жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жңҖиҝ‘ејҖеҸ‘зҡ„жҗңзҙўеј•ж“ҺдёӯпјҢйңҖиҰҒеҜ№зҙўеј•иҝӣиЎҢеҲҶзүҮгҖӮж №жҚ®йЎ№зӣ®зҡ„йңҖжұӮпјҢжҲ‘们жҸҗдҫӣдәҶдёӨз§ҚеҲҶзүҮж–№ејҸгҖӮиҝҮзЁӢеҚҡе®ўи®°еҪ•дёҖдёӢгҖӮ
Hashз®—жі•
еҺҹзҗҶеҫҲз®ҖеҚ•пјҢйҖҡиҝҮиЎҢй”®пјҲ_idпјүзҡ„HashеҖјзЎ®е®ҡжүҖеңЁзҡ„еҲҶзүҮпјҢ然еҗҺеҶҚиҝӣиЎҢж“ҚдҪңгҖӮ
дёҫдёӘж —пјҲдҫӢпјүеӯҗпјҢзҺ°еңЁжңүдёӘзҙўеј•пјҢеҲқе§ӢеҢ–5дёӘеҲҶзүҮпјҢеҲҶеҲ«дёәshard0пјҢ shard1пјҢ shard2пјҢ shard3пјҢ shard4гҖӮ
зҺ°еңЁйңҖиҰҒдҝқеӯҳдёҖиЎҢж•°жҚ®пјҢ_idдёә0001000000123пјҢ_idзҡ„HashCodeдёә1571574097пјҢеҜ№5жұӮдҪҷпјҲ1571574097 % 5пјүдёә2пјҢд»ҺиҖҢзЎ®е®ҡж•°жҚ®еә”иҜҘдҝқеӯҳеңЁshard2гҖӮдёӢйқўжҳҜдёҖдёӘз®ҖеҚ•зҡ„еӣҫи§Јпјҡ
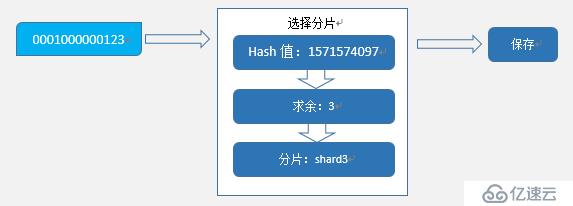
Hashз®—жі•еҲҶзүҮе®һзҺ°йқһеёёз®ҖеҚ•пјҢи®Ўз®—иҝҮзЁӢеҸӘйңҖиҰҒзҹҘйҒ“еҲҶзүҮж•°йҮҸеҚіеҸҜе®ҢжҲҗе®ҡдҪҚгҖӮдҪҶд№ҹжӯЈеӣ дёәеҲҶзүҮж•°йҮҸжҳҜз®—жі•зҡ„дёҖйғЁеҲҶпјҢдҝ®ж”№еҲҶзүҮж•°йҮҸзҡ„д»Јд»·д№ҹйқһеёёжҳӮиҙөгҖӮ
жңүдёҖз§Қи§ЈеҶіж–№жЎҲжҳҜйҮҚж–°жҺ’еҲ—пјҢжҜ”еҰӮд»ҺMдёӘеҲҶзүҮеҲҮеўһеҠ еҲ°NдёӘеҲҶзүҮпјҢе…Ҳе°ҶжҜҸдёӘеҲҶзүҮеҲҮеҲҶдёәNдёӘе°ҸеҲҶзүҮпјҢ然еҗҺеҶҚе°ҶжүҖжңүе°ҸеҲҶзүҮеҗҲ并дёәеӨ§еҲҶзүҮгҖӮд»ҺзҪ‘з»ңдёҠеӨҚеҲ¶дәҶдёҖеј еӣҫи§ЈиҜҙжҳҺпјҢ
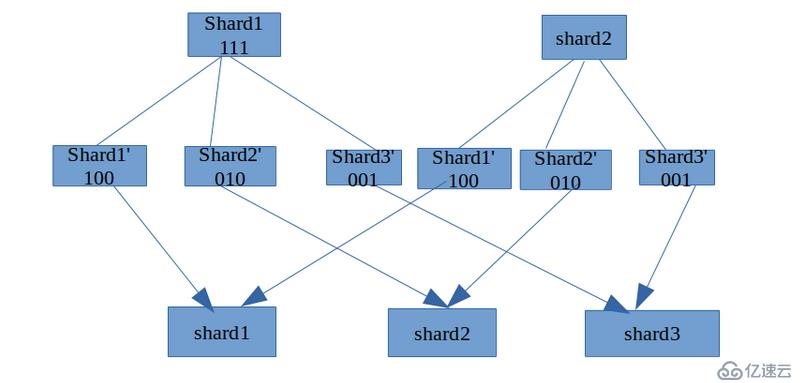
иҝҷз§Қж–№ејҸзҡ„дјҳзӮ№жҳҜпјҢеҸҜд»Ҙд»»ж„Ҹи®ҫе®ҡж–°зҡ„еҲҶзүҮж•°йҮҸгҖӮзјәзӮ№жҳҜйңҖиҰҒеҜ№жүҖжңүж•°жҚ®иҝӣиЎҢйҮҚж–°жҺ’еҲ—пјҢеҰӮжһңж•°жҚ®йҮҸеҫҲеӨ§пјҢеҸҜиғҪдјҡйқһеёёиҖ—ж—¶гҖӮ
