жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жё©йҰЁжҸҗзӨәпјҡиҰҒзңӢй«ҳжё…ж— з ҒеҘ—еӣҫпјҢиҜ·дҪҝз”ЁжүӢжңәжү“ејҖ并еҚ•еҮ»еӣҫзүҮж”ҫеӨ§жҹҘзңӢгҖӮ
1.й—®йўҳжҸҸиҝ°
CDHдёӯй»ҳи®ӨдёҚж”ҜжҢҒLzoеҺӢзј©зј–з ҒпјҢйңҖиҰҒдёӢиҪҪйўқеӨ–зҡ„ParcelеҢ…пјҢжүҚиғҪи®©Hadoopзӣёе…із»„件еҰӮHDFSпјҢHiveпјҢSparkж”ҜжҢҒLzoзј–з ҒгҖӮ
е…·дҪ“иҜ·еҸӮиҖғпјҡ
https://www.cloudera.com/documentation/enterprise/latest/topics/cm\_mc\_gpl\_extras.html
https://www.cloudera.com/documentation/enterprise/latest/topics/cm\_ig\_install\_gpl\_extras.html#xd\_583c10bfdbd326ba-3ca24a24-13d80143249--7ec6
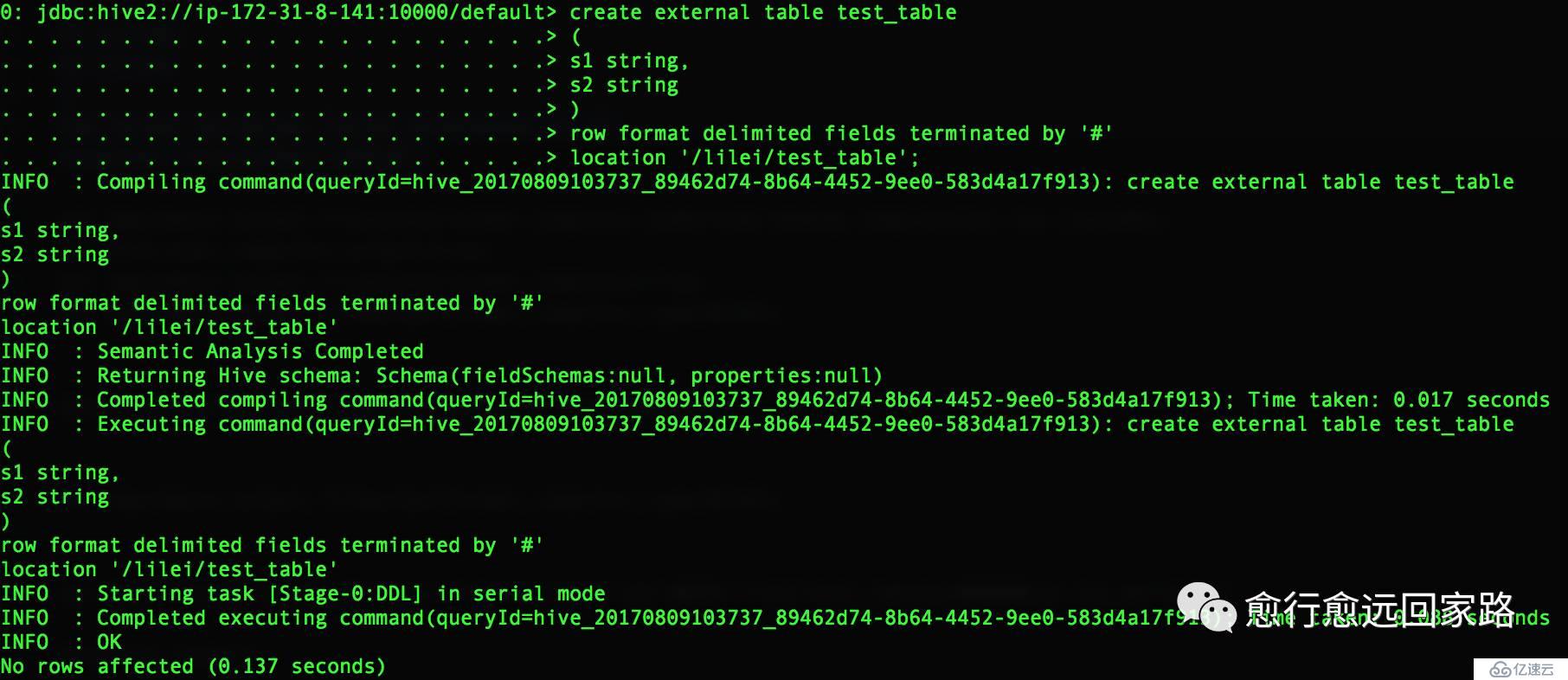
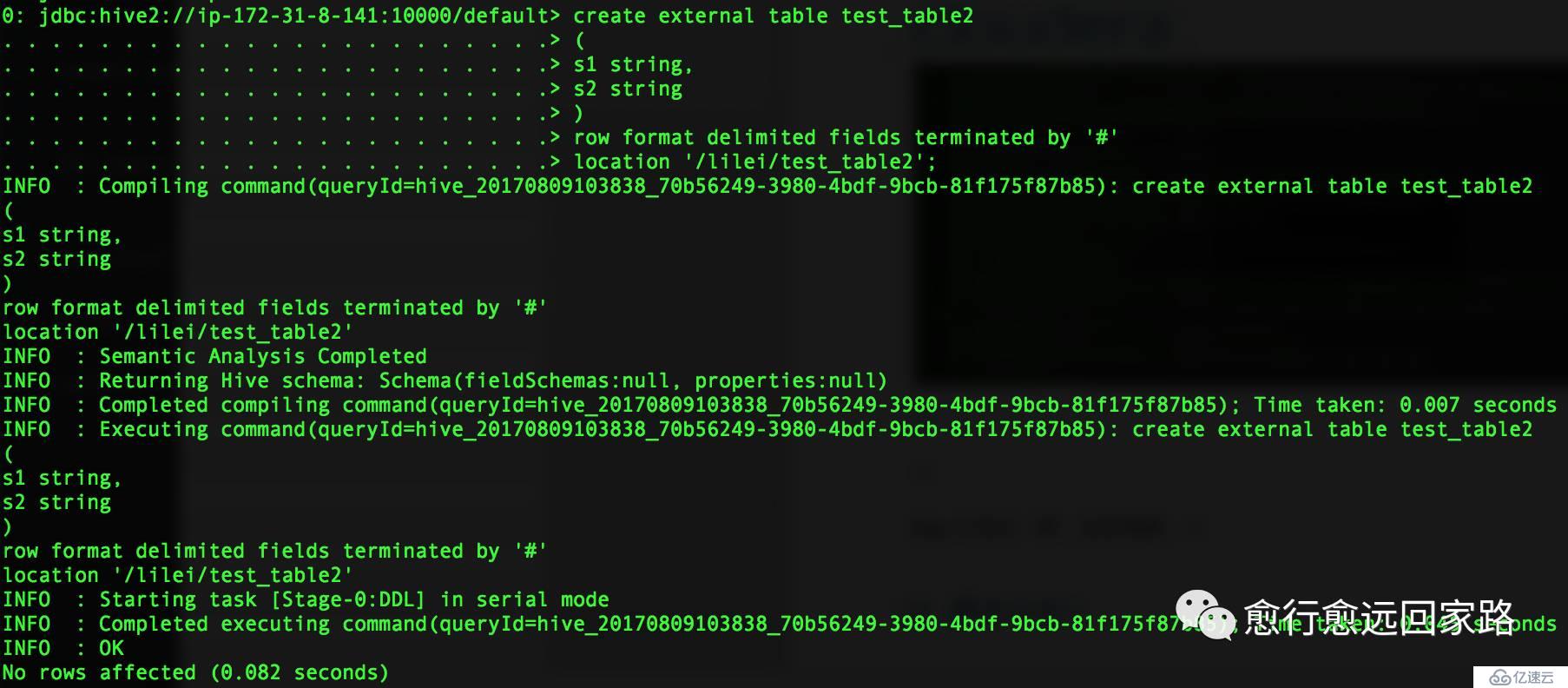
йҰ–е…ҲжҲ‘еңЁжІЎеҒҡйўқеӨ–й…ҚзҪ®зҡ„жғ…еҶөдёӢпјҢз”ҹжҲҗLzoж–Ү件并иҜ»еҸ–гҖӮжҲ‘们еңЁHiveдёӯеҲӣе»әдёӨеј иЎЁпјҢtest_tableе’Ңtest_table2пјҢtest_tableжҳҜж–Үжң¬ж–Ү件зҡ„иЎЁпјҢtest_table2жҳҜLzoеҺӢзј©зј–з Ғзҡ„иЎЁгҖӮеҰӮдёӢпјҡ
| create external table test_table(s1 string,s2 string)row format delimited fields terminated by '#'location '/lilei/test_table'; insert into test_table values('1','a'),('2','b'); create external table test_table2(s1 string,s2 string)row format delimited fields terminated by '#'location '/lilei/test_table2'; |
|---|
йҖҡиҝҮbeelineи®ҝй—®Hive并жү§иЎҢдёҠйқўе‘Ҫд»Өпјҡ
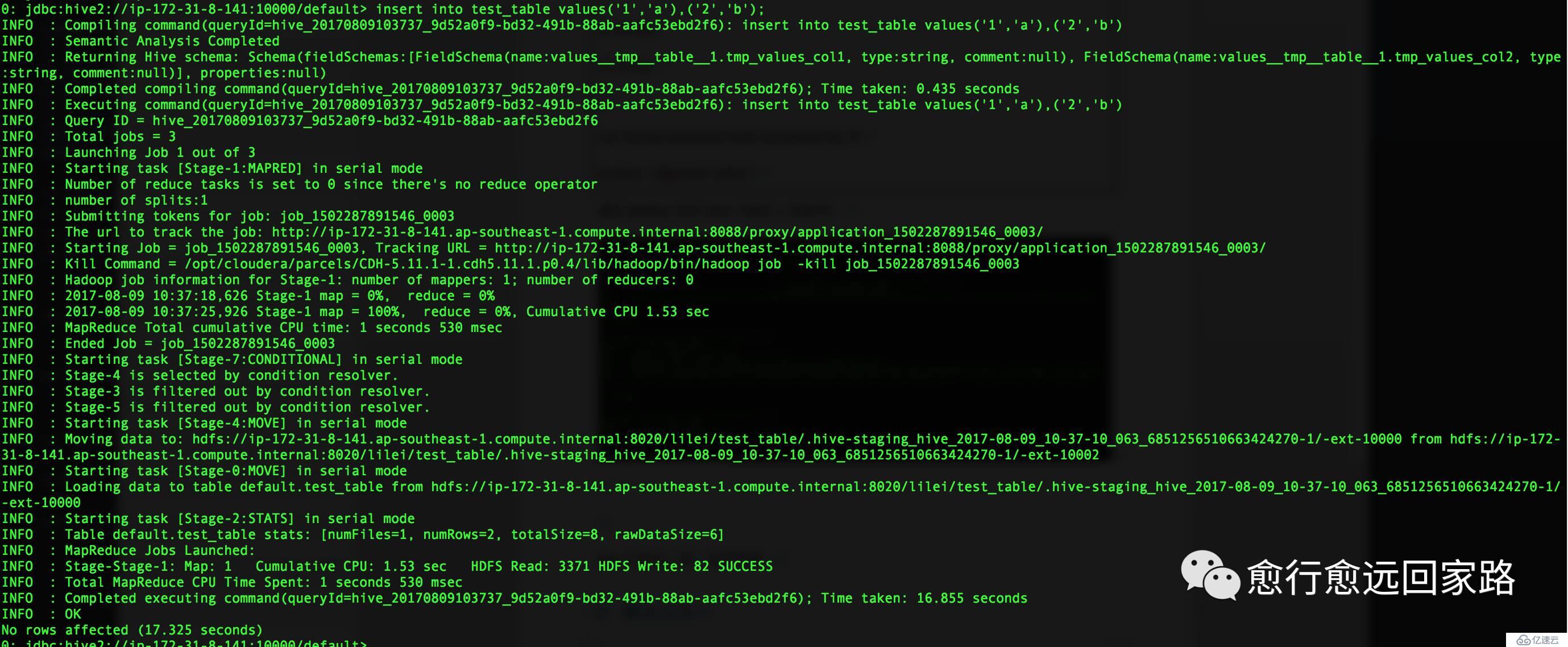
жҹҘиҜўtest_tableдёӯзҡ„ж•°жҚ®пјҡ

е°Ҷtest_tableдёӯзҡ„ж•°жҚ®жҸ’е…ҘеҲ°test_table2пјҢ并и®ҫзҪ®иҫ“еҮәж–Ү件дёәlzoеҺӢзј©пјҡ
