жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
Quick BI зҡ„жЁЎеһӢи®ҫи®ЎдёҺз”ҹжҲҗSQLеҺҹзҗҶеү–жһҗ
йҡҸзқҖдә’иҒ”зҪ‘зҡ„й«ҳйҖҹеҸ‘еұ•пјҢж•°жҚ®йҮҸе‘ҲзҺ°дә•е–·ејҸзҡ„еўһй•ҝпјҢеҰӮдҪ•жқҘеҲҶжһҗе’ҢдҪҝз”Ёиҝҷдәӣж•°жҚ®пјҢдҪҝж•°жҚ®дә§з”ҹе•Ҷдёҡд»·еҖјпјҢе·Із»ҸеҸҳеҫ—и¶ҠжқҘи¶ҠйҮҚиҰҒгҖӮеҖјеҫ—й«ҳе…ҙзҡ„жҳҜпјҢеҪ“еүҚи¶ҠжқҘи¶ҠеӨҡзҡ„дәәе·Із»Ҹж„ҸиҜҶеҲ°дәҶз”Ёж•°жҚ®еҲҶжһҗеҶіе®ҡе•Ҷдёҡзӯ–з•Ҙзҡ„йҮҚиҰҒжҖ§пјҢд№ҹйғҪеңЁиҝӣиЎҢзқҖеҗ„иЎҢеҗ„дёҡзҡ„ж•°жҚ®еҲҶжһҗгҖӮдј—жүҖе‘ЁзҹҘж•°жҚ®еҲҶжһҗзҡ„ж ёеҝғжҳҜж•°жҚ®пјҢдёәдәҶжӣҙе®№жҳ“зҡ„еҲҶжһҗж•°жҚ®пјҢж•°жҚ®жЁЎеһӢзҡ„и®ҫи®ЎйңҖиҰҒйҒөеҫӘдёҖе®ҡзҡ„规иҢғгҖӮеҪ“еүҚжңҖжөҒиЎҢзҡ„иҒ”жңәеҲҶжһҗеӨ„зҗҶ(OLAP)зҡ„规иҢғдёәз»ҙеәҰе»ә模规иҢғгҖӮжң¬ж–Үд»Ӣз»ҚQuick BIеҰӮдҪ•иҝӣиЎҢз»ҙеәҰе»әжЁЎпјҢеҹәдәҺз»ҙеәҰжЁЎеһӢеҰӮдҪ•жқҘиҮӘеҠЁеҢ–зҡ„з”ҹжҲҗеҲҶжһҗжҹҘиҜўзҡ„SQLиҜӯеҸҘпјҢд»ҺиҖҢдҪҝж•°жҚ®еҲҶжһҗеҸҳеҫ—жӣҙе®№жҳ“гҖӮ
е…ій”®еӯ—пјҡ Quick BIгҖҒOLAPгҖҒз»ҙеәҰе»әжЁЎгҖҒSQL
