您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
如今,随着业务“互联网化”和“智能化”的发展以及架构 “微服务”和“云化”的发展,应用系统对数据的存储管理提出了新的标准和要求,数据的多样性成为了数据库平台面临的一大挑战,数据库领域也催生了一种新的主流方向。
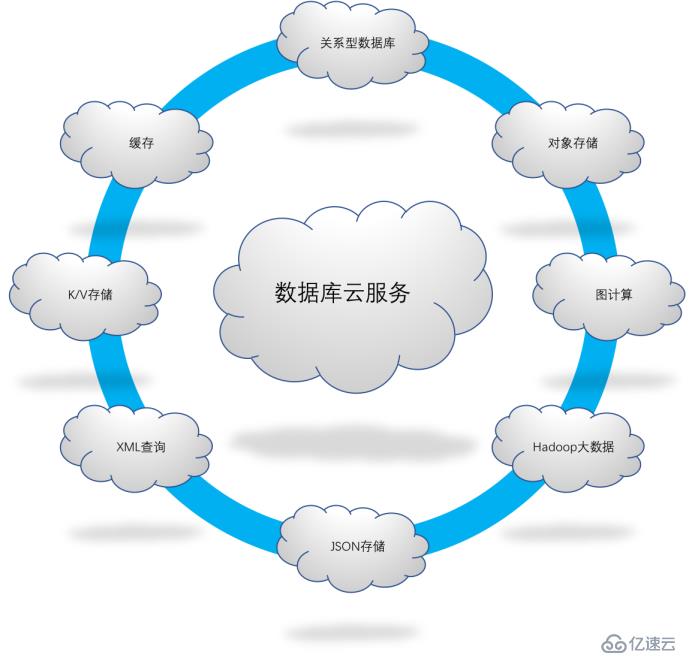
数据库多模Multi-Model是指同一个数据库支持多个存储引擎,可以同时满足应用程序对于结构化、半结构化、非结构化数据的统一管理需求。
1.数据库云化需求催生Multi-Model多模
企业使用云数据库对接的应用越来越多,需求多种多样,传统的做法是在dbPaaS里面提供十几个不同的数据库产品分别应对各种需求,这样的方法在系统增加后,整体维护性和数据一致性管理成本很高,会影响到整个系统的使用。
云数据库的“多模”示意图
为了实现业务数据的统一管理和数据融合,新型数据库需要具备多模式(Multi-Model)数据管理和存储的能力。通常来说,结构化数据特指表单类型的数据存储结构,典型应用包括银行核心交易等传统业务; 而半结构化数据则在用户画像、物联网设备日志采集、应用点击流分析等场景中得到大规模使用;非结构化数据则对应着海量的的图片、视频、和文档处理等业务,在金融科技的发展下增长迅速。
多模式数据管理能力,使得数据库能够进行跨部门、跨业务的数据统一存储与管理,实现多业务数据融合,支撑多样化的应用服务。在架构上,多模Multi-model也是针对云数据库需求的,则使得数据库使用一套数据管理体系可以支撑多种数据类型,因此支持多种业务模式,大大降低使用和运维的成本。
2.Multi-Model存储引擎架构
数据库是现有许多业务系统的核心。随着数据生成与采集技术的飞速发展,数据量不断爆炸式增长,数据的结构也越来越灵活多样。传统基于关系型理论构建起来的数据库管理系统,面对大数据、人工智能的真正到来,在成本、性能、扩展性、容错能力等方面遭遇到了不小的挑战。
面对多类型的的结构化数据、半结构化数据、非结构化数据,现代应用程序对不同的数据提出了不同的存储要求,数据库因此也需要适应这种多类型数据管理的需求。
比较流行的两种解决思路分别是:混合持久化(Polyglot Persistence)与多模数据库(Multi-Model Database)。
1)混合持久化 Polyglot Persistence
混合持久化的思路是指,用户根据工作的不同需求分别选择使用合适的数据库,这样在一个完整的系统中,可能同时运行着多种不同的数据库。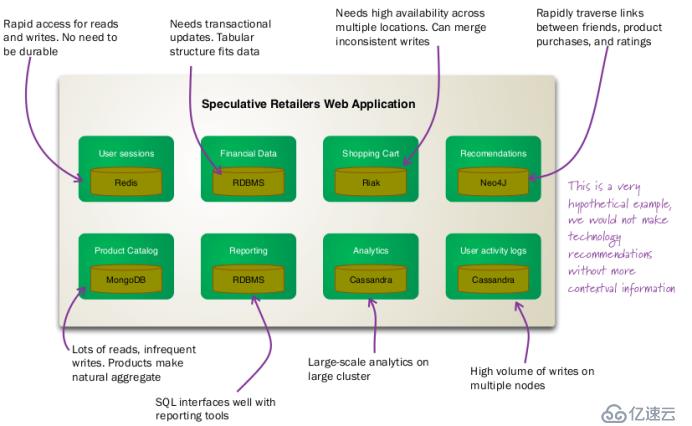
图1 Polyglot Persistence示意图
混合持久化一个显著的优点就是单一流程的性能提升,但缺点也同样的显而易见:以增加复杂性和学习成本为代价,在部署、使用及维护上带来了挑战。
2)多模Multi-Model
