您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
什么是HDFS:
HDFS的设计目标:
HDFS官方文档地址如下:
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
HDFS是主/从式的架构。一个HDFS集群会有一个NameNode(简称NN),也就是命名节点,该节点作为主服务器存在(master server)。NameNode用于管理文件系统的命名空间以及调节客户访问文件。此外,还会有多个DataNode(简称DN),也就是数据节点,数据节点作为从节点存在(slave server)。通常每一个集群中的DataNode,都会被NameNode所管理,DataNode用于存储数据。
HDFS公开了文件系统名称空间,允许用户将数据存储在文件中,就好比我们平时使用操作系统中的文件系统一样,用户无需关心底层是如何存储数据的。而在底层,一个文件会被分成一个或多个数据块,这些数据块会被存储在一组数据节点中。在CDH中数据块的默认大小是128M,这个大小我们可以通过配置文件进行调节。在NameNode上我们可以执行文件系统的命名空间操作,例如打开,关闭,重命名文件等。这也决定了数据块到数据节点的映射。
我们可以来看看HDFS的架构图: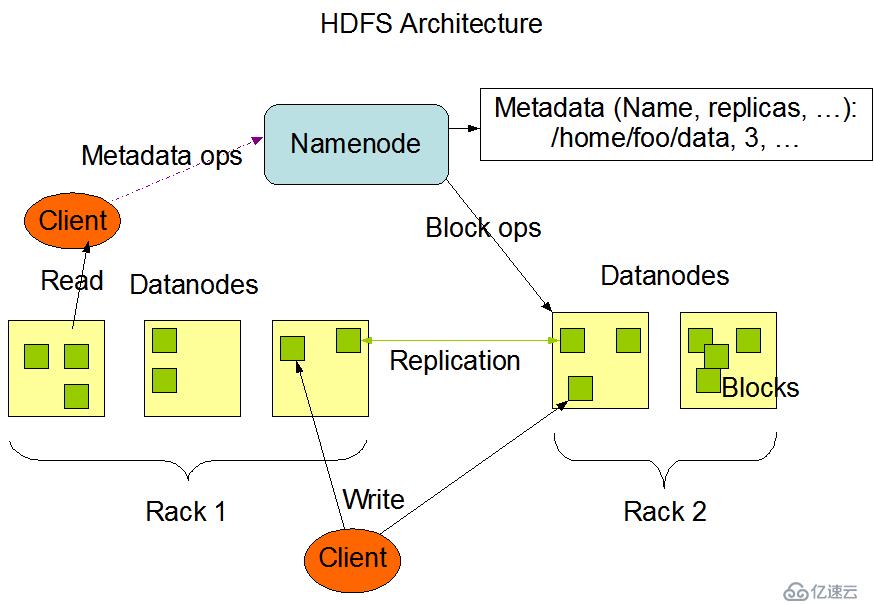
HDFS被设计为可以运行在普通的廉价机器上,而这些机器通常运行着一个Linux操作系统。HDFS是使用java语言编写的,任何支持java的机器都可以运行HDFS。使用高度可移植的java语言编写的HDFS,意味着可以部署在广泛的机器上。一个典型的HDFS集群部署会有一个专门的机器只能运行NameNode,而其他集群中的机器各自运行一个DataNode实例。虽然一台机器上也可以运行多个节点,但是并不建议这么做,除非是学习环境。
总结:
NN:
DN:
在HDFS中,一个文件会被拆分为一个或多个数据块。默认情况下,每个数据块都会有三个副本。每个副本都会被存放在不同的机器上,而且每一个副本都有自己唯一的编号。
如下图: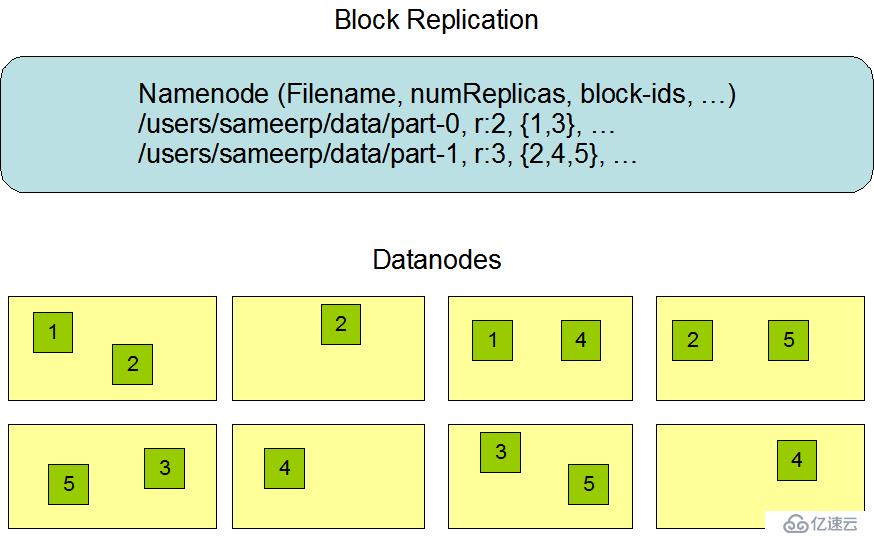
NameNode节点选择一个DataNode节点去存储block副本得过程就叫做副本存放,这个过程的策略其实就是在可靠性和读写带宽间得权衡。
《Hadoop权威指南》中的默认方式:
如下图: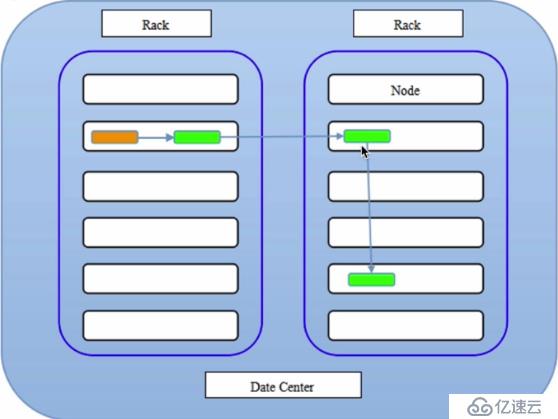
可以看出这个方案比较合理:
官方安装文档地址如下:
http://archive.cloudera.com/cdh6/cdh/5/hadoop-2.6.0-cdh6.7.0/hadoop-project-dist/hadoop-common/SingleCluster.html
环境描述:
下载Hadoop 2.6.0-cdh6.7.0的tar.gz包并解压:
[root@localhost ~]# cd /usr/local/src/
[root@localhost /usr/local/src]# wget http://archive.cloudera.com/cdh6/cdh/5/hadoop-2.6.0-cdh6.7.0.tar.gz
[root@localhost /usr/local/src]# tar -zxvf hadoop-2.6.0-cdh6.7.0.tar.gz -C /usr/local/注:如果在Linux上下载得很慢的话,可以在windows的迅雷上使用这个链接进行下载。然后再上传到Linux中,这样就会快一些。