OLAPпјҲOn-line Analytical ProcessingпјҢиҒ”жңәеҲҶжһҗеӨ„зҗҶпјүж №жҚ®еӯҳеӮЁж•°жҚ®зҡ„ж–№ејҸдёҚеҗҢеҸҜд»ҘеҲҶдёәROLAPгҖҒMOLAPгҖҒHOLAPгҖӮROLAPиЎЁзӨәеҹәдәҺе…ізі»ж•°жҚ®еә“еӯҳеӮЁзҡ„OLAPе®һзҺ°пјҲRelational OLAPпјүпјҢд»Ҙе…ізі»ж•°жҚ®еә“дёәж ёеҝғ,д»Ҙе…ізі»еһӢз»“жһ„иҝӣиЎҢеӨҡз»ҙж•°жҚ®зҡ„иЎЁзӨәе’ҢеӯҳеӮЁпјӣMOLAPиЎЁзӨәеҹәдәҺеӨҡз»ҙж•°жҚ®еӯҳеӮЁзҡ„OLAPе®һзҺ°пјҲMultidimensional OLAPпјүпјӣHOLAPиЎЁзӨәеҹәдәҺж··еҗҲж•°жҚ®еӯҳеӮЁзҡ„OLAPе®һзҺ°пјҲHybrid OLAPпјүпјҢеҰӮдҪҺеұӮз”Ёе…ізі»еһӢж•°жҚ®еә“еӯҳеӮЁпјҢй«ҳеұӮжҳҜеӨҡз»ҙж•°з»„еӯҳеӮЁгҖӮжҺҘдёӢжқҘдё»иҰҒд»Ӣз»ҚеҹәдәҺе…ізі»еһӢж•°жҚ®еә“зҡ„ROLAPзҡ„е»әжЁЎеҺҹзҗҶгҖӮ
ROLAPе°ҶеӨҡз»ҙж•°жҚ®еә“дёӯзҡ„иЎЁеҲҶдёәдёӨзұ»пјҡдәӢе®һиЎЁе’Ңз»ҙеәҰиЎЁгҖӮдәӢе®һиЎЁз”ЁдәҺеӯҳеӮЁз»ҙеәҰе…ій”®еӯ—е’Ңж•°еҖјзұ»еһӢзҡ„дәӢе®һж•°жҚ®пјҢдёҖиҲ¬жҳҜеӣҙз»•дёҡеҠЎиҝҮзЁӢиҝӣиЎҢи®ҫи®ЎпјҢдҫӢеҰӮпјҡй”Җе”®дәӢе®һиЎЁпјҢдёҖиҲ¬жқҘеӯҳеӮЁз”ЁжҲ·еңЁд»Җд№Ҳж—¶й—ҙгҖҒең°зӮ№иҙӯд№°дәҶдә§е“ҒпјҢй”ҖйҮҸе’Ңй”Җе”®йўқзӯүдҝЎжҒҜгҖӮз»ҙеәҰиЎЁз”ЁдәҺеӯҳеӮЁз»ҙеәҰзҡ„иҜҰз»Ҷж•°жҚ®пјҢдҫӢеҰӮй”Җе”®дәӢе®һиЎЁдёӯеӯҳеӮЁдәҶдә§е“Ғз»ҙеәҰзҡ„IDпјҢдә§е“Ғз»ҙеәҰиЎЁдёӯеӯҳеӮЁдә§е“Ғзҡ„еҗҚз§°гҖҒе“ҒзүҢдҝЎжҒҜпјҢдёӨиҖ…йҖҡиҝҮдә§е“ҒIDиҝӣиЎҢе…іиҒ”гҖӮ
