您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
我们知道在离线大数据处理领域中,hadoop是目前无可厚非的处理架构,到目前为止hadoop已经有三个大版本,每个版本下都有架构方面的调整。
在hadoop1.0中有一些弊端,比如hdfs元数据信息保存的单节点故障,并且任务计算框架只能使用mapreduce,而且造成了任务管理器的压力过大,因此在hadoop2.0中加入了yarn资源统一管理的机制,不仅解决了元数据单节点故障问题(双namenode)而且实现了元数据的实时热备(共享机制JournalNode),在hdfs和mr之间加入了yarn,统一协调资源。
在本文中只介绍yarn的运行原理,其他有关知识可以查询相关文档,这里就不多做介绍。
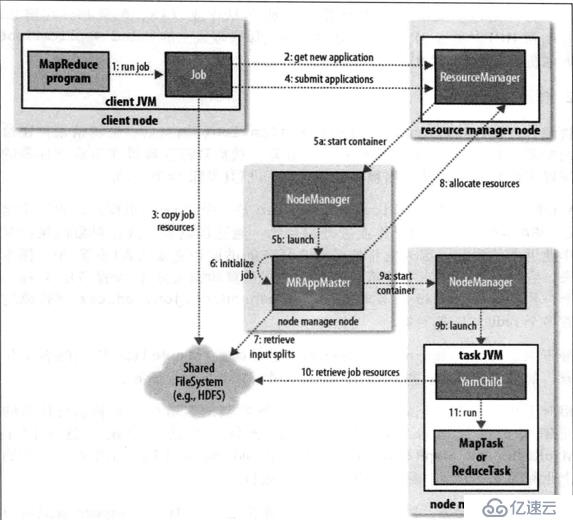
1. 客户端执行run方法,启动任务,启动过程中会检测相应执行权限请求路径等,若检测失败,则终止后续的执行
2. 第一步检测通过后,向resourcemanager发送请求,并返回任务id,以及任务在hdfs的存放路劲
3. 客户端接收到响应信息后,根据提交路径,将job任务打包上传到hdfs(共享文件系统)
4. 客户端再次向resourcemanager提交job任务(application)
5. Resourcemanager根据任务提交由资源调度器申请一个资源容器container,并由applicationmanager选择一台nodemanager(节点的资源管理器),启动一个与申请大小相同的container,并开启一个applicationmaster(任务的子实例协调管理者)
6. Appalicationmaster进行任务的初始化
7. 从resourcemanager获取执行任务在hdfs的位置,并根据任务信息计算mapreduce的数量
8. 根据初始化和运算结果,Appalicationmaster再根据mapreduce的任务大小依次到resourcemanager申请task(mapreduce)任务需要的container
9. Applicationmaster申请到container后再次选择一个nodemanager,并发送启动container的指令
10. Nodemanager收到指令后,启动container并从任务所在的hdfs路劲中获取执行的mapreduce任务
11. 启动jvm虚拟机来执行获取的mapreduce任务
注意:applicationmaster将监听每一个nodemanager执行的情况并随时汇报给resourcemanager,知道最后任务执行完成,将回收所有的资源,如果发现有任务执行失败,则由applicationmaster来协调,减轻了resourcemanager的负担,如果applicationmaster在运行过程中出问题,resourcemanager没有接收心跳后,会再在所有nodemanager节点中选择一个节点来启动applicationmaster来继续工作。
以上就是hadoop2.0中yarn的运行原理,大家相互学习-------成长从博客开始
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。