еҪ“然пјҢз”ұдәҺйЎ№зӣ®ж•°жҚ®еўһй•ҝжҳҜдёҚеҸҜйў„жөӢжҖ§пјҢжҲ‘们没жңүйҖүжӢ©дёҠйқўеўһзүҮж–№ејҸпјҢиҖҢжҳҜйҖүжӢ©дәҶеҸҰеӨ–дёҖз§ҚеўһзүҮзҡ„ж–№ејҸгҖӮ
еҠЁжҖҒеҲҶзүҮ
з»“еҗҲHashз®—жі•е’ҢдәҢеҸүж ‘зҡ„еҺҹзҗҶпјҢиҝӣиЎҢеҠЁжҖҒеўһеҠ еҲҶзүҮгҖӮ
йҰ–е…ҲпјҢHashз®—жі•дёҺд№ӢеүҚдёҖж ·пјҢжҗңзҙўеҲӣе»әж—¶пјҢеҸҜд»Ҙи®ҫзҪ®дёҖдёӘеҲқе§ӢеҢ–зҡ„еҲҶзүҮж•°йҮҸпјҢдҫӢеҰӮеҲқе§ӢеҢ–5дёӘеҲҶзүҮпјҢеҲҶеҲ«дёәshard_0пјҢ shard_1пјҢ shard_2пјҢ shard_3пјҢ shard_4гҖӮж·»еҠ ж•°жҚ®ж—¶пјҢйҖҡиҝҮ_idзҡ„HashеҖјзЎ®е®ҡж•°жҚ®йңҖиҰҒдҝқеӯҳеҲ°е“ӘдёӘеҲҶзүҮгҖӮдёҚеҗҢзҡ„жҳҜпјҢжҲ‘们и®ҫзҪ®дәҶжҜҸдёӘеҲҶзүҮзҡ„жңҖеӨ§иЎҢж•°пјҢеҪ“жҹҗдёӘеҲҶзүҮзҡ„ж•°йҮҸиҫҫеҲ°жңҖеӨ§иЎҢж•°ж—¶пјҢиҜҘеҲҶзүҮдјҡеҲҶжӢҶеҲҶдёәдёӨдёӘе°Ҹзҡ„еҲҶзүҮпјҢ并且дҪңдёәеҪ“еүҚеҲҶзүҮзҡ„еӯҗеҲҶзүҮгҖӮ
дҫӢеҰӮпјҢи®ҫзҪ®еҲҶзүҮжңҖеӨ§иЎҢж•°дёә1000дёҮпјҢеҪ“shard_2и¶…иҝҮ1000дёҮж—¶пјҢеҲҶиЈӮдёәдёӨдёӘеӯҗеҲҶзүҮshard_2_2е’Ңshard_2_7гҖӮеҰӮжһңshard_2_2ж•°жҚ®з»§з»ӯеўһй•ҝеҲ°1000дёҮпјҢеҲҷеҲҶиЈӮеӯҗеҲҶзүҮshard_2_2_2е’Ңshard_2_2_12гҖӮ
д»ҺзӨәдҫӢдёӯеҸҜд»ҘзңӢеҮәпјҢеҲҶиЈӮ并дёҚжҳҜжҜ«ж— 规еҲҷпјҢеҒҮи®ҫеҲҶзүҮзҡ„еҲқе§Ӣж•°йҮҸдёәmпјҢkиЎЁзӨәдәҢеҸүж ‘ж·ұеәҰпјҢеҲҷеҲҶзүҮnзҡ„еҲҶиЈӮ规еҲҷдёә
shard_n еҲҶиЈӮдёә shard_n_nе’Ңshard_n_(n + m * 1)
shard_n_n еҲҶиЈӮдёә shard_n_n_nе’Ңshard_n_n_(n + m * 2)
shard_n_(n + m * 1) еҲҶиЈӮдёә shard_n_(n + m * 1)_(n + m * 1) е’Ң shard_n_(n + m * 1)_(n + m * 1 + m * 2)
...