Multi-model多模数据库则是另一种解决思路,在同一个数据库内有多个数据引擎,将各种类型的数据进行集中存储和使用。多个不同类型的应用,同时接入一个数据库,并在同一个分布式数据库内进行管理,大大简化应用程序的开发及后期维护成本。
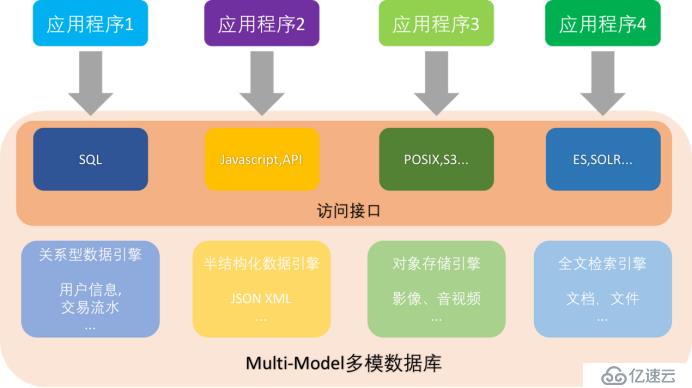
图2:多模数据库引擎架构示意图
图为多模Multi-Model数据库的示意图,我们可以看到在同一个存储引擎里面同时具备 关系型数据、JSON半结构化数据、对象数据以及全文检索引擎等等多个数据引擎,统一提供给应。这一架构大大降低开发和运维的难度,应用统一连接到数据库,数据库内部进行数据的划分、隔离和管理,对应用来说只需要连接到数据库即可,无需为了每个应用搭建对应的数据后台。
3.存储数据结构
针对多模数据库的需求,分布式数据库的存储数据结构也会有新的创新。以下就是SequoiaDB在Multi-model方面,进行的数据存储结构和访问的设计和实现,可以作为Multimodel数据库的一个很好的参考。
3.1 结构化、半结构化数据存储
结构化数据的特点是结构固定,每一行的属性是相同的,如传统关系型数据库表中的数据。半结构化数据是一种自描述结构,它包含相关标记用来分隔语义元素及对记录和字段进行分层,如 XML,JSON 等。
存储结构
如何在数据引擎中同时管理结构化和半结构化数据呢?SequoiaDB 使用JSON 数据模型,在数据库内部使用BSON 格式来将结构化及非结构化数据以文档的形式存储在集合中。
BSON(Binary JSON)是对 JSON 的一种二进制编码数据格式,和 JSON 一样,BSON支持嵌入式的文档和数组。BSON 由若干个键值对存储为单个实体,这种实体称为文档。BSON 包含了 JSON 中的数据类型,并扩展了一些 JSON 中没有的数据类型,如Date,BinData 等。BSON 结构的一个简单示例如下图所示。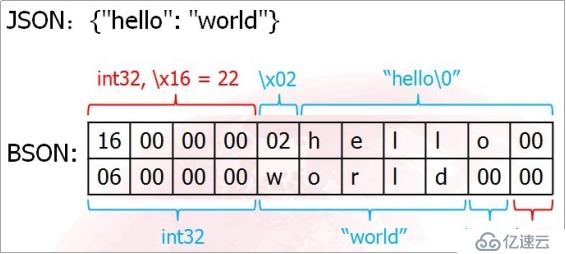
图3: BSON 结构示例
BSON 具有以下几个特性:轻量级(Lightweight),可遍历性(Traversable),高效性(Efficient)。由于BSON结构包含足够的自描述信息,因此它是一种 schema-less 的存储形式。
SequoiaDB将 BSON作为记录的存储结构,由于其良好的灵活性,不需要事先对集合的结构进行定义,每一个记录中包含的字段信息可以相同,也可以不同,并可随时进行修改,这样对结构及半结构化的数据都能以一致的方式统一存储和访问。
SequoiaDB中的数据管理模型如图4所示。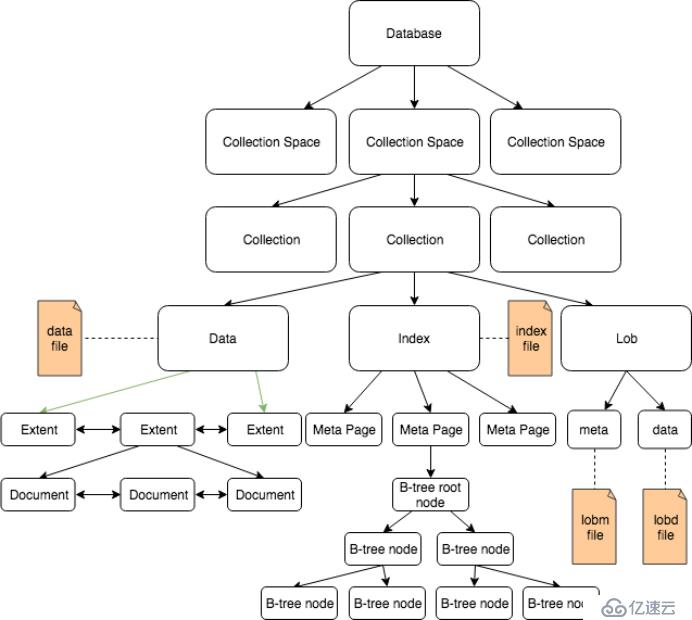
图4: SequoiaDB 数据管理模型架构图
数据最终都是要在磁盘文件中进行持久存储,与之相关的三个概念如下:
文件(File):磁盘上的物理文件,用于持久存储集合数据、索引及 LOB 数据。
页(Page):页是数据库文件中用于组织数据的一种基本结构,SequoiaDB中使用页来对文件中的空间进行管理与分配。
数据块(Extent):由若干个页组成,用于存放记录。