| set mapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.LzoCodec;set hive.exec.compress.output=true;set mapreduce.output.fileoutputformat.compress=true;set mapreduce.output.fileoutputformat.compress.type=BLOCK; insert overwrite table test_table2 select * from test_table; |
|---|
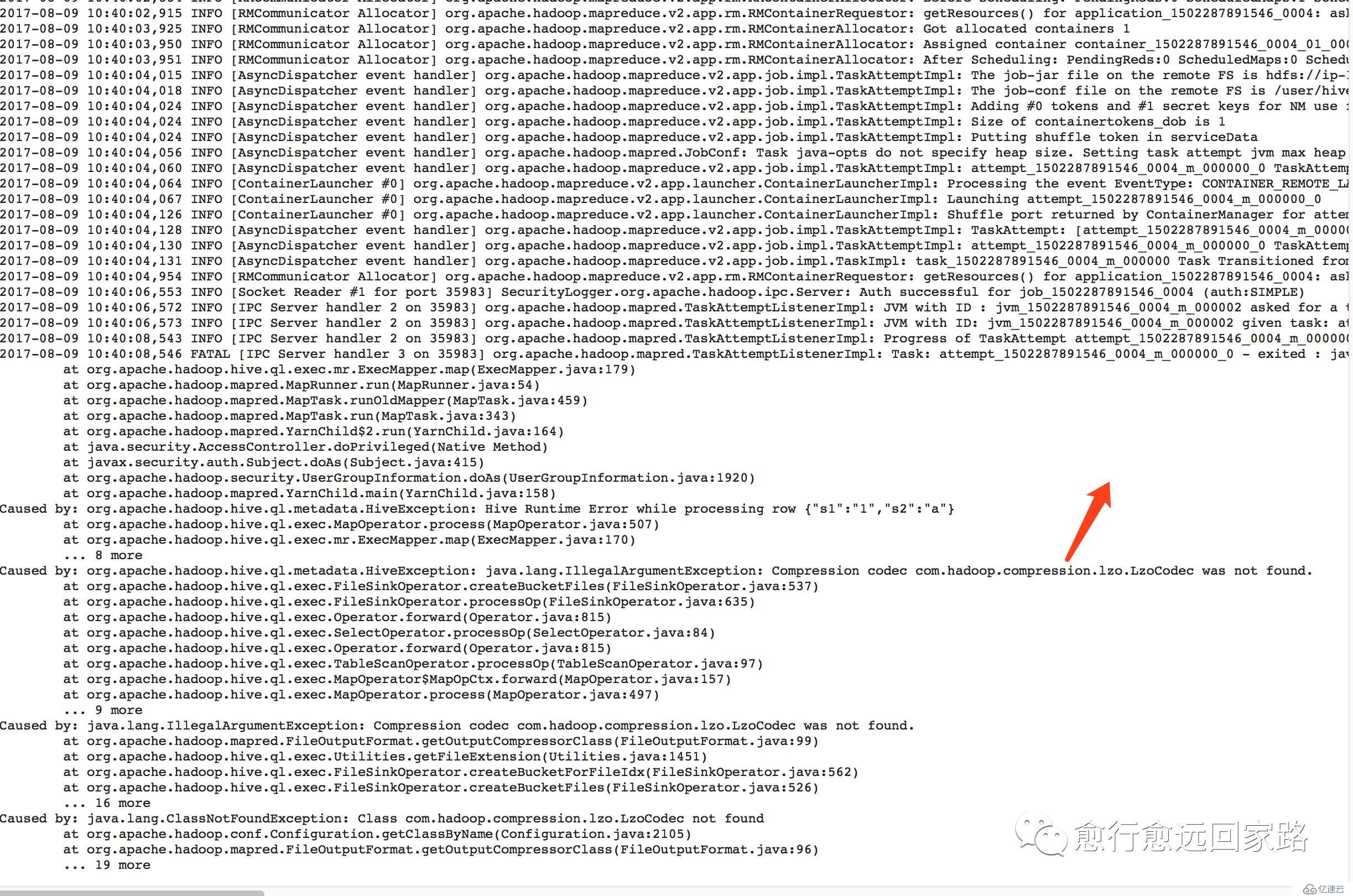
еңЁHiveдёӯжү§иЎҢжҠҘй”ҷеҰӮдёӢпјҡ
| Error:Error while processing statement: FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask (state=08S01,code=2) |
|---|
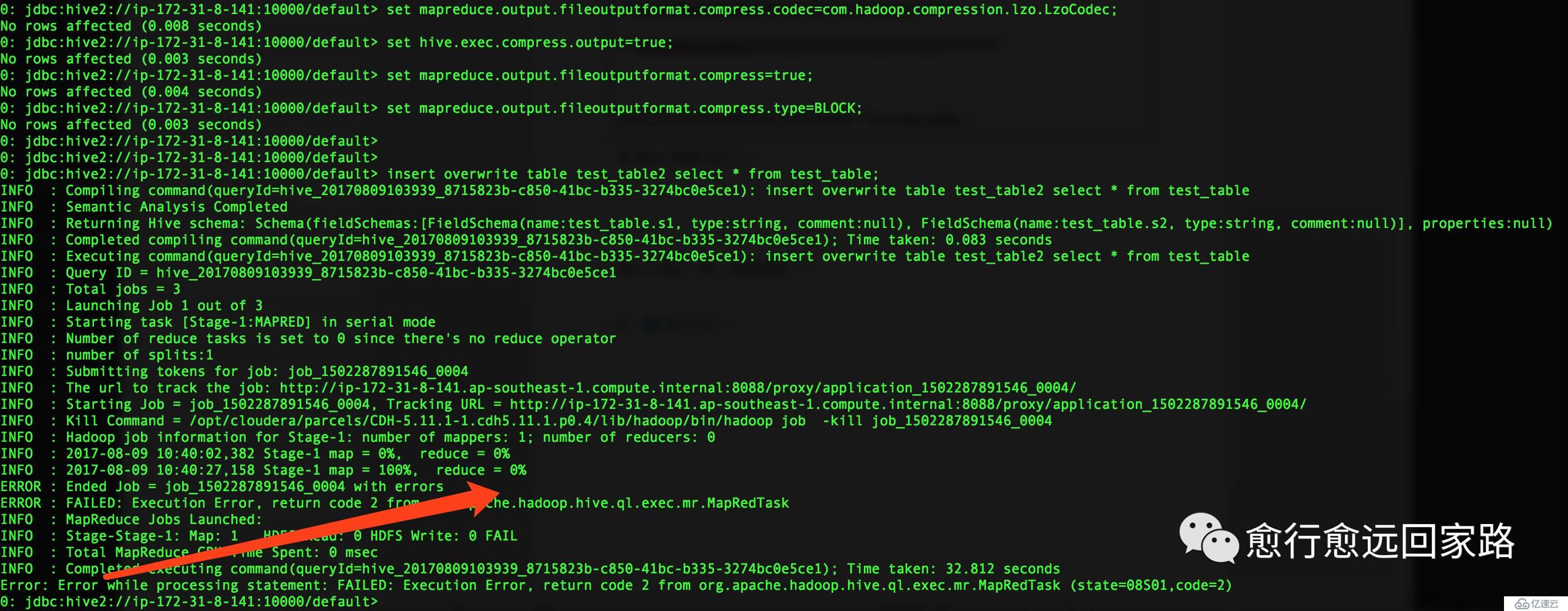