ROLAPж №жҚ®дәӢе®һиЎЁгҖҒз»ҙеәҰиЎЁй—ҙзҡ„е…ізі»пјҢеҸҲеҸҜеҲҶдёәжҳҹеһӢжЁЎеһӢ(Star Schema)гҖҒйӣӘиҠұжЁЎеһӢ(Snowflake Schema)гҖӮ
жҳҹеһӢжЁЎеһӢе®ғз”ұдәӢе®һиЎЁпјҲFactTableпјүе’Ңз»ҙиЎЁпјҲDimensionTableпјүз»„жҲҗгҖӮдәӢе®һиЎЁдёӯзҡ„з»ҙеәҰеӨ–й”®еҲҶеҲ«дёҺзӣёеҜ№еә”зҡ„з»ҙиЎЁдёӯзҡ„дё»й”®зӣёе…іиҒ”пјҢе…іиҒ”д№ӢеҗҺз”ұдәҺеҪўзҠ¶зңӢиө·жқҘеғҸжҳҜдёҖдёӘжҳҹжҳҹпјҢжүҖд»ҘеҪўиұЎзҡ„з§°дёәжҳҹеһӢжЁЎеһӢгҖӮд»ҘдёӢзӨәдҫӢдёәжҳҹеһӢжЁЎеһӢпјҡе…¶дёӯsales_fact_1997дёәдәӢе®һиЎЁпјҢеӯҳеӮЁе®ўжҲ·еңЁжҹҗдёӘж—¶й—ҙгҖҒжҹҗдёӘе•Ҷеә—гҖҒиҙӯд№°дәҶжҹҗдёӘдә§е“ҒпјҢиҙӯд№°йҮҸе’Ңй”Җе”®йўқзҡ„дҝЎжҒҜпјҢи®°еҪ•зҡ„жҳҜдёҖдёӘдёӢеҚ•иҝҮзЁӢгҖӮдәӢе®һиЎЁsales_fact_1997йҖҡиҝҮеӨ–й”®product_idгҖҒcustomer_idгҖҒtime_idгҖҒstore_idеҲҶеҲ«дёҺз»ҙеәҰиЎЁproduct(дә§е“Ғз»ҙиЎЁ)гҖҒcustomer(е®ўжҲ·з»ҙиЎЁ)гҖҒtime_by_day(ж—¶й—ҙз»ҙиЎЁ)гҖҒstore(е•Ҷеә—з»ҙиЎЁ)зӣёе…іиҒ”пјҢе…іиҒ”е…ізі»дёәеӨҡеҜ№дёҖе…іиҒ”гҖӮ
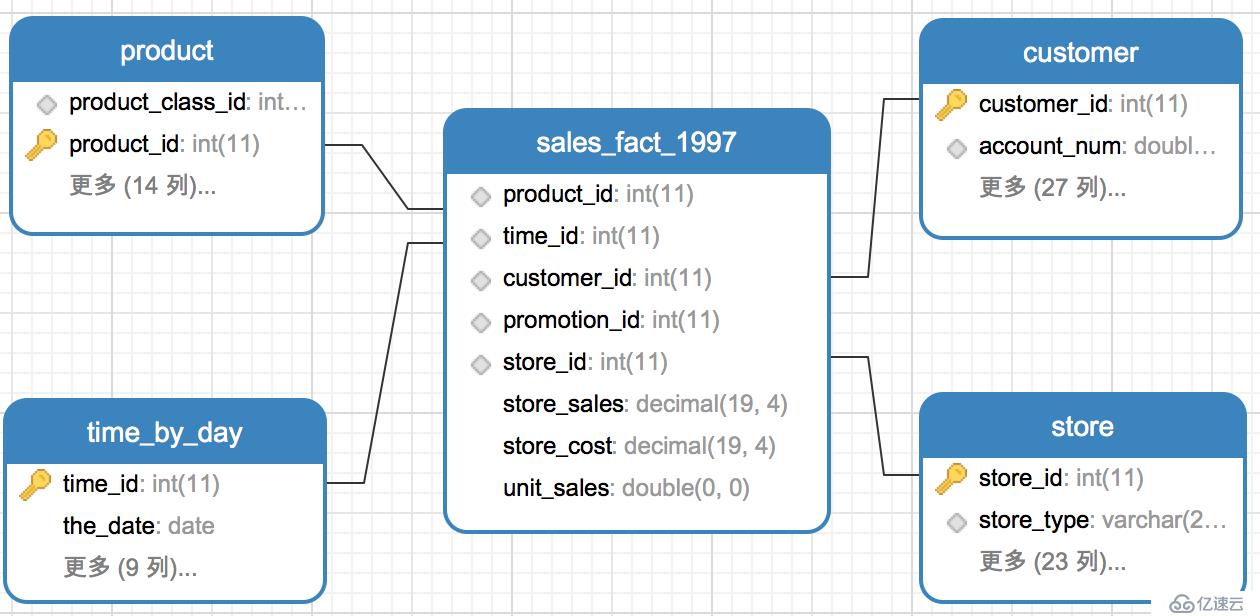