дёҠйқўзҡ„е…¬ејҸзңӢиө·жқҘеҫҲеӨҚжқӮпјҢжҲ‘们дҪҝз”Ёеӣҫи§ЈжқҘиҜҙжҳҺеҲҶиЈӮиҝҮзЁӢ
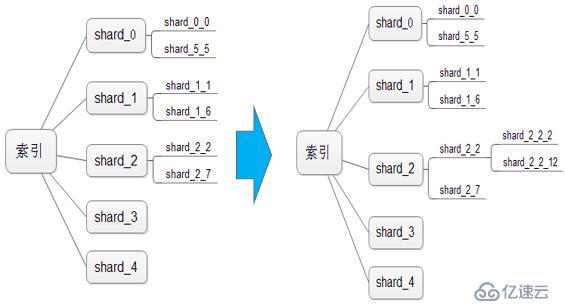
еҰӮжһңиҝҳжІЎжңүжҳҺзҷҪпјҢжҲ‘们еҸҜд»ҘйҖҡиҝҮ_idеҜ»жүҫеҜ№еә”зҡ„еҲҶзүҮжқҘжўізҗҶдёҖдёӢжҖқи·ҜпјҢиҝҳжҳҜдёҠйқўзҡ„дҫӢеӯҗпјҢ
йңҖиҰҒдҝқеӯҳдёҖиЎҢж•°жҚ®пјҢ_idдёә0001000000123пјҢ_idзҡ„HashCodeдёә1571574097пјҢеҜ№5жұӮдҪҷпјҲ1571574097 % 5пјүдёә2пјҢд»ҺиҖҢзЎ®е®ҡж•°жҚ®еә”иҜҘдҝқеӯҳеңЁshard_2гҖӮ
shard_2е·Із»ҸеҲҶиЈӮдёәshard_2_2е’Ңshard_2_7дёӨдёӘеӯҗеҲҶзүҮдәҶпјҢиҝҷдёҖеұӮзҡ„еҹәж•°дёә10пјҲеҹәж•°=еҲқе§ӢеҢ–еҲҶзүҮж•°йҮҸ*еұӮж•°пјүпјҢжҲ‘们е°Ҷ1571574097еҜ№10жұӮдҪҷ(1571574097 % 10)дёә7,еҲҷж•°жҚ®дҝқеӯҳеңЁshard_2_7гҖӮ
shard_2_7жІЎжңүеӯҗеҲҶзүҮпјҢиҜҙжҳҺиҜҘеҲҶзүҮжІЎжңүеҲҶиЈӮпјҢзӣҙжҺҘдҝқеӯҳеңЁиҜҘеҲҶзүҮеҚіеҸҜгҖӮ
еҲҶжһҗдёҖдёӢеҲҶзүҮеҜ»жүҫеҺҹзҗҶпјҡ
жҢүз…§hashз®—жі•жүҫеҲ°еҲҶзүҮпјӣ
еҰӮжһңеҲҶзүҮжңүеӯҗеҲҶзүҮпјҢеҲҷд»ҺеӯҗеҲҶзүҮдёӯжҹҘжүҫпјӣ
еҰӮжһңеҲҶзүҮжІЎжңүеӯҗеҲҶзүҮпјҢеҲҷж•°жҚ®дҝқеӯҳеңЁиҜҘеҲҶзүҮпјӣ
еҶҚжқҘеҲҶжһҗдёҖдёӢеҲҶзүҮеҲҶиЈӮ规еҲҷпјҢдёәд»Җд№Ҳshard_1дјҡеҲҶиЈӮдёәshard_1_1е’Ңshard_1_6пјҹ
еҺҹеӣ еҫҲз®ҖеҚ•пјҢshard_1иЎЁзӨәidзҡ„hashеҖјеҜ№5еҸ–дҪҷеҗҺеҖјдёә1пјҢеҰӮжһңshard_1еҲҶиЈӮдёә2д»ҪпјҢеҲҷ第2еұӮзҡ„еҹәж•°10=дёҠдёҖеұӮеҹәж•°*2пјҢеҚі5 * 2гҖӮеҜ№5еҸ–дҪҷеҖјдёә1пјҢйӮЈд№ҲеҜ№10еҸ–дҪҷз»“жһңеҸӘдјҡжҳҜ1е’Ң6пјҢеӣ жӯӨ
