жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
ж–Ү | еҗ•й№Ҹ DataPipelineжһ¶жһ„еёҲ

иҝӣе…ҘеӨ§ж•°жҚ®ж—¶д»ЈпјҢе®һж—¶дҪңдёҡжңүзқҖи¶ҠжқҘи¶ҠйҮҚиҰҒзҡ„ең°дҪҚгҖӮжң¬ж–Үе°Ҷд»Һд»ҘдёӢеҮ дёӘйғЁеҲҶиҝӣиЎҢи®Іи§ЈDataPipelineеңЁеӨ§ж•°жҚ®е№іеҸ°зҡ„е®һж—¶ж•°жҚ®жөҒе®һи·өгҖӮ
дёҖгҖҒдјҒдёҡзә§ж•°жҚ®йқўдёҙзҡ„дё»иҰҒй—®йўҳе’ҢжҢ‘жҲҳ
1.ж•°жҚ®йҮҸдёҚж–ӯж”ҖеҚҮ
йҡҸзқҖдә’иҒ”зҪ‘+зҡ„蓬еӢғеҸ‘еұ•е’Ңз”ЁжҲ·и§„жЁЎзҡ„жҖҘеү§жү©еј пјҢдјҒдёҡж•°жҚ®йҮҸд№ҹеңЁйЈһйҖҹеўһй•ҝпјҢж•°жҚ®зҡ„йҮҸд»ҘGBдёәеҚ•дҪҚпјҢйҖҗжёҗзҡ„ејҖе§Ӣд»ҘTB/GB/PB/EBпјҢз”ҡиҮіZB/YBзӯүгҖӮеҗҢж—¶еӨ§ж•°жҚ®д№ҹеңЁдёҚж–ӯж·ұе…ҘеҲ°йҮ‘иһҚгҖҒйӣ¶е”®гҖҒеҲ¶йҖ зӯүиЎҢдёҡпјҢеҸ‘жҢҘзқҖи¶ҠжқҘи¶ҠеӨ§зҡ„дҪңз”ЁгҖӮ
2. ж•°жҚ®иҙЁйҮҸзҡ„иҰҒжұӮдёҚж–ӯең°жҸҗеҚҮ
еҪ“еүҚжҜ”иҫғжөҒиЎҢзҡ„AIгҖҒж•°жҚ®е»әжЁЎпјҢеҜ№ж•°жҚ®иҙЁйҮҸиҰҒжұӮй«ҳгҖӮе°Өе…¶еңЁйҮ‘иһҚйўҶеҹҹпјҢеҜ№дәҺж•°жҚ®иҙЁйҮҸзҡ„иҰҒжұӮжҳҜйқһеёёй«ҳзҡ„гҖӮ
3. ж•°жҚ®е№іеҸ°жһ¶жһ„зҡ„еӨҚжқӮеҢ–
дјҒдёҡзә§еә”з”Ёжһ¶жһ„зҡ„еҸҳеҢ–йҡҸзқҖдјҒдёҡ规模иҖҢеҸҳгҖӮ规模е°Ҹзҡ„дјҒдёҡпјҢз”ЁжҲ·е°‘гҖҒж•°жҚ®йҮҸд№ҹе°ҸпјҢеҸҜиғҪеҸӘйңҖдёҖдёӘMySQLе°ұжҗһиғҪжҗһпјӣдёӯеһӢдјҒдёҡпјҢйҡҸзқҖдёҡеҠЎйҮҸзҡ„дёҠеҚҮпјҢиҝҷж—¶еҖҷеҸҜиғҪйңҖиҰҒи®©дё»еә“еҒҡOLTPпјҢеӨҮеә“еҒҡOLAPпјӣеҪ“дјҒдёҡиҝӣе…Ҙ规模еҢ–пјҢж•°жҚ®йҮҸйқһеёёеӨ§пјҢеҺҹжңүзҡ„OLTPеҸҜиғҪе·Із»ҸдёҚиғҪж»Ўи¶ідәҶпјҢиҝҷж—¶еҖҷжҲ‘们дјҡеҒҡдёҖдәӣзӯ–з•ҘпјҢжқҘдҝқиҜҒOLTPе’ҢOLAPйҡ”зҰ»пјҢдёҡеҠЎзі»з»ҹе’ҢBIзі»з»ҹеҲҶејҖдә’дёҚеҪұе“ҚпјҢдҪҶеҒҡдәҶйҡ”зҰ»еҗҺеҗҢж—¶еёҰжқҘдәҶдёҖдёӘж–°зҡ„еӣ°йҡҫпјҢж•°жҚ®жөҒзҡ„е®һж—¶еҗҢжӯҘзҡ„йңҖжұӮпјҢиҝҷж—¶дјҒдёҡе°ұйңҖиҰҒдёҖдёӘеҸҜжү©еұ•гҖҒеҸҜйқ зҡ„жөҒејҸдј иҫ“е·Ҙе…·гҖӮ