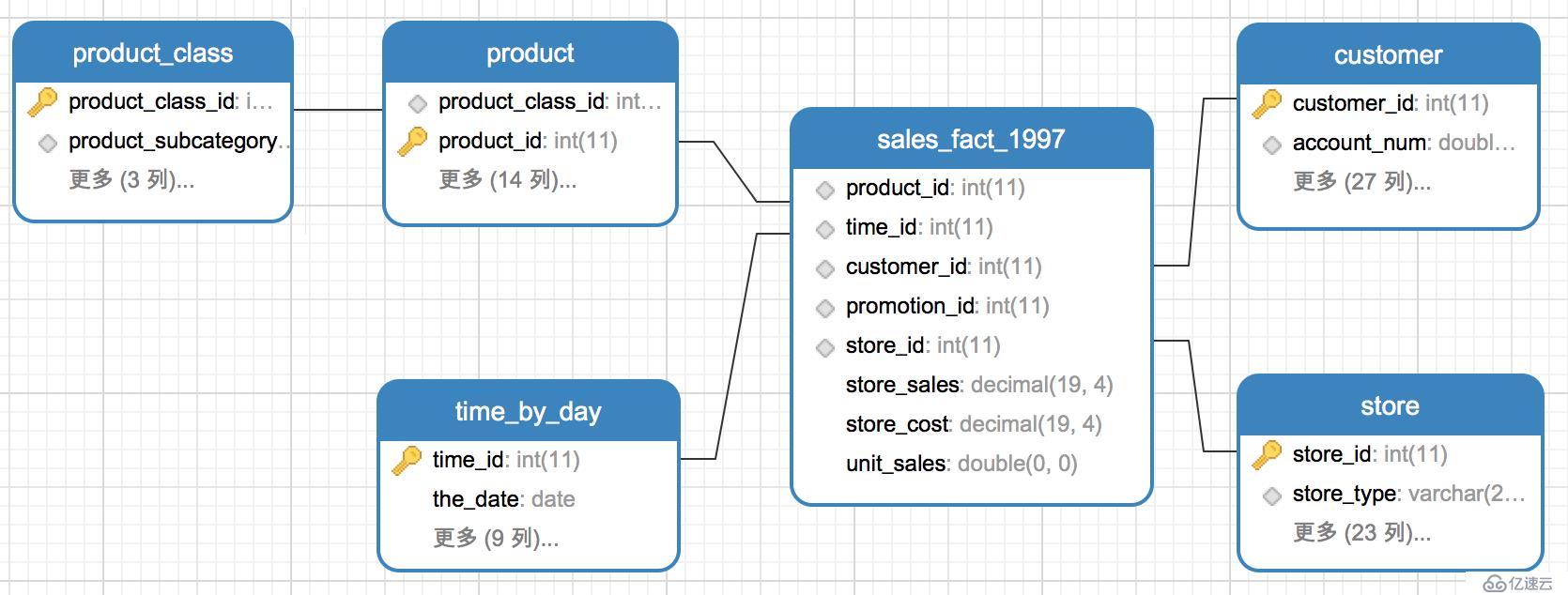
йӣӘиҠұжЁЎеһӢжҳҜеҪ“жңүдёҖдёӘжҲ–еӨҡдёӘз»ҙиЎЁжІЎжңүзӣҙжҺҘиҝһжҺҘеҲ°дәӢе®һиЎЁдёҠпјҢиҖҢжҳҜйҖҡиҝҮе…¶д»–з»ҙиЎЁиҝһжҺҘеҲ°дәӢе®һиЎЁдёҠж—¶пјҢе…¶еӣҫи§Је°ұеғҸдёҖдёӘйӣӘиҠұпјҢж•…з§°йӣӘиҠұжЁЎеһӢгҖӮдёӢйқўзӨәдҫӢproductпјҲдә§е“Ғпјүз»ҙеәҰиЎЁдёҺproduct_class(дә§е“Ғзұ»еҲ«)з»ҙеәҰиЎЁйҖҡиҝҮproduct_class_idзӣёе…іиҒ”пјҢе…іиҒ”е…ізі»дёәеӨҡеҜ№дёҖгҖӮproduct_classжІЎжңүдёҺsales_fact_1997дәӢе®һиЎЁзӣҙжҺҘе…іиҒ”гҖӮ
жЁЎеһӢжһ„е»әеҘҪдәҶеҗҺпјҢжҺҘдёӢжқҘзҡ„йҮҚзӮ№е°ұжҳҜй’ҲеҜ№еҲҶжһҗйңҖжұӮжқҘз”ҹжҲҗж»Ўи¶іеҲҶжһҗйңҖиҰҒзҡ„SQLиҜӯеҸҘпјҢ然еҗҺе°ҶSQLиҜӯеҸҘдёӢеҸ‘еҲ°DBдёӯжқҘжҹҘиҜўж•°жҚ®пјҢиҝ”еӣһеҲҶжһҗз»“жһңгҖӮдёӢйқўйҖҡиҝҮе…·дҪ“зҡ„йңҖжұӮеңәжҷҜжқҘд»Ӣз»ҚеҰӮдҪ•з”ҹжҲҗSQLиҜӯеҸҘгҖӮ
йңҖжұӮеңәжҷҜпјҡ
жҢүж—ҘжңҹгҖҒдә§е“ҒжҹҘзңӢжҖ»зҡ„й”Җе”®йўқгҖҒй”Җе”®йҮҸпјҢж—Ҙжңҹйҷҗе®ҡеңЁ1997е№ҙпјҢжҖ»й”Җе”®йўқйҷҗе®ҡеңЁ1000е…ғд»ҘдёҠпјҢз»“жһңжҢүз…§жҖ»зҡ„й”Җе”®йўқеҖ’еәҸжҺ’еҲ—пјҢзңӢеүҚ5дёӘгҖӮ
