您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
如何使用UCSC XENA综合性分析某一个基因在癌症当中的作用,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
今天我们就基于UCSC XENA来简单的设计一个简单的课题。
之前在介绍ICGC数据库使用的时候,我们可以通过ICGC数据库来进行整个基因组的检索。比如来查看某个或者某几个肿瘤当中突变最多的基因是哪个。但是在UCSC XENA当中我们需要有一定的检索目标。我们没有办法去寻找变化最大的基因。我们只能在提前知道某一个基因之后。然后才能进行相关的查询。但是UCSC XENA比ICGC好的地方在于。ICGC只能查询突变相关的信息,而在XENA当中,我们则可以检索和这个基因所有相关的信息以及和临床特征的相关性。
由于XENA只能检索指定的基因来进行检索,所以我们在检测的第一步需要选择一个目标基因。为了方便选择,我们使用GEPIA2来寻找COAD当中最有差异的前10的基因来进行后续的分析
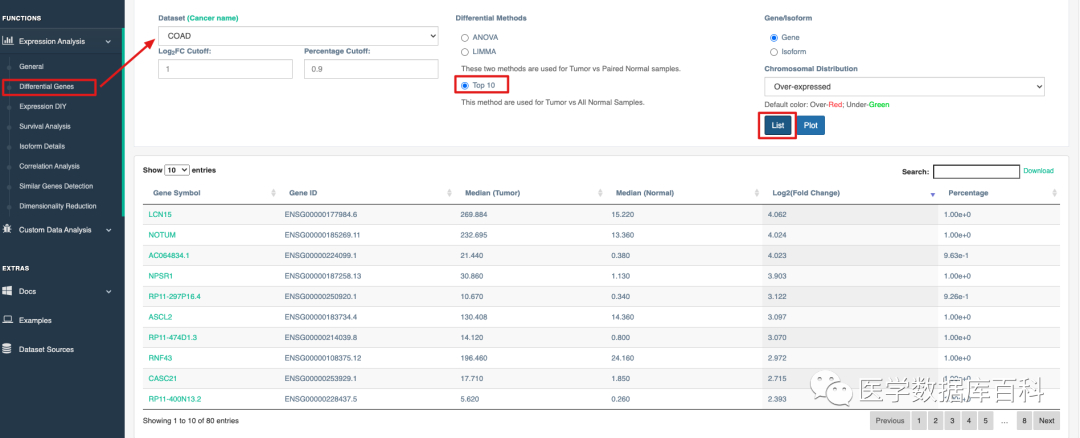
经过这样的筛选,我们一共获得了五个在COAD当中高表达的基因。这十个基因分别是:LCN15 ,NOTUM ,NPSR1,ASCL2 ,RNF43。
经过这样的筛选,我们知道了这几个基因是和COAD的发生有关系的。但是对于COAD临床参数的影响,我们不是很清楚。所以进一步的我们想要看COAD当中这十个基因的作用有多大
在XENA当中。我们要做的第一步就是选择目标癌种,我们可以在数据集选择的界面输入关键词就可以获得相关的数据集了。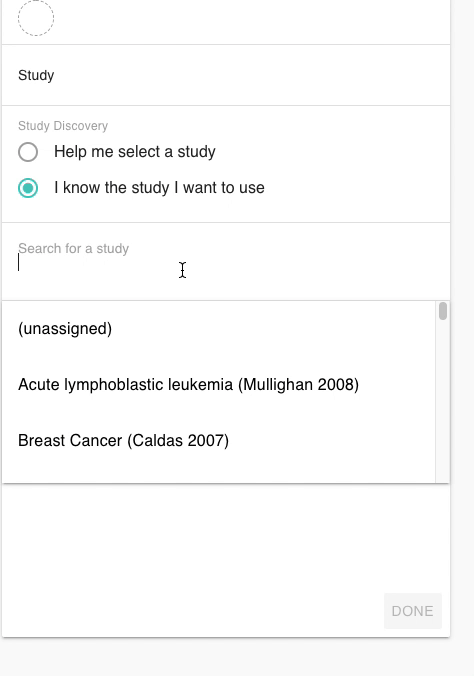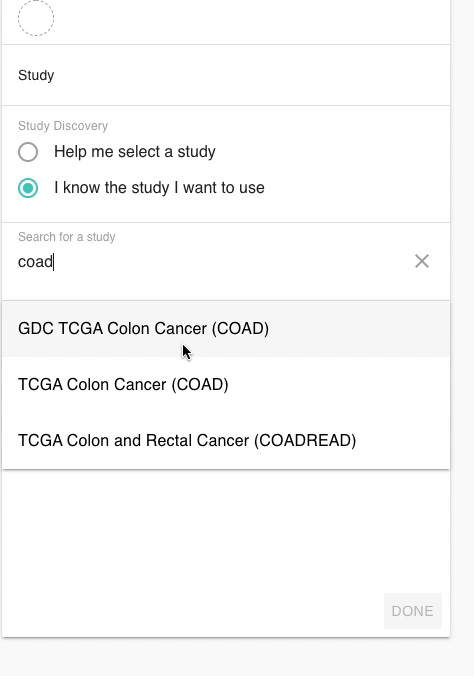