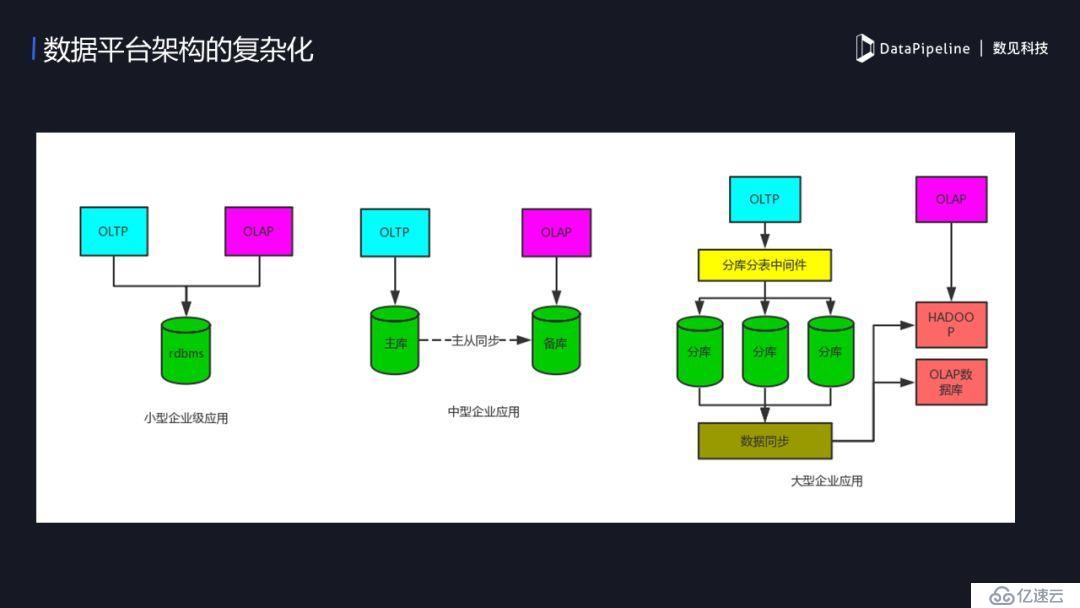
дәҢгҖҒеӨ§ж•°жҚ®е№іеҸ°дёҠзҡ„е®һи·өжЎҲдҫӢ
дёӢеӣҫжҳҜдёҖдёӘе…ёеһӢзҡ„BIе№іеҸ°и®ҫи®ЎеңәжҷҜпјҢд»ҘMySQLдёәдҫӢпјҢDataPipelineжҳҜеҰӮдҪ•е®һзҺ°MySQLзҡ„SourceConnectorгҖӮMySQLдҪңдёәSourceз«Ҝж—¶пјҡ
е…ЁйҮҸ+ еўһйҮҸпјӣ
е…ЁйҮҸпјҡйҖҡиҝҮselect ж–№ејҸпјҢе°Ҷж•°жҚ®еҠ иҪҪеҲ°kafkaдёӯпјӣ
еўһйҮҸпјҡе®һж—¶иҜ»еҸ– binlogзҡ„ж–№ејҸпјӣ
дҪҝз”Ёbinlogж—¶йңҖиҰҒжіЁж„ҸејҖеҗҜrow жЁЎејҸ并且imageи®ҫзҪ®дёә fullгҖӮ
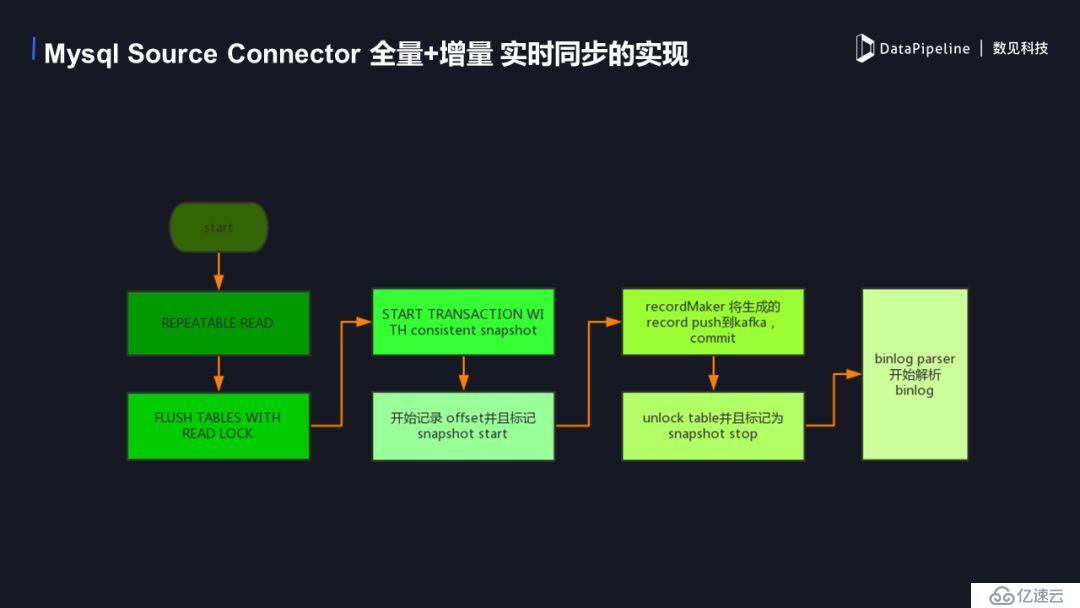
1. MySQL SourceConnector е…ЁйҮҸ+еўһйҮҸе®һж—¶еҗҢжӯҘзҡ„е®һзҺ°
дёӢйқўжҳҜе…·дҪ“зҡ„е®һзҺ°жөҒзЁӢеӣҫпјҢйҰ–е…ҲејҖеҗҜrepeatable readдәӢеҠЎпјҢдҝқиҜҒеңЁжү§иЎҢиҜ»й”Ғд№ӢеүҚзҡ„ж•°жҚ®еҸҜд»ҘзЎ®е®һзҡ„иҜ»еҲ°гҖӮ然еҗҺиҝӣиЎҢflush table with read lock ж“ҚдҪңпјҢж·»еҠ дёҖдёӘиҜ»й”Ғ,йҳІжӯўиҝҷдёӘж—¶еҖҷжңүж–°зҡ„ж•°жҚ®иҝӣе…ҘеҪұе“Қж•°жҚ®зҡ„иҜ»еҸ–пјҢиҝҷж—¶ејҖе§ӢдёҖдёӘtruncation with snapshotпјҢжҲ‘们еҸҜд»Ҙи®°еҪ•еҪ“еүҚbinlogзҡ„offset 并ж Үи®°дёҖдёӘsnapshot startпјҢиҝҷж—¶зҡ„offset дёәеўһйҮҸиҜ»еҸ–ж—¶ејҖе§Ӣзҡ„offsetгҖӮеҪ“дәӢеҠЎејҖе§ӢеҗҺеҸҜд»ҘиҝӣиЎҢе…ЁйҮҸж•°жҚ®зҡ„иҜ»еҸ–гҖӮrecord markerиҝҷж—¶дјҡе°Ҷз”ҹжҲҗrecord еҶҷеҲ° kafka дёӯпјҢ然еҗҺcommit иҝҷдёӘдәӢеҠЎгҖӮеҪ“е…ЁйҮҸж•°жҚ®pushе®ҢжҜ•еҗҺжҲ‘们解йҷӨиҜ»й”Ғ并且ж Үи®°snapshot stopпјҢжӯӨж—¶е…ЁйҮҸж•°жҚ®е·Із»ҸйғҪиҝӣе…ҘkafkaдәҶпјҢд№ӢеҗҺд»Һд№ӢеүҚи®°еҪ•зҡ„offsetејҖе§ӢеўһйҮҸж•°жҚ®зҡ„еҗҢжӯҘгҖӮ
2. DataPipelineеҒҡдәҶе“ӘдәӣдјҳеҢ–е·ҘдҪң
