жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
[TOC]
еңЁзј–еҶҷMapReduceзЁӢеәҸж—¶пјҢжҲ‘们дјҡеҸ‘зҺ°пјҢеҜ№дәҺMapReduceзҡ„иҫ“е…Ҙиҫ“еҮәж•°жҚ®пјҲkey-valueпјүпјҢжҲ‘们еҸӘиғҪдҪҝз”ЁHadoopжҸҗдҫӣзҡ„ж•°жҚ®зұ»еһӢпјҢиҖҢдёҚиғҪдҪҝз”ЁJavaжң¬иә«зҡ„еҹәжң¬ж•°жҚ®зұ»еһӢпјҢжҜ”еҰӮпјҢеҰӮжһңж•°жҚ®зұ»еһӢдёәlongпјҢйӮЈд№ҲеңЁзј–еҶҷMRзЁӢеәҸж—¶пјҢеҜ№еә”Hadoopзҡ„ж•°жҚ®зұ»еһӢеҲҷдёәLongWritableгҖӮе…ідәҺеҺҹеӣ пјҢз®ҖеҚ•иҜҙжҳҺеҰӮдёӢпјҡ
hadoopеңЁиҠӮзӮ№й—ҙзҡ„еҶ…йғЁйҖҡи®ҜдҪҝз”Ёзҡ„жҳҜRPCпјҢRPCеҚҸи®®жҠҠж¶ҲжҒҜзҝ»иҜ‘жҲҗдәҢиҝӣеҲ¶еӯ—иҠӮжөҒеҸ‘йҖҒеҲ°иҝңзЁӢиҠӮзӮ№пјҢ
иҝңзЁӢиҠӮзӮ№еҶҚйҖҡиҝҮеҸҚеәҸеҲ—еҢ–жҠҠдәҢиҝӣеҲ¶жөҒиҪ¬жҲҗеҺҹе§Ӣзҡ„дҝЎжҒҜгҖӮд№ҹе°ұжҳҜиҜҙпјҢдј йҖ’зҡ„ж¶ҲжҒҜеҶ…е®№жҳҜйңҖиҰҒз»ҸиҝҮhadoopзү№е®ҡзҡ„еәҸеҲ—еҢ–дёҺеҸҚеәҸеҲ—еҢ–ж“ҚдҪңзҡ„пјҢеӣ жӯӨпјҢжүҚйңҖиҰҒдҪҝз”ЁhadoopжҸҗдҫӣзҡ„ж•°жҚ®зұ»еһӢпјҢеҪ“然пјҢеҰӮжһңжғіиҰҒиҮӘе®ҡд№үMRзЁӢеәҸдёӯkey-valueзҡ„ж•°жҚ®зұ»еһӢпјҢеҲҷйңҖиҰҒе®һзҺ°зӣёеә”зҡ„жҺҘеҸЈпјҢеҰӮWritableгҖҒWritableComparableжҺҘеҸЈгҖӮ
д№ҹе°ұжҳҜиҜҙпјҢеҰӮжһңйңҖиҰҒиҮӘе®ҡд№үkey-valueзҡ„ж•°жҚ®зұ»еһӢпјҢеҝ…йЎ»иҰҒйҒөеҫӘеҰӮдёӢзҡ„еҺҹеҲҷпјҡ
/**
* MapReduceзҡ„д»»ж„Ҹзҡ„keyе’ҢvalueйғҪеҝ…йЎ»иҰҒе®һзҺ°WritableжҺҘеҸЈ
* MapReduceзҡ„д»»ж„Ҹkeyеҝ…йЎ»е®һзҺ°WritableComparableжҺҘеҸЈпјҢWritableComparableжҳҜWritableзҡ„еўһејәзүҲ
* keyиҝҳйңҖиҰҒе®һзҺ°Comparableзҡ„еҺҹеӣ еңЁдәҺпјҢеҜ№keyжҺ’еәҸжҳҜMapReduceжЁЎеһӢдёӯзҡ„еҹәжң¬еҠҹиғҪ
*/е…¶е®һеүҚйқўеҶҷзҡ„еҫҲеӨҡNettyзҡ„ж–Үз« пјҢеҲ°дәҶеҗҺйқўеҶҷзј–и§Јз ҒжҠҖжңҜж—¶пјҢйңҖиҰҒе®һзҺ°зҡ„еҠҹиғҪдёҺHadoopжҳҜдёҖж ·зҡ„пјҢеӣ дёәеҲ°жңҖеҗҺзҡ„зӣ®зҡ„пјҢжҲ‘д№ҹжҳҜеёҢжңӣиҮӘе·ұеҶҷдёҖдёӘRPCжЎҶжһ¶пјҲжЁЎд»ҝйҳҝйҮҢзҡ„dubboпјүгҖӮ
е…ідәҺWritableжҺҘеҸЈпјҢжәҗд»Јз Ғдёӯзҡ„и§ЈйҮҠе°ұйқһеёёеҘҪдәҶпјҡ
/**
* A serializable object which implements a simple, efficient, serialization
* protocol, based on {@link DataInput} and {@link DataOutput}.