1. еҲҶжһҗйңҖиҰҒз”ЁеҲ°зҡ„еӯ—ж®өе’ҢиЎЁпјҢзӣ®ж ҮжҳҜжҳҺзЎ®жҹҘиҜўйңҖиҰҒз”ЁеҲ°е“ӘдәӣиЎЁгҖҒиЎЁй—ҙе…ізі»гҖҒиЎЁдёҠеҲҶз»„еӯ—ж®өгҖҒиҒҡеҗҲеӯ—ж®өпјҢзЎ®е®ҡSQLдёӯselectе’ҢfromдҝЎжҒҜгҖӮ
2. еҲҶжһҗзӯӣйҖүжқЎд»¶пјҢзӣ®ж ҮжҳҜжҳҺзЎ®SQLдёӯwhereдёӯйңҖиҝҮж»Өзҡ„еҖјгҖӮ
3. еҲҶжһҗеҲҶз»„з»ҙеәҰпјҢзӣ®ж ҮжҳҜжҳҺзЎ®SQLдёӯgroup byзҡ„еӯ—ж®өгҖӮ
4. еҲҶжһҗиҒҡеҗҲеҗҺзҡ„зӯӣйҖүжқЎд»¶пјҢзӣ®ж ҮжҳҜжҳҺзЎ®havingдёӯйңҖиҰҒиҝҮж»Өзҡ„еҖјгҖӮ
5. еҲҶжһҗйңҖиҰҒжҺ’еәҸзҡ„еҲ—е’ҢжҺ’еәҸзұ»еһӢ(еҚҮеәҸиҝҳжҳҜйҷҚеәҸ)гҖӮ
6. з”ҹжҲҗз»“жһңдёӘж•°йҷҗеҲ¶жқЎд»¶
7. ж №жҚ®д»ҘдёҠдҝЎжҒҜз”ҹжҲҗжҹҘиҜўSQLпјҡ
select еҲҶз»„еӯ—ж®өгҖҒиҒҡеҗҲеӯ—ж®ө from иЎЁ(еҗ«иЎЁе…іиҒ”) where зӯӣйҖүжқЎд»¶ group by еҲҶз»„з»ҙеәҰ having иҒҡеҗҲеҗҺзҡ„зӯӣйҖүжқЎд»¶ order by жҺ’еәҸдҝЎжҒҜ з»“жһңжқЎж•°йҷҗеҲ¶гҖӮ
жҢүз…§дёҠйқўзҡ„жӯҘйӘӨпјҢе’Ңжң¬дҫӢеӯҗдёӯзҡ„йңҖжұӮпјҢеҲҶжһҗжҹҘиҜўдёӯзҡ„е…ій”®дҝЎжҒҜпјҲд»ҘдёӢжӯҘйӘӨдёҺз”ҹжҲҗSQLжҖқи·Ҝдёӯзҡ„жӯҘйӘӨдёҖдёҖеҜ№еә”пјү
1. з”ЁеҲ°зҡ„еҲҶз»„еӯ—ж®өпјҡthe_dateгҖҒproduct_name, е…¶дёӯеҲҶз»„еӯ—ж®өthe_dateдёәж—ҘзІ’еәҰпјҢйңҖеӨ„зҗҶдёәе№ҙзІ’еәҰпјҡDATE_FORMAT(`the_date` , '%Y')