1пјүд»ҘеҫҖеңЁж•°жҚ®еҗҢжӯҘзҺҜиҠӮйғҪеҲҶдёәе…ЁйҮҸеҗҢжӯҘе’ҢеўһйҮҸеҗҢжӯҘпјҢе…ЁйҮҸеҗҢжӯҘдёәдёҖдёӘжү№еӨ„зҗҶгҖӮеңЁжү№еӨ„зҗҶж—¶жҲ‘们йғҪжҳҜиҝӣиЎҢall or nothingзҡ„еӨ„зҗҶпјҢдҪҶеҪ“еӨ§ж•°жҚ®жғ…еҶөдёӢдёҖдёӘжү№йҮҸдјҡеҚ з”ЁзӣёеҪ“й•ҝзҡ„ж—¶й—ҙпјҢж—¶й—ҙи¶Ҡй•ҝеҸҜйқ жҖ§е°ұи¶ҠйҡҫдҝқйҡңпјҢжүҖд»ҘеҫҖеҫҖдјҡеҮәзҺ°ж–ӯжҺүзҡ„жғ…еҶөпјҢиҝҷж—¶дёҖдёӘйҮҚж–°еӨ„зҗҶдјҡи®©еҫҲеӨҡдәәеҙ©жәғгҖӮDataPipeline и§ЈеҶідәҶиҝҷдёҖз—ӣзӮ№пјҢйҖҡиҝҮз®ЎзҗҶж•°жҚ®дј иҫ“ж—¶зҡ„position жқҘеҒҡеҲ°ж–ӯзӮ№з»ӯдј пјҢиҝҷж—¶еҪ“дёҖдёӘеӨ§и§„жЁЎзҡ„ж•°жҚ®д»»еҠЎеҚідҪҝеҸ‘з”ҹдәҶж„ҸеӨ–пјҢд№ҹеҸҜд»ҘйҮҚж–ӯжҺүзҡ„зӮ№жқҘ继з»ӯд№ӢеүҚзҡ„д»»еҠЎпјҢеӨ§еӨ§зј©зҹӯдәҶеҗҢжӯҘзҡ„ж—¶й—ҙпјҢжҸҗй«ҳдәҶеҗҢжӯҘзҡ„ж•ҲзҺҮгҖӮ
2пјүеңЁеҗҢжӯҘеӨҡдёӘд»»еҠЎзҡ„ж—¶еҖҷпјҢеҫҲйҡҫе№іиЎЎж•°жҚ®дј иҫ“еҜ№жәҗз«Ҝзҡ„еҺӢеҠӣе’Ңзӣ®зҡ„з«Ҝзҡ„е®һж—¶жҖ§пјҢеңЁеӨ§ж•°жҚ®йҮҸдёӢзҡ„дј иҫ“е°Өе…¶иғҪеӨҹдҪ“зҺ°пјҢиҝҷж—¶DataPipeline еңЁжӯӨеҒҡдәҶеӨ§йҮҸзӣёе…іжөӢиҜ•жқҘдјҳеҢ–дёҚеҗҢзҡ„иҝһжҺҘжұ пјҢејҖж”ҫж•°жҚ®дј иҫ“ж•ҲзҺҮзҡ„иҮӘе®ҡд№үеҢ–пјҢдҫӣе®ўжҲ·й’ҲеҜ№иҮӘе·ұзҡ„дёҡеҠЎзі»з»ҹе®ҡеҲ¶еҗҲйҖӮзҡ„дј иҫ“д»»еҠЎпјҢеҜ№дәҺдёҚеҗҢз§Қзұ»зҡ„ж•°жҚ®еә“зҡ„дј иҫ“иҝӣиЎҢдјҳеҢ–е’Ңи°ғж•ҙпјҢдҝқиҜҒж•°жҚ®дј иҫ“зҡ„й«ҳж•ҲжҖ§гҖӮ
3пјүиҮӘе®ҡд№үејӮжһ„ж•°жҚ®зұ»еһӢзҡ„иҪ¬еҢ–пјҢеҫҖеҫҖејҖжәҗзұ»еӨ§ж•°жҚ®дј иҫ“е·Ҙе…·еҰӮ sqoop зӯүпјҢеҜ№ејӮжһ„ж•°жҚ®зұ»еһӢзҡ„ж”ҜжҢҒдёҚеӨҹзҒөжҙ»пјҢз§Қзұ»д№ҹдёҚеӨҹйҪҗе…ЁгҖӮеғҸйҮ‘иһҚйўҶеҹҹдёӯеҜ№ж•°жҚ®зІҫеәҰиҰҒжұӮиҫғй«ҳзҡ„еңәжҷҜпјҢеңЁдј з»ҹж•°жҚ®еә“еҗ‘еӨ§ж•°жҚ®е№іеҸ°дј иҫ“ж—¶йҖ жҲҗзҡ„зІҫеәҰдёўеӨұжҳҜеҫҲеӨ§зҡ„дёҖдёӘй—®йўҳгҖӮDataPipeline еҜ№жӯӨеҒҡдәҶжӣҙеӨҡж•°жҚ®зұ»еһӢзҡ„ж”ҜжҢҒпјҢжҜ”еҰӮhive ж”ҜжҢҒзҡ„еӨҚжқӮзұ»еһӢд»ҘеҸҠ decimal е’Ң timestamp зӯүгҖӮ