shard_1еҲҶиЈӮдёәshard_1_1е’Ңshard_1_6гҖӮ
ж•°жҚ®дёҖиҮҙжҖ§
еҠЁжҖҒеҲҶзүҮжҳҜеңЁдҪҝз”ЁиҝҮзЁӢдёӯиҮӘеҠЁеҲҶзүҮпјҢеҲҶзүҮиҝҮзЁӢдјҡйқһеёёй•ҝпјҢз»ҸиҝҮжөӢиҜ•пјҢзҙўеј•32еҲ—500дёҮиЎҢзҡ„еҲҶиЈӮдёәдёӨдёӘеӯҗеҲҶзүҮпјҢиҖ—ж—¶245з§’гҖӮеҲҶиЈӮиҝҮзЁӢеҰӮжһңеҺҹе§Ӣж•°жҚ®еҸ‘з”ҹдҝ®ж”№пјҢиҝҷдәӣдҝ®ж”№еҸҜиғҪдјҡдёўеӨұгҖӮеӣ жӯӨпјҢеңЁеҲҶиЈӮиҝҮзЁӢдёӯйңҖиҰҒдёҖе®ҡзҡ„жҺӘж–Ҫдҝқйҡңж•°жҚ®е®үе…ЁжҖ§гҖӮ
ж–№жі•дёҖпјҢдҪҝз”ЁжӮІи§Ӯй”ҒгҖӮ
еҲҶиЈӮеүҚеҜ№й”Ғе®ҡеҲҶзүҮдёҚиғҪеҶҚдҝ®ж”№пјҢзӣҙеҲ°еҲҶиЈӮе®ҢжҲҗеҗҺжүҚиғҪеҶҚдҝ®ж”№гҖӮ
дјҳзӮ№пјҡйҖ»иҫ‘з®ҖеҚ•зІ—жҡҙпјҢејҖеҸ‘йҡҫеәҰдҪҺгҖӮ
зјәзӮ№пјҡй”Ғзҡ„ж—¶й—ҙеӨӘй•ҝеҸҜиғҪдјҡеҜјиҮҙи°ғз”ЁжңҚеҠЎж–№дә§з”ҹеӨ§йҮҸзҡ„ејӮеёёиҜ·жұӮгҖӮ
ж–№жі•дәҢпјҢдҪҝз”ЁдәӢеҠЎж—Ҙеҝ—гҖӮ
еҲҶиЈӮеүҚеҲӣе»әдәӢеҠЎж—Ҙеҝ—пјҢеҪ“еүҚshardжүҖжңүж–°еўһгҖҒдҝ®ж”№е’ҢеҲ йҷӨж“ҚдҪңйғҪеҶҷе…ҘдәӢеҠЎж—Ҙеҝ—гҖӮеҲҶиЈӮе®ҢжҲҗеҗҺпјҢй”Ғе®ҡеҲҶзүҮе’ҢеӯҗеҲҶзүҮпјҢд»ҺдәӢеҠЎж—Ҙеҝ—дёӯжҒўеӨҚж•°жҚ®еҲ°еӯҗеҲҶзүҮпјҢ然еҗҺи§Јй”ҒгҖӮ
дјҳзӮ№пјҡеҸӘжңүеңЁеҲӣе»әдәӢеҠЎж—Ҙеҝ—е’ҢжҒўеӨҚж•°жҚ®ж—¶дјҡй”Ғе®ҡеҲҶзүҮпјҢй”Ғе®ҡж—¶й—ҙжҜ”иҫғзҹӯжҡӮпјҢеҪұе“ҚжңҚеҠЎи°ғз”Ёж–№еҮ д№ҺдёҚеҸ—еҪұе“ҚгҖӮ
зјәзӮ№пјҡејҖеҸ‘йҡҫеәҰеӨ§пјҢйңҖиҰҒејҖеҸ‘дёҖеҘ—дәӢеҠЎж—Ҙеҝ—е’Ңж—Ҙеҝ—жҒўеӨҚж“ҚдҪңжҺҘеҸЈгҖӮдҪҶжҳҜеә•еұӮluceneеӯҳеӮЁе·Із»ҸжңүдёҖеҘ—дәӢеҠЎж—Ҙеҝ—жҺҘеҸЈе’Ңе®һзҺ°пјҢиҜҘзјәзӮ№еҮ д№ҺеҸҜд»ҘеҝҪз•ҘгҖӮ
иЎҢй”®йҖ’еўһеҲҶзүҮ