解压完后,进入到解压后的目录下,可以看到hadoop的目录结构如下:
[root@localhost /usr/local/src]# cd /usr/local/hadoop-2.6.0-cdh6.7.0/
[root@localhost /usr/local/hadoop-2.6.0-cdh6.7.0]# ls
bin cloudera examples include libexec NOTICE.txt sbin src
bin-mapreduce1 etc examples-mapreduce1 lib LICENSE.txt README.txt share
[root@localhost /usr/local/hadoop-2.6.0-cdh6.7.0]#简单说明一下其中几个目录存放的东西:
以上就算是把hadoop给安装好了,接下来就是编辑配置文件,把JAVA_HOME配置一下:
[root@localhost /usr/local/hadoop-2.6.0-cdh6.7.0]# cd etc/
[root@localhost /usr/local/hadoop-2.6.0-cdh6.7.0/etc]# cd hadoop
[root@localhost /usr/local/hadoop-2.6.0-cdh6.7.0/etc/hadoop]# vim hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8/ # 根据你的环境变量进行修改由于我们要进行的是单节点伪分布式环境的搭建,所以还需要配置两个配置文件,分别是core-site.xml以及hdfs-site.xml,如下:
[root@localhost /usr/local/hadoop-2.6.0-cdh6.7.0/etc/hadoop]# vim core-site.xml # 增加如下内容
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.77.130:8020</value> # 指定默认的访问地址以及端口号
</property>
<property>
<name>hadoop.tmp.dir</name> # 指定临时文件所存放的目录
<value>/data/tmp/</value>
</property>
</configuration>
[root@localhost /usr/local/hadoop-2.6.0-cdh6.7.0/etc/hadoop]# mkdir /data/tmp/
[root@localhost /usr/local/hadoop-2.6.0-cdh6.7.0/etc/hadoop]# vim hdfs-site.xml # 增加如下内容
<configuration>
<property>
<name>dfs.replication</name> # 指定只产生一个副本
<value>1</value>
</property>
</configuration>然后配置一下密钥对,设置本地免密登录,搭建伪分布式的话这一步是必须的:
[root@localhost ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
Generating public/private dsa key pair.