*
* <p>Any <code>key</code> or <code>value</code> type in the Hadoop Map-Reduce
* framework implements this interface.</p>
*
* <p>Implementations typically implement a static <code>read(DataInput)</code>
* method which constructs a new instance, calls {@link #readFields(DataInput)}
* and returns the instance.</p>
*
* <p>Example:</p>
* <p><blockquote><pre>
* public class MyWritable implements Writable {
* // Some data
* private int counter;
* private long timestamp;
*
* public void write(DataOutput out) throws IOException {
* out.writeInt(counter);
* out.writeLong(timestamp);
* }
*
* public void readFields(DataInput in) throws IOException {
* counter = in.readInt();
* timestamp = in.readLong();
* }
*
* public static MyWritable read(DataInput in) throws IOException {
* MyWritable w = new MyWritable();
* w.readFields(in);
* return w;
* }
* }
* </pre></blockquote></p>
*/зӣҙжҺҘз»ҷеҮәе®ҳж–№жәҗз Ғдёӯзҡ„и§ЈйҮҠпјҡ
/**
* A {@link Writable} which is also {@link Comparable}.
*
* <p><code>WritableComparable</code>s can be compared to each other, typically
* via <code>Comparator</code>s. Any type which is to be used as a
* <code>key</code> in the Hadoop Map-Reduce framework should implement this
* interface.</p>
*
* <p>Note that <code>hashCode()</code> is frequently used in Hadoop to partition
* keys. It's important that your implementation of hashCode() returns the same
* result across different instances of the JVM. Note also that the default
* <code>hashCode()</code> implementation in <code>Object</code> does <b>not</b>
* satisfy this property.</p>
*
* <p>Example:</p>
* <p><blockquote><pre>
* public class MyWritableComparable implements WritableComparable<MyWritableComparable> {
* // Some data
* private int counter;
* private long timestamp;
*
* public void write(DataOutput out) throws IOException {
* out.writeInt(counter);
* out.writeLong(timestamp);
* }
*
* public void readFields(DataInput in) throws IOException {
* counter = in.readInt();
* timestamp = in.readLong();
* }
*
* public int compareTo(MyWritableComparable o) {
* int thisValue = this.value;
* int thatValue = o.value;
* return (thisValue < thatValue ? -1 : (thisValue==thatValue ? 0 : 1));
* }
*
* public int hashCode() {
* final int prime = 31;
* int result = 1;
* result = prime * result + counter;
* result = prime * result + (int) (timestamp ^ (timestamp >>> 32));
* return result
* }
* }
* </pre></blockquote></p>
*/дёӢеӣҫжҳҜз”өдҝЎдёҖж®өж—Ҙеҝ—и®°еҪ•зҡ„иЎЁз»“жһ„пјҢзҺ°йңҖиҰҒз»ҹи®ЎжҜҸдёҖдёӘжүӢжңәеҸ·з Ғзҡ„upPackNumгҖҒdownPackNumгҖҒupPayLoadгҖҒdownPayLoadзҡ„жҖ»е’ҢгҖӮ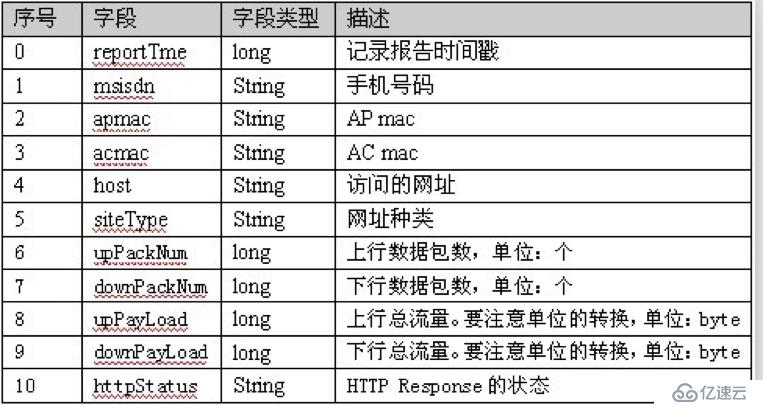
иҰҒжұӮпјҡдҪҝз”ЁиҮӘе®ҡд№үWritableе®ҢжҲҗгҖӮ
жҸҗдҫӣзҡ„ж–Үжң¬ж•°жҚ®еҰӮдёӢпјҡ