3. Sinkз«Ҝд№ӢHive
1пјүHiveзҡ„зү№жҖ§
Hive еҶ…йғЁиЎЁе’ҢеӨ–йғЁиЎЁпјӣ
дҫқиө–HDFSпјӣ
ж”ҜжҢҒдәӢеҠЎе’ҢйқһдәӢеҠЎпјӣ
еӨҡз§ҚеҺӢзј©ж јејҸпјӣ
еҲҶеҢәеҲҶжЎ¶гҖӮ
2пјүHiveеҗҢжӯҘзҡ„й—®йўҳ
еҰӮдҪ•дҝқиҜҒе®һж—¶зҡ„еҶҷе…Ҙпјҹ
schema changeдәҶжҖҺд№ҲеҠһпјҹ
жҖҺд№Ҳжү©еұ•жҲ‘жғідҝқеӯҳзҡ„ж јејҸпјҹ
жҖҺд№Ҳе®һзҺ°еӨҡз§ҚеҲҶеҢәж–№ејҸпјҹ
еҗҢжӯҘдёӯж–ӯдәҶжҖҺд№ҲеҠһпјҹ
еҰӮдҪ•дҝқиҜҒжҲ‘зҡ„ж•°жҚ®дёҚдёўпјҹ
3пјүKafkaConnect HDFS зҡ„ Hive еҗҢжӯҘе®һи·ө
дҪҝз”ЁеӨ–иЎЁпјҡHiveеӨ–йғЁиЎЁпјҢиғҪеӨҹжҸҗй«ҳеҶҷе…Ҙж•ҲзҺҮпјҢзӣҙжҺҘеҶҷHDFSпјҢеҮҸе°‘IOж¶ҲиҖ—пјҢиҖҢеҶ…иЎЁдјҡжҜ”еӨ–иЎЁеӨҡдёҖж¬ЎIOпјӣ
Schema changeпјҡзӣ®еүҚзҡ„еҒҡжі•жҳҜзӣ®зҡ„з«Ҝж №жҚ®жәҗз«Ҝзҡ„еҸҳеҢ–иҖҢеҸҳеҢ–пјҢеҪ“жңүеўһеҠ еҲ—еҲ йҷӨеҲ—зҡ„жғ…еҶөпјҢзӣ®ж Үз«Ҝдјҡи·ҹйҡҸжәҗз«Ҝж”№еҠЁпјӣ
зӣ®еүҚж”ҜжҢҒзҡ„еӯҳеӮЁж јејҸпјҡparquetпјҢavro пјҢcsv
жҸ’件еҢ–зҡ„partitionerпјҢжҸҗдҫӣеӨҡз§ҚеҲҶеҢәж–№ејҸпјҢеҰӮ Wallclock RecordRecordFieldпјҡwallclockжҳҜдҪҝз”ЁеҶҷе…ҘеҲ°hiveз«Ҝж—¶зҡ„зі»з»ҹж—¶й—ҙпјҢRecord дҪҝз”ЁжҳҜиҜ»еҸ–ж—¶з”ҹжҲҗrecordзҡ„ж—¶й—ҙпјҢRecordFieldжҳҜдҪҝз”Ёз”ЁжҲ·иҮӘе®ҡд№үзҡ„ж—¶й—ҙжҲіжқҘе®ҡд№үеҲҶеҢәпјҢжңӘжқҘдјҡе®һзҺ°еҸҜиҮӘе®ҡд№үеҢ–зҡ„partitioner жқҘж»Ўи¶ідёҚеҗҢзҡ„йңҖжұӮпјӣ
Recover жңәеҲ¶дҝқйҡңдёӯж–ӯеҗҺдёҚдјҡдёўеӨұж•°жҚ®пјӣ
дҪҝз”ЁWAL пјҲWrite-AheadLoggingпјүжңәеҲ¶пјҢдҝқиҜҒж•°жҚ®зӣ®зҡ„з«Ҝж•°жҚ®дёҖиҮҙжҖ§гҖӮ
4пјүRecoverзҡ„жңәеҲ¶