Your identification has been saved in /root/.ssh/id_dsa.
Your public key has been saved in /root/.ssh/id_dsa.pub.
The key fingerprint is:
c2:41:89:65:bd:04:9e:3e:3f:f9:a7:51:cd:e9:cf:1e root@localhost
The key's randomart image is:
+--[ DSA 1024]----+
| o=+ |
| .+..o |
| +. . |
| o .. o . |
| = S . + |
| + . . . |
| + . .E |
| o .. o.|
| oo .+|
+-----------------+
[root@localhost ~]# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
[root@localhost ~]# ssh localhost
ssh_exchange_identification: read: Connection reset by peer
[root@localhost ~]# 如上,测试本地免密登录的时候报了个ssh_exchange_identification: read: Connection reset by peer错误,于是着手排查错误,发现是/etc/hosts.allow文件里限制了IP,于是修改一下该配置文件即可,如下:
[root@localhost ~]# vim /etc/hosts.allow # 修改为 sshd: ALL
[root@localhost ~]# service sshd restart
[root@localhost ~]# ssh localhost # 测试登录成功
Last login: Sat Mar 24 21:56:38 2018 from localhost
[root@localhost ~]# logout
Connection to localhost closed.
[root@localhost ~]# 接下来就可以启动HDFS了,不过在启动之前需要先格式化文件系统:
[root@localhost ~]# /usr/local/hadoop-2.6.0-cdh6.7.0/bin/hdfs namenode -format注:只有第一次启动才需要格式化
使用服务启动脚本启动服务:
[root@localhost ~]# /usr/local/hadoop-2.6.0-cdh6.7.0/sbin/start-dfs.sh
18/03/24 21:59:03 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [192.168.77.130]
192.168.77.130: namenode running as process 8928. Stop it first.
localhost: starting datanode, logging to /usr/local/hadoop-2.6.0-cdh6.7.0/logs/hadoop-root-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]