1363157985066,13726230503,00-FD-07-A4-72-B8:CMCC,120.196.100.82,i02.c.aliimg.com,,24,27,2481,24681,200
1363157995052,13826544101,5C-0E-8B-C7-F1-E0:CMCC,120.197.40.4,,,4,0,264,0,200
1363157991076,13926435656,20-10-7A-28-CC-0A:CMCC,120.196.100.99,,,2,4,132,1512,200
1363154400022,13926251106,5C-0E-8B-8B-B1-50:CMCC,120.197.40.4,,,4,0,240,0,200
1363157993044,18211575961,94-71-AC-CD-E6-18:CMCC-EASY,120.196.100.99,iface.qiyi.com,и§Ҷйў‘зҪ‘з«ҷ,15,12,1527,2106,200
1363157995074,84138413,5C-0E-8B-8C-E8-20:7DaysInn,120.197.40.4,122.72.52.12,,20,16,4116,1432,200
1363157993055,13560439658,C4-17-FE-BA-DE-D9:CMCC,120.196.100.99,,,18,15,1116,954,200
1363157995033,15920133257,5C-0E-8B-C7-BA-20:CMCC,120.197.40.4,sug.so.360.cn,дҝЎжҒҜе®үе…Ё,20,20,3156,2936,200
1363157983019,13719199419,68-A1-B7-03-07-B1:CMCC-EASY,120.196.100.82,,,4,0,240,0,200
1363157984041,13660577991,5C-0E-8B-92-5C-20:CMCC-EASY,120.197.40.4,s19.cnzz.com,з«ҷзӮ№з»ҹи®Ў,24,9,6960,690,200
1363157973098,15013685858,5C-0E-8B-C7-F7-90:CMCC,120.197.40.4,rank.ie.sogou.com,жҗңзҙўеј•ж“Һ,28,27,3659,3538,200
1363157986029,15989002119,E8-99-C4-4E-93-E0:CMCC-EASY,120.196.100.99,www.umeng.com,з«ҷзӮ№з»ҹи®Ў,3,3,1938,180,200
1363157992093,13560439658,C4-17-FE-BA-DE-D9:CMCC,120.196.100.99,,,15,9,918,4938,200
1363157986041,13480253104,5C-0E-8B-C7-FC-80:CMCC-EASY,120.197.40.4,,,3,3,180,180,200
1363157984040,13602846565,5C-0E-8B-8B-B6-00:CMCC,120.197.40.4,2052.flash3-http.qq.com,з»јеҗҲй—ЁжҲ·,15,12,1938,2910,200
1363157995093,13922314466,00-FD-07-A2-EC-BA:CMCC,120.196.100.82,img.qfc.cn,,12,12,3008,3720,200
1363157982040,13502468823,5C-0A-5B-6A-0B-D4:CMCC-EASY,120.196.100.99,y0.ifengimg.com,з»јеҗҲй—ЁжҲ·,57,102,7335,110349,200
1363157986072,18320173382,84-25-DB-4F-10-1A:CMCC-EASY,120.196.100.99,input.shouji.sogou.com,жҗңзҙўеј•ж“Һ,21,18,9531,2412,200
1363157990043,13925057413,00-1F-64-E1-E6-9A:CMCC,120.196.100.55,t3.baidu.com,жҗңзҙўеј•ж“Һ,69,63,11058,48243,200
1363157988072,13760778710,00-FD-07-A4-7B-08:CMCC,120.196.100.82,,,2,2,120,120,200
1363157985079,13823070001,20-7C-8F-70-68-1F:CMCC,120.196.100.99,,,6,3,360,180,200
1363157985069,13600217502,00-1F-64-E2-E8-B1:CMCC,120.196.100.55,,,18,138,1080,186852,200дёӢйқўе°ұеҹәдәҺWritableжҺҘеҸЈеҶҷдёҖдёӘHttpDataWritableзұ»пјҢд»Јз ҒеҰӮдёӢпјҡ
package com.uplooking.bigdata.mr.http;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* MapReduceзҡ„д»»ж„Ҹзҡ„keyе’ҢvalueйғҪеҝ…йЎ»иҰҒе®һзҺ°WritableжҺҘеҸЈ
* MapReduceзҡ„д»»ж„Ҹkeyеҝ…йЎ»е®һзҺ°WritableComparableжҺҘеҸЈпјҢWritableComparableжҳҜWritableзҡ„еўһејәзүҲ
*/
public class HttpDataWritable implements Writable {
private long upPackNum;
private long downPackNum;
private long upPayLoad;
private long downPayLoad;
