您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本文小编为大家详细介绍“HetuEngine怎么实现On Yarn原理”,内容详细,步骤清晰,细节处理妥当,希望这篇“HetuEngine怎么实现On Yarn原理”文章能帮助大家解决疑惑,下面跟着小编的思路慢慢深入,一起来学习新知识吧。
顾名思义,就是将进程运行在Yarn上,由Yarn进行资源的管理和调度。
不论是TrinoDB/PrestoDB还是openLooKeng,部署方式都是将coordinator和worker进程直接运行在主机上,与主机上的其他应用程序共享资源,无法做到资源隔离,并且难以扩展。
MRS HetuEngine借助Yarn Service提供的能力,将coordinator和worker进程以Yarn application的形式运行在Yarn container中,通过MRS集群的租户划分,可以将HetuEngine计算实例启动在特定租户队列里,从而实现资源隔离。
下图是HetuEngine的拓扑图。HetuEngine向下可以对接各类数据源(比如Hive,GaussDB,HBASE,Elasticsearch等),对外向用户提供CLI/JDBC接口。在同一套MRS集群中,HetuEngine可以在不同租户队列中启动多个HetuEngine计算实例,支持一个租户队列上启动一个计算实例。由HetuEngine的HSBroker实例与Yarn Service交互,将租户队列与计算实例绑定,由HSConsole提供运维管理页面,对HetuEngine的多个计算实例进行运维管理操作,包括启动、停止、删除计算实例,对计算实例进行资源配置,扩缩容等。
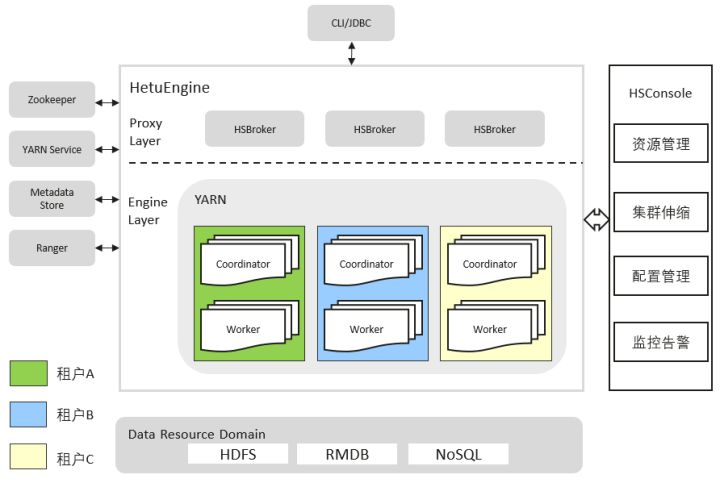
如前所述,On Yarn就是把进程运行在了Yarn 的container中。HetuEngine 是如何实现将coordinator 和worker运行中Yarn中呢?