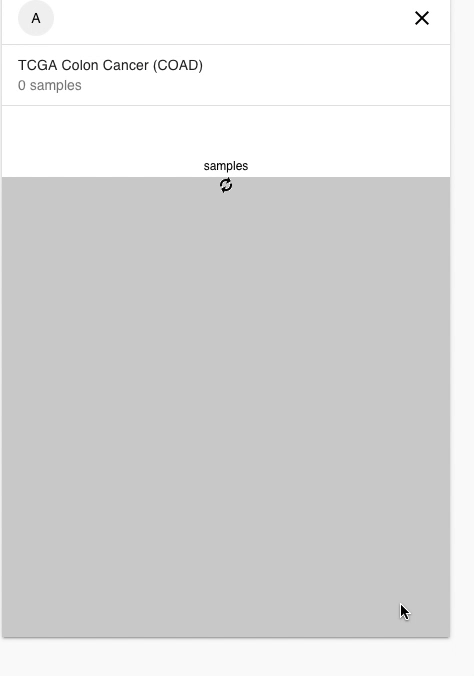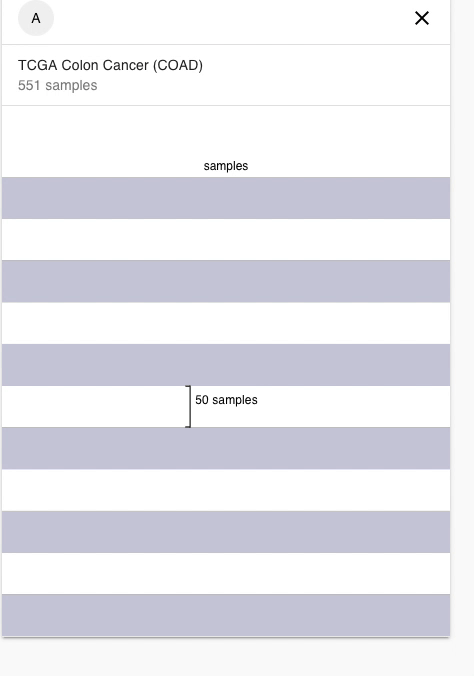
由于我们要对基因表达进行分析。所以第一步就是放置基因相关的表达信息。在XENA里面,对于多基因的表达信息提取,有两种方式:
一种是直接把所有基因都放进去,这样的话就可以在一个模块当中获得所有目标基因的表达信息,
另外一种的话就是一个基因一个基因的选择。
前面一种除了可视化好一些,在后面和临床参数分析方面,也可以一次性现实所有的结果,而后面一种则是可以来进行预后的KM分析。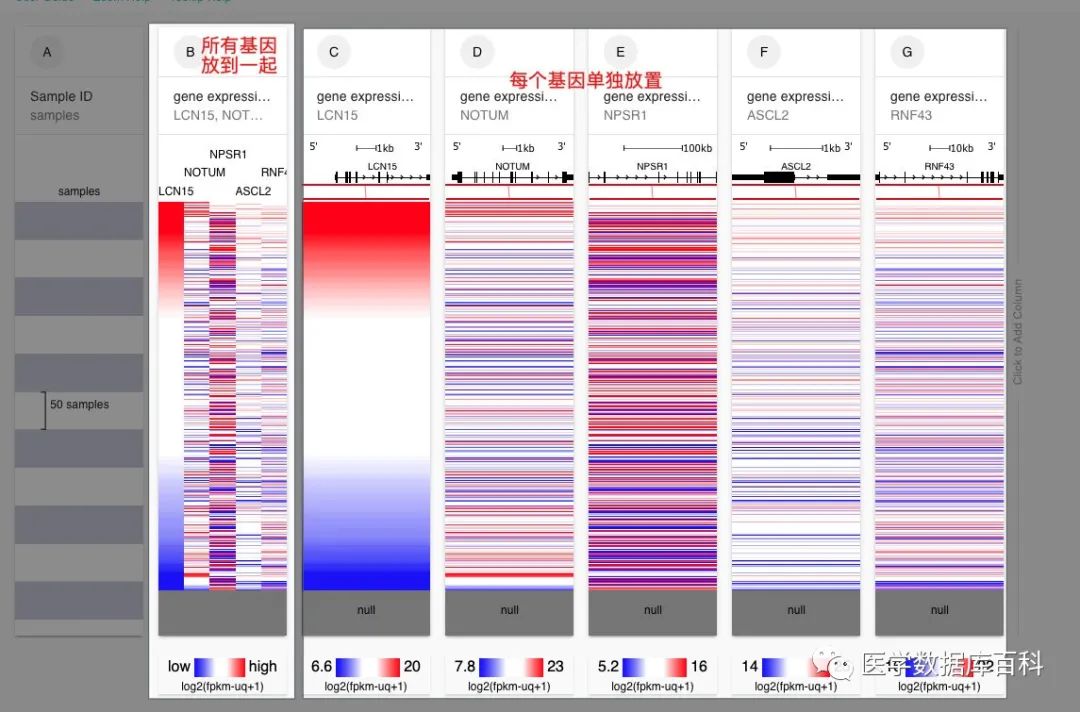
我们在做生信分析的时候,除了差异表达分析,做的第二多的可能就是预后分析了。在XENA 当中,我们对于每一个单数据的模块,都可以进行预后分析。如果是连续性的,XENA会自动分成两组来进行KM分析,如果是分类变量那么就可以直接进行分析了。