йҖҡиҝҮYarnзҡ„8088еҸҜд»ҘеҸ‘зҺ°жҳҜеӣ дёәжүҫдёҚеҲ°LzoеҺӢзј©зј–з Ғпјҡ
| Compression codec com.hadoop.compression.lzo.LzoCodec was not found. |
|---|
2.и§ЈеҶіеҠһжі•
йҖҡиҝҮCloudera Managerзҡ„ParcelйЎөйқўй…ҚзҪ®Lzoзҡ„ParcelеҢ…ең°еқҖпјҡ
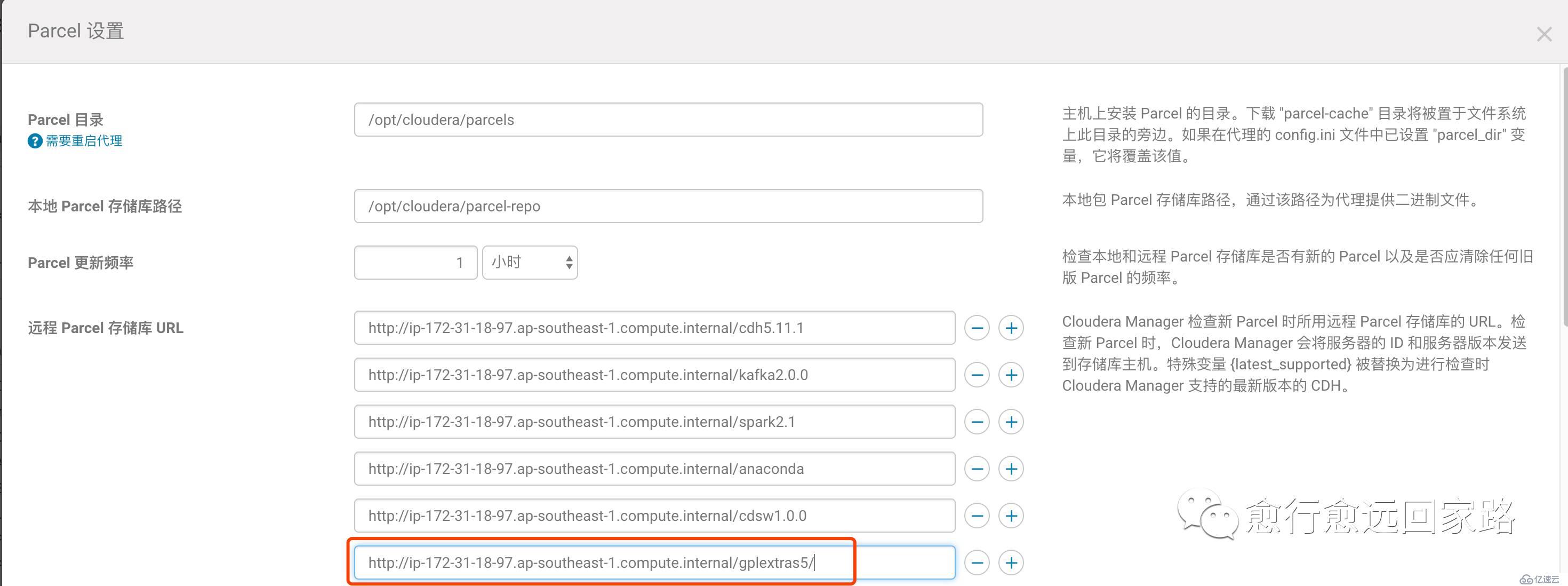
жіЁж„ҸпјҡеҰӮжһңйӣҶзҫӨж— жі•и®ҝй—®е…¬зҪ‘пјҢйңҖиҰҒжҸҗеүҚдёӢиҪҪеҘҪParcelеҢ…并еҸ‘еёғеҲ°httpd
дёӢиҪҪ->еҲҶй…Қ->жҝҖжҙ»





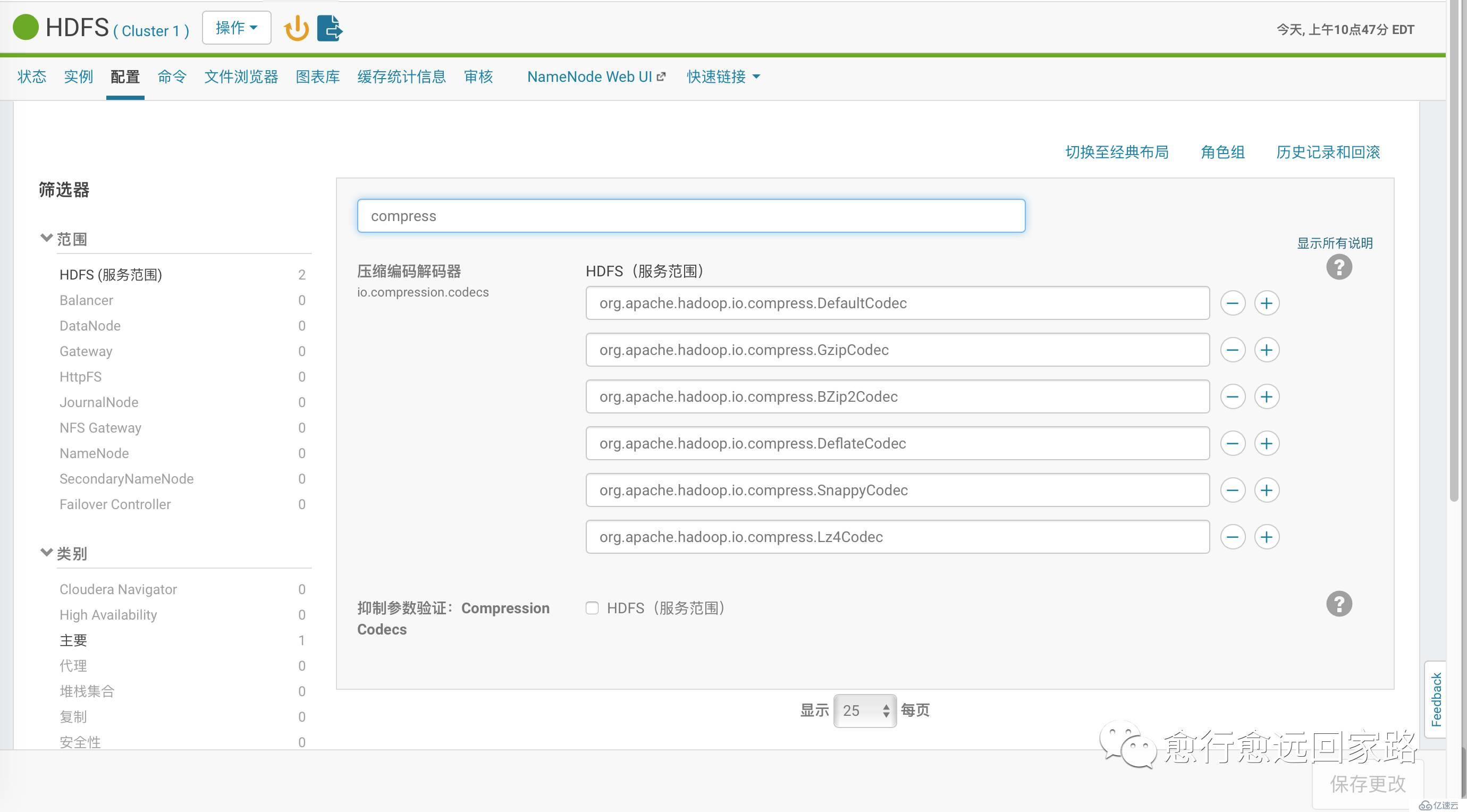
й…ҚзҪ®HDFSзҡ„еҺӢзј©зј–з ҒеҠ е…ҘLzoпјҡ