иҒҡеҗҲеӯ—ж®өпјҡstore_salesгҖҒunit_salesпјҢиҒҡеҗҲж–№ејҸйғҪдёәsumпјӣ
з”ЁеҲ°зҡ„иЎЁпјҡsales_fact_1997гҖҒproductгҖҒtime_by_dayпјӣ
иЎЁй—ҙе…ізі»пјҡsales_fact_1997. product_id= product. product_id
sales_fact_1997. time_id= time_by_day .time_id
2. зӯӣйҖүжқЎд»¶пјҡ
the_date`= STR_TO_DATE('1997-01-01 00:00:00' ,'%Y-%m-%d %H:%i:%s')
3. еҲҶз»„з»ҙеәҰпјҡDATE_FORMAT(`the_date` , '%Y')гҖҒproduct_name
4. иҒҡеҗҲеҗҺзҡ„зӯӣйҖүжқЎд»¶пјҡSUM(`store_sales`) > 1000
5. жҺ’еәҸпјҡorder by иҒҡеҗҲеҗҺзҡ„еҲ«еҗҚ desc
6. йҷҗеҲ¶з»“жһңдёӘж•°пјҡlimit 0,5
7. з”ҹжҲҗзҡ„SQLеҰӮдёӢ

дёӢйқўзҪ—еҲ—еҮәд»ҘдёҠзӨәдҫӢдёӯз”ЁеҲ°зҡ„иЎЁзҡ„е»әиЎЁиҜӯеҸҘпјҢйңҖиҰҒеңЁ MySQLж•°жҚ®еә“дёӢжү§иЎҢпјҢе…¶д»–зұ»еһӢж•°жҚ®еә“йңҖиҰҒеҒҡдёҖдәӣи°ғж•ҙгҖӮ
1. sales_fact_1997иЎЁ

2. productиЎЁ

3. product_classиЎЁ

4. time_by_dayиЎЁ
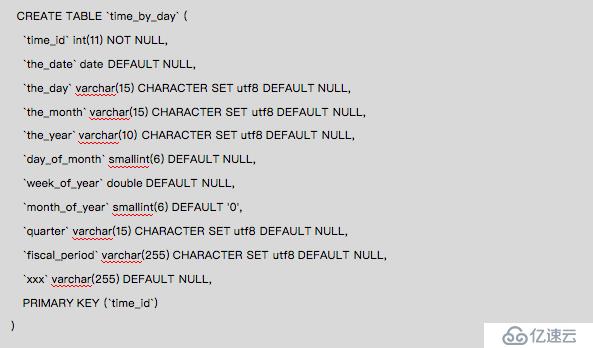
5. customerиЎЁ

6. storeиЎЁ

е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