recover жҳҜдёҖз§ҚжҒўеӨҚзҡ„жңәеҲ¶пјҢеңЁж•°жҚ®дј иҫ“зҡ„йҳ¶ж®өеҫҖеҫҖеҸҜиғҪеҮәзҺ°еҗ„з§ҚдёҚеҗҢзҡ„й—®йўҳпјҢеҰӮзҪ‘з»ңй—®йўҳзӯүзӯүгҖӮеҪ“еҮәзҺ°й—®йўҳеҗҺжҲ‘们йңҖиҰҒжҒўеӨҚж•°жҚ®еҗҢжӯҘпјҢйӮЈд№ҲrecoverжҳҜжҖҺд№ҲдҝқиҜҒж•°жҚ®жӯЈеёёдј иҫ“дёҚдёўеӨұе‘ўпјҹеҪ“recoverејҖе§Ӣзҡ„ж—¶еҖҷпјҢиҺ·еҸ–зӣ®ж Үж–Ү件еңЁhdfs дёҠзҡ„з§ҹзәҰпјҢеҰӮжһңиҝҷж—¶еҖҷйңҖиҰҒиҜ»еҶҷзҡ„HDFSеҪ“еүҚж–Ү件жҳҜиў«еҚ з”Ёзҡ„пјҢйӮЈжҲ‘们йңҖиҰҒзӯүеҫ…е®ғзӣҙеҲ°еҸҜд»ҘиҺ·еҸ–еҲ°з§ҹзәҰгҖӮеҪ“жҲ‘们иҺ·еҸ–еҲ°з§ҹзәҰеҗҺе°ұеҸҜд»ҘејҖе§ӢиҜ»д№ӢеүҚеҶҷе…Ҙж—¶еҖҷзҡ„logпјҢеҰӮжһң第дёҖж¬ЎдјҡеҲӣе»әдёҖдёӘж–°зҡ„logпјҢ并ж Үи®°дёҖдёӘbeginпјҢ然еҗҺи®°еҪ•дәҶеҪ“ж—¶зҡ„kafka offsetгҖӮиҝҷж—¶еҖҷйңҖиҰҒжё…зҗҶд№ӢеүҚйҒ—з•ҷдёӢжқҘзҡ„дёҙж—¶ж•°жҚ®пјҢжё…зҗҶжҺүд№ӢеҗҺеҶҚйҮҚж–°ејҖе§ӢеҗҢжӯҘзӣҙеҲ°еҗҢжӯҘз»“жқҹдјҡж Үи®°дёҖдёӘendгҖӮеҰӮжһңжІЎжңүз»“жқҹзҡ„иҜқе°ұзӣёеҪ“дәҺжӯЈеңЁиҝӣиЎҢдёӯпјҢжӯЈеңЁиҝӣиЎҢдёӯжҜҸж¬ЎйғҪдјҡжҸҗдәӨеҪ“еүҚеҗҢжӯҘзҡ„offsetпјҢжқҘдҝқиҜҒеҮәзҺ°ж„ҸеӨ–еҗҺдјҡеӣһж»ҡеҲ°д№ӢеүҚoffsetгҖӮ
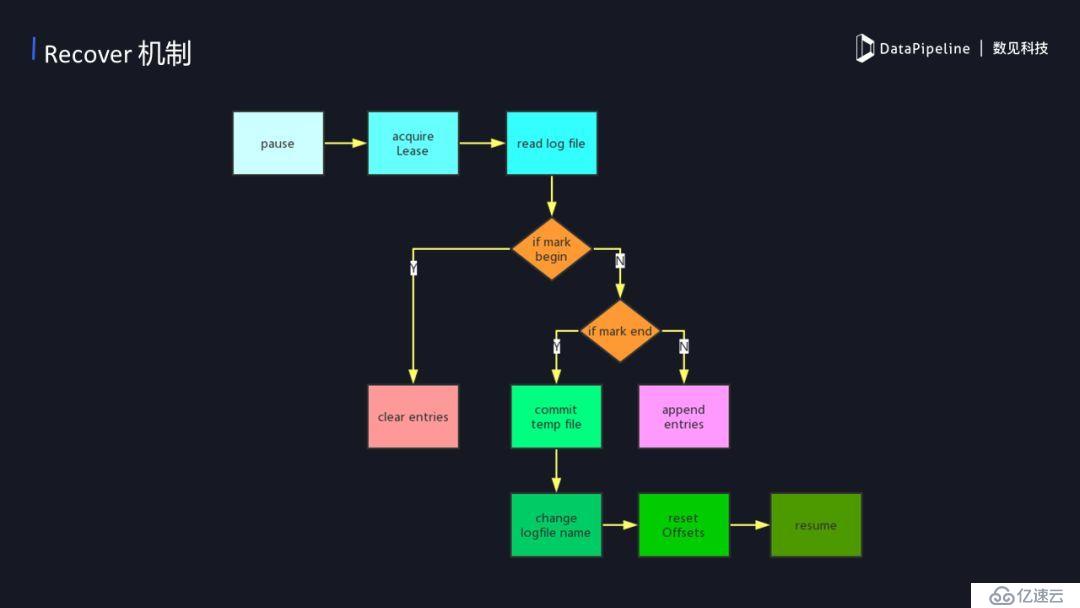
5пјүWAL пјҲWrite-Ahead LoggingпјүжңәеҲ¶
Write-Ahead LoggingжңәеҲ¶е…¶е®һе°ұжҳҜж ёеҝғжҖқжғіеңЁж•°жҚ®еҶҷе…ҘеҲ°ж•°жҚ®еә“д№ӢеүҚпјҢе®ғе…ҲеҶҷдёҙж—¶ж–Ү件пјҢеҪ“дёҖдёӘжү№ж¬Ўз»“жқҹеҗҺпјҢеңЁе°ҶиҝҷдёӘдёҙж—¶ж–Ү件改еҗҚдёәжӯЈејҸж–Ү件пјҢзЎ®дҝқжҜҸж¬ЎжҸҗдәӨеҗҺзҡ„жӯЈејҸж–Ү件дёҖиҮҙжҖ§пјҢеҰӮжһңдёӯйҖ”еҮәзҺ°еҶҷе…Ҙй”ҷиҜҜе°Ҷдёҙж—¶ж–Ү件еҲ йҷӨйҮҚж–°еҶҷе…ҘпјҢзӣёеҪ“дәҺдёҖдёӘеӣһж»ҡгҖӮhive зҡ„еҗҢжӯҘдё»иҰҒеҲ©з”Ёиҝҷз§Қе®һзҺ°ж–№ејҸжқҘдҝқиҜҒдёҖиҮҙжҖ§гҖӮйҰ–е…Ҳе®ғеҗҢжӯҘж•°жҚ®еҶҷе…ҘеҲ°HDFSдёҙж—¶ж–Ү件дёҠпјҢзЎ®дҝқдёҖдёӘжү№ж¬Ўзҡ„ж•°жҚ®жӯЈеёёеҗҺеҶҚйҮҚе‘ҪеҗҚеҲ°жӯЈејҸж–Ү件еҪ“дёӯгҖӮжӯЈејҸзҡ„ж–Ү件еҗҚдјҡеҢ…еҗ«kafka offsetпјҢдҫӢеҰӮдёҖдёӘavro ж–Ү件зҡ„ж–Ү件еҗҚдёә xxxx+001+0020.avro пјҢиҝҷиЎЁзӨәеҪ“еүҚж–Ү件дёӯжңүoffset 1 еҲ° 20 зҡ„20жқЎж•°жҚ®гҖӮ