在该模型中,与结构/半结构化数据存储相关的三个核心逻辑概念包括:
集合空间(Collection Space):用于存储集合的对象,物理上对应于一组磁盘上的文件。
集合(Collection):存放文档的逻辑对象。
文档(Document):存储在集合中的记录,以 BSON 结构存储。
一个集合会包含若干个 extent,所有这些 extent使用链表串联起来。当向集合中插入文档时,需要从 extent 中分配空间。如果当前 extent 没有足够空间,则分配新的 extent(必要时对文件进行扩展),挂到该集合的 extent 链表上,然后向其中插入文档。每个 extent 内的记录也通过链表的形式组织起来,这样在进行表扫描时,可顺序读取块内的所有记录。
数据访问
1)SQL
当前大量基于数据库的应用使用 SQL 来进行数据库访问,因此对的 SQL 支持是数据库必不可少的能力。SequoiaDB支持标准 SQL 接口,完全兼容 PostgreSQL 及 MySQL语法和协议,现有的应用可平滑地将存储系统切换为 SequoiaDB,以获得分布式存储系统所带来的扩展性、性能及可靠性等立面的巨大提升。
2)API
SequoiaDB 在结构化数据提供了丰富的 API 接口用于管理整个集群及操作数据,提供了各种主流编译语言的驱动。
数据压缩
对于JSON/BSON数据结构,因为其嵌套结构,在拥有灵活的存储结构同时,也会造成数据的膨胀。JSON数据存储的膨胀问题,也是早期如MongoDB等JSON数据库性能瓶颈的一个重要原因。
SequoiaDB在使用JSON/BSON作为数据存储结构时,为了避免过度的膨胀问题,在数据引擎中加入了数据压缩的机制。目前SequoiaDB引擎提供了两类压缩方式:行压缩与表压缩。行压缩使用Snappy算法,是一种不需要字典的快速压缩机制。表压缩则使用LZW算法,是一种基于字典的压缩机制。
数据压缩机制,一方面从存储上节省空间和成本,另一方面提升单位I/O的效率。在IO吞吐量非常高的查询场景下,基于数据字典的深度压缩机制能够大幅降低IO开销,有效提高查询效率。
3.2非结构化数据存储
存储结构
非结构化数据即没有固定结构的数据,如文档、图片、音频/视频等,这种类型的数据在现在的很多业务中所占的比重越来越大。在SequoiaDB中,使用大对象(LOB,Large Object)来对这种类型的数据进行管理。
大对象依附于普通集合存在,当用户上传一个大对象时,系统为它分配一个唯一的 OID 值,后续对该大对象的操作可通过该值来进行指定。
大对象在存储时会进行分片,并使用hash算法将分片分散存储在相应的分区组中,其哈希空间与所属集合的哈希空间一致。分片大小为 LOB 页大小,在创建集合空间时指定,默认为 512KB。
为了对 LOB 数据进行有效的存储和管理,SequoiaDB内部将 LOB 数据抽象为元数据和数据本身,并使用两种文件来存储这些数据: LOBM 文件用于存储 LOB 分片的元数据,LOBD 文件用于存储真正的 LOB 数据分片。它们的逻辑结构如下图所示。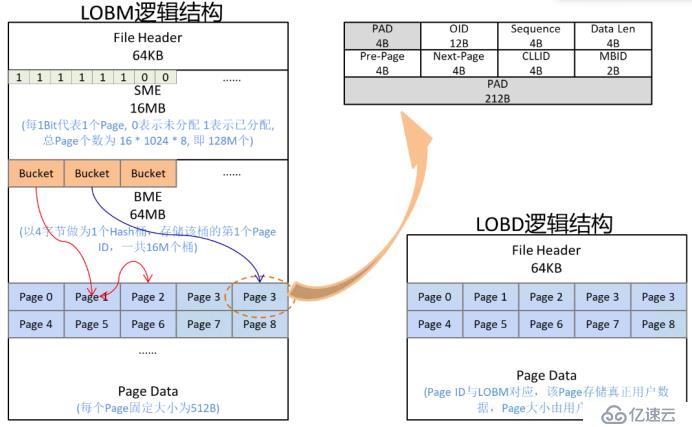