public HttpDataWritable() {
}
public HttpDataWritable(long upPackNum, long downPackNum, long upPayLoad, long downPayLoad) {
this.upPackNum = upPackNum;
this.downPackNum = downPackNum;
this.upPayLoad = upPayLoad;
this.downPayLoad = downPayLoad;
}
public void write(DataOutput out) throws IOException {
out.writeLong(upPackNum);
out.writeLong(downPackNum);
out.writeLong(upPayLoad);
out.writeLong(downPayLoad);
}
public void readFields(DataInput in) throws IOException {
this.upPackNum = in.readLong();
this.downPackNum = in.readLong();
this.upPayLoad = in.readLong();
this.downPayLoad = in.readLong();
}
public long getUpPackNum() {
return upPackNum;
}
public void setUpPackNum(long upPackNum) {
this.upPackNum = upPackNum;
}
public long getDownPackNum() {
return downPackNum;
}
public void setDownPackNum(long downPackNum) {
this.downPackNum = downPackNum;
}
public long getUpPayLoad() {
return upPayLoad;
}
public void setUpPayLoad(long upPayLoad) {
this.upPayLoad = upPayLoad;
}
public long getDownPayLoad() {
return downPayLoad;
}
public void setDownPayLoad(long downPayLoad) {
this.downPayLoad = downPayLoad;
}
@Override
public String toString() {
return upPackNum + "\t" + downPackNum + "\t" +
upPayLoad + "\t" + downPayLoad;
}
}
зЁӢеәҸд»Јз ҒеҰӮдёӢпјҡ
package com.uplooking.bigdata.mr.http;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class HttpDataJob {
public static void main(String[] args) throws Exception {
if (args == null || args.length < 2) {
System.err.println("Parameter Errors! Usages:<inputpath> <outputpath>");
System.exit(-1);
}
Path inputPath = new Path(args[0]);
Path outputPath = new Path(args[1]);
Configuration conf = new Configuration();
String jobName = HttpDataJob.class.getSimpleName();
Job job = Job.getInstance(conf, jobName);
//и®ҫзҪ®jobиҝҗиЎҢзҡ„jar
job.setJarByClass(HttpDataJob.class);
//и®ҫзҪ®ж•ҙдёӘзЁӢеәҸзҡ„иҫ“е…Ҙ
FileInputFormat.setInputPaths(job, inputPath);
job.setInputFormatClass(TextInputFormat.class);//е°ұжҳҜи®ҫзҪ®еҰӮдҪ•е°Ҷиҫ“е…Ҙж–Ү件解жһҗжҲҗдёҖиЎҢдёҖиЎҢеҶ…е®№зҡ„и§Јжһҗзұ»
//и®ҫзҪ®mapper
job.setMapperClass(HttpDataMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(HttpDataWritable.class);
//и®ҫзҪ®ж•ҙдёӘзЁӢеәҸзҡ„иҫ“еҮә
// outputpath.getFileSystem(conf).delete(outputpath, true);//еҰӮжһңеҪ“еүҚиҫ“еҮәзӣ®еҪ•еӯҳеңЁпјҢеҲ йҷӨд№ӢпјҢд»ҘйҒҝе…Қ.FileAlreadyExistsException
FileOutputFormat.setOutputPath(job, outputPath);
job.setOutputFormatClass(TextOutputFormat.class);
//и®ҫзҪ®reducer
job.setReducerClass(HttpDataReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(HttpDataWritable.class);
//жҢҮе®ҡзЁӢеәҸжңүеҮ дёӘreducerеҺ»иҝҗиЎҢ
job.setNumReduceTasks(1);
//жҸҗдәӨзЁӢеәҸ
job.waitForCompletion(true);
}