PS:上面我们也说了。对于预后分析的时候,基因的表达是要单纯一个模块的。所以对于融合到一起的结果。我们是不能进行分析的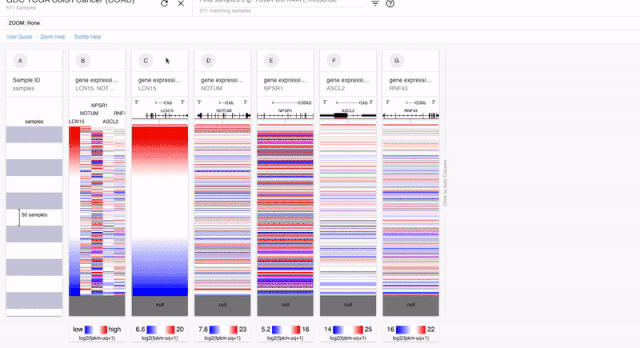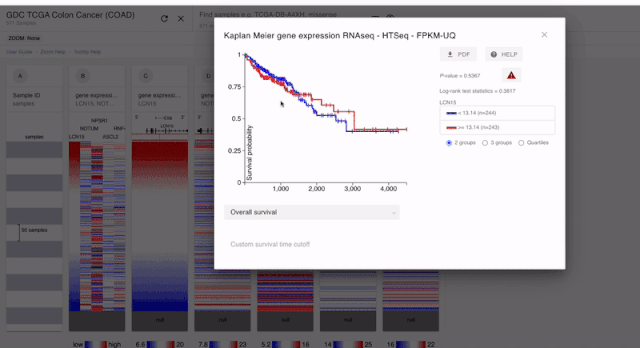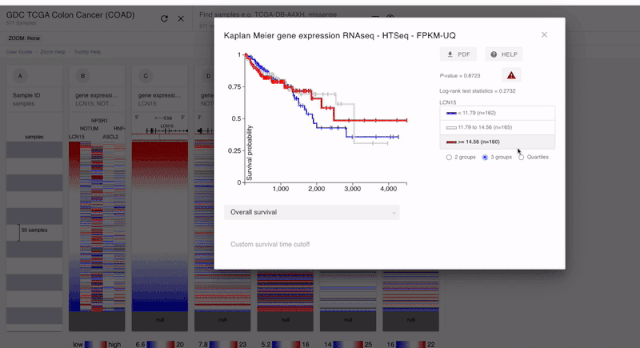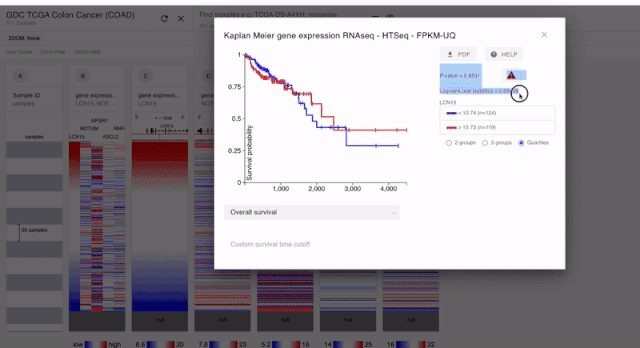
通过以上的分析,我们就可以获得五个基因的预后分析的结果了。经过分析,我们发现这五个基因和预后都没有关系????。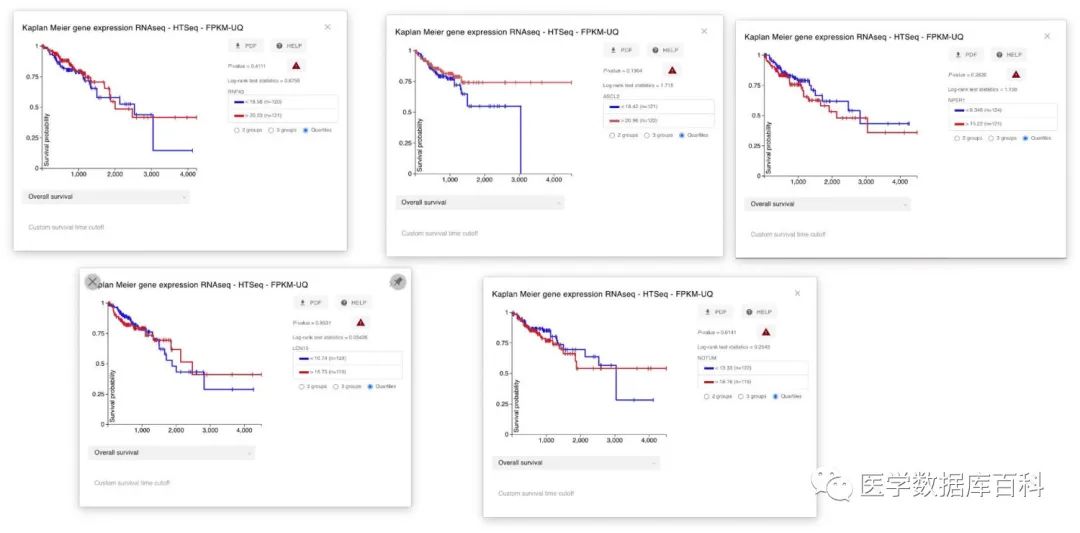
如果XENA只是可以做和预后相关的分析的话,那么其实很多数据库都是可以做的(GEPIA, Cbio等等)。XENA更好的一点在于,它提供了TCGA里面所有相关的临床病理参数的结果。我们可以做其他数据库做不了的临床参数的分析。