| com.hadoop.compression.lzo.LzoCodeccom.hadoop.compression.lzo.LzopCodec |
|---|
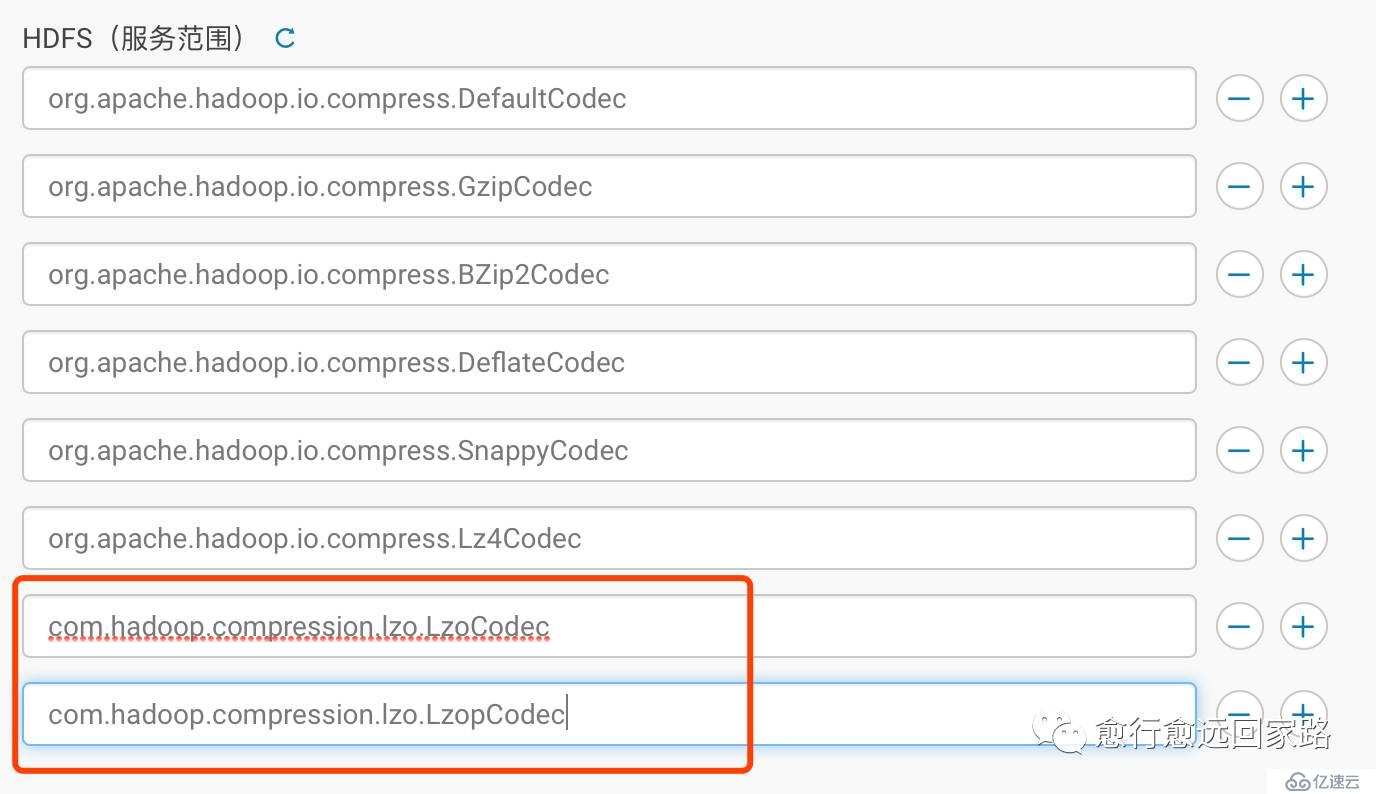
дҝқеӯҳжӣҙж”№пјҢйғЁзҪІе®ўжҲ·з«Ҝй…ҚзҪ®пјҢйҮҚеҗҜж•ҙдёӘйӣҶзҫӨгҖӮ
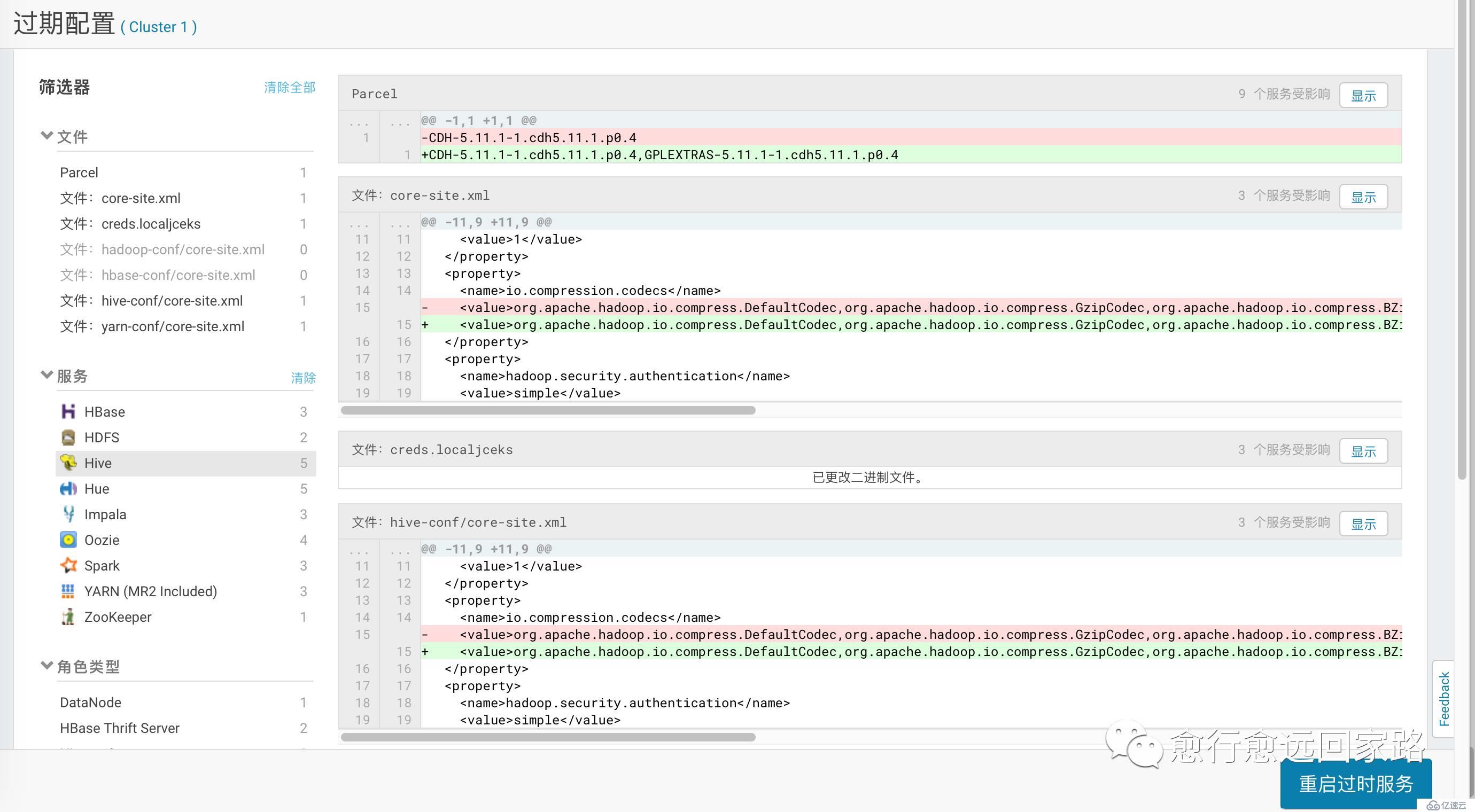
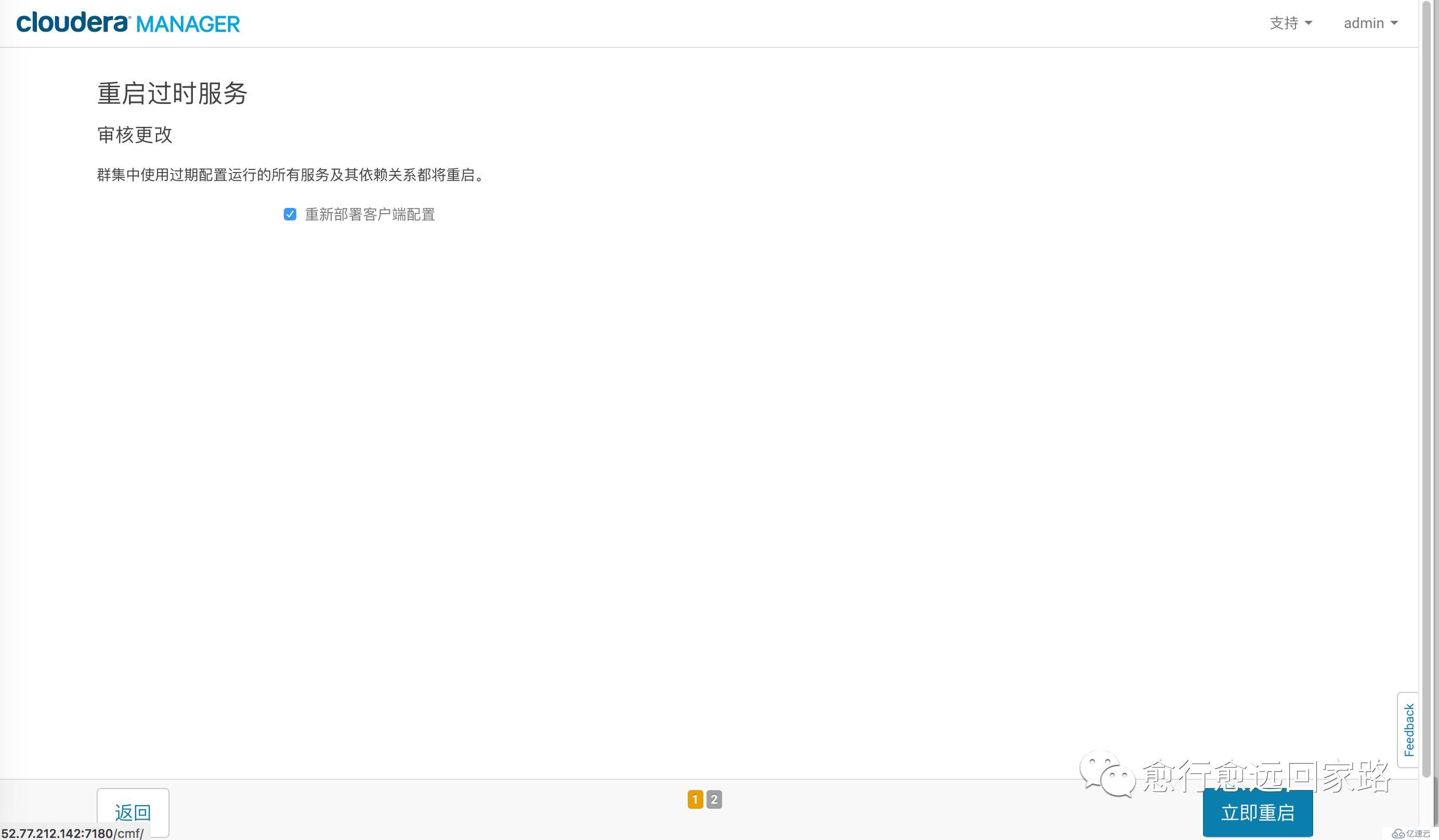
зӯүеҫ…йҮҚеҗҜжҲҗеҠҹпјҡ
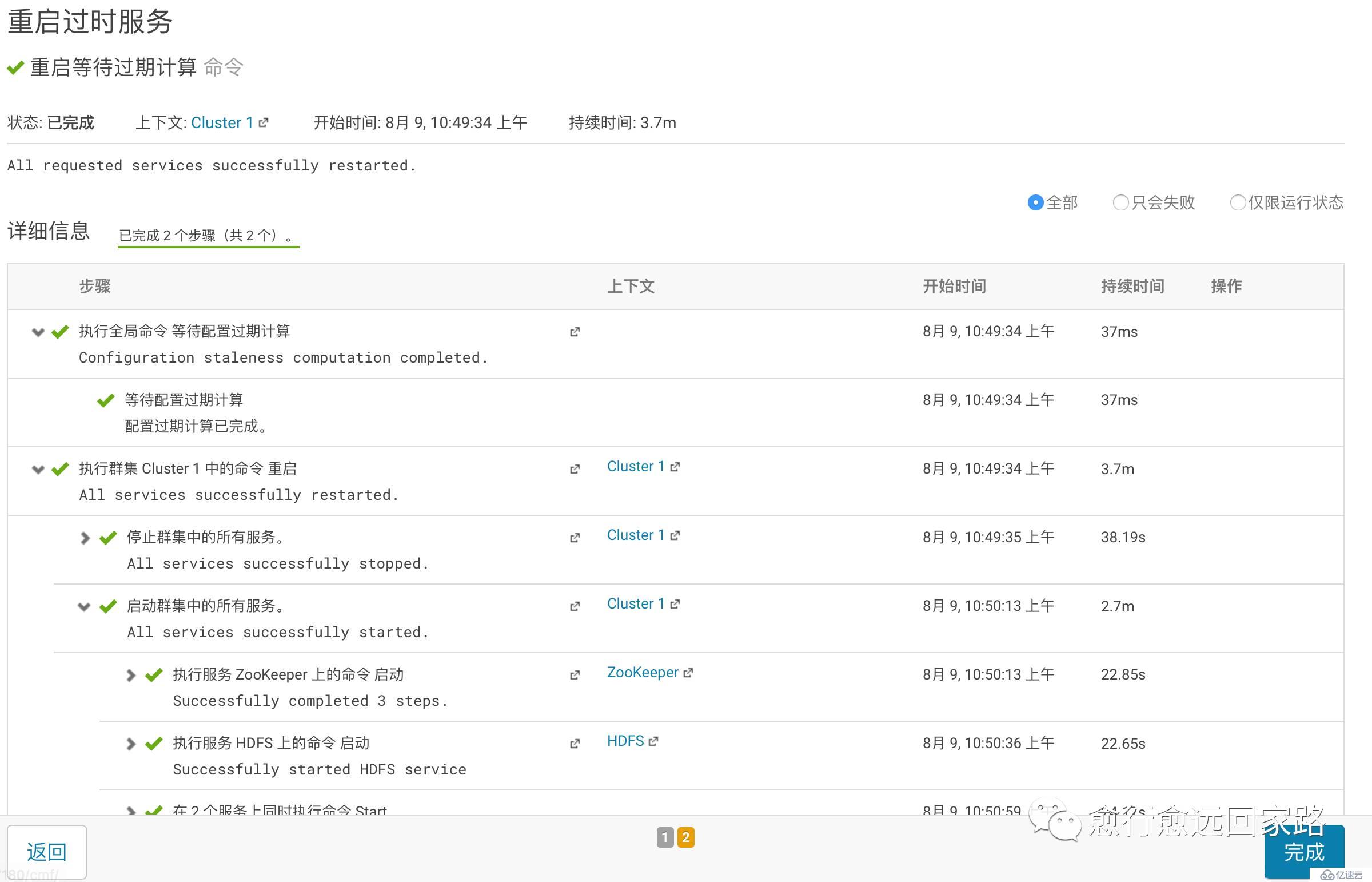
еҶҚж¬ЎжҸ’е…Ҙж•°жҚ®еҲ°test_table2пјҢи®ҫзҪ®дёәLzoзј–з Ғж јејҸпјҡ
| set mapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.LzoCodec;set