public static class HttpDataMapper extends Mapper<LongWritable, Text, Text, HttpDataWritable> {
@Override
protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException {
String line = v1.toString();
String[] items = line.split(",");
// иҺ·еҸ–жүӢжңәеҸ·з Ғ
String phoneNum = items[1];
// иҺ·еҸ–upPackNumгҖҒdownPackNumгҖҒupPayLoadгҖҒdownPayLoad
long upPackNum = Long.parseLong(items[6]);
long downPackNum = Long.parseLong(items[7]);
long upPayLoad = Long.parseLong(items[8]);
long downPayLoad = Long.parseLong(items[9]);
// жһ„е»әHttpDataWritableеҜ№иұЎ
HttpDataWritable httpData = new HttpDataWritable(upPackNum, downPackNum, upPayLoad, downPayLoad);
// еҶҷеҮәж•°жҚ®еҲ°context
context.write(new Text(phoneNum), httpData);
}
}
public static class HttpDataReducer extends Reducer<Text, HttpDataWritable, Text, HttpDataWritable> {
@Override
protected void reduce(Text k2, Iterable<HttpDataWritable> v2s, Context context) throws IOException, InterruptedException {
long upPackNum = 0L;
long downPackNum = 0L;
long upPayLoad = 0L;
long downPayLoad = 0L;
// йҒҚеҺҶv2sпјҢи®Ўз®—еҗ„дёӘеҸӮж•°зҡ„жҖ»е’Ң
for(HttpDataWritable htd : v2s) {
upPackNum += htd.getUpPackNum();
downPackNum += htd.getDownPackNum();
upPayLoad += htd.getUpPayLoad();
downPayLoad += htd.getDownPayLoad();
}
// жһ„е»әHttpDataWritableеҜ№иұЎ
HttpDataWritable httpData = new HttpDataWritable(upPackNum, downPackNum, upPayLoad, downPayLoad);
// еҶҷеҮәж•°жҚ®еҲ°context
context.write(k2, httpData);
}
}
}жіЁж„ҸпјҢдёҠйқўзҡ„зЁӢеәҸжҳҜйңҖиҰҒиҜ»еҸ–е‘Ҫд»ӨиЎҢзҡ„еҸӮж•°иҫ“е…Ҙзҡ„пјҢеҸҜд»ҘеңЁжң¬ең°зҡ„зҺҜеўғжү§иЎҢпјҢд№ҹеҸҜд»Ҙжү“еҢ…жҲҗдёҖдёӘjarеҢ…дёҠдј еҲ°HadoopзҺҜеўғзҡ„LinuxжңҚеҠЎеҷЁдёҠжү§иЎҢпјҢиҝҷйҮҢпјҢжҲ‘дҪҝз”Ёзҡ„жҳҜжң¬ең°зҺҜеўғпјҲжҲ‘зҡ„ж“ҚдҪңзі»з»ҹжҳҜMac OSпјүпјҢиҫ“е…Ҙзҡ„еҸӮж•°еҰӮдёӢпјҡ
/Users/yeyonghao/data/input/HTTP_20160415143750.dat /Users/yeyonghao/data/output/mr/http/h-1иҝҗиЎҢзЁӢеәҸеҗҺпјҢжҹҘзңӢиҫ“еҮәз»“жһңпјҢеҰӮдёӢпјҡ
yeyonghao@yeyonghaodeMacBook-Pro:~/data/output/mr/http/h-1$ cat part-r-00000
13480253104 3 3 180 180
13502468823 57 102 7335 110349
13560439658 33 24 2034 5892
13600217502 18 138 1080 186852
13602846565 15 12 1938 2910
13660577991 24 9 6960 690
13719199419 4 0 240 0
13726230503 24 27 2481 24681
13760778710 2 2 120 120
13823070001 6 3 360 180
13826544101 4 0 264 0
13922314466 12 12 3008 3720
13925057413 69 63 11058 48243
13926251106 4 0 240 0
13926435656 2 4 132 1512
15013685858 28 27 3659 3538
15920133257 20 20 3156 2936
15989002119 3 3 1938 180
18211575961 15 12 1527 2106
18320173382 21 18 9531 2412
84138413 20 16 4116 1432иҜҙжҳҺжҲ‘们зҡ„MapReduceзЁӢеәҸжІЎжңүй—®йўҳпјҢ并且еҶҷзҡ„HttpDataWritableзұ»д№ҹжҳҜеҸҜд»ҘжӯЈеёёдҪҝз”Ёзҡ„гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