比如:TNM分期这种的。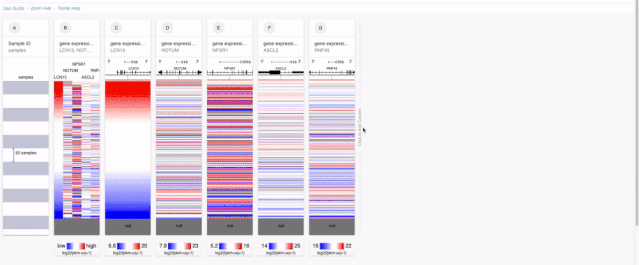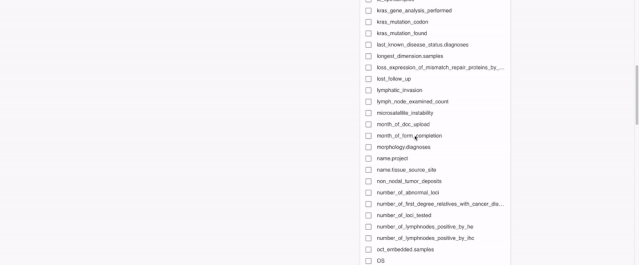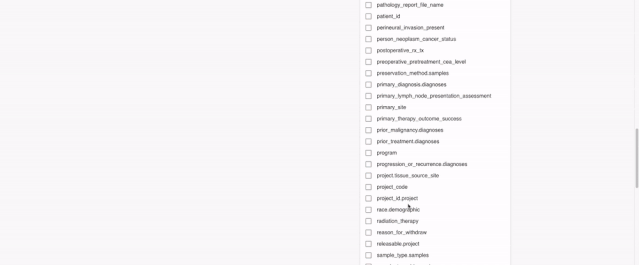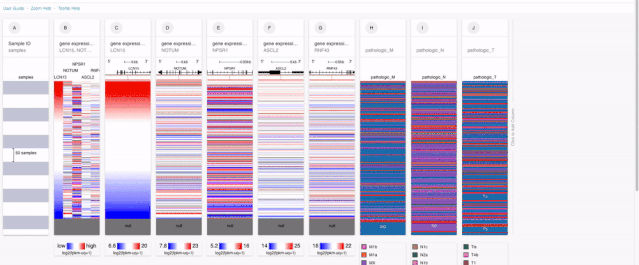
经过一顿的数据添加,我们最终就得到了在COAD当中含有基因表达以及TNM分期数据的数据集。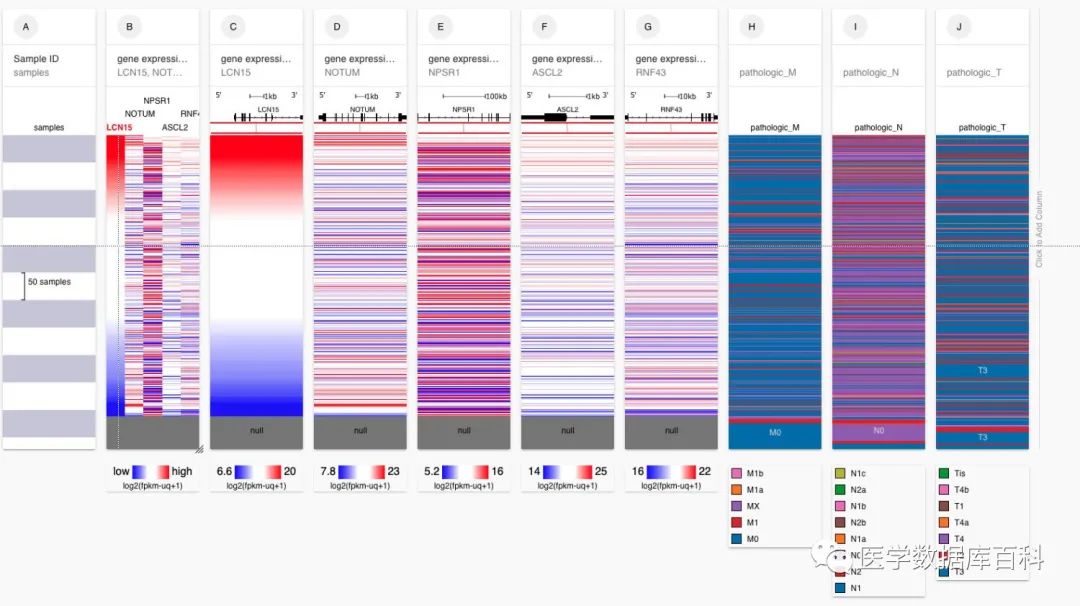
在得到最终想要分析的数据之后,我们发现由于XENA提供的没有经过修改的数据,所以类似临床数据是需要经过处理的。例如M分期当中:就包含:M0, M1, M1a, M1b以及Mx这个不确定分期的数据变量。