4. Sinkз«Ҝд№ӢGreenPlum
GreenPlumпјҢжҳҜдёҖдёӘMPPжһ¶жһ„зҡ„ж•°жҚ®д»“еә“пјҢеә•еұӮз”ұеӨҡдёӘpostgresж•°жҚ®еә“дҪңдёәи®Ўз®—иҠӮзӮ№пјҢж“…й•ҝOLAPпјҢдҪңдёәBIж•°жҚ®д»“еә“жңүзқҖиүҜеҘҪзҡ„жҖ§иғҪгҖӮ
1пјүDataPipelineеҜ№GreenPlum еҗҢжӯҘе®һи·өд»ҘеҸҠдјҳеҢ–зӯ–з•Ҙ
greenplum ж”ҜжҢҒеӨҡз§Қж•°жҚ®еҠ иҪҪж–№ејҸпјҢзӣ®еүҚжҲ‘们дҪҝз”Ёcopyзҡ„еҠ иҪҪж–№ејҸгҖӮ
жү№йҮҸеӨ„зҗҶжҸҗй«ҳsinkз«ҜеҶҷе…Ҙж•ҲзҺҮпјҢдёҚиҝӣиЎҢinsert е’Ң update зҡ„ж“ҚдҪңпјҢдёҖеҫӢдҪҝз”Ё delete + copy зҡ„ж–№ејҸжү№йҮҸеҠ иҪҪпјӣ
еӨҡзәҝзЁӢеҠ йў„еҠ иҪҪжңәеҲ¶пјҡ
вһў жҜҸдёӘйңҖиҰҒеҗҢжӯҘзҡ„иЎЁеҚ•зӢ¬и®°еҪ•дёҖдёӘoffsetпјҢеҪ“ж•ҙдёӘд»»еҠЎеӨұиҙҘж—¶еҸҜд»ҘеҲҶејҖиҝӣиЎҢжҒўеӨҚпјӣ
вһў дҪҝз”ЁдёҖдёӘзәҝзЁӢжұ з®ЎзҗҶеҠ иҪҪж•°жҚ®зҡ„зәҝзЁӢпјҢжҜҸдёӘеҗҢжӯҘзҡ„иЎЁеҚ•зӢ¬дёҖдёӘзәҝзЁӢжқҘиҝӣиЎҢеҠ иҪҪж•°жҚ®пјҢеӨҡиЎЁеҗҢж—¶еҗҢжӯҘпјӣ
вһў еңЁеҠ иҪҪж•°жҚ®зҡ„ж—¶й—ҙйҮҢпјҢжҸҗеүҚеҜ№kafkaиҝӣиЎҢж¶Ҳиҙ№пјҢзј“еӯҳеӨ„зҗҶеҘҪзҡ„дёҖдёӘж•°жҚ®йӣҶпјҢеҪ“дёҖдёӘзәҝзЁӢеҠ иҪҪж•°жҚ®з»“жқҹеҗҺ马дёҠејҖе§Ӣж–°зҡ„зәҝзЁӢеҠ иҪҪж•°жҚ®пјҢеҮҸе°‘еӨ„зҗҶеҠ иҪҪж•°жҚ®зҡ„ж—¶й—ҙпјӣ
delete + copyзҡ„ж–№ејҸеҸҜд»ҘдҝқиҜҒж•°жҚ®жңҖз»ҲдёҖиҮҙжҖ§пјӣ
source з«Ҝжңүдё»й”®зҡ„иЎЁеҸҜд»ҘйҖҡиҝҮдё»й”®жқҘеҗҲ并дёҖдёӘжү№ж¬ЎйңҖиҰҒеҗҢжӯҘзҡ„ж•°жҚ®пјҢеҰӮдёҖдёӘйңҖиҰҒеҗҢжӯҘзҡ„жү№йҮҸж•°жҚ®дёӯеҢ…еҗ«дёҖжқЎ insert зҡ„ж•°жҚ®пјҢеҗҺйқўи·ҹзқҖ update иҜҘжқЎж•°жҚ®пјҢйӮЈе°ұж— йңҖеҗҢжӯҘдёӨйҒҚпјҢе°ҶиҜҘж•°жҚ®жӣҙж–°еҲ° update д№ӢеҗҺзҡ„зҠ¶жҖҒ copy еҲ° gp еҪ“дёӯеҚіеҸҜгҖӮ