hive.exec.compress.output=true;set mapreduce.output.fileoutputformat.compress=true;set mapreduce.output.fileoutputformat.compress.type=BLOCK; insert overwrite table test_table2 select * from test_table; |
|---|
жҸ’е…ҘжҲҗеҠҹпјҡ
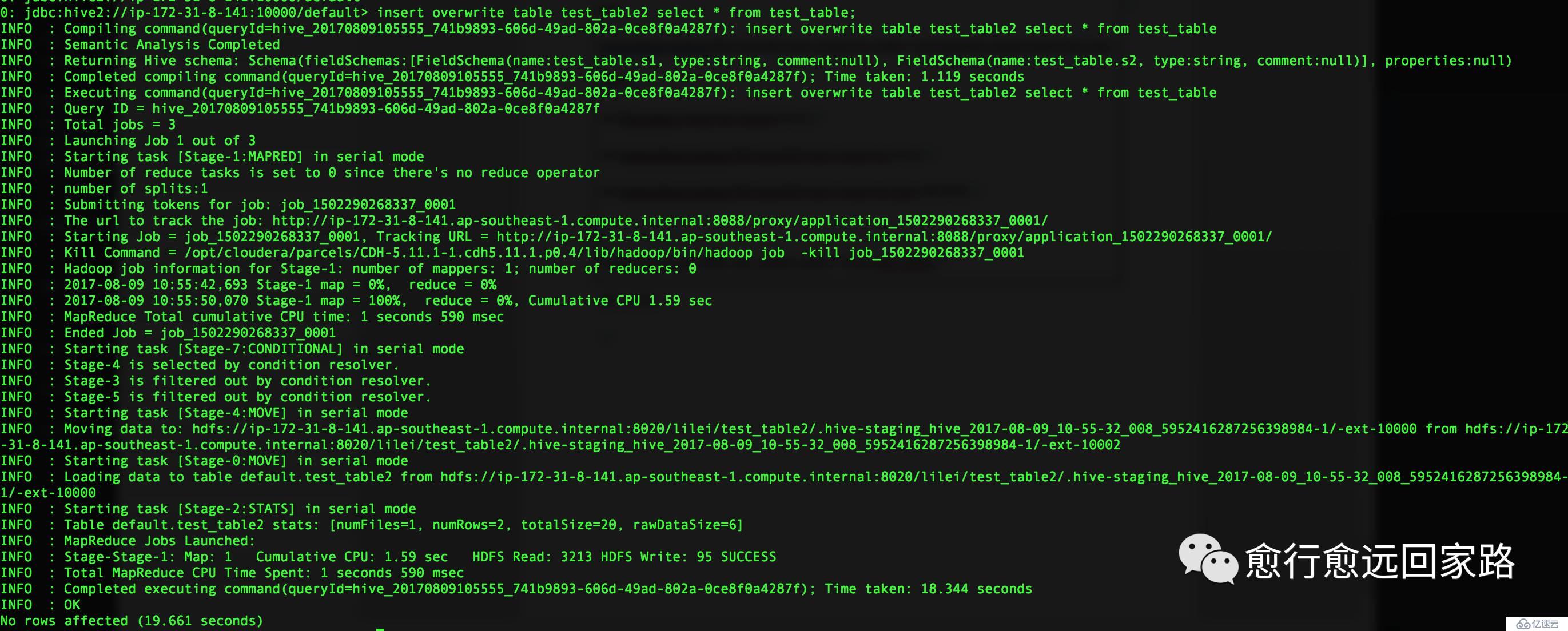
йҰ–е…ҲзЎ®и®Өtest_table2дёӯзҡ„ж–Ү件дёәLzoж јејҸпјҡ

еңЁHiveзҡ„beelineдёӯиҝӣиЎҢжөӢиҜ•пјҡ

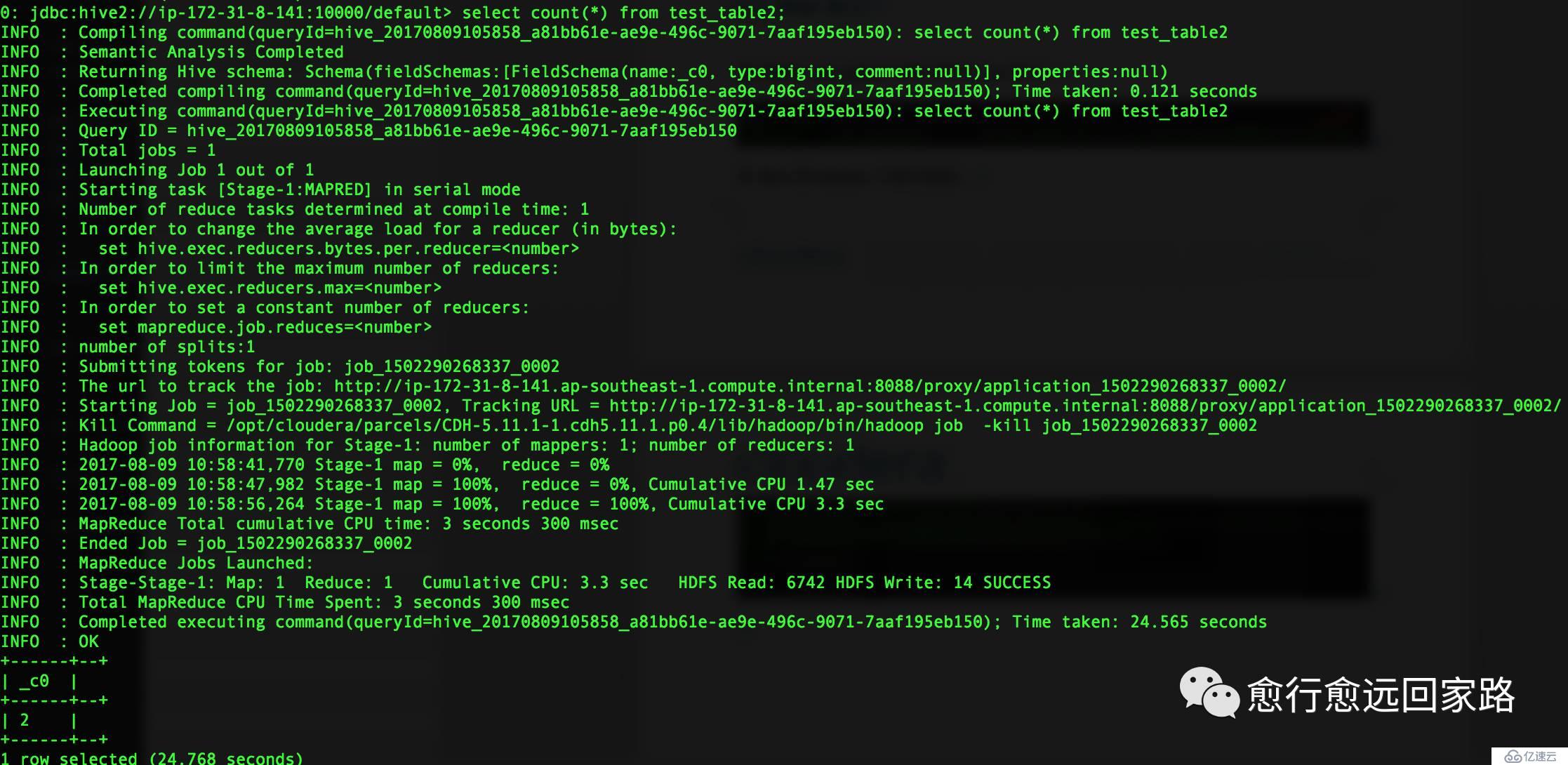
HiveеҹәдәҺLzoеҺӢзј©ж–Ү件иҝҗиЎҢжӯЈеёёгҖӮ
2.2 Spark SQLйӘҢиҜҒ