这个时候,最直接的方法,就是我们点击Download然后下载到所有的原始数据之后,然后自己来处理数据,然后进行统计分析。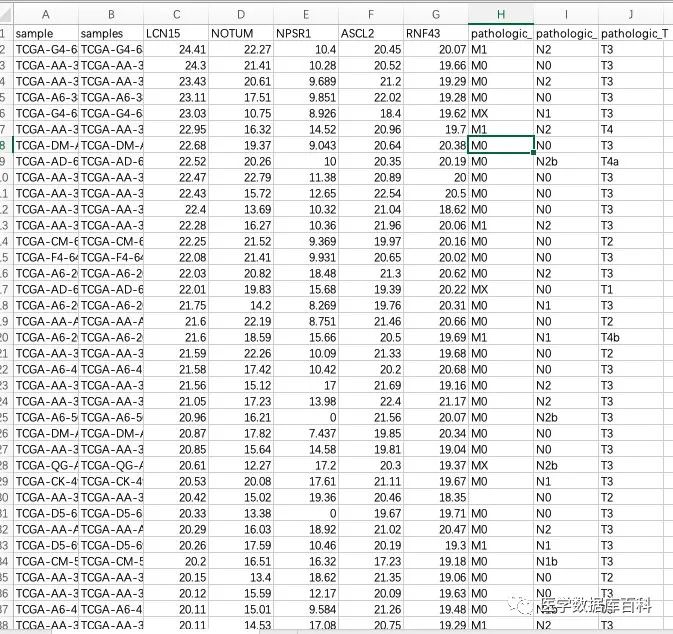
如果说,那我自己对于数据的处理和分析不是很熟练,那这个时候就可以利用XENA自带的筛选功能来进行分析了。
这里我们利用M分期为例来进行演示XENA的筛选分析。由于操作过程教程。所以就简单的做了一个视频。关于XENA具体的筛选原则可以参考: https://ucsc-xena.gitbook.io/project/overview-of-features/filter-and-subgrouping
最终通过分析,我们得到了NOTUM在M分期当中存在差异表达。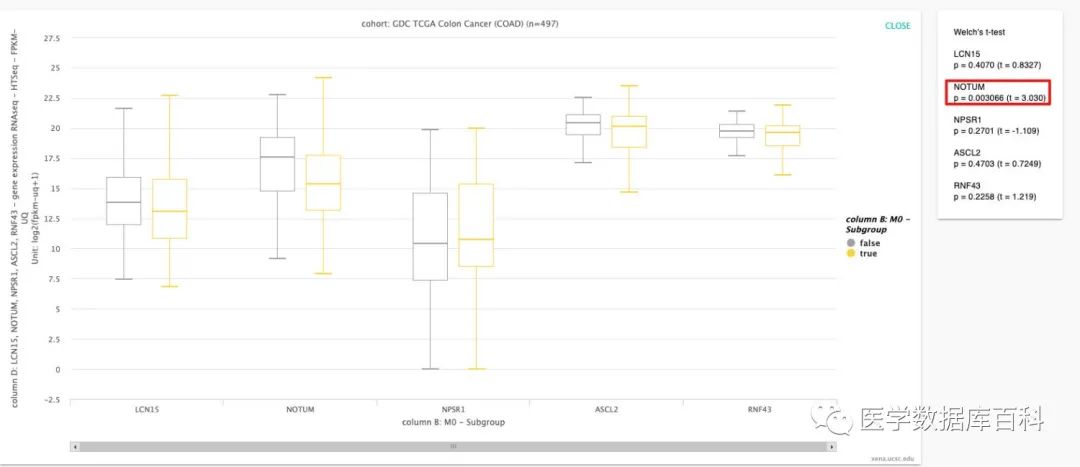
关于如何使用UCSC XENA综合性分析某一个基因在癌症当中的作用问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。