еҗҢжӯҘGreenPlumйңҖиҰҒжіЁж„Ҹпјҡеӣ дёәжҳҜйҖҡиҝҮcopy еҶҷе…Ҙж–Ү件зҡ„пјҢйңҖиҰҒж–Ү件жҳҜз»“жһ„еҢ–ж•°жҚ®пјҢе…ёеһӢзҡ„жҳҜдҪҝз”ЁCSVпјҢCSV еҶҷе…Ҙж—¶йңҖжіЁж„ҸspiltquoteпјҢescapequoteпјҢйҒҝе…ҚеҮәзҺ°ж•°жҚ®й”ҷдҪҚзҡ„зҺ°иұЎгҖӮupdateдё»й”®зҡ„й—®йўҳ , еҪ“жәҗз«ҜжҳҜupdateдёҖдёӘдё»й”®ж—¶пјҢеҗҢж—¶йңҖиҰҒи®°еҪ•updateеүҚзҡ„дё»й”®пјҢ并еңЁзӣ®ж Үз«ҜиҝӣиЎҢеҲ йҷӨгҖӮиҝҳжңү \0 зү№ж®Ҡеӯ—з¬Ұзҡ„й—®йўҳпјҢеӣ дёәж ёеҝғжҳҜз”ЁCиҜӯиЁҖпјҢжүҖд»ҘеңЁеҗҢжӯҘзҡ„ж—¶еҖҷ\0йңҖиҰҒзү№ж®ҠеӨ„зҗҶжҺүгҖӮ
дёүгҖҒDataPipelineжңӘжқҘзҡ„е·ҘдҪң
1. зӣ®еүҚжҲ‘们碰еҲ°kafka connect rebalanceзҡ„дёҖдәӣй—®йўҳпјҢжүҖд»ҘжҲ‘们еҜ№е…¶иҝӣиЎҢдәҶж”№йҖ гҖӮд»ҘеҫҖзҡ„rebalanceжңәеҲ¶жҳҜеҒҮеҰӮжҲ‘们еўһеҠ жҲ–иҖ…еҲ йҷӨдёҖдёӘtaskпјҢдјҡеҜјиҮҙж•ҙдёӘйӣҶзҫӨrebalanceпјҢиҝҷж ·йҖ жҲҗеҫҲеӨҡж— и°“зҡ„ејҖй”ҖиҖҢдё”йў‘з№Ғзҡ„rebalance дёҚеҲ©дәҺж•°жҚ®еҗҢжӯҘзҡ„д»»еҠЎзҡ„зЁіе®ҡгҖӮдәҺжҳҜжҲ‘们е°ҶrebalanceжңәеҲ¶ж”№йҖ жҲҗдёҖдёӘй»ҸжҖ§зҡ„жңәеҲ¶пјҡ
еҪ“жҲ‘们еўһеҠ дёҖдёӘж–°зҡ„д»»еҠЎзҡ„ж—¶еҖҷпјҢжҲ‘们дјҡжЈҖжҹҘжүҖжңүзҡ„workerдҪҝз”ЁзҺҮжҜ”иҫғдҪҺзҡ„пјҢеҪ“workerзҡ„taskжҜ”иҫғе°‘пјҢжҲ‘们еҸӘжҠҠе®ғеҠ иҝӣжҜ”иҫғе°‘зҡ„workerе°ұеҸҜд»ҘдәҶпјҢд№ҹдёҚйңҖиҰҒеҒҡе…ЁйҮҸзҡ„е№іиЎЎпјҢеҪ“然иҝҷж—¶еҖҷеҸҜиғҪиҝҳжҳҜжңүдёҖдәӣдёҚе№іиЎЎзҡ„иө„жәҗжөӘиҙ№пјҢиҝҷжҳҜжҲ‘们еҸҜд»Ҙе®№еҝҚзҡ„пјҢиҮіе°‘жҜ”жҲ‘们еҒҡдёҖж¬Ўе…ЁйҮҸзҡ„rebalanceејҖй”ҖиҰҒе°Ҹпјӣ
еҒҮеҰӮеҲ йҷӨдёҖдёӘtaskпјҢд»ҘеҫҖзҡ„жңәеҲ¶жҳҜеҲ йҷӨдёҖдёӘtaskзҡ„ж—¶еҖҷд№ҹдјҡеҒҡе…ЁйҮҸзҡ„RebalanceпјҢж–°зҡ„жңәеҲ¶дёҚдјҡи§ҰеҸ‘rebalanceгҖӮиҝҷж—¶еҖҷеҰӮжһңж—¶й—ҙй•ҝд№ҹдјҡйҖ жҲҗдёҖдёӘиө„жәҗдёҚе№іиЎЎпјҢиҝҷжҳҜжҲ‘们еҸҜд»ҘиҮӘеҠЁеҢ–rebalanceдёҖдёӢжүҖжңүзҡ„йӣҶзҫӨпјӣ