Yarn Service提供了一系列API以及一个通用的AM,让用户可以调用API即可将任务提交到Yarn上,由Yarn实现任务的容器化,对容器进行资源和生命周期管理。详细请参考开源社区的介绍。https://hadoop.apache.org/docs/r3.1.0/hadoop-yarn/hadoop-yarn-site/yarn-service/Overview.html
HetuEngine的 On Yarn实现正是借助了Yarn Service所提供的能力。在HetuEngine的HSBroker中,调用Yarn Service的API,拉起application,在container中运行HetuEngine自己的进程,也就是coordinator和worker。其中有以下几个关键点:
Yarn Service API
创建一个Yarn Service服务的接口是/app/v1/services,参数json结构如下。
POST /app/v1/services
{
"name": "hello-world",
"version": "1.0.0",
"description": "hello world example",
"components" :
[
{
"name": "hello",
"number_of_containers": 1,
"artifact": {
"id": "nginx:latest",
"type": "DOCKER"
},
"launch_command": "./start_nginx.sh",
"resource": {
"cpus": 1,
"memory": "256",
"additional" : {
"yarn.io/gpu" : {
"value" : 4,
"unit" : ""
}
}
}
}
]name:服务名称,显示在Yarn的resource manager WEB界面servicename;
version:版本号
description:服务的描述
components:一个service中可以包含多个component,以运行不同的任务;
components.name:component名称
number_of_containers:此component中container的数量;
artifact:进程依赖的资源文件,包含id和type信息,type支持docker和tarball
launch_command:进程启动命令
resource:此component所需的资源。
HetuEngine的HSBroker根据用户输入构造此json,然后调用Yarn Service API,实现On Yarn。此外Yarn Service还提供stop/delete等API,也由HSBroker调用,实现对HetuEngine计算实例的停止/删除等运维操作。
Yarn Service支持资源文件在HDFS上的形式启动进程,其提供的API可以接收tar包以及docker等形式的资源文件,由Yarn Service自行将HDFS上的文件进行资源本地化。因此,HetuEngine只需将依赖的jar包和资源文件提前部署在HDFS上的指定位置,在调用Yarn Service的API时指定资源文件即可。

HetuEngine支持将计算实例与Yarn的租户队列绑定,每个队列上都可以运行一套coordinator + worker的组合。基于前面Yarn Service能力,只需在构造json时,指定队列信息即可。除了队列,还可以设置container的放置策略(plecement policy),这里不进行详述,可以参考yarn的文档。
HetuEngine支持用户自定义coordinator和worker的个数以及CPU内存大小。如下图,在HetuEngine的HSConsole页面,用户可以设置计算实例的CPU,内存,节点个数。内部实现是由HSBroker接收用户输入,将container运行所需的资源大小设置在json的resource段中。
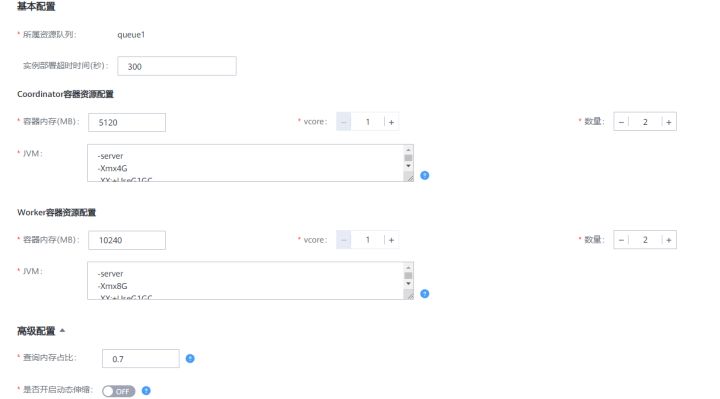
当前HetuEngine支持横向扩展worker的个数,实现资源的弹性伸缩。即使在计算实例处于运行中时,也可以手动调整worker的个数,无需重启计算实例。这得益于Yarn Service的API中提供的flex接口,可以实现向一个运行中的application增加或者减少container的数量。
HetuEngine的计算实例创建完成后,用户可以通过hetu-cli或者JDBC程序进行访问,需要用户绑定对应的租户队列权限,才能向指定的队列提交任务。
Hetu CLI示例:
hetu-cli --catalog hive --tenant tenantName --schema schemaName
租户名:(可选)租户名。指定HetuEngine启动的租户资源队列,不指定为租户的默认队列。使用此参数时,kinit的用户需要具有该租户对应角色的权限。
Hetu JDBC示例:
Properties properties = new Properties();
...…
properties.setProperty("tenant", "default");
properties.setProperty("deploymentMode", "on_yarn");
……
connection = DriverManager.getConnection(url, properties);
……读到这里,这篇“HetuEngine怎么实现On Yarn原理”文章已经介绍完毕,想要掌握这篇文章的知识点还需要大家自己动手实践使用过才能领会,如果想了解更多相关内容的文章,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。