The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established.
ECDSA key fingerprint is 63:74:14:e8:15:4c:45:13:9e:16:56:92:6a:8c:1a:84.
Are you sure you want to continue connecting (yes/no)? yes # 第一次启动会询问是否连接节点
0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts.
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop-2.6.0-cdh6.7.0/logs/hadoop-root-secondarynamenode-localhost.out
18/03/24 21:59:22 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[root@localhost ~]# jps # 检查是否有以下几个进程,如果少了一个都是不成功的
8928 NameNode
9875 Jps
9578 DataNode
9757 SecondaryNameNode
[root@localhost ~]# netstat -lntp |grep java # 检查端口
tcp 0 0 0.0.0.0:50090 0.0.0.0:* LISTEN 9757/java
tcp 0 0 192.168.77.130:8020 0.0.0.0:* LISTEN 8928/java
tcp 0 0 0.0.0.0:50070 0.0.0.0:* LISTEN 8928/java
tcp 0 0 0.0.0.0:50010 0.0.0.0:* LISTEN 9578/java
tcp 0 0 0.0.0.0:50075 0.0.0.0:* LISTEN 9578/java
tcp 0 0 0.0.0.0:50020 0.0.0.0:* LISTEN 9578/java
tcp 0 0 127.0.0.1:53703 0.0.0.0:* LISTEN 9578/java
[root@localhost ~]# 然后将Hadoop的安装目录配置到环境变量中,方便之后使用它的命令:
[root@localhost ~]# vim ~/.bash_profile # 增加以下内容
export HADOOP_HOME=/usr/local/hadoop-2.6.0-cdh6.7.0/
export PATH=$HADOOP_HOME/bin:$PATH
[root@localhost ~]# source !$
source ~/.bash_profile
[root@localhost ~]#确认服务启动成功后,使用浏览器访问192.168.77.130:50070,会访问到如下页面: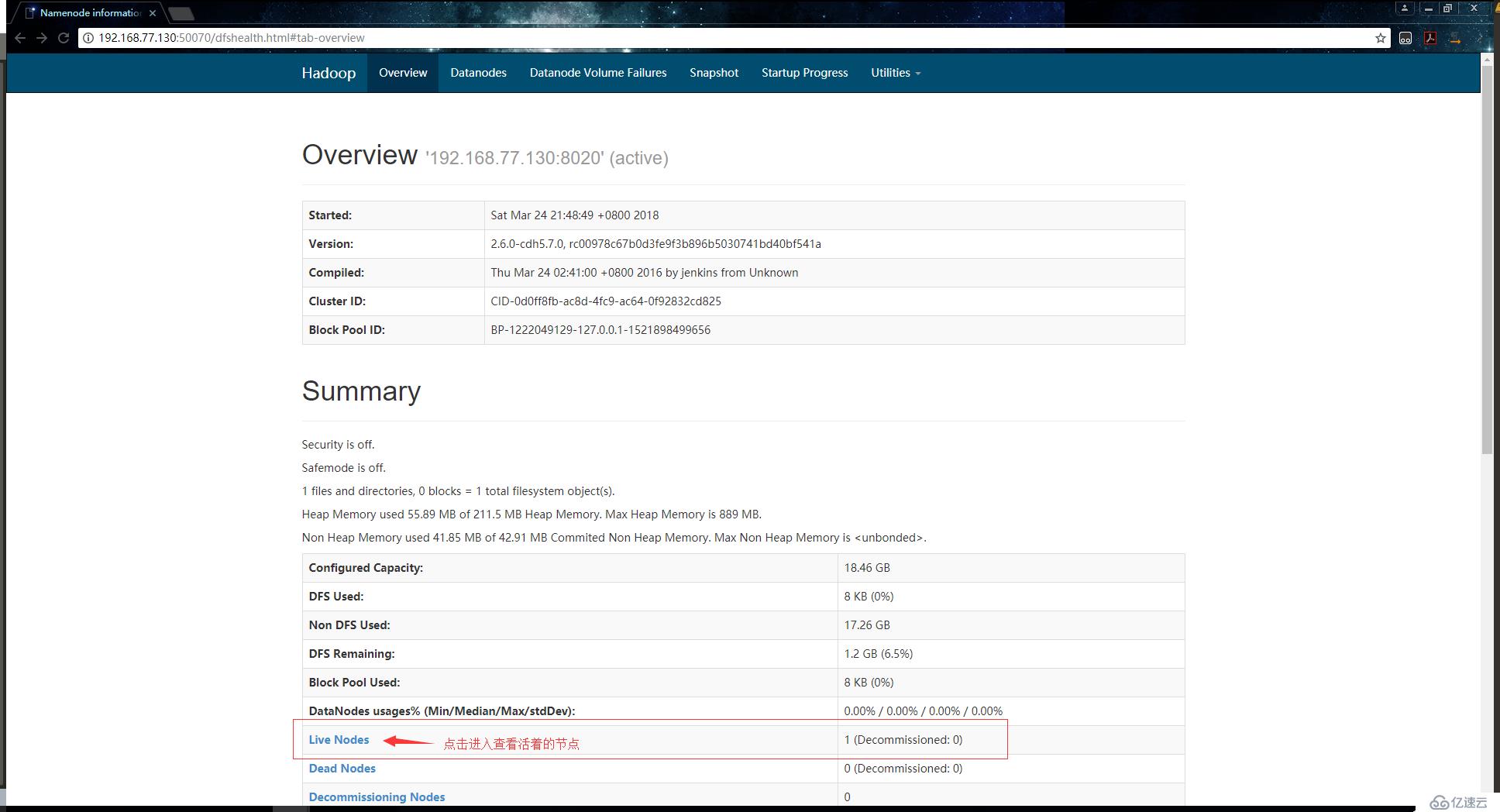
点击Live Nodes查看活着的节点:
如上,可以看到节点的信息。到此,我们伪分布式的hadoop集群就搭建完成了。
