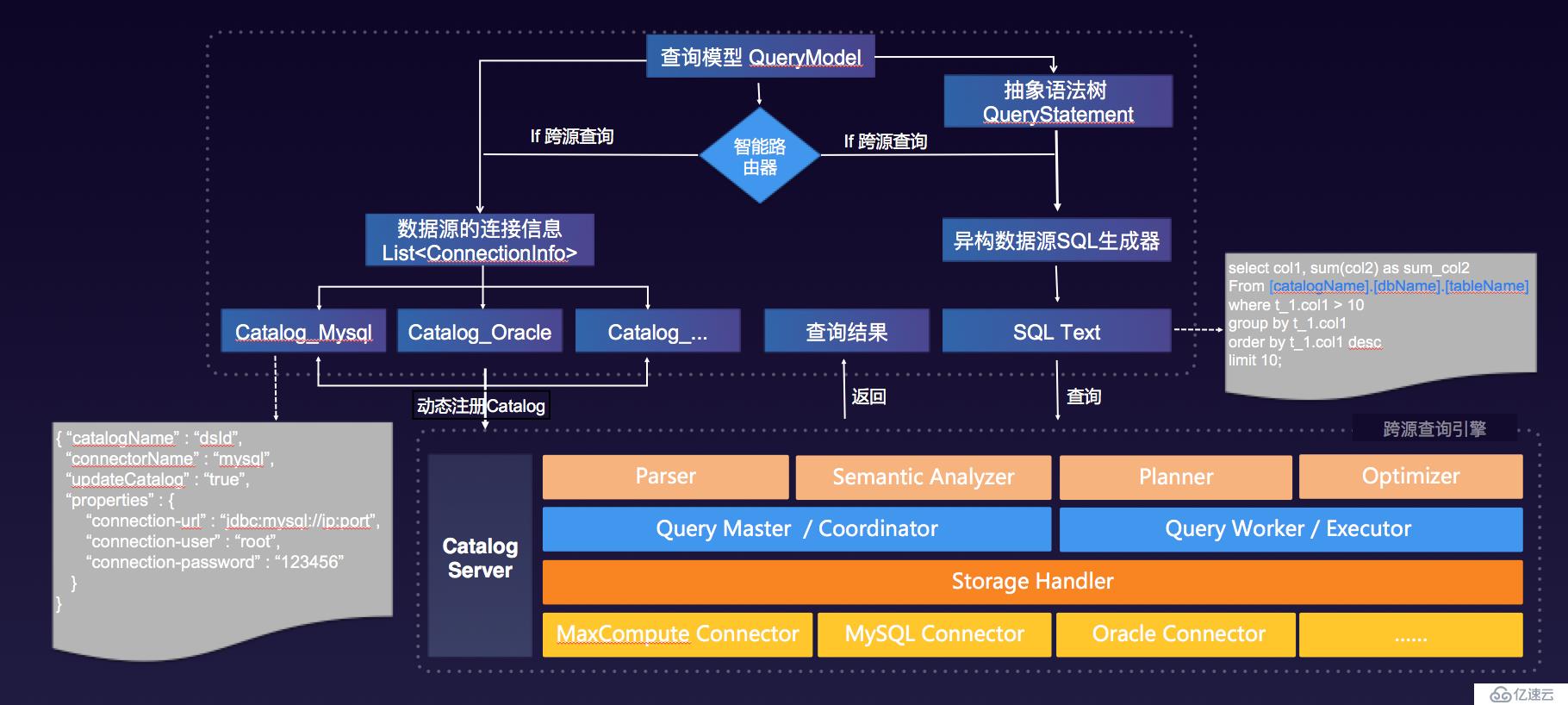
注意要确保本次查询所涉及到的catalogs 向跨源查询引擎的CatalogServer 动态注册成功后,才能下发本次查询的SQLText到跨源查询引擎。
示例:MaxCompute, MySQL 间的异构查询SQL:
查询结果: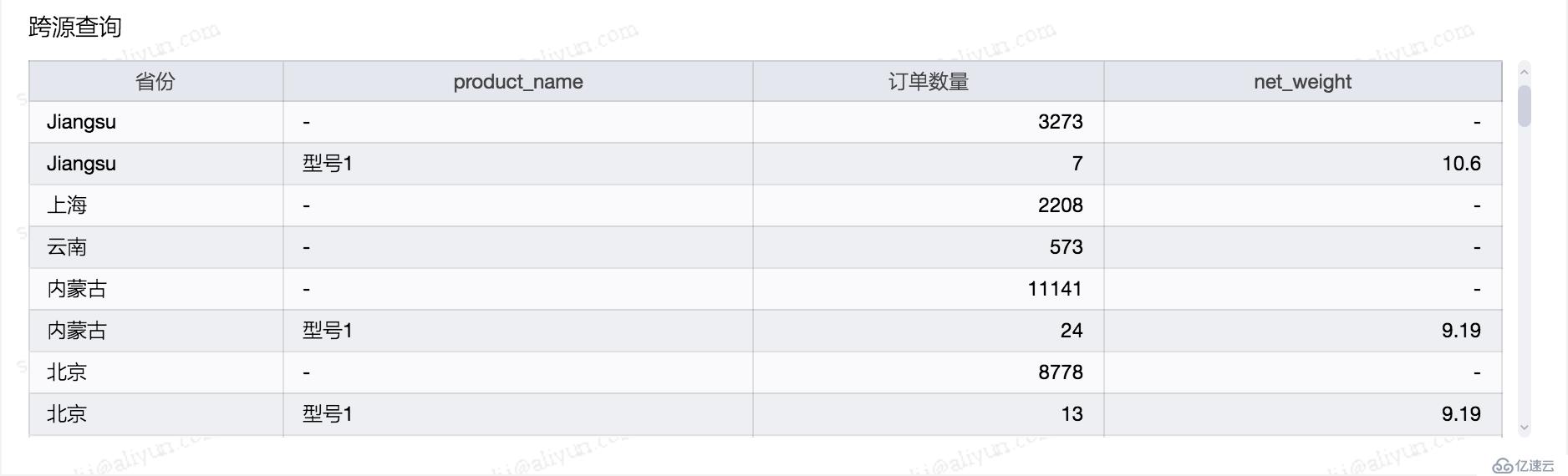
4.3 小结
异构数据源分析功能对用户是透明无感知的,欢迎前往Quick BI体验。用户只需在数据集关联时选用来源于不同库的数据表,就可轻松体验异构数据源分析功能,目前支持MaxCompute、MySQL、Oracle间的异构数据源查询或同构数据源跨库查询。后续会支持更多类型数据源异构查询,如 Hive, SQLServer, PostgresSql 等。
五、未完待续
Quick BI 后续将会迭代更新逐步支持更多类型数据源的多维分析,如API类数据源等,敬请期待…
作者:萨若 衣候
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。