еҒҮеҰӮиҜҙйӣҶзҫӨзҡ„жҹҗдёӘиҠӮзӮ№е®•жҺүдәҶпјҢиҜҘиҠӮзӮ№зҡ„taskжҖҺд№ҲеҠһе‘ўпјҹжҲ‘们дёҚдјҡ马дёҠе°ұжҠҠиҝҷдёӘиҠӮзӮ№дёҠзҡ„ taskеҲҶй…ҚеҮәеҺ»пјҢдјҡе…Ҳзӯүеҫ…10еҲҶй’ҹпјҢеӣ дёәжңүзҡ„ж—¶еҖҷе®ғеҸҜиғҪеҸӘжҳҜзҹӯжҡӮзҡ„иҝһжҺҘи¶…ж—¶пјҢиҝҮдёҖж®өж—¶й—ҙеҗҺе°ұдјҡжҒўеӨҚпјҢеҰӮжһңж №жҚ®иҝҷдёӘжқҘеҒҡдёҖж¬ЎrebalanceпјҢеҸҜиғҪиҝҷжҳҜдёҚеӨӘеҖјзҡ„гҖӮеҪ“зӯүеҫ…10еҲҶй’ҹеҗҺиҠӮзӮ№иҝҳжҳҜжІЎжңүжҒўеӨҚпјҢжҲ‘们еҶҚеҒҡrebalanceпјҢе°Ҷе®•жҺүзҡ„иҠӮзӮ№д»»еҠЎеҲҶй…ҚеҲ°е…¶д»–иҠӮзӮ№дёҠпјӣ
2. жәҗз«Ҝзҡ„ж•°жҚ®дёҖиҮҙжҖ§пјҢзӣ®еүҚйҖҡиҝҮWALзҡ„жңәеҲ¶еҸҜд»ҘдҝқиҜҒзӣ®зҡ„з«Ҝзҡ„дёҖиҮҙжҖ§пјӣ
3. еӨ§ж•°жҚ®йҮҸдёӢзҡ„еҗҢжӯҘдјҳеҢ–д»ҘеҸҠжҸҗй«ҳеҗҢжӯҘзҡ„зЁіе®ҡжҖ§гҖӮ
еӣӣгҖҒжҖ»з»“
1. еӨ§ж•°жҚ®ж—¶д»ЈдјҒдёҡж•°жҚ®йӣҶжҲҗдё»иҰҒйқўдёҙеҗ„з§ҚеӨҚжқӮзҡ„жһ¶жһ„пјҢеә”еҜ№иҝҷдәӣеӨҚжқӮзҡ„зі»з»ҹеҜ№ETLзҡ„иҰҒжұӮд№ҹи¶ҠжқҘи¶Ҡй«ҳгҖӮжҲ‘们иғҪеҒҡзҡ„е°ұжҳҜйңҖиҰҒжқғиЎЎеҲ©ејҠйҖүеҸ–дёҖдёӘз¬ҰеҗҲдёҡеҠЎйңҖжұӮзҡ„жЎҶжһ¶пјӣ
2. Kafka Connect жҜ”иҫғйҖӮеҗҲеҜ№ж•°жҚ®йҮҸеӨ§пјҢдё”жңүе®һж—¶жҖ§йңҖжұӮзҡ„дёҡеҠЎпјӣ
3. еҹәдәҺKafka Connect дјҳиүҜзү№жҖ§еҸҜд»ҘдҫқжҚ®дёҚеҗҢзҡ„ж•°жҚ®д»“еә“зү№жҖ§жқҘжҸҗй«ҳж•°жҚ®ж—¶ж•ҲжҖ§е’ҢеҗҢжӯҘж•ҲзҺҮпјӣ
4. DataPipelineй’ҲеҜ№зӣ®еүҚдјҒдёҡеңЁеӨ§и§„жЁЎе®һж—¶ж•°жҚ®жөҒзҡ„з—ӣзӮ№пјҢиҝӣиЎҢдәҶзӣёе…ізҡ„ж”№йҖ е’ҢдјҳеҢ–пјҢйҰ–е…Ҳж•°жҚ®з«ҜеҲ°з«ҜдёҖиҮҙжҖ§зҡ„дҝқиҜҒжҳҜеҮ д№ҺжүҖжңүдјҒдёҡеңЁж•°жҚ®еҗҢжӯҘиҝҮзЁӢдёӯзў°еҲ°зҡ„пјҢзӣ®еүҚе·Із»ҸеҒҡеҲ°еҹәдәҺkafka connect зҡ„жЎҶжһ¶дёӯ rebalance дёӯзҡ„дјҳеҢ–е’Ңж”№йҖ гҖӮ
вҖ”endвҖ”
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