以上已经介绍了如何搭建伪分布式的Hadoop,既然环境已经搭建起来了,那要怎么去操作呢?这就是本节将要介绍的内容:
HDFS自带有一些shell命令,通过这些命令我们可以去操作HDFS文件系统,这些命令与Linux的命令挺相似的,如果熟悉Linux的命令很容易就可以上手HDFS的命令,关于这些命令的官方文档地址如下:
http://archive.cloudera.com/cdh6/cdh/5/hadoop-2.6.0-cdh6.7.0/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapredCommands.html
以下介绍几个常用的命令:
首先我们创建一个测试文件:
[root@localhost ~]# cd /data/
[root@localhost /data]# vim hello.txt # 随便写一些内容
hadoop welcome
hadoop hdfs mapreduce
hadoop hdfs
[root@localhost /data]# 1.查看文件系统的根目录:
[root@localhost /data]# hdfs dfs -ls /
[root@localhost /data]#2.将刚刚创建的文件拷贝到文件系统的根目录下:
[root@localhost /data]# hdfs dfs -put ./hello.txt /
[root@localhost /data]# hdfs dfs -ls /
Found 1 items
-rw-r--r-- 1 root supergroup 49 2018-03-24 22:37 /hello.txt
[root@localhost /data]# 3.查看文件内容:
[root@localhost /data]# hdfs dfs -cat /hello.txt
hadoop welcome
hadoop hdfs mapreduce
hadoop hdfs
[root@localhost /data]# 4.创建目录:
[root@localhost /data]# hdfs dfs -mkdir /test
[root@localhost /data]# hdfs dfs -ls /
Found 2 items
-rw-r--r-- 1 root supergroup 49 2018-03-24 22:37 /hello.txt
drwxr-xr-x - root supergroup 0 2018-03-24 22:40 /test
[root@localhost /data]# 5.递归创建目录:
[root@localhost /data]# hdfs dfs -mkdir -p /test/a/b/c6.递归查看目录:
[root@localhost /data]# hdfs dfs -ls -R /
-rw-r--r-- 1 root supergroup 49 2018-03-24 23:02 /hello.txt
drwxr-xr-x - root supergroup 0 2018-03-24 23:04 /test
drwxr-xr-x - root supergroup 0 2018-03-24 23:04 /test/a