图5: LOB 文件逻辑结构
其中LOBM 文件主要包括:
文件头:包含该文件的一些元数据信息。
空间管理段(SME):用来标记页的使用情况。
桶管理段(BME):hash 值相同的分片所占用的页以双向链表的形式挂在一个桶上。
页:与 LOBD 中的页一一对应,记录该页所属的集合信息,OID及sequence 值等。
LOBD 文件主要包括:
文件头:包含该文件的一些元数据信息。
真正的数据页:用于存储 LOB 分片。LOB 还有一些自身的元数据,保存在 sequence 为0的分片中,包括该 LOB 数据的大小、创建时间、版本号等。
数据访问
1)写入LOB
当需要写入 LOB 数据时,LOB 数据会在协调节点上进行分片,每一个分片分配了一个 sequence 值,它表示这些分片在原始 LOB 数据中的顺序。因此,LOB 的OID与分片的 sequence 值唯一地标识了这个分片。
在存储一个 LOB 分片时,使用其 OID + sequence 计算 hash 值。先使用集合的分区 hash函数来计算出该分片要存储到哪个分区组上,然后使用 LOB 分片的 hash 函数来计算出其挂接到哪个桶上,之后在 LOBD 及 LOBM 文件中分配数据页,完成数据写入,LOBM 中的页挂到对应的桶上。
2)读取LOB
在获取 LOB 数据时,需要指定其 OID值。引擎根据OID值获取 sequence 值为0的分片,从中读出 LOB 的元数据信息,然后进行分片计算,确定所有分片信息,向所有包含分片的分区组发送请求。
当协调节点接收到各级返回的分片数据后,按 sequence 的顺序对 LOB 数据进行合并还原,以获取完整的 LOB 数据。
3)标准 Posix文件系统接口
除了LOB的API之外,目前提供SequoiaFS文件系统,它是基于FUSE在Linux系统下实现的一套文件系统,支持通用的文件操作API。SequoiaFS利用SequoiaDB的集合存储文件和目录的属性信息,LOB对象存储文件的数据内容,从而实现了类似NFS分布式网络文件系统。用户可以将远程SequoiaDB的某个集合通过映射的方式挂载到本地节点,从而在挂载节点的目标目录下可以通过通用文件系统API对文件和目录进行操作。
4.小结
根据Gartner的报告,Multi-Model多模是数据库领域近年兴起的一个主要的技术方向之一,其代表了在云化架构下,多类型数据管理的一种新理念,也是简化运维、节省开发成本的一个新选择。
SequoiaDB的Multi-Model数据库产品,目前已经在许多行业的到了应用,这也证明市场正在慢慢接受这一新的数据库架构。我们也看到MySQL,PostgreSQL等数据库也在开始支持JSON等多类型格式,也在朝着Multi-model的方向发展。未来相信各产品也会持续保持创新,出现更多Multi-model的数据库产品。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。