еҰӮжһңдҝқеӯҳж•°жҚ®зҡ„иЎҢй”®ж•ҙдҪ“дёҠжҳҜйҖ’еўһзҡ„пјҢдҫӢеҰӮпјҢиЎҢй”®жҳҜ000000001,000000002,000000003,...иҝҷз§Қж јејҸпјҢеҸҜд»ҘжҢүиЎҢй”®иҝӣиЎҢеҲҶзүҮгҖӮиҝҷз§ҚеҲҶзүҮе®һзҺ°ж–№ејҸжҜ”иҫғз®ҖеҚ•пјҢ
1. еҲӣе»әзҙўеј•ж—¶и®ҫзҪ®дёҖдёӘеҲқе§ӢеҢ–еҲҶзүҮпјӣ
2. ж·»еҠ ж•°жҚ®иҝҮзЁӢдёӯпјҢ并且记еҪ•еҲҶзүҮиЎҢй”®жңҖе°ҸеҖјminIdе’ҢжңҖеӨ§еҖјmaxIdпјӣ
3. еҪ“еҲҶзүҮж•°жҚ®йҮҸи¶…иҝҮи®ҫзҪ®зҡ„жңҖеӨ§еҖјжҳҜпјҢеҲӣе»әдёҖдёӘж–°зҡ„еҲҶзүҮпјҢж–°еўһзҡ„ж•°жҚ®дҝқеӯҳеңЁиҜҘеҲҶзүҮпјӣ
4. жӣҙж–°ж•°жҚ®ж—¶пјҢйҖҡиҝҮдёҺжҜҸдёӘеҲҶзүҮзҡ„minIdе’ҢmaxIdжҜ”иҫғпјҢзЎ®е®ҡжүҖеңЁзҡ„еҲҶзүҮгҖӮ
иЎҢй”®йҖ’еўһеҲҶзүҮдёҺHashз®—жі•еҲҶзүҮжҜ”иҫғпјҡ
1.иЎҢй”®йҖ’еўһеҲҶзүҮж–№ејҸе®һзҺ°жӣҙз®ҖеҚ•пјҢејҖеҸ‘жҲҗжң¬жӣҙдҪҺпјӣ
2.иЎҢй”®йҖ’еўһеҲҶзүҮйҖҡиҝҮminIdе’ҢmaxIdе®ҡдҪҚеҲҶзүҮпјҢеҰӮжһңжҜҸдёӘеҲҶзүҮдҝЎжҒҜдёӯйңҖиҰҒи®°еҪ•еҲҶзүҮзҡ„minIdе’ҢmaxIdпјӣ
3.иЎҢй”®йҖ’еўһеҲҶзүҮеӯҳе…Ҙж•°жҚ®ж—¶пјҢйңҖиҰҒжҢүз…§дёҖе®ҡзҡ„йЎәеәҸеӯҳе…ҘпјҢеҗҰеҲҷеҸҜиғҪдјҡеҜјиҮҙж•°жҚ®еҖҫж–ңпјӣ
4.иЎҢй”®йҖ’еўһеҲҶзүҮжҢүйңҖж·»еҠ еҲҶзүҮпјҢеҸӘйңҖиҰҒи®ҫзҪ®жҜҸдёӘеҲҶзүҮзҡ„жңҖеӨ§иЎҢж•°пјҢжІЎжңүеҲҶиЈӮиҝҮзЁӢпјӣ
5.иЎҢй”®йҖ’еўһеҲҶзүҮеӨ§йҮҸзҡ„еҺӢеҠӣйӣҶдёӯеңЁжңҖж–°зҡ„еҲҶзүҮдёҠпјҢHashз®—жі•еҲҶзүҮеҺӢеҠӣеҲҶж•ЈеҲ°еҗ„дёӘеҲҶзүҮпјҢзҗҶи®әдёҠHashз®—жі•еҲҶзүҮеҸҜд»Ҙж”ҜжҢҒжӣҙй«ҳзҡ„еҗһеҗҗйҮҸгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