drwxr-xr-x - root supergroup 0 2018-03-24 23:04 /test/a/b
drwxr-xr-x - root supergroup 0 2018-03-24 23:04 /test/a/b/c
[root@localhost /data]# 7.拷贝文件:
[root@localhost /data]# hdfs dfs -copyFromLocal ./hello.txt /test/a/b
[root@localhost /data]# hdfs dfs -ls -R /
-rw-r--r-- 1 root supergroup 49 2018-03-24 23:02 /hello.txt
drwxr-xr-x - root supergroup 0 2018-03-24 23:04 /test
drwxr-xr-x - root supergroup 0 2018-03-24 23:04 /test/a
drwxr-xr-x - root supergroup 0 2018-03-24 23:06 /test/a/b
drwxr-xr-x - root supergroup 0 2018-03-24 23:04 /test/a/b/c
-rw-r--r-- 1 root supergroup 49 2018-03-24 23:06 /test/a/b/hello.txt
[root@localhost /data]# 8.从文件系统中拿出文件:
[root@localhost /data]# hdfs dfs -get /test/a/b/hello.txt9.删除文件:
[root@localhost /data]# hdfs dfs -rm /hello.txt
Deleted /hello.txt
[root@localhost /data]# 10.删除目录:
[root@localhost /data]# hdfs dfs -rm -R /test
Deleted /test
[root@localhost /data]# 以上就是最为常用的一些操作命令了,如果需要使用其他命令,直接执行hdfs dfs就可以查看到所支持的所有命令。
接下来我们在浏览器里查看文件系统,首先将刚刚删除的文件put回去:
[root@localhost /data]# hdfs dfs -put ./hello.txt /在浏览器上查看文件系统:
查看文件的信息: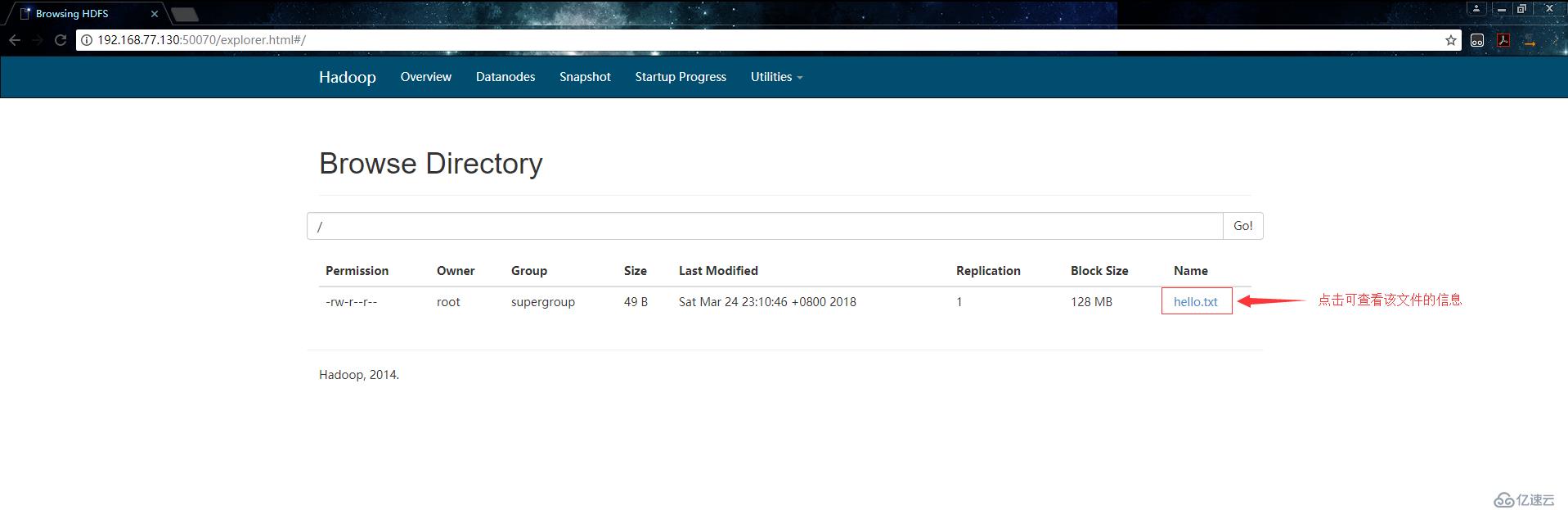
可以看到关于该文件的详细信息: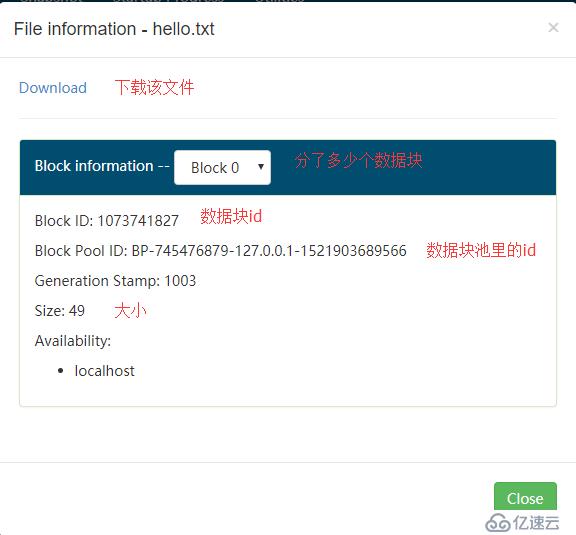
由于这个文件太小了,所以只有一个数据块。
我们来put一个比较大的文件,例如我们之前使用的Hadoop的安装包:
[root@localhost /data]# cd /usr/local/src/
[root@localhost /usr/local/src]# hdfs dfs -put ./hadoop-2.6.0-cdh6.7.0.tar.gz /如下,可以看到,这个文件被分为了三个数据块: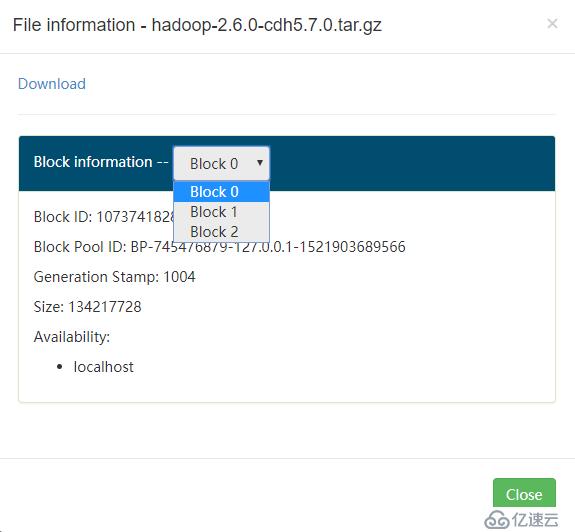
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。