| var textFile=sc.textFile("hdfs://ip-172-31-8-141:8020/lilei/test_table2/000000_0.lzo_deflate") textFile.count() sqlContext.sql("select * from test_table2") |
|---|
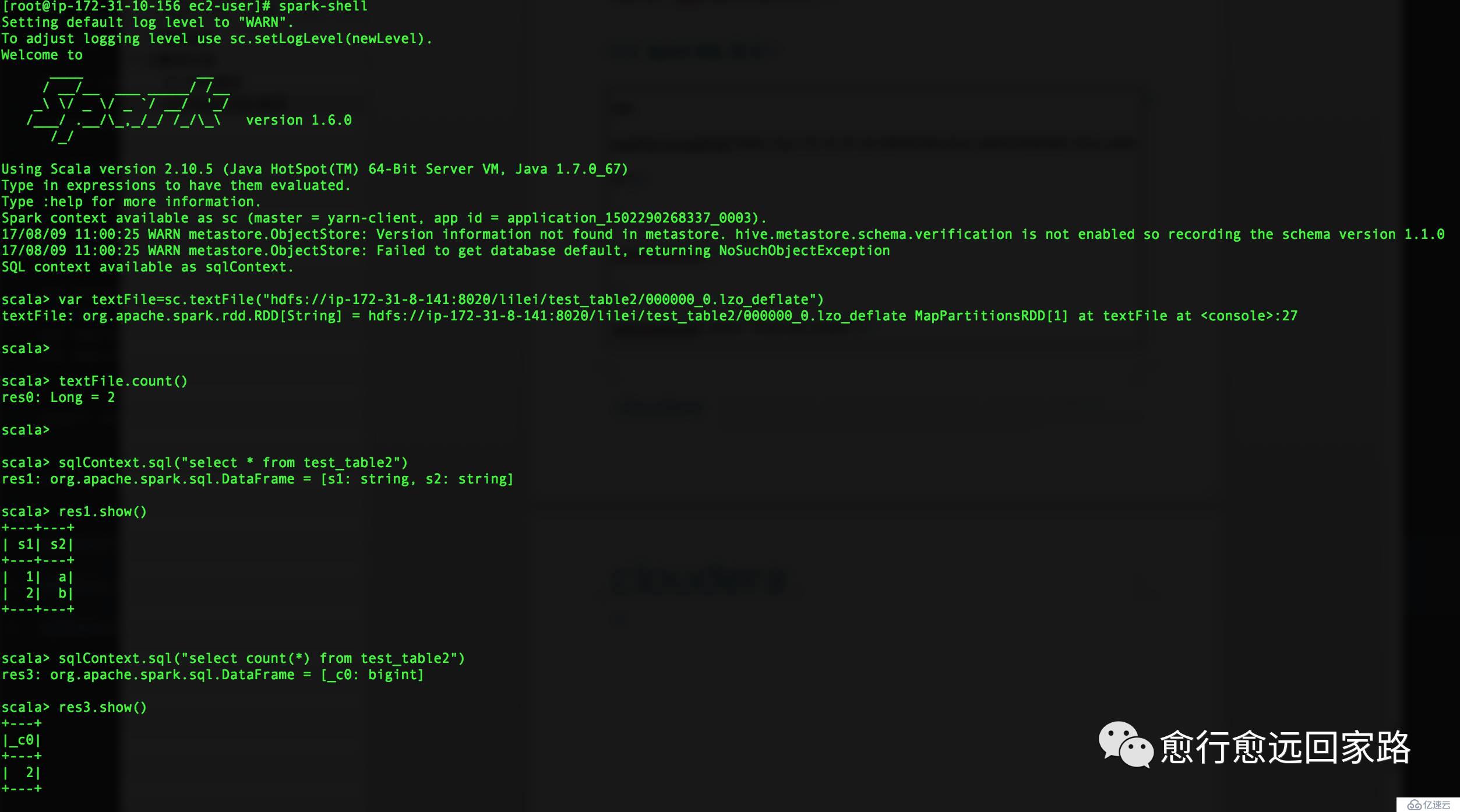
SparkSQLеҹәдәҺLzoеҺӢзј©ж–Ү件иҝҗиЎҢжӯЈеёёгҖӮ
йҶүй…’йһӯеҗҚ马пјҢе°‘е№ҙеӨҡжө®еӨёпјҒ еІӯеҚ—жөЈжәӘжІҷпјҢе‘•еҗҗй…’иӮҶдёӢпјҒжҢҡеҸӢдёҚиӮҜж”ҫпјҢж•°жҚ®зҺ©зҡ„иҠұпјҒ

жё©йҰЁжҸҗзӨәпјҡиҰҒзңӢй«ҳжё…ж— з ҒеҘ—еӣҫпјҢиҜ·дҪҝз”ЁжүӢжңәжү“ејҖ并еҚ•еҮ»еӣҫзүҮж”ҫеӨ§жҹҘзңӢгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